线性回归模型的参数估计
本文是实验设计与分析(第6版,Montgomery著傅珏生译)第10章拟合回归模型第10.3节的python解决方案。本文尽量避免重复书中的理论,着于提供python解决方案,并与原书的运算结果进行对比。您可以从Detail 下载实验设计与分析(第6版,Montgomery著傅珏生译)电子版。本文假定您已具备python基础,如果您还没有python的基础,可以从Detail 下载相关资料进行学习。
很多问题中,有两个或多个变量是相关的,我们想要建立模型并探索这些关系。例如,在化工工艺中,产品的产率和运行温度有关。化学工程师想要建立产率和温度的模型,并用这一模型进行预测、过程优化和过程控制。
一般地,设有一个因变量或响应y,它依赖于k个自变量或回归变量,例如x1,x2,···,xk。这些变量之间的关系可以用一个称为回归模型的数学模型来刻画。它拟合一组样本数据。在有些场合,实验者知道y和x1,x2,···,xk之间真实函数关系的精确表达式,比方说,y=ɸ(x1,
x2,··,xk)。但是,大多数情况下,真实的函数关系是末知的,实验者要选取一个合适的函数形式来逼近ɸ。低阶的多项式模型是广为应用的逼近函数。
在实验设计与回归分析之间有强烈的相互影响。本书始终强调以经验模型定量地表示实验结果的重要性,这将使模型易于理解、解释和实现。回归模型是它的基础。在许多场合,我们己经给出了描述实验结果的回归模型。本章将介绍有关拟合这些模型的一些内容。关于回归的更完整的叙述见Montgomery,,Peck,and Vining(2001)以及Myers(1990)。
回归分析常用于分析无计则实验所得的数据,例如,观测不可控现象所得的数据或历史记录。回归分析在出现某些间题的设计过的实验中也是很有用的。
多元线性回归模型中,通常用最小二乘法来估计回归系数。设有n>k个响应的观测值,比方说,y1,y2,…,yn与每一个观测响应yi对应,每一个回归变量也有相应的观测值,记xij表示变量xj的第i个观测值或水平。数据如表10.1所示,假定模型中误差项ε满足E(ε)=0,V(ε)=s2,且{εi}是不相关的随机变量。
可以用表10.1中列出的观测值写出模型
![]()
1.估计s2(略)
2.估计量的性质(略)
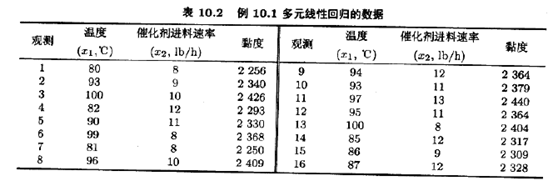
例10.1聚合物的黏度(y)和两个过程变量--反应温度(x1)与催化剂进料速率(x2)--的16个试验的观测值如表10.2所示。我们将用这些数据拟合多元线性模型
![]()
X矩阵和向量分别是
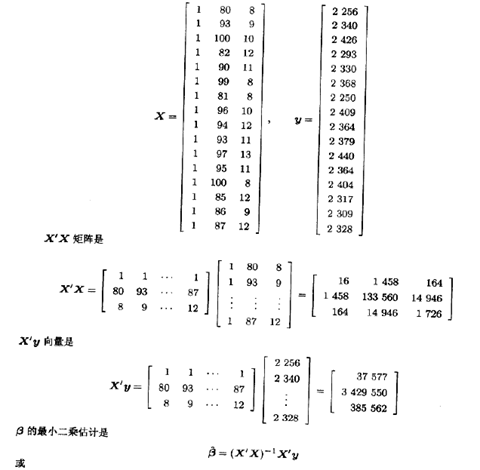
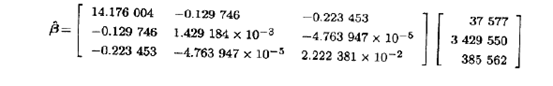

回归系数保留两位小数时的最小二乘拟合是
![]()
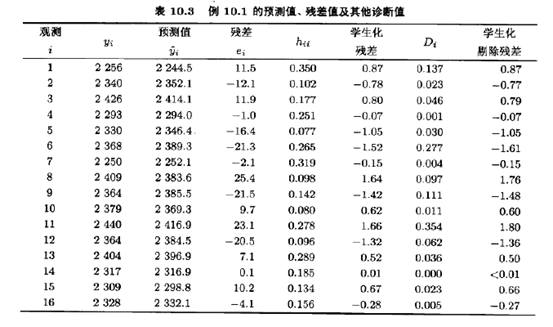
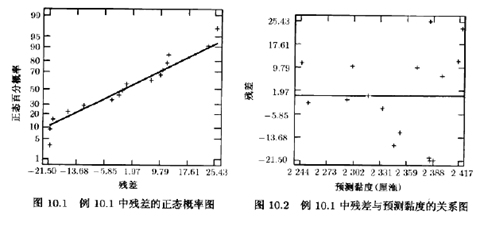
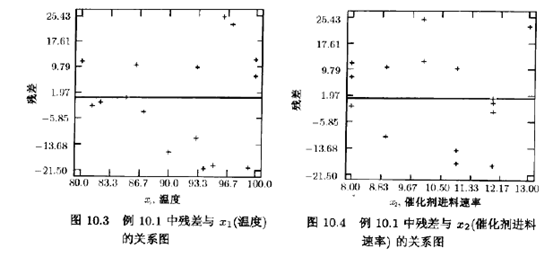
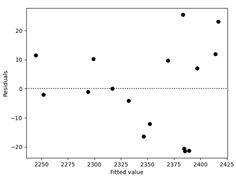
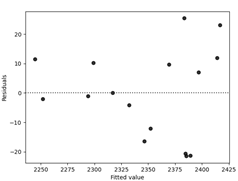
表10.3的前3列分别表示实际观测值yi、预测值或拟合值ˆyi和残差值。图10.1是残差的正态概率图,残差与预测值ˆyi的关系图和残差与两个变量x1和x2的关系图分别显示在图10.2,图10.3和图10.4中,正如在设计过的实验中一样,残差图是回归模型中不可或缺的都分,这些图形表明观测到的黏度值的方差随着黏度的增大而增加。图10.3表明黏度的变异性随着温度的增加而增加。
3.使用计算机
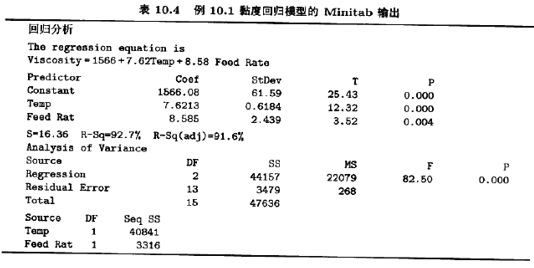
几平所有统计软件包都可以进行回归模型拟合。表10.4列出了用Minitab软件拟合例10.1中黏度回归模型时所获得的部分输出结果。在这个物出中有许多量我们已经熟悉了,因为它们的含义类似于在设计过的实验中计算机输出的分析结果,在本书前面的章节中,我们已看到许多计算机输出结果,在后面的章节中我们物详细讨论表10.4中方差分析和t检验的信息,并将指出如何正确计算这些量
import statsmodels.formula.api as smf
import pandas as pd
import statsmodels.api as sm
from sklearn import linear_model
import seaborn as sns
import matplotlib.pyplot as plt
Viscosity=[2256,2340,2426,2293,2330,2368,2250,2409,2364,2379,2440,2364,2404,2317,2309,2328]
Temperature=[80,93,100,82,90,99,81,96,94,93,97,95,100,85,86,87]
Rate =[8,9,10,12,11,8,8,10,12,11,13,11,8,12,9,12]
visc = {"Viscosity":Viscosity,"Temperature":Temperature,"Rate":Rate}
df =pd.DataFrame(visc)
#model = smf.ols('df.Viscosity ~ C(df.Temperature) + C(df.Rate)', data=df).fit()
model = smf.ols('df.Viscosity ~df.Temperature +df.Rate', data=df).fit()
#model = smf.ols('df.Viscosity ~ df.Temperature + df.Rate + df.Temperature:df.Rate', data=df).fit()
print(model.summary2())
>>> print(model.summary2())
C:\Users\Administrator\AppData\Local\Programs\Python\Python311\Lib\site-packages\scipy\stats\_stats_py.py:1736: UserWarning: kurtosistest only valid for n>=20 ... continuing anyway, n=16
warnings.warn("kurtosistest only valid for n>=20 ... continuing "
Results: Ordinary least squares
====================================================================
Model: OLS Adj. R-squared: 0.916
Dependent Variable: df.Viscosity AIC: 137.5159
Date: 2024-03-14 09:43 BIC: 139.8337
No. Observations: 16 Log-Likelihood: -65.758
Df Model: 2 F-statistic: 82.50
Df Residuals: 13 Prob (F-statistic): 4.10e-08
R-squared: 0.927 Scale: 267.60
--------------------------------------------------------------------
Coef. Std.Err. t P>|t| [0.025 0.975]
--------------------------------------------------------------------
Intercept 1566.0778 61.5918 25.4267 0.0000 1433.0167 1699.1388
df.Temperature 7.6213 0.6184 12.3236 0.0000 6.2853 8.9573
df.Rate 8.5848 2.4387 3.5203 0.0038 3.3164 13.8533
--------------------------------------------------------------------
Omnibus: 1.215 Durbin-Watson: 2.607
Prob(Omnibus): 0.545 Jarque-Bera (JB): 0.779
Skew: -0.004 Prob(JB): 0.677
Kurtosis: 1.919 Condition No.: 1385
====================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors
is correctly specified.
[2] The condition number is large, 1.38e+03. This might indicate
that there are strong multicollinearity or other numerical
print(model.params)
>>> print(model.params)
Intercept 1566.077771
df.Temperature 7.621290
df.Rate 8.584846
dtype: float64
anovatable=sm.stats.anova_lm(model)
>>> anovatable
df sum_sq mean_sq F PR(>F)
df.Temperature 1.0 40840.842466 40840.842466 152.616757 1.473645e-08
df.Rate 1.0 3316.244074 3316.244074 12.392360 3.764806e-03
Residual 13.0 3478.850960 267.603920 NaN NaN
ax = sns.residplot(x=model.predict(df.Temperature), y=df.Viscosity, lowess=False, color='black')
ax.set_xlabel('Fitted value')
ax.set_ylabel('Residuals')
plt.show()
ax = sns.residplot(x=model.predict(df.Rate), y=df.Viscosity, lowess=False, color='black')
ax.set_xlabel('Fitted value')
ax.set_ylabel('Residuals')
plt.show()
#from sklearn import linear_model
# 创造线性回归对象
#OLS = linear_model.LinearRegression(fit_intercept=True) # 训练模型 OLS.fit(X, Y)
4.在设计过的实验中拟合模型
我们常常用回归模型以定量的方式表示设计过的实验的结果。下面我们给出一个完整的例子以说明如何来做。在这个例子后面还有3个简单的例子,用于说明在设计过的实验中回归分析的其他用途。
例10.2 23析因设计的回归分析
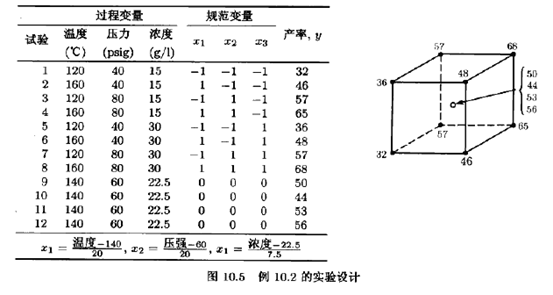
一位化学工程师研究一个过程的产率,考察3个过程变量:温度、压强以及催化剂浓度。每个变量取低与高两个水平,工程师决定进行有4个中心点的23设计的实验。设计与所得的产率如图10.5所示,这里我们同时列出了设计因子的自然水平,以及常在2k析因设计中表示因子水平的+1,-1规范变量。
设工程师决定拟合只有主效应的模型,即
![]()
对此模型,X矩阵和y向量是
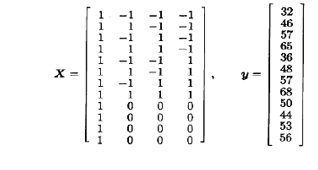
易得
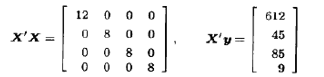
因为X’X是对角矩阵,其逆也是对角的,回归系数的最小二乘估计是

拟合的回归模型是
![]()
与我们在许多场合已使用过的相同,这些回归系数和通常的23设计分析法求得的效应估计量有密切的关系。例如,温度的效应〔参阅图10.5)是
![]()
注意x1的回归系数是
(11.25)/2=5.625
也就是说,回归系数正好是通常效应估计的1/2。这一点对于2k设计总是正确的。如上所述,在第6章至第8章中,对好几个二水平实验,我们都用了这一结果来得到回归模型、拟合值以及残差。此例表明,由2k设计所得的效应估计量是最小二乘估计。
在例10.2中,因为X‘X是对角矩阵,逆矩阵容易求得。这一点从直观上看有优越性,不仅因为计算简单,而且因为所有回归系数的估计量是不相关的,即,Cov(ˆβi,ˆβj)=0。在收集数据之前,如果能够选择x变量的水平的话,我们就会设计实验使得X‘X为对角矩阵。
在实践中,这一点相对容易做到。我们知道,X‘X的对角线之外的元素是X列的叉积之和。因此,必须使X的列间的内积等于零,也就是说,这些列必须是正交的(orthogonal)。为拟合回归棋型而进行的实验设计,若具正交性,则称它为正交设计。一般说来,2k析因设计是拟合多元线性回归模型的正交设计。
在设计过的实验中出现某些问题时,回归方法也是十分有用的。这将在下面两个例子中给予说明。
#P327 例10.2
import statsmodels.formula.api as smf
import pandas as pd
import statsmodels.api as sm
from sklearn import linear_model
import seaborn as sns
import matplotlib.pyplot as plt
Yield =[32, 46, 57,65, 36, 48, 57, 68, 50, 44, 53, 56]
Temp=[120,160,120,160,120,160,120,160,140, 140, 140, 140]
Pressure=[40, 40, 80, 80, 40, 40, 80, 80, 60, 60, 60, 60]
Conc=[15, 15, 15, 15, 30, 30, 30, 30, 22.5,22.5,22.5,22.5]
data= {"Yield":Yield,"Temperature":Temp,"Pressure":Pressure,"Conc":Conc}
df =pd.DataFrame(data)
model = smf.ols('df.Yield ~df.Temperature +df.Pressure+df.Conc', data=df).fit()
print(model.summary2())
print(model.params)
anovatable=sm.stats.anova_lm(model)
ax = sns.residplot(x=model.predict(df.Temperature), y=df.Viscosity, lowess=False, color='black')
ax.set_xlabel('Fitted value')
ax.set_ylabel('Residuals')
plt.show()
ax = sns.residplot(x=model.predict(df.Rate), y=df.Viscosity, lowess=False, color='black')
ax.set_xlabel('Fitted value')
ax.set_ylabel('Residuals')
plt.show()
Yield=[32, 46, 57,65, 36, 48, 57, 68, 50, 44, 53, 56]
Temp=[-1,1,-1,1,-1,1,-1,1,0, 0, 0, 0]
Pressure=[-1, -1, 1, 1, -1, -1, 1, 1, 0, 0, 0, 0]
Conc=[-1,-1, -1, -1, 1, 1, 1, 1, 0,0,0,0]
data= {"Yield":Yield,"Temperature":Temp,"Pressure":Pressure,"Conc":Conc}
df =pd.DataFrame(data)
#model = smf.ols('df.Viscosity ~ C(df.Temperature) + C(df.Rate)', data=df).fit()
model = smf.ols('df.Yield ~df.Temperature +df.Pressure+df.Conc', data=df).fit()
#model = smf.ols('df.Yield ~pd.get_dummies(df.Temperature) +pd.get_dummies(df.Pressure)+pd.get_dummies(df.Conc)', data=df).fit()
#model = smf.ols('df.Viscosity ~ df.Temperature + df.Rate + df.Temperature:df.Rate', data=df).fit()
print(model.summary2())
print(model.params)
anovatable=sm.stats.anova_lm(model)
ax = sns.residplot(x=model.predict(df.Temperature), y=df.Viscosity, lowess=False, color='black')
ax.set_xlabel('Fitted value')
ax.set_ylabel('Residuals')
plt.show()
ax = sns.residplot(x=model.predict(df.Rate), y=df.Viscosity, lowess=False, color='black')
ax.set_xlabel('Fitted value')
ax.set_ylabel('Residuals')
plt.show()
>>> print(model.summary2())
C:\Users\Administrator\AppData\Local\Programs\Python\Python311\Lib\site-packages\scipy\stats\_stats_py.py:1736: UserWarning: kurtosistest only valid for n>=20 ... continuing anyway, n=12
warnings.warn("kurtosistest only valid for n>=20 ... continuing "
Results: Ordinary least squares
=================================================================
Model: OLS Adj. R-squared: 0.902
Dependent Variable: df.Yield AIC: 66.1833
Date: 2024-03-14 10:18 BIC: 68.1229
No. Observations: 12 Log-Likelihood: -29.092
Df Model: 3 F-statistic: 34.70
Df Residuals: 8 Prob (F-statistic): 6.20e-05
R-squared: 0.929 Scale: 11.203
-----------------------------------------------------------------
Coef. Std.Err. t P>|t| [0.025 0.975]
-----------------------------------------------------------------
Intercept 51.0000 0.9662 52.7827 0.0000 48.7719 53.2281
df.Temperature 5.6250 1.1834 4.7533 0.0014 2.8961 8.3539
df.Pressure 10.6250 1.1834 8.9785 0.0000 7.8961 13.3539
df.Conc 1.1250 1.1834 0.9507 0.3696 -1.6039 3.8539
-----------------------------------------------------------------
Omnibus: 6.492 Durbin-Watson: 1.659
Prob(Omnibus): 0.039 Jarque-Bera (JB): 2.670
Skew: -0.837 Prob(JB): 0.263
Kurtosis: 4.593 Condition No.: 1
=================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the
errors is correctly specified.
>>> print(model.params)
Intercept 51.000
df.Temperature 5.625
df.Pressure 10.625
df.Conc 1.125
dtype: float64
>>> anovatable=sm.stats.anova_lm(model)
>>> anovatable
df sum_sq mean_sq F PR(>F)
df.Temperature 1.0 253.125 253.125000 22.594142 0.001439
df.Pressure 1.0 903.125 903.125000 80.613668 0.000019
df.Conc 1.0 10.125 10.125000 0.903766 0.369607
Residual 8.0 89.625 11.203125 NaN NaN
例10.3有缺失观值的23析因设计
考虑例10.2的有4个中心点的23析因设计,假设完成实验后,缺失了各变量都是高水平的那个试验(图105中的第8号试验)。这可能由多种原因造成,比如测量系统产生一个错误的读数,因子水平组合是不可能的搭配,实验单元可能有危险性,等等。
我们将用其余的11个数据拟合主效应模型
![]()
此时X矩阵和y向量是

为估计模型参数,计算
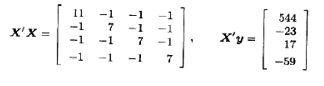
得

因此,拟合的模型是
![]()
将此模型与例10.2中由所有12个数据所得的模型比较。回归系数非常相似
因为回归系数与因子效应有密切的关系,我们的结论并未受到缺失观测值的严重影响。但是,由于(X‘X)与其逆不再是对角阵,效应的估计量也不再正交。
例10.3
Yield=[32, 46, 57, 65, 36, 48, 57, 50, 44, 53, 56]
Temp=[-1, 1 , -1, 1, -1, 1, -1, 0, 0, 0, 0]
Pressure=[-1, -1, 1, 1, -1, -1, 1, 0, 0, 0, 0]
Conc=[-1, -1, -1, -1, 1, 1, 1, 0, 0, 0, 0]
data= {"Yield":Yield,"Temperature":Temp,"Pressure":Pressure,"Conc":Conc}
df =pd.DataFrame(data)
#model = smf.ols('df.Viscosity ~ C(df.Temperature) + C(df.Rate)', data=df).fit()
model = smf.ols('df.Yield ~df.Temperature +df.Pressure+df.Conc', data=df).fit()
#model = smf.ols('df.Yield ~pd.get_dummies(df.Temperature) +pd.get_dummies(df.Pressure)+pd.get_dummies(df.Conc)', data=df).fit()
#model = smf.ols('df.Viscosity ~ df.Temperature + df.Rate + df.Temperature:df.Rate', data=df).fit()
print(model.summary2())
print(model.params)
anovatable=sm.stats.anova_lm(model)
ax = sns.residplot(x=model.predict(df.Temperature), y=df.Viscosity, lowess=False, color='black')
ax.set_xlabel('Fitted value')
ax.set_ylabel('Residuals')
plt.show()
ax = sns.residplot(x=model.predict(df.Rate), y=df.Viscosity, lowess=False, color='black')
ax.set_xlabel('Fitted value')
ax.set_ylabel('Residuals')
plt.show()
>>> print(model.summary2())
C:\Users\Administrator\AppData\Local\Programs\Python\Python311\Lib\site-packages\scipy\stats\_stats_py.py:1736: UserWarning: kurtosistest only valid for n>=20 ... continuing anyway, n=11
warnings.warn("kurtosistest only valid for n>=20 ... continuing "
Results: Ordinary least squares
=================================================================
Model: OLS Adj. R-squared: 0.864
Dependent Variable: df.Yield AIC: 62.2599
Date: 2024-03-14 10:23 BIC: 63.8514
No. Observations: 11 Log-Likelihood: -27.130
Df Model: 3 F-statistic: 22.23
Df Residuals: 7 Prob (F-statistic): 0.000592
R-squared: 0.905 Scale: 12.766
-----------------------------------------------------------------
Coef. Std.Err. t P>|t| [0.025 0.975]
-----------------------------------------------------------------
Intercept 51.0577 1.1079 46.0832 0.0000 48.4378 53.6776
df.Temperature 5.7115 1.4015 4.0754 0.0047 2.3976 9.0255
df.Pressure 10.7115 1.4015 7.6432 0.0001 7.3976 14.0255
df.Conc 1.2115 1.4015 0.8645 0.4160 -2.1024 4.5255
-----------------------------------------------------------------
Omnibus: 5.936 Durbin-Watson: 1.671
Prob(Omnibus): 0.051 Jarque-Bera (JB): 2.117
Skew: -0.855 Prob(JB): 0.347
Kurtosis: 4.302 Condition No.: 2
=================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the
errors is correctly specified.
>>> print(model.params)
Intercept 51.057692
df.Temperature 5.711538
df.Pressure 10.711538
df.Conc 1.211538
dtype: float64
例10.4设计因子水平不第确
在进行一个设计过的实验时,有时难以达到成保特设计所需的精确因子水平,小的偏差并不重要,但对大的偏差要多加关注,在实验者不能得到所需因子水平的设计过的实验中,回归方法很有用。
为了说明这个问题,表10.5中的实验是例10.2的23设计的一个变形,这里,许多试验组合并不是设计所指定的真正水平的组合,温度变量的控制似乎最为困难。
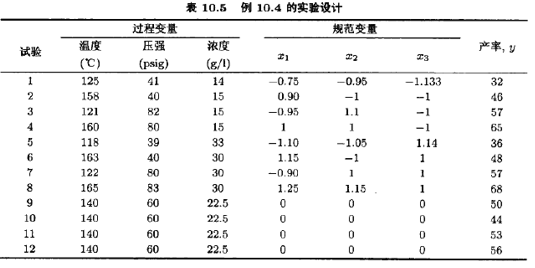
我们将拟合主效应模型
![]()
X矩阵和向量是
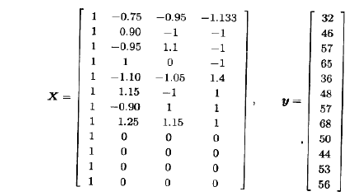
为估计模型参数,计算

得

回归系数保留两位小数,拟合的模型是
![]()
将此棋型与例10.2中的原模型比较,原模型中因子水平是设计指定的真正水平,两者之间只有非常小的差异。这个实验结果的实际解释不会因为实验者不能精确达到所要的因子水平面受到严重影响。
#例10.4
Yield=[32, 46, 57,65, 36, 48, 57, 68, 50, 44, 53, 56]
Temp=[-0.75,0.90,-0.95,1,-1.10,1.15,-0.90,1.25,0, 0, 0, 0]
Pressure=[-0.95, -1, 1.1, 1, -1.05, -1, 1, 1.15, 0, 0, 0, 0]
Conc=[-1.133,-1, -1, -1, 1.14, 1, 1, 1, 0,0,0,0]
data= {"Yield":Yield,"Temperature":Temp,"Pressure":Pressure,"Conc":Conc}
df =pd.DataFrame(data)
#model = smf.ols('df.Viscosity ~ C(df.Temperature) + C(df.Rate)', data=df).fit()
model = smf.ols('df.Yield ~df.Temperature +df.Pressure+df.Conc', data=df).fit()
#model = smf.ols('df.Yield ~pd.get_dummies(df.Temperature) +pd.get_dummies(df.Pressure)+pd.get_dummies(df.Conc)', data=df).fit()
#model = smf.ols('df.Viscosity ~ df.Temperature + df.Rate + df.Temperature:df.Rate', data=df).fit()
print(model.summary2())
print(model.params)
anovatable=sm.stats.anova_lm(model)
ax = sns.residplot(x=model.predict(df.Temperature), y=df.Viscosity, lowess=False, color='black')
ax.set_xlabel('Fitted value')
ax.set_ylabel('Residuals')
plt.show()
ax = sns.residplot(x=model.predict(df.Rate), y=df.Viscosity, lowess=False, color='black')
ax.set_xlabel('Fitted value')
ax.set_ylabel('Residuals')
plt.show()
>>> print(model.summary2())
C:\Users\Administrator\AppData\Local\Programs\Python\Python311\Lib\site-packages\scipy\stats\_stats_py.py:1736: UserWarning: kurtosistest only valid for n>=20 ... continuing anyway, n=12
warnings.warn("kurtosistest only valid for n>=20 ... continuing "
Results: Ordinary least squares
=================================================================
Model: OLS Adj. R-squared: 0.888
Dependent Variable: df.Yield AIC: 67.8081
Date: 2024-03-14 10:26 BIC: 69.7477
No. Observations: 12 Log-Likelihood: -29.904
Df Model: 3 F-statistic: 29.97
Df Residuals: 8 Prob (F-statistic): 0.000106
R-squared: 0.918 Scale: 12.828
-----------------------------------------------------------------
Coef. Std.Err. t P>|t| [0.025 0.975]
-----------------------------------------------------------------
Intercept 50.5198 1.0361 48.7609 0.0000 48.1306 52.9089
df.Temperature 5.3715 1.2556 4.2782 0.0027 2.4762 8.2668
df.Pressure 10.1297 1.2270 8.2558 0.0000 7.3003 12.9591
df.Conc 1.0909 1.2227 0.8922 0.3984 -1.7288 3.9105
-----------------------------------------------------------------
Omnibus: 2.093 Durbin-Watson: 1.614
Prob(Omnibus): 0.351 Jarque-Bera (JB): 0.517
Skew: -0.475 Prob(JB): 0.772
Kurtosis: 3.366 Condition No.: 1
=================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the
errors is correctly specified.
>>> print(model.params)
Intercept 50.519754
df.Temperature 5.371511
df.Pressure 10.129659
df.Conc 1.090855
dtype: float64
例10,5在分式析因设计中,分离有别名的交互作用
从第8章中可以看到,用折叠法可以在一个分式析因设计中分离有别名的交互作用。对一个分辨度为III的设计,可以构造一个完全折叠没计,其第二个分式设计是对原分式设计取反。这个组合的设计可用于分离所有与两因子交互作用有别名的主效应。
使用完全折叠的难点在于,它要求第二组试验的个数与原来的分式设计完全相同。为了分离某些有别名的交互作用,可以在原分式设计的基础上增加几个试验,增如试验的个数少于全折叠所要求的。部分折叠技术可以用于解决这个问题。利用回归方法可以方便地看到部分折叠技术是如何起作用的,有时甚至可以找到更有效的折叠设计。
例如,假设我们要进行24-1IV设计。表8-3列出了这个设计的主分式设计,在这个设计中,I=ABCD。假设在获得前8个试验数据后,最大的效应是A,B,C,D(忽略别名是这些主效应的3因子交互作用)和AB+CD别名链。虽然可以忽略另两个别名链,但显然AB与CD中至少有一个偏大。为发现哪个交互作用是重要的,我们当然可以做另一组替补的分式设计,这需再做8个试验。于是,可用所有16个试验估计主效应和2因子交互作用。另一种方法是进行包括4个附加试验的部分折叠设计。
可以用少于4个试验来分离别名AB和CD.假设我们希望拟合模型
![]()
其中x1,x2,x3,x4是表示A,B,C,D的规范变量。用表8-3中的设计,此棋型的X矩阵是

为了便于理解,我们在各列的上方写出了变量名。注意到x1x2列与x3x4列相同(如所预期的,因为AB或x1x2是CD或x3x4的别名),这意味着X的各列之间不独立。因此,我们不能同时估计模型中的β12和β34。然而,假设在替补的分式设计中把x1=-1,x2=-1,x3=-1,x4=1这个试验加入到原来的8个试验中,则模型中的X矩阵变为

注意到,现在列x1x2与x3x4不再相同,这祥我们就能够拟合同时含有交互作用工x1x2(AB)与x3x4(CD)的回归模型。可归系数的大小给出了交互作用重要性的信息。
尽管添加一个试验就可以分离交互作用AB和CD。但这种方法有一个峡点,假设在前8个试验与稍后添加的试验之间存在一个时间效应(或一个区组效应)。在X矩阵中加上区组列,得

我们已假定在前8个试验中区组因子取低水平“-”,在第9个试验中区组因子取高水平“+”。可以看到,每一列与区组列的叉积之和不等于零,这意味着区组对处理不再是正交的,或者说,现在区组效应影响模型回归系数的估计。为使区组正交化,必须添知偶数次试验,比如,4个试验

可以分离AB和CD,并得到正交区组(用与前面类似的方法写出X矩阵,就可以看到此结论)。由试验所需次数,这等价于都分折叠。
通常直接检查由分式析因设计得到的简化模型的X矩阵,并决定为了分离我们感兴趣的有别名的交互作用,在原设计中应该增如哪些试验。此外,可以用本章稍后给出的回归模型的结果来评估特殊增大策略的影响。还可以用基于计算机的方法构造用于分离有别名的效应的增大设计(参见第8章的补充材料)。第11章将讨论计算机生成的设计。