黑马Java基础笔记-14
Arrays
sort
基本数据类型:双枢轴快速排序(Dual-Pivot Quicksort)+ 插入排序
Java 自 Java 7 起对所有基本类型数组(如
int[]、double[]等)采用 双枢轴快速排序(Dual-Pivot Quicksort),仅当递归处理的子区间长度 ≤ 47 时回退到插入排序以优化小规模性能(这样做能有效减少递归深度和方法调用开销,同时利用插入排序在小规模数据上的低常数因子优势)为什么不适用二分插入排序?
- 内存访问模式优化 普通插入排序采用顺序访问模式,对CPU缓存更友好。在小数据量下,顺序移动元素的开销可能低于二分插入排序的随机访问模式。
- 实现简单性与代码优化 普通插入排序代码更简洁,无需递归或复杂边界判断。这在Java标准库中尤为重要——需减少代码体积与潜在错误,同时允许JVM编译器更高效地优化(如循环展开)。
引用数据类型:TimSort(二分插入排序+归并排序)
对引用类型数组(如
String[]、Object[]或带比较器的T[]),则采用 TimSort排序算法(六)- TimSort | SakuraTears的博客,Timsort排序算法可以概括成如下几步:
1.把待排数组划分成一个个run,当然run不能太短,长度最小阈值为minRun;
2.run的划分规则:从数组最小下标low开始,寻找连续有序部分(连续逆序也算,寻找的时候会把这段顺序反过来),如果这段有序部分长度小于minRun,就用二分插入排序补充到minRun;
3.将run入栈,当栈顶的run的长度不满足下列约束条件中任意一个时,runLen[n-1] > runLen[n] + runLen[n+1] runLen[n] > runLen[n+1]则利用归并排序将其中最短的2个run合并成一个新run;(类似于金字塔型)
4.最后会有一次强制合并合并所有栈内剩余所有run(自底向上,保证稳定性),最终栈空,生成有序数组该算法会先识别“自然有序段”(runs),对长度不足 minrun(通常 [16–32](MIN_MERGE = 32),minrun只和待排序数组长度有关)的小段使用二分插入排序扩展至 minrun,再对所有 runs 进行归并,以保证稳定性(相同元素中在原数组中在前的元素排完序之后还是在前)
左侧run(老run、大run,在栈下层)会先给复制到临时数组中,右侧run不会,而是一个指针指到起始位置(待排序数组);
还有一个指针
dest指向左侧run在待排序数组的原位置,这就是排序的原点,现在开始使用临时数组与右侧run指针指的元素进行比较,按照规则填入dest中最后如果左侧run还有剩就复制到原数组中
参考代码
// 'a' 是原始数组,既包含左侧 run,也包含右侧 run private void mergeLo(int base1, int len1, int base2, int len2) {T[] a = this.a; // 原始待排序数组T[] tmp = ensureCapacity(len1); // 临时缓冲区,用于存储左侧 runSystem.arraycopy(a, base1, tmp, 0, len1);int cursor1 = 0; // 对应 tmp 中的下标int cursor2 = base2; // 对应 a 中右侧 run 的起始下标int dest = base1; // 写回 a 的起始位置// 合并循环:比较 tmp[cursor1](左 run)与 a[cursor2](右 run)while (len1 > 0 && len2 > 0) {if (c.compare(tmp[cursor1], a[cursor2]) <= 0) {// 相等或左侧更小,先写回左 run 的元素a[dest++] = tmp[cursor1++];len1--;} else {// 否则写回右 run 的元素a[dest++] = a[cursor2++];len2--;}}// 剩余元素收尾:左侧还剩就复制 tmp;右侧还剩则已经在 a 中正确位置if (len1 > 0) {System.arraycopy(tmp, cursor1, a, dest, len1);} }
- 保证了稳定性
和对部分有序数据的自适应性
为什么使用二分插入排序?
对象之间的比较往往开销较高(因为它们需要调用
compareTo或者特定比较器)为了减少每次将新元素插入到已排序部分时的比较次数,TimSort使用了二分插入排序
并行排序(Arrays.parallelSort,Java 8+)基于 Fork/Join 框架,将数组划分为多段并行调用上述串行算法排序,最后再以并行归并方式将各已排序子段整合为最终结果。
Lambda表达式
- Lambda表达式可以用来简化匿名内部类的书写
- Lambda表达式只能简化函数式接口的匿名内部类的写法
- 函数式接口: 有且仅有一个抽象方法的接口叫做函数式接口,接口上方可以加@FunctionalInterface注解
集合
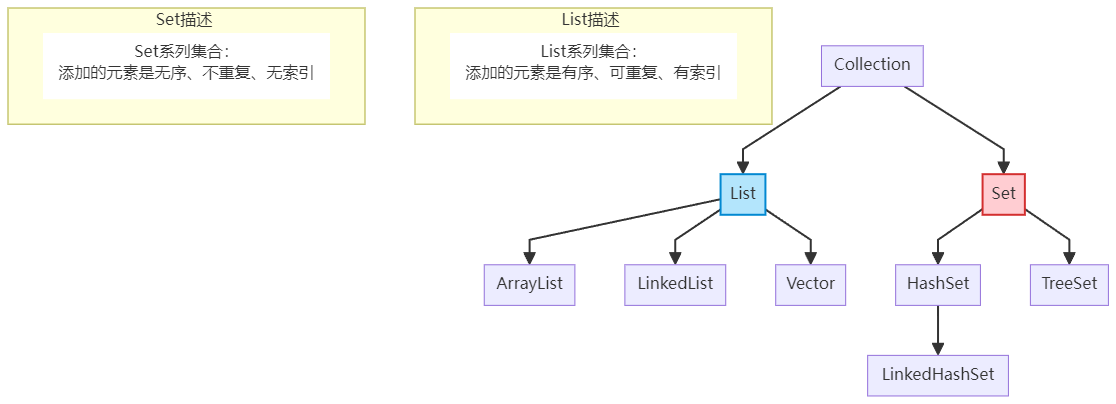
contains底层是使用equals方法实现的,如果需要判断引用数据类型需要重写equals方法
遍历
迭代器
在使用迭代器遍历时不能使用集合的方法来操作元素,需要使用迭代器删除元素的方法
如果当前位置没有元素,还要强行获取,会报NoSuchElementException
迭代器遍历完毕,指针不会复位(可以重新获取迭代器对象)
源码分析

增强型for循环
增强for的底层就是迭代器,为了简化迭代器的代码书写的。
它是JDK5之后出现的,其内部原理就是一个Iterator迭代器
所有的单列集合和数组才能用增强for进行遍历。
lanbda表达式
底层是for的循环遍历(增强for和普通for)

ArrayList
remove细节
调用方法的时候,如果方法出现了重载现象,优先调用实参跟形参类型一致的那个方法。
//List系列集合中的两个删除的方法
//1.直接删除元素
//2.通过索引进行删除//1.创建集合并添加元素
//1.To创建>list=new ArrayList<>();
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);//2.删除元素
//请问:此时删除的是1这个元素,还是1索引上的元素?
//为什么?
//因为在调用方法的时候,如果方法出现了重载现象
//优先调用,实参跟形参类型一致的那个方法。
//list.remove(1);//删除2//手动装箱,手动把基本数据类型的1,变成Integer类型
Integer =Integer.valueOf(1);
list.remove(i);//删除1
System.out.println(list);
源码分析
底层原理
-
利用空参创建集合
- 在底层创建一个默认长度为
0的数组。
- 在底层创建一个默认长度为
-
添加第一个元素时
- 底层会创建一个新的长度为
10的数组。
- 底层会创建一个新的长度为
-
存满时扩容
- 数组会扩容为原来长度的
1.5倍。
- 数组会扩容为原来长度的
-
一次添加多个元素时
- 如果扩容后的数组长度仍不足以容纳新增元素,则新创建数组的长度以实际所需为准。
源码分析
初次创建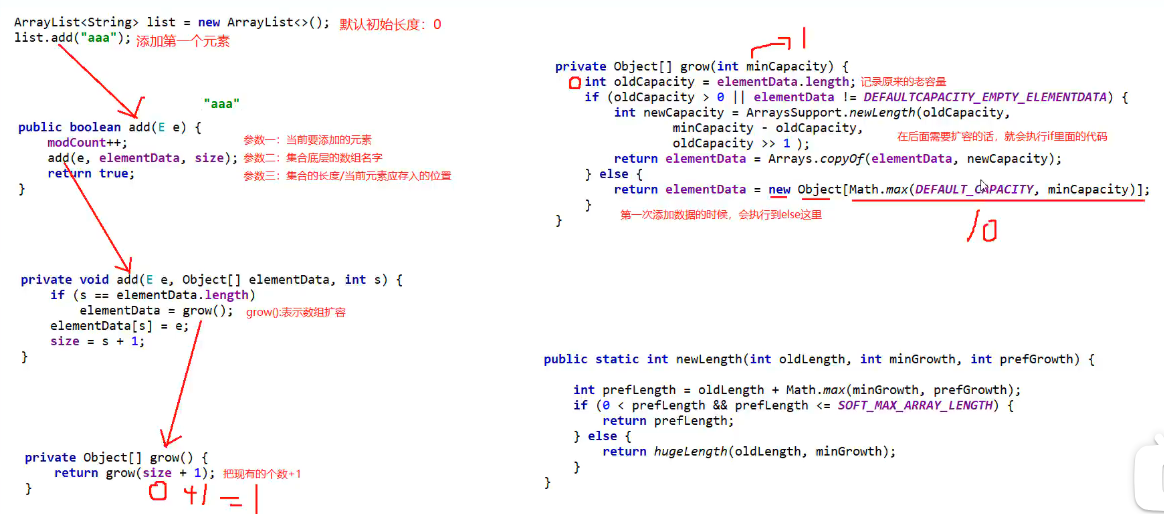
扩容

List
比集合多了一个列表迭代器和一个根据索引遍历
列表迭代器
// 5.列表迭代器
// 获取一个列表迭代器的对象,里面的指针默认也是指向θ索引的
// 额外添加了一个方法:在遍历的过程中,可以添加元素
ListIterator<Book>it=list.listListIterATOR();
while( it.hasNext( )){String str = it.next( );if("bbb".equals(str){//qqgit.add("qqq");}
}
ListIterator的功能扩展
与普通迭代器Iterator相比,ListIterator新增了以下功能,这些功能是List接口特有的:
- 双向遍历:支持
hasPrevious()和previous()方法反向遍历元素. - 修改操作:允许在遍历过程中通过
add()、set()等方法动态增删或修改元素. - 索引访问:可通过
nextIndex()和previousIndex()获取当前元素的索引.
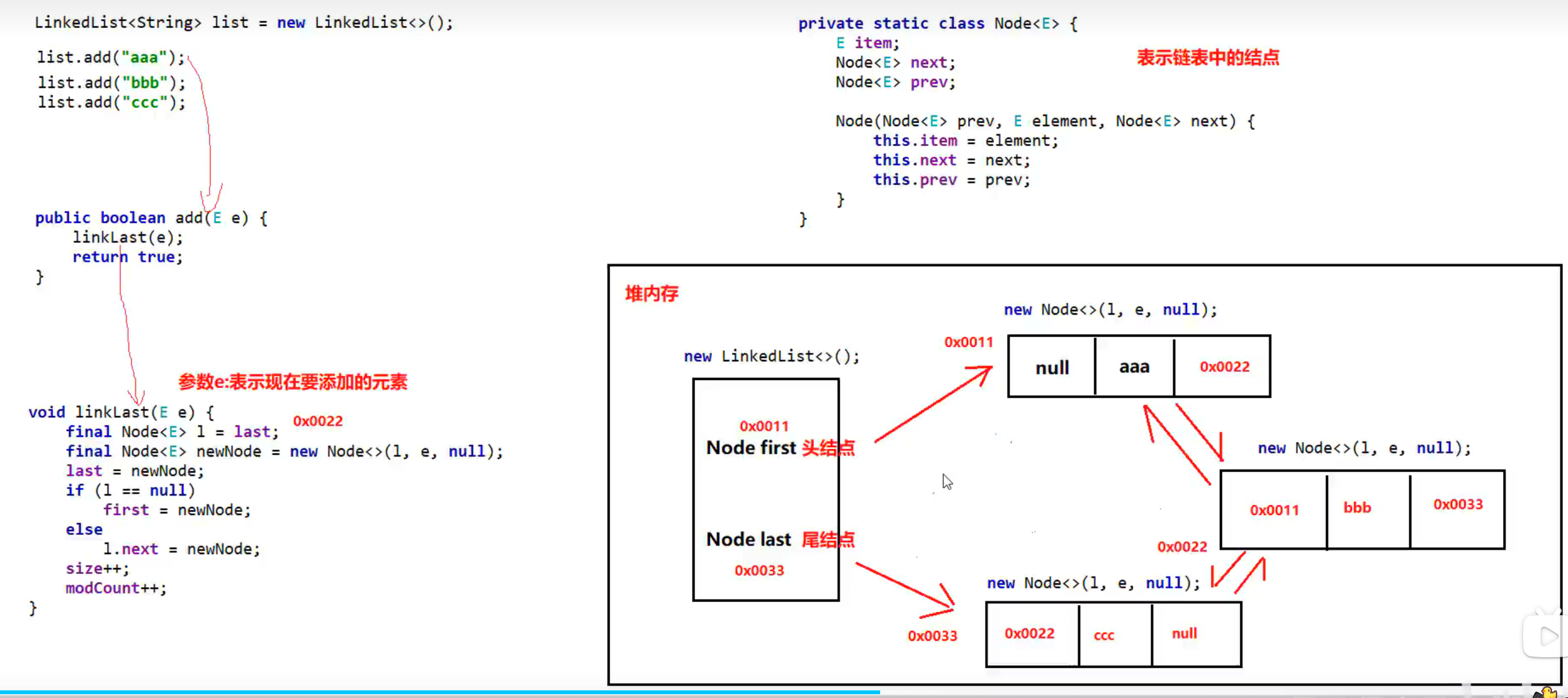
LinkedList
源码分析
泛型
java中的泛型是伪泛型

Java 泛型通过**“类型擦除”机制实现:编译器在编译阶段将所有类型参数替换为其边界类型**(若无边界则为 Object),在字节码中只保留普通类和方法;在必要位置插入强制转换指令以保证取出时能够返回原声明的泛型类型;并可能生成桥接方法以维护泛型方法的多态性。运行时所有泛型实参信息已被抹除,容器内部统一以 Object 或边界类型存储
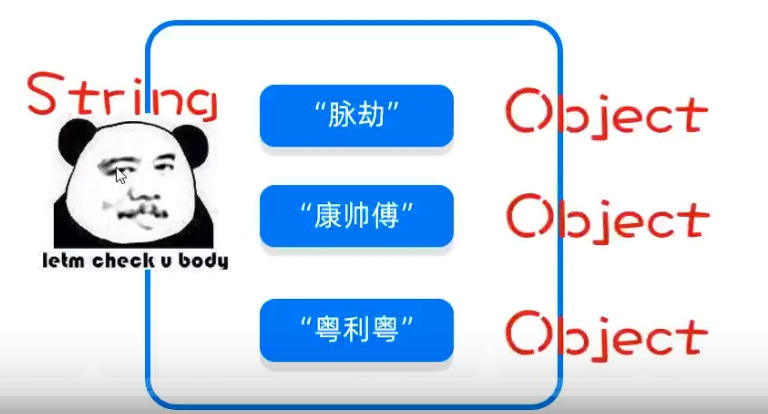
泛型的通配符
泛型不具备继承性(确定好类型后不能使用子类),但是数据具备继承性(但是可以使用父类来装子类数据)
?也表示不确定的类型
他可以进行类型的限定
?extends E:表示可以传递E或者E所有的子类类型
?super E:表示可以传递E或者E所有的父类类型
平衡二叉树
每个节点左右高度差距小于等于1
不平衡需要旋转
右旋
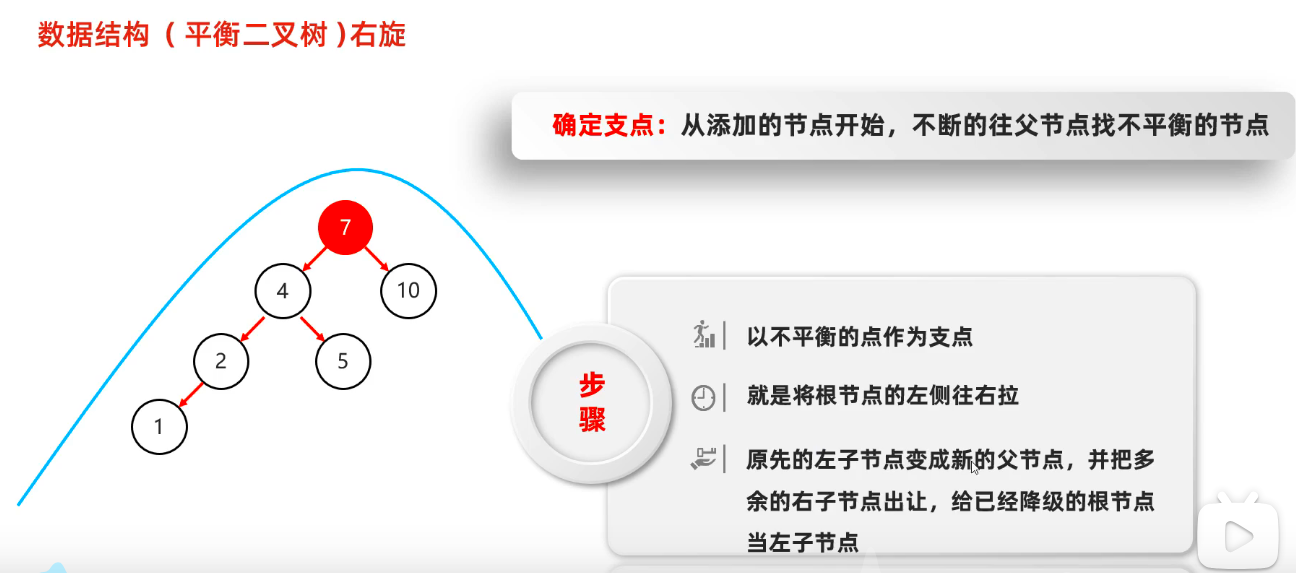
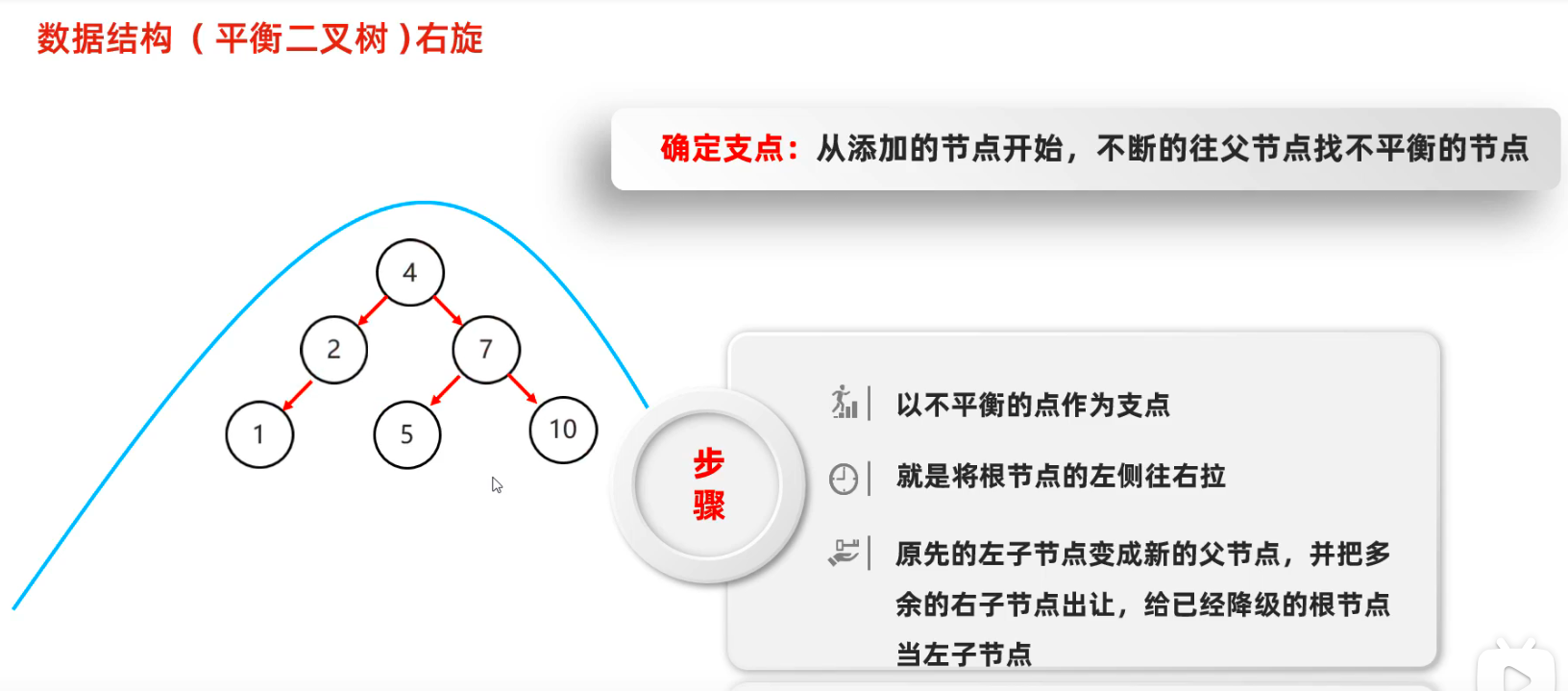
需要旋转的四种情况
- 左左 : 一次右旋
- 左右 : 先局部左旋,再整体右旋
- 右右 : 一次左旋
- 右左 : 先局部右旋,再整体左旋
红黑树
-
是一个二叉查找树
-
但是不是高度平衡的
-
条件:特有的红黑规则
-
增删改查性能比较好(旋转次数少,多是改属性(颜色))
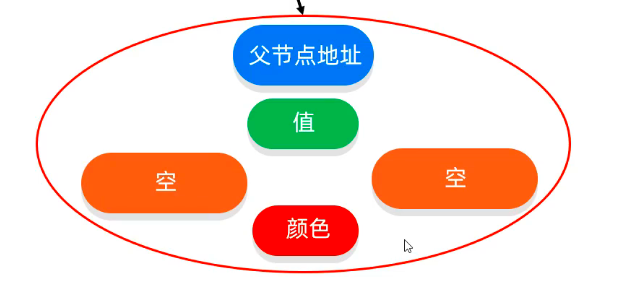
规则
①每一个节点是红色的,或者是黑色的
②根节点必须是黑色
③叶节点是黑色的
④两个红色节点不能相连
⑤任意节点到所有后代叶节点的简单路径上,黑色节点数量相同
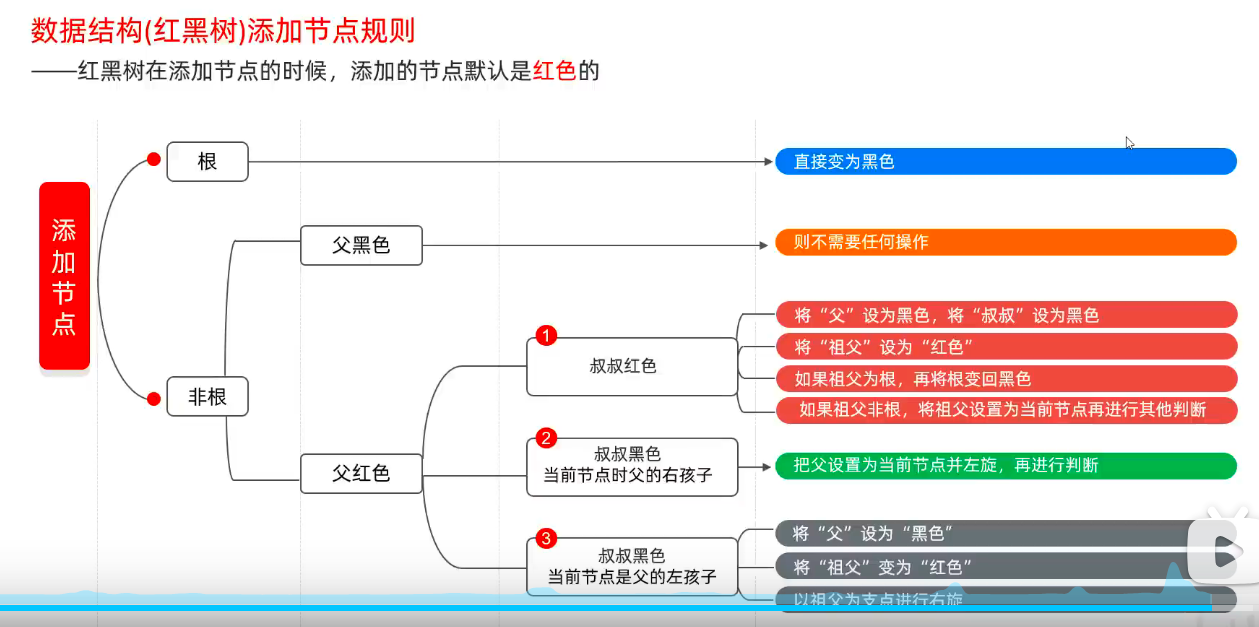
添加节点规则
默认添加红节点效率高