MCP + 数据库,一种比 RAG 检索效果更好的新方式!
在开始学习之前,我们先了解一下,RAG 技术目前的局限性。
资料推荐
💡MCP中转API推荐
✨中转使用教程
一、背景:RAG 的局限性
RAG,即检索增强生成(Retrieval-Augmented Generation),是目前大模型领域的一个热门方向。它将信息检索技术与生成式模型相结合,解决大模型在知识准确性、上下文理解以及对最新信息的利用等方面的难题。
在之前的教程中,如何拥有一个无限制、可联网、带本地知识库的私人 DeepSeek? 我们一起学习了如何在本地部署模型并且引入知识库。
但是很多小伙伴可能对 RAG 有点误解,觉得我们只要将一些额外的知识通过 RAG 导入,模型就能完美的掌握并且回答这些知识相关的问题。但事实和想象还是有差距的,大家在实际尝试后可能会发现,RAG 的精准度似乎没有那么好。
从 RAG 本身技术原理的角度出发,目前存在着以下问题:
检索精度不足:首先,RAG 最核心的就是先将知识转换成 “向量“ ,导入 “向量数据库“,然后在将用户输入的信息也转换成 “向量” ,然后再去向量数据库匹配出相似的 “向量“,最后再由大模型去总结检索到的内容。
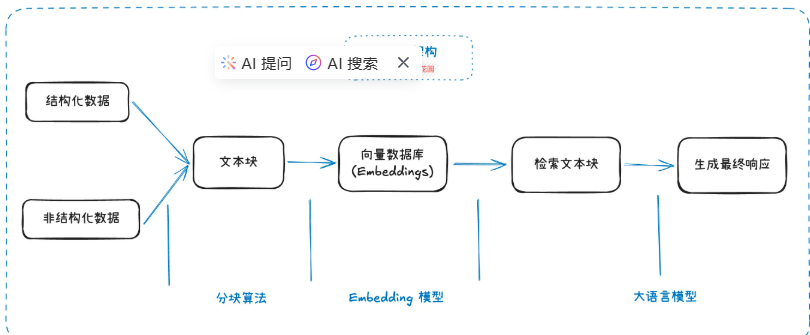
从这个过程中我们看出,大模型仅仅起到了总结的作用,而检索到信息的精准度大部分情况下取决于向量的相似度匹配,检索结果可能包含无关内容(低精确率)或遗漏关键信息(低召回率)。
生成内容不完整:由于 RAG 处理的是文档的切片,而切片的局部性注定了它无法看到整篇文档的信息,因此在回答诸如“列举XXX”“总结XXX”等问题时,一般回答是不完整的。
缺乏大局观:RAG 无法判断需要多少个切片才能回答问题,也无法判断文档间的联系。例如,在法律条文中,新的解释可能覆盖旧的解释,但 RAG 无法判断哪个是最新的。
多轮检索能力弱:RAG 缺乏执行多轮、多查询检索的能力,而这对推理任务来说是必不可少的。
尽管近期也有些新出现的技术,如 GraphRAG、KAG 等能够在一定程度上解决这些问题,但都还不成熟,目前的 RAG 技术还远远达不到我们预期想要的效果。
下面,我们将介绍一个新的方案,通过 MCP + 数据库来提高结构化数据的检索精准度,基本上能够实现 text to SQL 的效果,实测的检索效果也要比 RAG 好很多,例如我们有这样一份学生列表的信息:

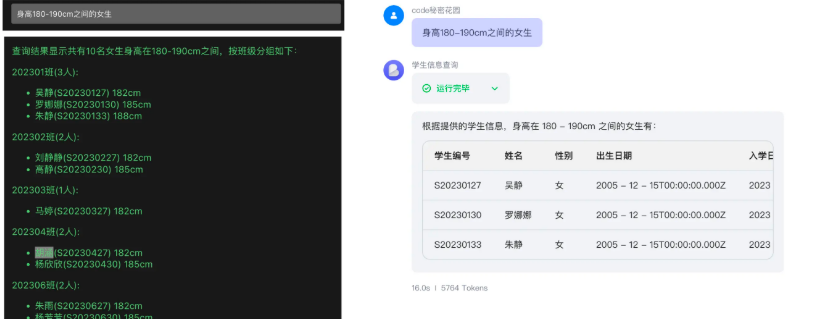
我们用一个稍微复杂一点问题(身高 180-190cm 之间的女生有哪些?)来测试:
实战:使用 MCP 调用数据库
首先,为了方便给大家进行演示,我们先来构造一个简单的数据库案例。
4.1 Mongodb
这里我们选择的数据库是 MongoDB:一款流行的开源的文档型数据库。MongoDB 使用文档型数据模型,数据以 JSON 格式存储。

为什么选择 MongoDB 而不是 sqlite 之类的关系型数据库呢,主要还是因为在关系型数据库中,表结构是固定的,若要添加新字段或修改表结构,往往需要进行复杂的迁移操作。而 MongoDB 的文档型数据模型,允许在同一个集合中存储不同结构的文档,应用程序可以根据需要灵活地添加或修改字段,无需事先定义严格的表结构,这对于我们想构建一个持续补充的结构化知识库的场景,是非常友好的。
大家可以直接在官方文档下载安装 MongoDB Community Server(MongoDB 的免费开源版本):
安装完成后,其会默认监听我们本地的 27017 端口
然后,为了可视化查看数据,我们还需要安装 MongoDB Compass (MongoDB 提供的本地 GUI 可视化工具)
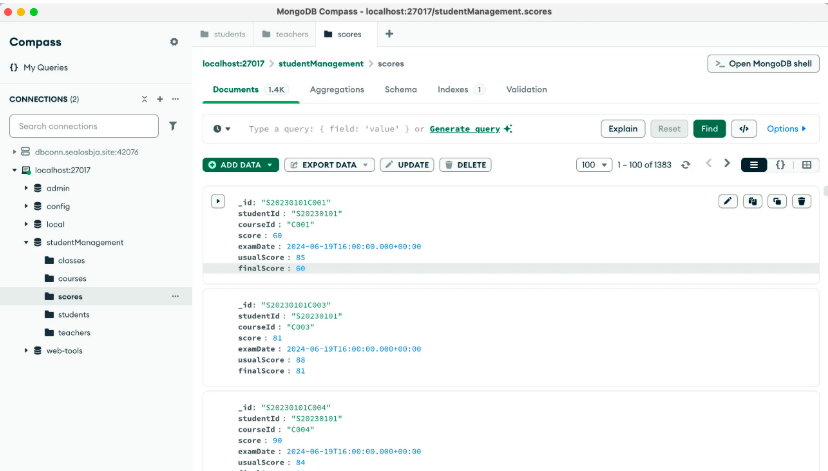
安装完成后,我们通过 MongoDB Compass 客户端链接到本地的 MongoDB Server:
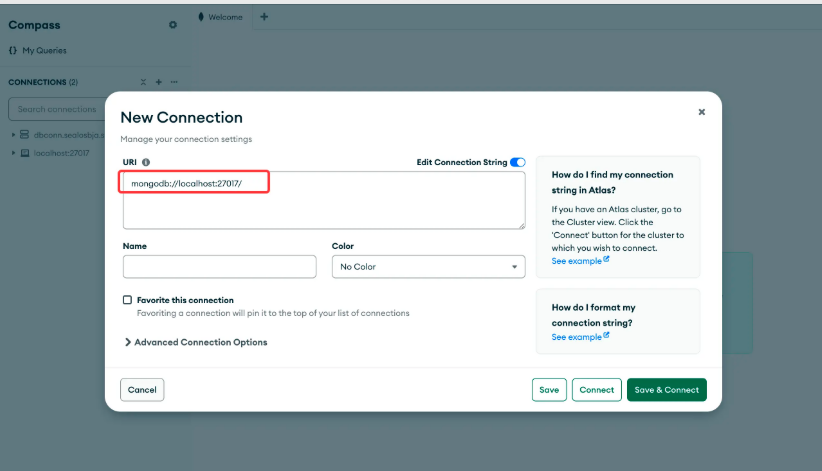
随后,大家就可以通过客户端将自己的数据导入 MongoDB 数据库,在后面的例子中,我们将使用一个学生信息的数据来进行演示,假定我们的数据是这样的:
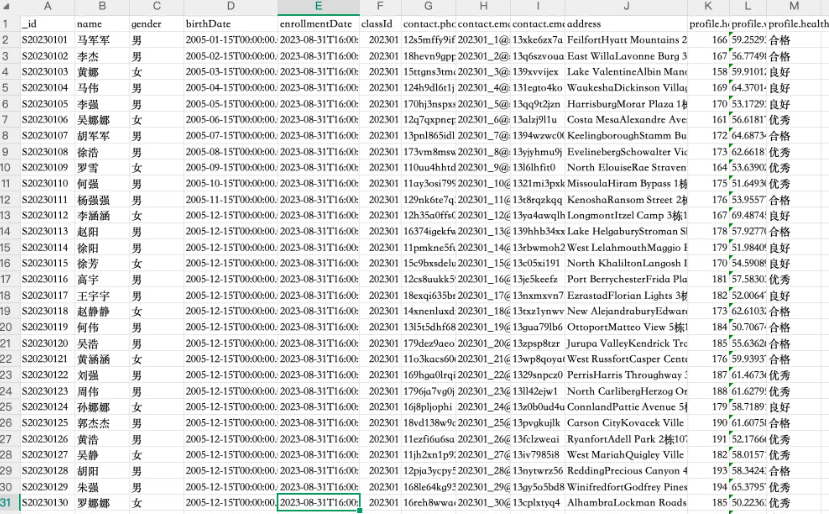
如果你不知道怎么导入 MongoDB ,可以借助 AI 来帮你编写导入脚本,然后根据 AI 提示进行导入即可:
提示词:帮我编写一个脚本,可以将当前表格中的数据导入我本地的 MongoDB 数据库,数据库的名称为 studentManagement
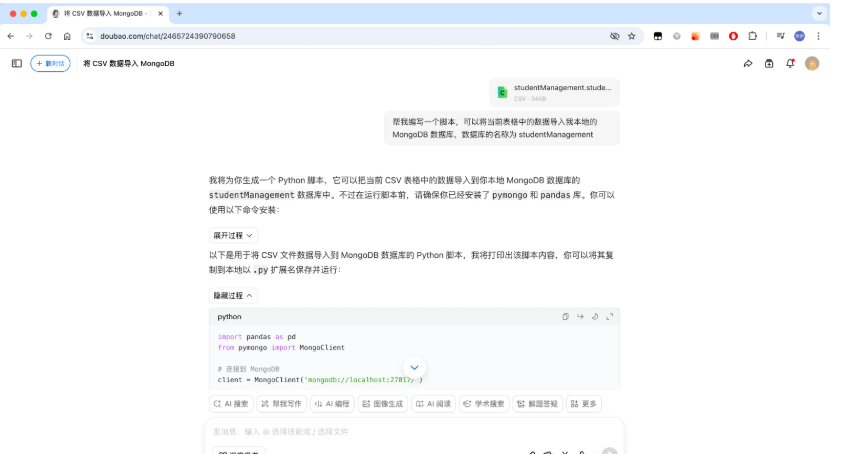
然后根据 AI 提示运行脚本进行导入即可,成功导入后的效果:
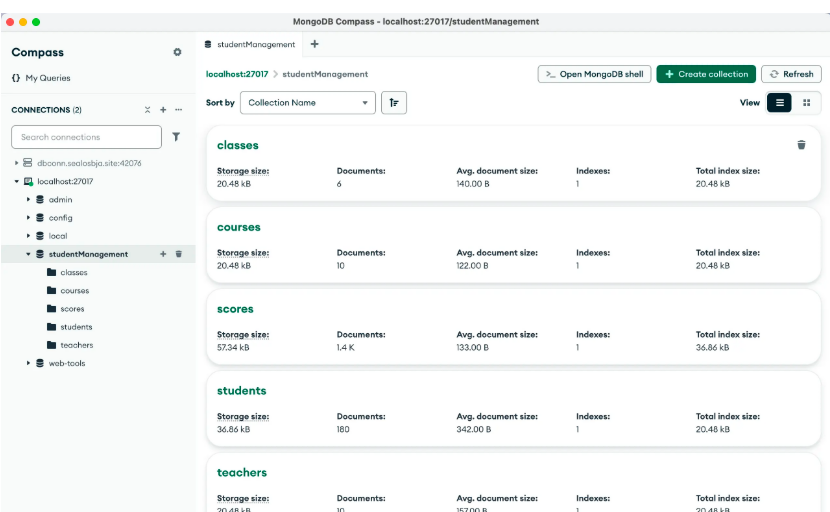
学生信息表:
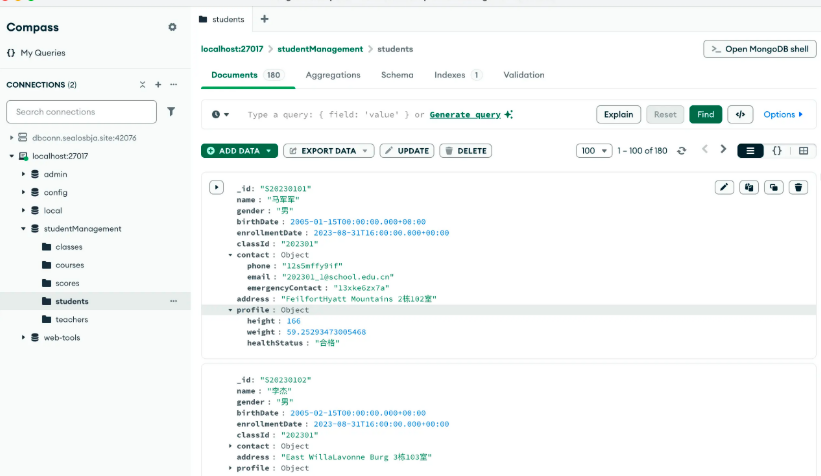
学生分数表: