关于初学者对大模型的一些概念的理解
在网上看到的一张图,我感觉还是比较清晰的,能快速对大模型有一个概念。
大模型及相关概念详解
大模型(Large Language Model, LLM)就是近年来人工智能领域的核心技术,基于海量数据和强大算力训练而成,能够处理自然语言理解、生成、推理等复杂任务。
1. 大模型(Large Language Model, LLM)
定义
大模型是指参数量巨大( 百亿级、千亿级,甚至万亿级)的深度学习模型,核心是基于 深度学习 和 神经网络、Transformer架构,通过自监督学习(如掩码语言建模)从海量文本数据中学习语言规律。
Transformer 通过 “自注意力机制(Self-Attention)” 和 “多头注意力机制(Multi-Head Attention)” 实现高效的信息处理,相比于传统的 RNN(循环神经网络)和 CNN(卷积神经网络)具有更强的并行计算能力和更长的上下文理解能力。
核心特点
-
规模效应:参数量越大,模型表现通常越好(如GPT-3有1750亿参数)。
-
通用性:可处理多种任务(文本生成、翻译、问答等)。
-
上下文学习(In-Context Learning):通过少量示例(Few-shot)即可适应新任务。
典型模型
-
GPT系列(OpenAI):生成式预训练模型。
-
DeepSeek:把思考过程展示了出来,
-
等等
但是不要简单的认为大模型就只是AI对话,他的应用方向非常广泛,涵盖
自然语言处理(NLP)、计算机视觉(CV)、语音识别、科学计算、自动驾驶等 领域。
| NLP 语言 AI | 智能对话、代码生成 | chatgpt |
| 计算机视觉(CV) | 图片、检测等等 | ViT |
| AI语言 | 智能语言 | Whisper |
| 智能机器人 | 无人车、机器人 | Tesla FSD |
当然除了这是比较广泛的还有很多领域可以使用AI,现在就是一个AI的时代,就像以前计算机刚开始的时候懂计算机,我感觉哈。。。
其次,我们可以根据AI开发自己的具有个性化的一些功能点,比如初高中刷题的时候,看题解真不一定看的懂,我们就可以通过调教AI,给他输入特点的公式概念和数学概念,他甚至可以把他思考的过程给你输出出来,还有PPT、手抄报、作文等等都可以通过AI来做。再比如在计算机领域,我们在开发应用的时候,还可以借助AI来帮我们实现个性化的推荐,我们只需要给他喂数据进行训练微调,相比于传统的推荐算法更加简单,门槛低了很多了,还有比如可以根据要求给我们生成图片,或者进行图片监测。
比如我实现过一个让大模型给我生成一个文本相似度计算的功能,我们知道当调用大模型的时候,如果问题过于复杂,他的响应时间会很慢,像DeepSeek等,就很慢,我们就可以设置一个缓存的功能,如果文本相似度比较高的话就直接返回缓存就可以了,当然这个功能比较有限,只适合于小规模的对话形式,对于大规模的问答来说,就显得比较鸡肋了,命中率很低,当时作为学习确实也能降低一点token的计算费用嘛。。
2. 关键概念解析
(1) 提示词(Prompt)
像我们在平时使用别人的AI对话模型时,豆包、deepseek、千问等等,如果要让他写一个算法,我们直接把题目复制过去的话,他回答就不一定是对,甚至大部分都不是对的,最多提供一个思路,还需要我们自己去调,但是我们可以再给他【输入格式】【输出格式】【最优解】【Java语言】【C++语言】【更多的测试用例让他自我验证】【指定类名,方法名,变量名】甚至还可以指定版本。再举个例子,我们需要从很多数据中进行筛选,就是一个简单的数据清洗的过程,引导模型的数据输出格式和过滤要求,以及一些原始数据就能够帮我们减少失误的概率。等等。
-
定义:用户输入给模型的指令或问题,用于引导模型生成预期输出。
-
类型:
-
零样本(Zero-shot):直接提问,如“翻译这句话:Hello”。
-
少样本(Few-shot):提供示例,如“苹果→apple;香蕉→banana;橘子→?”。
-
思维链(Chain-of-Thought):引导模型分步推理,如“步骤1:计算成本;步骤2:...”。
-
-
优化技巧:
-
明确指令(如“用学术风格总结”)。
-
添加角色(如“你是一个资深医生”)。
-
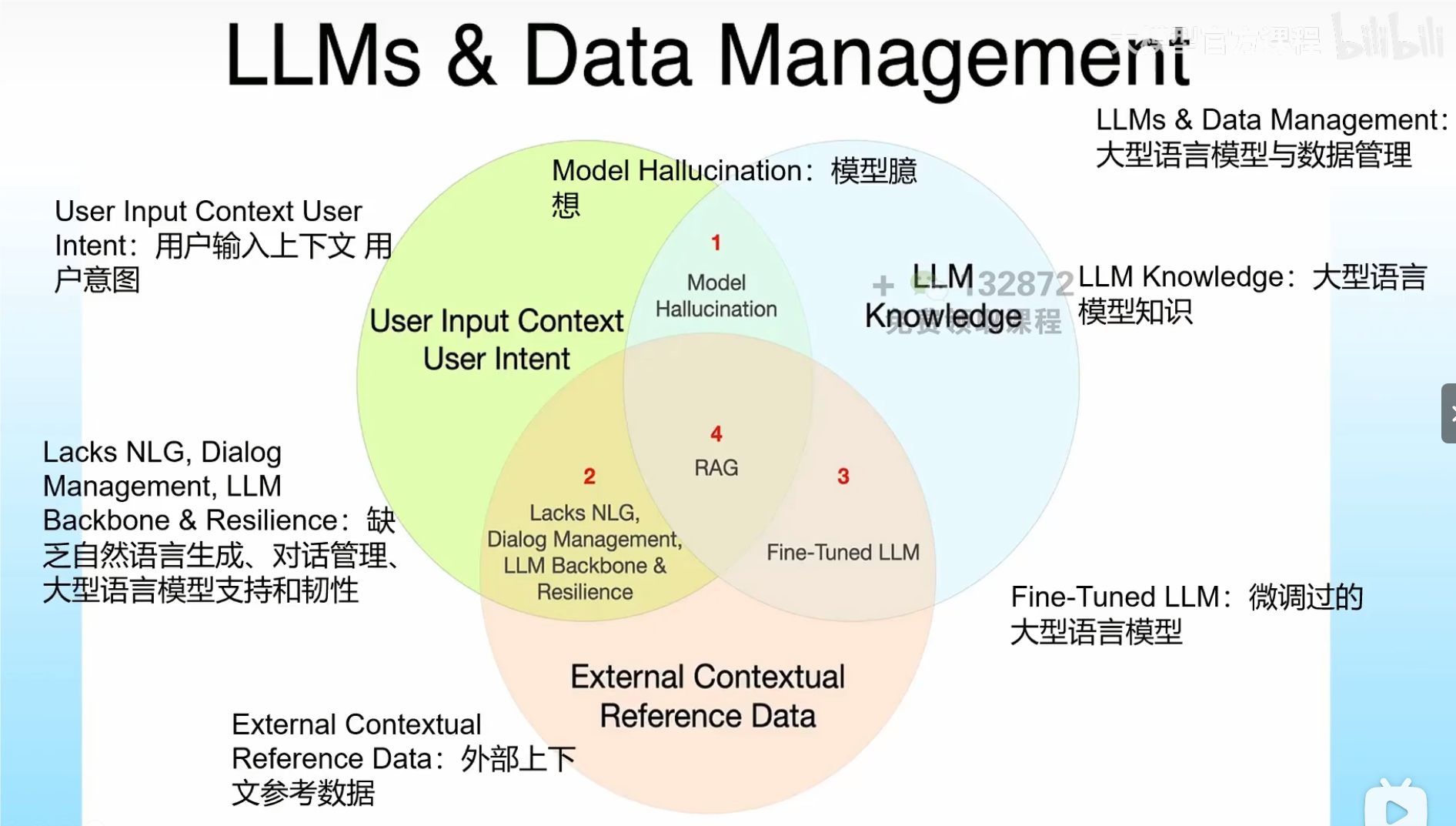
(2) RAG(Retrieval-Augmented Generation)检索增强生成。
-
简单来说:就是让大语言模型在“生成答案”之前,先去找资料(检索)来增强它的知识,再用这些资料来生成更准确的回答。很多大模型是基于公开的资料训练出来的,而很多私域的信息他是没有学习过的,而很多知识是私有的知识,这就需要通过资料的方式增强他原来不熟悉的知识。
-
流程
-
-
首先我们需要做数据准备,把你要用的资料收集好,比如:公司内部文档(PDF、Word、Markdown)、FAQ列表、产品手册等,然后清洗这些数据,比如去掉无关信息、切分成合理的小段。然后把每一小段文本用Embedding模型转成向量,把这些向量存到向量数据库里,比如FAISS、Milvus等。
2、检索查询,当用户提问时,先用相同的Embedding模型把问题也转成向量。然后在向量数据库里用向量相似度搜索,找出最相关的几段资料(比如Top 5)。这些找到的内容就是上下文增强材料。
3、生成回答,紧接着,就可以把用户的问题 + 检索到的资料一起,作为Prompt发给大语言模型(LLM)。 这样可以保证模型只在资料范围内生成答案,降低幻觉。
-
-
优势:
-
解决模型“幻觉”问题(生成虚假信息)。
-
支持动态更新知识(无需重新训练模型)。
-
-
应用:客服系统、医疗问答。
(3) 微调(Fine-tuning)
-
定义:在预训练大模型基础上,用特定领域数据继续训练,使其适应具体任务。
-
方法:
-
全参数微调:更新所有参数,资源消耗大。
-
LoRA(低秩适应):仅训练少量低秩矩阵,高效且轻量。
-
-
应用场景:
-
法律、医疗等专业领域模型定制。
-
风格化文本生成(如莎士比亚风格)。
-
(4) 知识蒸馏(Knowledge Distillation)
-
定义:将大模型(教师模型)的知识“压缩”到小模型(学生模型)中,保持性能的同时减少计算资源需求。
-
技术:
-
软标签(Soft Labels):教师模型输出的概率分布作为监督信号。
-
中间层匹配:对齐教师和学生模型的中间表示。
-
-
应用:移动端部署、边缘计算。
(5) Agent(智能体)
-
定义:具备自主决策能力的AI系统,可调用工具、与环境交互、完成多步任务。
-
核心能力:
-
工具使用:调用搜索引擎、API等。
-
记忆:保留对话历史或任务状态。
-
规划:拆解复杂任务(如“订机票→选酒店”)。
-
-
示例:
-
AutoGPT:自主完成用户目标。
-
ChatGPT Plugins:通过插件扩展功能。
-
(6) AIGC(AI-Generated Content)
-
定义:利用AI生成文本、图像、音频、视频等内容的技术。
-
应用场景:
-
文本:新闻写作、代码生成(GitHub Copilot)。
-
图像:Stable Diffusion、DALL·E。
-
视频:Runway ML生成动态内容。
-
-
伦理问题:
-
版权争议(训练数据来源)。
-
虚假信息(Deepfake)。
-
3. 延伸问题:幻觉(Hallucination)
大模型的“幻觉”指的是 生成很多似合理但实际上错误或虚假的信息。
定义
模型生成与输入无关或事实错误的虚假信息,例如:
-
捏造不存在的论文引用。
-
提供错误的历史事件日期。
原因
-
训练数据噪声:模型学习到错误关联。训练数据本身可能包含 错误信息、不完整数据、偏见信息,导致模型学到不真实的内容。以及训练数据可能过时。
-
概率生成机制:模型倾向于生成“流畅但不准确”的内容。
-
缺乏实时知识:无法获取训练数据之外的信息。
-
语言模型的“填空”机制,Transformer 语言模型本质上是一个 “填空预测器”,它是根据概率预测来选择下一个输出的词,而不是在“思考”正确答案。
解决方案
1、RAG,通过RAG的方式,让大模型在回答问题之前先检索真实数据,再让模型进行回答
2、Fine-tuning,即微调,通过微调的方式,给模型学习专业领域的知识,让他更好的回答,就是让大模型会使用工具的方案,联网查询、帮你操作本地文件、帮你调外部服务等待,不止Function Call,MCP、A2A都是可以让大模型更好的使用工具的技术方案。
3、限制AI的回答,比如在提示词中告诉他如果你不知道,直接就回答不知道
4、通过标注和反馈不断优化模型。并把反馈可以给到模型让模型调整。
5、让同一个模型多次生成同一个内容的答案,然后选择一个最终版本。
6、在问题回答之后,让 AI 自己检查自己的答案,并标记不确定的部分。
7、联网, 在 AI 生成答案之前,先通过网络查询最新数据。
8、 让 AI先写下推理过程,再得出最终结论,而不是直接给出答案。
4. 其他重要概念
(1) 多模态大模型
-
定义:同时处理文本、图像、音频等多种输入输出的模型(如GPT-4V、Flamingo)。
-
应用:医疗影像分析、跨模态搜索。
(2) 对齐(Alignment)
-
目标:使模型行为符合人类价值观(如无害、诚实)。
-
方法:
-
RLHF(人类反馈强化学习):通过人类评分优化模型。
-
宪法AI:预设伦理规则约束输出。
-
(3) 长上下文窗口
-
挑战:传统Transformer的注意力机制复杂度随上下文长度平方增长。
-
优化技术:
-
滑动窗口注意力(如Longformer)。
-
稀疏注意力(如GPT-4的128K上下文支持)。
-
以上有部分是AI生成的,但是我改了很多,AI答的不太好,太笼统了不像人话。
我对大模型的认识也比较浅显哈。。欢迎大家指正。