C++中的string(1)简单介绍string中的接口用法以及注意事项
文章目录
- C++中的string(1)
- 前言
- Part1(补充)
- **1. C++ 标准库(Standard Library)**
- **2. C++ 标准模板库(STL, Standard Template Library)**
- **3. 关键区别**
- Part2(string)
- **1. 概述**
- **2. 函数用法**
- 1. 构造函数:
- 2. 析构函数(跳过)
- 3. 赋值重载
- **1. 拷贝赋值**
- **2. C 风格字符串赋值**
- **3. 字符赋值**
- 4. 元素访问
- 1. operator[]
- 1. 非 `const` 版本
- 2. `const` 版本
- 2. at访问
- 1. 函数原型
- 2. 核心特点:越界检查
- 3. 示例代码
- 4. 与 `operator[]` 的对比
- 5. 容量函数
- 1. std::[string](https://legacy.cplusplus.com/reference/string/string/)::size
- 函数定义
- 功能
- 与 `length` 函数的关系
- 注意事项
- 示例
- 2. std::[string](https://legacy.cplusplus.com/reference/string/string/)::length
- 3. std::[string](https://legacy.cplusplus.com/reference/string/string/)::max_size
- 函数定义
- 功能
- 与其他函数的区别
- 注意事项
- 4. std::[string](https://legacy.cplusplus.com/reference/string/string/)::resize
- 1. `void resize(size_t n);`
- 2. `void resize(size_t n, char c);`
- 注意事项
- 5. std::[string](https://legacy.cplusplus.com/reference/string/string/)::capacity
- 函数定义
- 核心作用
- 示例
- 注意事项
- 6. std::[string](https://legacy.cplusplus.com/reference/string/string/)::reserve
- 核心作用
- 参数说明
- 示例
- 注意事项
- 7. std::[string](https://legacy.cplusplus.com/reference/string/string/)::clear
- 8. std::[string](https://legacy.cplusplus.com/reference/string/string/)::empty
- 6. 迭代器
- 1. `begin()` 和 `end()`
- 2. `rbegin()` 和 `rend()`
- 3. `cbegin()` 和 `cend()`(C++11 引入)
- 4. `crbegin()` 和 `crend()`(C++11 引入)
- 总结:
- 一、迭代器的作用
- 二、迭代器存在的原因
- 三、迭代器可理解为
- 7. 修改功能的接口
- 1. std::[string](https://legacy.cplusplus.com/reference/string/string/)::operator+=
- 2. std::[string](https://legacy.cplusplus.com/reference/string/string/)::append
- 3. std::[string](https://legacy.cplusplus.com/reference/string/string/)::push_back
- 4. std::[string](https://legacy.cplusplus.com/reference/string/string/)::assign
- 5. std::[string](https://legacy.cplusplus.com/reference/string/string/)::insert
- 6. std::[string](https://legacy.cplusplus.com/reference/string/string/)::erase
- 7. std::[string](https://legacy.cplusplus.com/reference/string/string/)::replace
- 8. std::[string](https://legacy.cplusplus.com/reference/string/string/)::swap
- 与标准库 `swap` 算法的区别
- 9. std::[string](https://legacy.cplusplus.com/reference/string/string/)::pop_back
- 功能特点
- 注意事项
- 8. 非成员函数重载
- 1. `operator+`(字符串拼接)
- 2. `relational operators`(关系运算符,如 `==`、`<` 等)
- 3. `swap`(交换两个字符串内容)
- 4. `operator>>`(从流中提取字符串)
- 5. `operator<<`(将字符串插入流)
- 6. `getline`(从流中读取一行到字符串)
- 9. 字符串操作
- 1. std::[string](https://legacy.cplusplus.com/reference/string/string/)::data
- 示例
- 注意事项
- 2. std::[string](https://legacy.cplusplus.com/reference/string/string/)::copy
- 功能与参数
- 返回值
- 示例
- 注意事项
- 3. 一坨查找函数find()
- 1. std::[string](https://legacy.cplusplus.com/reference/string/string/)::find
- 2. std::[string](https://legacy.cplusplus.com/reference/string/string/)::rfind
- 注意事项
- 3. std::[string](https://legacy.cplusplus.com/reference/string/string/)::find_first_of
- 注意事项
- 4. std::[string](https://legacy.cplusplus.com/reference/string/string/)::find_last_of
- 5. std::[string](https://legacy.cplusplus.com/reference/string/string/)::find_first_not_of
- 注意事项
- 6. std::[string](https://legacy.cplusplus.com/reference/string/string/)::find_last_not_of
- 总结
C++中的string(1)
前言
这一集, 我们主要介绍C++中的std::string的用法以及相关注意事项, 让大家初步了解一下string.
这一集的重点是: 知道string是个什么东西, 并知道它大概有什么用法, 记住一些常用的用法, 顺便涉猎一些不太常用的用法. 这一集并不会过分涉及string的底层, 等我们讲完这一集, 知道用法之后, 下一集再带大家看底层. 这一集主要是带大家看c++的文档, 去学习string的用法.
需要说明的是,虽然 std::string 出现时间早于 STL(标准模板库),且未被归类为容器类,但它实际上满足序列式容器的所有特性,可视为专用于存储字符的容器。容器本质上是数据结构的一种抽象,用于管理和操作数据集合。(粗俗点说, 就是数据结构, 管理数据的)
而且因为std::string时间出现的比较早, 所以它的设计其实有点可以说是冗余, 有点像新手办事, 想把事情办全乎, 额外做了很多无用功的感觉, 这是一件很正常的事情(第一次总是会紧张的) . 不过我们还是得要好好学习这一部分的东西的.
顺便说一下, 就是, C++ 标准库的很多接口设计具有高度一致性, 而且接口规范非常统一。所以我们现在前期讲string的内容的时候就会详细一些, 带着大家看文档, 我会努力的给大家讲明白, 我们看明白string中的内容, 后面STL的内容理解起来就会快很多, 因为标准库中相同功能的接口(如遍历、查找、修改等)往往遵循一致的命名规范和使用逻辑 (有点像你学了手动挡之后去开自动挡就像喝水一样, 明白吗 ?)
最后再说明一点, 在不同编译器里面, 编译器厂商会根据c++委员会定制的标准编写要求的接口(函数). 也就是说该有的功能都会有, 但是, 不同编译器实现接口的逻辑可能不一样, 也就是底层实现可能略有不同, 这一点大家是要知道的.
Part1(补充)
1. C++ 标准库(Standard Library)
定义:C++ 标准库是 C++ 语言的官方库,包含了一系列标准化的组件、工具和功能,为开发者提供基础编程设施。
范围:
- 核心语言支持:如类型系统、内存管理(
new/delete)、异常处理等。 - C 标准库兼容部分:如
<cstdio>、<cstdlib>等(对应 C 语言的stdio.h、stdlib.h)。 - 字符串处理:
std::string、std::wstring等。 - 容器与算法:包含 STL 的所有组件(见下文)。
- 输入 / 输出流:
std::cout、std::cin、文件操作等。 - 工具库:如时间处理(
<chrono>)、随机数生成(<random>)、正则表达式(<regex>)等。
特点:
- 全面性:覆盖了语言的各个方面,是 C++ 编程的基础。
- 标准化:所有组件都在 ISO C++ 标准中明确定义,保证跨平台一致性。
2. C++ 标准模板库(STL, Standard Template Library)
定义:STL 是 C++ 标准库的一个子集,由 Alexander Stepanov 和 Meng Lee 在 1990 年代开发,后被纳入 C++ 标准。它以模板(Template) 为核心机制,提供了通用的容器、算法和迭代器。
核心组件:
- 容器(Containers):存储数据的类模板,如:
- 序列容器:
vector、list、deque - 关联容器:
map、set、unordered_map - 适配器:
stack、queue、priority_queue
- 序列容器:
- 算法(Algorithms):操作容器的通用函数,如
sort、find、transform等。 - 迭代器(Iterators):遍历容器元素的接口,类似泛型指针。
- 函数对象(Function Objects):支持函数式编程的可调用对象(如
std::less)。
特点:
- 泛型编程:通过模板实现与数据类型无关的通用代码。
- 高复用性:容器和算法可以自由组合,减少重复开发。
- 性能优化:STL 的实现经过高度优化,效率接近手动编写的底层代码。
3. 关键区别
| 维度 | C++ 标准库 | STL(标准模板库) |
|---|---|---|
| 范围 | 包含整个 C++ 官方库(约 60 + 个头文件) | 仅包含容器、算法、迭代器等组件 |
| 历史 | 随 C++ 语言发展逐步完善(始于 1998) | 1990 年代单独开发,后被并入标准库 |
| 核心技术 | 模板、类、函数等多种机制 | 主要基于模板编程 |
| 典型组件 | std::string、iostream、内存管理 | vector、map、sort()、迭代器 |
Part2(string)
1. 概述
std::string 是 C++ 标准库中用于处理可变长度字符串的类,定义于头文件 <string>。它封装了动态字符数组,提供安全、便捷的字符串操作,避免了 C语言 风格字符串(char*)的内存管理问题。string里面封装了一个char类型的字符数组, 而且里面有各种接口(函数)去管理这个字符数组, 大家可以这样理解.
好, 现在大家打开cplusplus.com - The C++ Resources Network这个网址, 我们通过看这个网站中的文档来学习.
两个情况, 一种就是大家点进去就是旧版的, 我们使用旧版网页来学习, 因为旧版方便一些, 而且有搜索功能
第二种就是点进去是新版的, 新版的可以切换成旧版的, 看图:
其次, 刚刚上面给的网站不是官方的, 这个才是: cppreference.com 但是我们学习, 使用上面那个其实也够了.
ok, 大家进到旧版界面之后, 在search搜索框那里搜string, 然后你就能看到string的成员变量类型, 成员函数, 以及非成员函数, 接下来, 我们就要进入到这些函数里面去学习使用方法, 先用起来. (函数其实就是接口, 接口就是函数, 一个意思)
大家仔细看, 其实可以发现, 网站已经把成员函数分了类的, 第一部分的成员函数就是构造函数, 析构函数, 还有赋值重载, 大家可以借助翻译查看单词意思, 不过建议不要全文翻译, 将就的看明白意思就行.
2. 函数用法
1. 构造函数:
大家通过这张图了解一下这个页面咋用先:
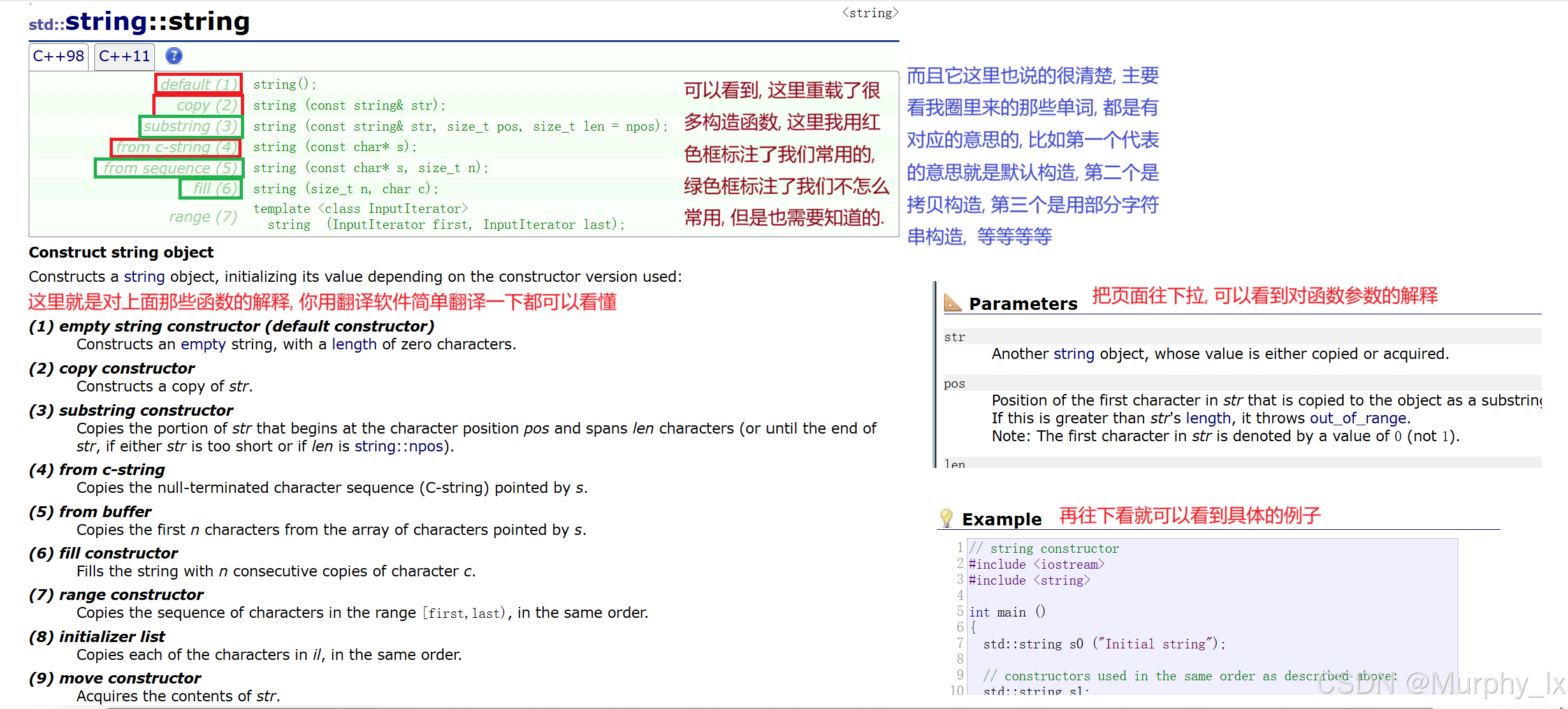
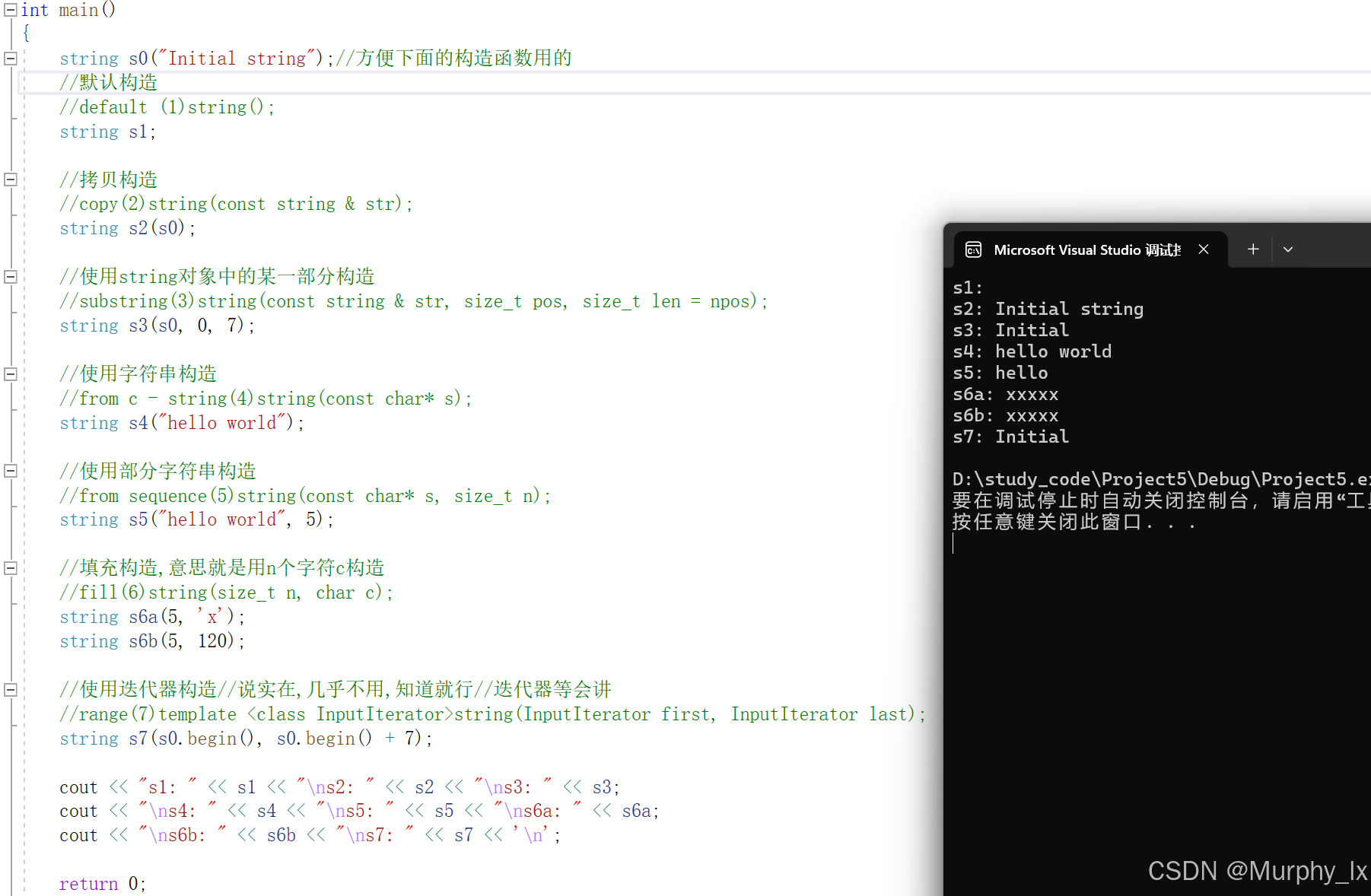
下面的图是一个使用效果以及一个基本解释:
//总的代码:
#include<iostream>
#include<string>using std::cout;
using std::cin;
using std::endl;
using std::string;//这里大家注意, 我指定展开了std::string, 所以下面就可以直接用string了int main()
{ string s0("Initial string");//方便下面的构造函数用的//默认构造//default (1)string();string s1;//拷贝构造//copy(2)string(const string & str);string s2(s0);//使用string对象中的某一部分构造//substring(3)string(const string & str, size_t pos, size_t len = npos);string s3(s0, 0, 7);//使用c语言风格字符串构造//from c - string(4)string(const char* s);string s4("hello world");//部分 C 语言字符串构造函数//from sequence(5)string(const char* s, size_t n);string s5("hello world", 5);//填充构造,意思就是用n个字符c构造//fill(6)string(size_t n, char c);string s6a(5, 'x');string s6b(5, 120);//使用迭代器构造//说实在,几乎不用,知道就行//迭代器等会讲//range(7)template <class InputIterator>string(InputIterator first, InputIterator last);string s7(s0.begin(), s0.begin() + 7);cout << "s1: " << s1 << "\ns2: " << s2 << "\ns3: " << s3;cout << "\ns4: " << s4 << "\ns5: " << s5 << "\ns6a: " << s6a;cout << "\ns6b: " << s6b << "\ns7: " << s7 << '\n';return 0;
}
我们讲几个大家比较陌生的:
//使用string对象中的某一部分构造//substring(3)string(const string & str, size_t pos, size_t len = npos);string s3(s0, 0, 7);
我们前面提到过string可以理解为一个字符数组, 那么数组就有下标昂, 所以pos其实就是数组下标的意思. len就是长度, 或者说字符个数. 所以这个构造函数的功能就是: 用str这个string对象(或者理解为字符数组), 从数组下标为pos的位置开始的len个字符构造出一个新的string对象. 大家可以看上面的效果图, 就清楚了, 或者看那个网页下面的例子展示.
那么这里大家主要疑惑的点可能就是npos这个东西是什么 :(有东西可以点进去看的)

从图里面可以看到npos是一个定义在string类里面的静态的常量
而且它的类型是size_t, size_t这个类型其实就是无符号整型, 通常就是 unsigned long long.
那么npos这个常量初始化为 -1 , 它就会被隐式转换为无符号类型的最大值(如 UINT_MAX 或 ULLONG_MAX)
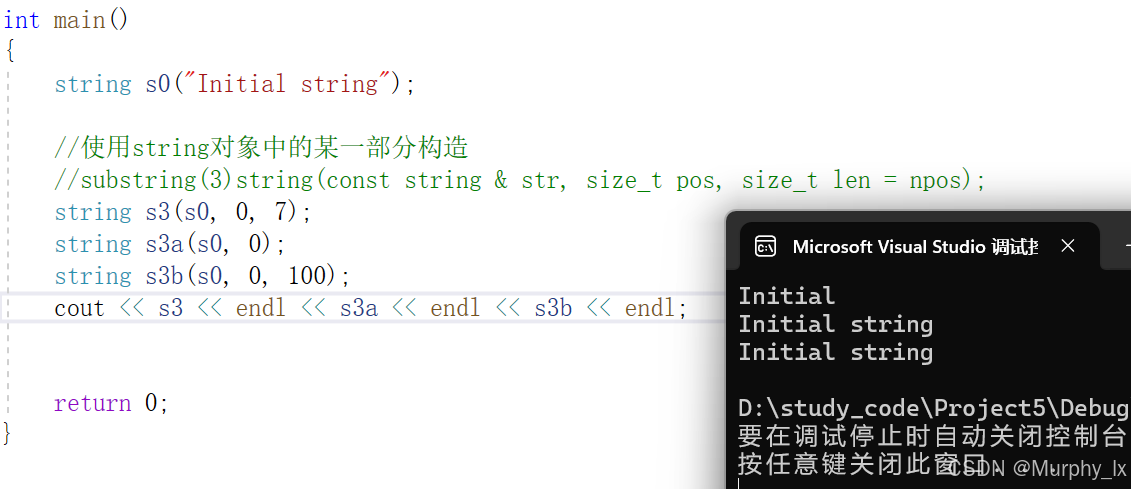
那么大家通过看这幅图呢, 大家就可以理解npos的主要作用是什么了, 当你没有传参数len过去的时候, 就会用缺省值npos嘛, 那么它这个构造函数的功能就相当于:
用str这个string对象, 从数组下标为pos的位置开始的npos个字符构造出一个新的string对象. 那么这里其实就是相当于用从下标pos开始后面的所有字符去构造一个新的string对象嘛, 应该很好理解.
而且刚刚那张图里面还有一个len=100, 这里很明显就是超过了s0这里面字符数组的大小嘛, 那么其实也就是相当于用s0从下标为0开始后面的所有字符构造出一个新的string对象s3b.
这里其实有个截断规则:若 pos + len > s0.size(),则截取到字符串末尾, 也就是说不会越界访问嘛, 在学c语言的时候都知道字符串有一个隐藏的\0标识字符串的结束嘛, 所以这里是不会越界访问的.
不过这里还是有大家需要注意的:
- 越界风险:若
pos > s0.size(),会抛出std::out_of_range异常。也就是说pos这个数组下标, 你不能超过这个字符数组的大小.s0.size()这一集会说, 就是告诉我们string对象中有效字符的个数的. 大家就理解成字符数组那样, 告诉我们数组中有多少个有效的字符就ok了. - 所以我们需要注意一下
pos这个参数, 别越界使用.
//使用c语言风格字符串构造//from c - string(4)string(const char* s);string s4("hello world");
- 功能:从以
\0结尾的 C 语言字符串(如char[]或const char*)创建std::string。 - 注意事项:
- 自动处理终止符:构造时会忽略
\0,仅复制有效字符(例如"hello"的长度为 5,不含\0)。 - 空指针风险:若传入
nullptr,行为未定义(可能崩溃)。需确保s指向有效内存。所以这里是不能用空指针去构造的.
- 自动处理终止符:构造时会忽略
//部分 C 语言字符串构造函数//from sequence(5)string(const char* s, size_t n);string s5("hello world", 5);
- 功能:从 C 字符串
s中复制前n个字符,不检查\0。 - 注意事项:
- 无视终止符:即使前
n个字符中包含\0,也会全部复制。例如:
- 无视终止符:即使前
string s("abc\0def", 7); // s 的内容为 "abc\0def",长度为 7, '\0'算一个字符
-
- 内存越界:确保
s指向的内存至少包含n个有效字符,否则会读取未定义内存。
- 内存越界:确保
//填充构造,意思就是用n个字符c构造//fill(6)string(size_t n, char c);string s6a(5, 'x'); // 用 5 个 'x' 填充string s6b(5, 120); // 等价于 s6b,因为 120 是 'x' 的 ASCII 值
- 功能:创建包含
n个重复字符c的字符串。 - 注意事项:
- 字符解释:第二个参数是
char类型,整数会被隐式转换为字符(如120 → 'x')。 - 性能:时间复杂度为 O (n),适用于初始化固定长度的字符串(如缓冲区)。
- 字符解释:第二个参数是
//使用迭代器构造//说实在,几乎不用,知道就行//迭代器等会讲//range(7)template <class InputIterator>string(InputIterator first, InputIterator last);string s7(s0.begin(), s0.begin() + 7);
- 功能:复制迭代器
[first, last)范围内的字符序列。 - 注意事项:
- 左闭右开区间:包含
first但不包含last,因此s7的内容为"Initial"。 - 迭代器有效性:确保
first和last指向同一个字符串,且first <= last,否则行为未定义。 - 适用性:可用于从其他容器(如
vector<char>)构造字符串,但实际中较少使用。
- 左闭右开区间:包含
2. 析构函数(跳过)
没啥好说的, 自动调用
3. 赋值重载
1. 拷贝赋值
string& operator= (const string& str);
- 功能:将另一个
string对象str的内容复制到当前字符串。 - 示例:
std::string s1 = "hello";
std::string s2 = "world";
s1 = s2; // s1 变为 "world"
- 注意事项:
- 深拷贝:修改
s1不会影响s2,反之亦然。 - 自我赋值安全:
s1 = s1是合法的,不会导致错误。 - 内存管理:赋值前会释放原字符串的内存,再分配新内存存储
str的内容。
- 深拷贝:修改
2. C 风格字符串赋值
string& operator= (const char* s);
- 功能:将以
\0结尾的 C 字符串(如char[]或const char*)复制到当前字符串。 - 示例:
std::string s;
s = "hello"; // s 变为 "hello"
- 注意事项:
- 自动处理终止符:赋值时会忽略
\0,仅复制有效字符(例如"hello"的长度为 5,不含\0)。 - 空指针风险:若传入
nullptr,行为未定义(可能崩溃)。需确保s指向有效内存。 - 性能开销:需要计算 C 字符串的长度(通过遍历直到
\0),时间复杂度为 O (n)。
- 自动处理终止符:赋值时会忽略
3. 字符赋值
string& operator= (char c);
- 功能:将单个字符
c赋值给当前字符串,覆盖原有内容。 - 示例:
std::string s = "abc";
s = 'X'; // s 变为 "X"
- 注意事项:
- 覆盖原有内容:无论原字符串长度如何,赋值后字符串长度变为 1。
- 字符编码:
c是单字节字符(如 ASCII, 这里面的字符一个就是一个字节),若需存储多字节字符(如UTF-8),应使用字符串形式(如s = "€")。
4. 元素访问
咱们先来看这一块:

1. operator[]
这一块是啥, 其实就是对[]这个玩意的重载, 这个东西我们啥时候见, 数组用下标访问元素的时候见嘛, 对吧. 相当于重载了这么一个玩意. 这样我们也可以直接使用数组的方式(用下标访问数组中的内容).
1. 非 const 版本
char& operator[](size_t pos);
- 功能:返回位置
pos处字符的可修改引用,允许通过该引用直接修改字符。 - 示例:
std::string s = "abc";
char ch = s[0]; //ch就是'a'
s[0] = 'X'; // 将第一个字符改为 'X',s 变为 "Xbc"
//这里非const版本其实就和数组那一样,可以通过下标访问,也可以通过下标访问修改.
//也就是:可读可写.
- 注意事项:
- 不检查越界:若
pos >= s.size(),访问行为未定义(可能崩溃或读取非法内存)。直接报错 - 适用于写操作:当需要修改字符串内容且确保索引合法时使用。
- 不检查越界:若
2. const 版本
const char& operator[](size_t pos) const;
- 功能:返回位置
pos处字符的只读引用,用于在const std::string对象或希望避免修改字符时访问字符。 - 示例:
const std::string s = "abc";
char c = s[1]; // 合法,读取第二个字符 'b'
// s[1] = 'X'; // 编译错误,const 版本禁止修改
//这里就没有写的权限(或者说修改的权限了),因为被const修饰了,那自然就不能修改了
//这里只能读.
- 注意事项:
- 同样不检查越界,对
const对象越界访问仍会导致未定义行为。直接报错 - 适用于读操作:在无需修改字符(如遍历
const字符串)时使用。
- 同样不检查越界,对
2. at访问
std::string::at 是 std::string 类提供的成员函数,用于访问字符串中指定位置的字符,与 operator[] 类似,但增加了越界检查机制,安全性更高。
1. 函数原型
- 非
const版本:
char& at(size_t pos);
- 返回位置
pos处字符的可修改引用,允许通过该引用修改字符。 const版本:
const char& at(size_t pos) const;
- 返回位置
pos处字符的只读引用,用于const std::string对象或禁止修改字符的场景。
2. 核心特点:越界检查
若 pos >= std::string::size()(即索引越界),at 会抛出 std::out_of_range 异常,避免像 operator[] 那样导致未定义行为(如程序崩溃或读取非法内存)。
3. 示例代码
#include <iostream>
#include <string>int main() {std::string s = "hello";// 合法访问std::cout << s.at(1) << std::endl; // 输出 "e"// 越界访问(触发异常)try {s.at(10); // pos=10 超过 s.size()=5} catch (const std::out_of_range& e) {std::cerr << "Error: " << e.what() << std::endl; // 输出错误信息}// 修改字符(非 const 版本)s.at(0) = 'H'; // s 变为 "Hello"std::cout << s << std::endl;// 只读访问(const 对象)const std::string s_const = "world";std::cout << s_const.at(2) << std::endl; // 输出 "r"// s_const.at(2) = 'x'; // 编译错误,const 版本禁止修改return 0;
}
4. 与 operator[] 的对比
| 特性 | std::string::at | std::string::operator[] |
|---|---|---|
| 越界检查 | 有,抛出 std::out_of_range | 无,越界导致未定义行为 |
| 安全性 | 高(适合索引可能非法的场景) | 低(需确保索引合法) |
| 异常处理 | 可通过 try-catch 捕获异常 | 无法通过异常处理,可能直接崩溃 |
其实一个就是温柔一点的报错, 一个是粗暴一点的报错, 这个就看大家选择了, 两者主要就是这方面的区别, 看大家爱好了, 用哪一个其实影响都不大的.
这里需要和大家补充一下的就是, 像at这种检测到异常之后会输出错误信息, 然后跳过异常片段, 继续运行下面的代码.
而重载[]那里, 如果出问题了, 就是直接报错, 程序崩溃了. 你们可以试一下. 论方便和熟悉程度, 我们肯定是更喜欢使用[]的, 不过大家想用什么都没关系.
5. 容量函数
接着我们看这一块:

1. std::string::size
std::string::size 是 std::string 类的一个常用成员函数,用于获取字符串中当前存储的字符数量(即字符串的长度)
函数定义
size_t size() const;
- 返回类型:
size_t(无符号整数类型,通常为unsigned long或unsigned long long),表示字符串的长度。 - 常量性:
const成员函数,调用时不会修改字符串对象本身,可用于const std::string对象。
功能
返回字符串中有效字符的个数,不包含终止符 \0(不同于 C 风格字符串的 strlen,但结果一致)。例如:
std::string s = "hello";
std::cout << s.size(); // 输出 5("hello" 有 5 个字符)
与 length 函数的关系
在 std::string 中,size() 与 length() 功能完全相同,均用于获取字符串长度,提供两者是为了兼容不同习惯(length 类似 C 风格,size 符合 STL 容器风格)。
所以在c++中, 为了和后面学习的容器的接口相照应, 我们更加习惯使用size(). 因为length()虽说也可以用, 但是后面的容器的相关接口用的大多都是size(), 所以以后我们统一都使用size(). 这个等我们学到后面就知道了.
注意事项
- 无符号类型:返回值为无符号的
size_t,避免与有符号整数直接混合比较,以防逻辑错误。 - 空字符串:对空字符串
std::string empty;,empty.size()返回0。 - 常量对象:可安全用于
const字符串,如:
const std::string cstr = "test";
std::cout << cstr.size(); // 输出 4(合法调用)
示例
#include <iostream>
#include <string>int main() {std::string str = "example";std::cout << "String: \"" << str << "\", Size: " << str.size() << std::endl; // 输出:String: "example", Size: 7const std::string empty_str = "";std::cout << "Empty String Size: " << empty_str.size() << std::endl; // 输出:Empty String Size: 0return 0;
}
在上述代码中,\" 是 C++ 中的转义字符 。在字符串字面量中,双引号 " 用于界定字符串的起止,但如果想要在字符串里表示双引号字符本身,就需要用 \ 对 " 进行转义,写成 \" 。这样编译器就知道这里的双引号不是用来界定字符串边界的,而是字符串内容的一部分。
例如:
std::string s = "He said, \"Hello!\"";
std::cout << s << std::endl;
// 输出:He said, "Hello!"
这里 \" 让双引号作为字符串内容输出,而不会被解析成字符串界定符号。
2. std::string::length
跳过, 和size()功能一模一样. 更何况我们更多时候都是使用size().
3. std::string::max_size
std::string::max_size 是 std::string 类的一个成员函数,用于返回当前系统和库实现下,std::string 对象理论上最多能容纳的字符数量。
函数定义
size_t max_size() const;
- 返回类型:
size_t(无符号整数类型,通常为unsigned long或unsigned long long),表示字符串可容纳的最大字符数。 - 常量性:
const成员函数,调用时不会修改字符串对象,可用于const std::string对象。
功能
max_size() 返回一个理论值,代表在不触发内存分配错误的前提下,std::string 能存储的最大字符数量。该值由系统内存、库实现及 size_t 类型的范围决定,通常是一个非常大的数(接近 size_t 能表示的最大值)。例如:
#include <iostream>
#include <string> int main() { std::string s; std::cout << "max_size: " << s.max_size() << std::endl; // 输出一个极大值(如 18446744073709551615) return 0;
}
与其他函数的区别
size():返回当前字符串实际存储的字符数(长度),而max_size()是理论最大容量。capacity():返回当前已分配内存可容纳的字符数(可通过reserve()调整),max_size()是更严格的理论上限。
注意事项
- 理论值限制:
max_size()是理论值,实际分配内存时可能因系统资源(如内存不足)而失败。 - 实现差异:不同编译器或库实现中,
max_size()的返回值可能不同,但通常都足够大,日常使用很难达到。是几乎达不到的.
std::string::max_size 主要用于了解字符串容量的理论极限,实际编程中较少直接使用,但对理解字符串的内存限制有一定意义。// 所以说, 这里大家只要只要知道有这么一个东西就行了, 涉猎一下.
4. std::string::resize
std::string::resize 是 std::string 类用于调整字符串长度的成员函数,有两种重载形式.
1. void resize(size_t n);
- 功能:将字符串的长度调整为n.
- 若
n < 当前长度:截断字符串,仅保留前n个字符。 - 若
n > 当前长度:在字符串末尾添加默认字符(空字符'\0'),使长度达到n。
- 若
- 示例:
std::string s = "hello"; // 长度为 5
s.resize(3); // 截断为 "hel"
s.resize(7); // 扩展为 "hel\0\0\0\0"(添加 4 个空字符)
这里可以使用调试看一下:
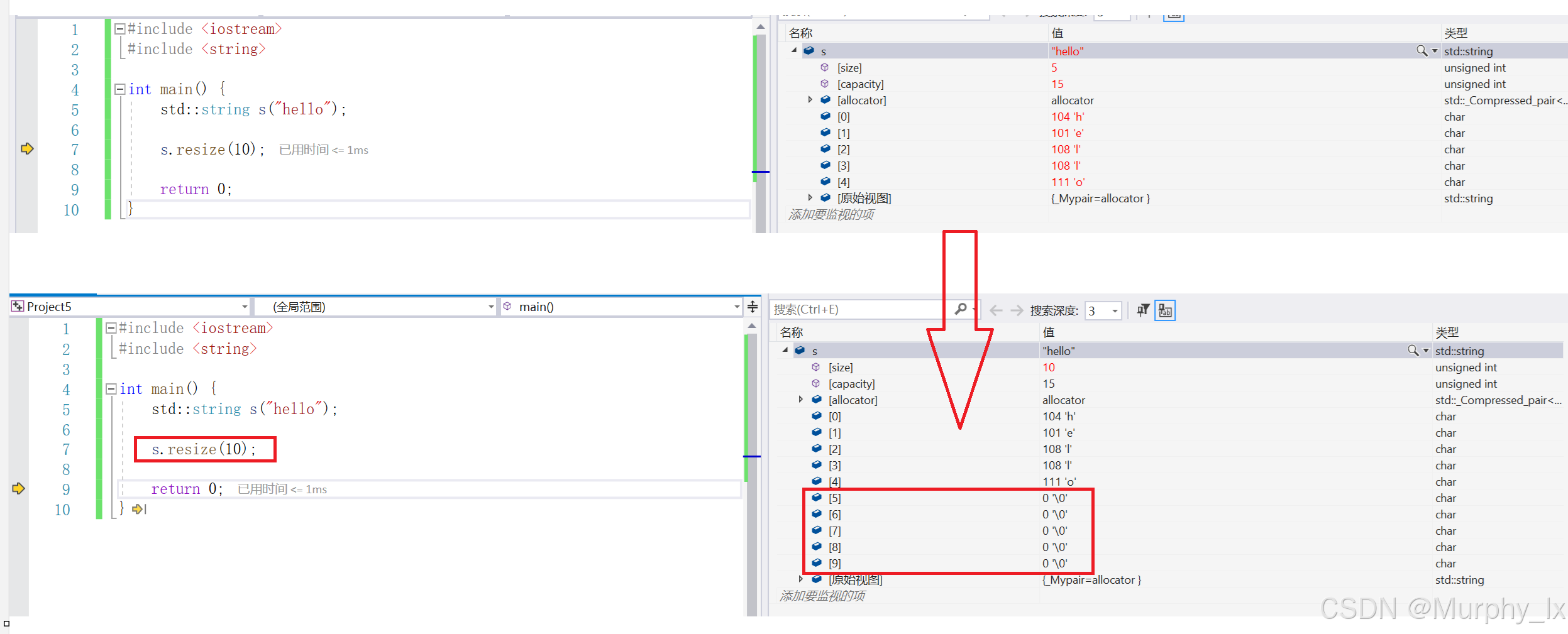
它确实是用空字符'\0'来填充的.
2. void resize(size_t n, char c);
- 功能:将字符串的长度调整为n。
- 若
n < 当前长度:截断字符串,仅保留前n个字符(与第一个重载相同)。 - 若
n > 当前长度:在字符串末尾添加字符c,使长度达到n。
- 若
- 示例:
std::string s = "hello"; // 长度为 5
s.resize(7, 'x'); // 扩展为 "helloxx"(添加 2 个 'x')
注意事项
- 修改容量:
resize可能改变字符串的容量(capacity),但并非一定(取决于库的实现和当前容量是否足够)。
大家可以看下面这幅图:
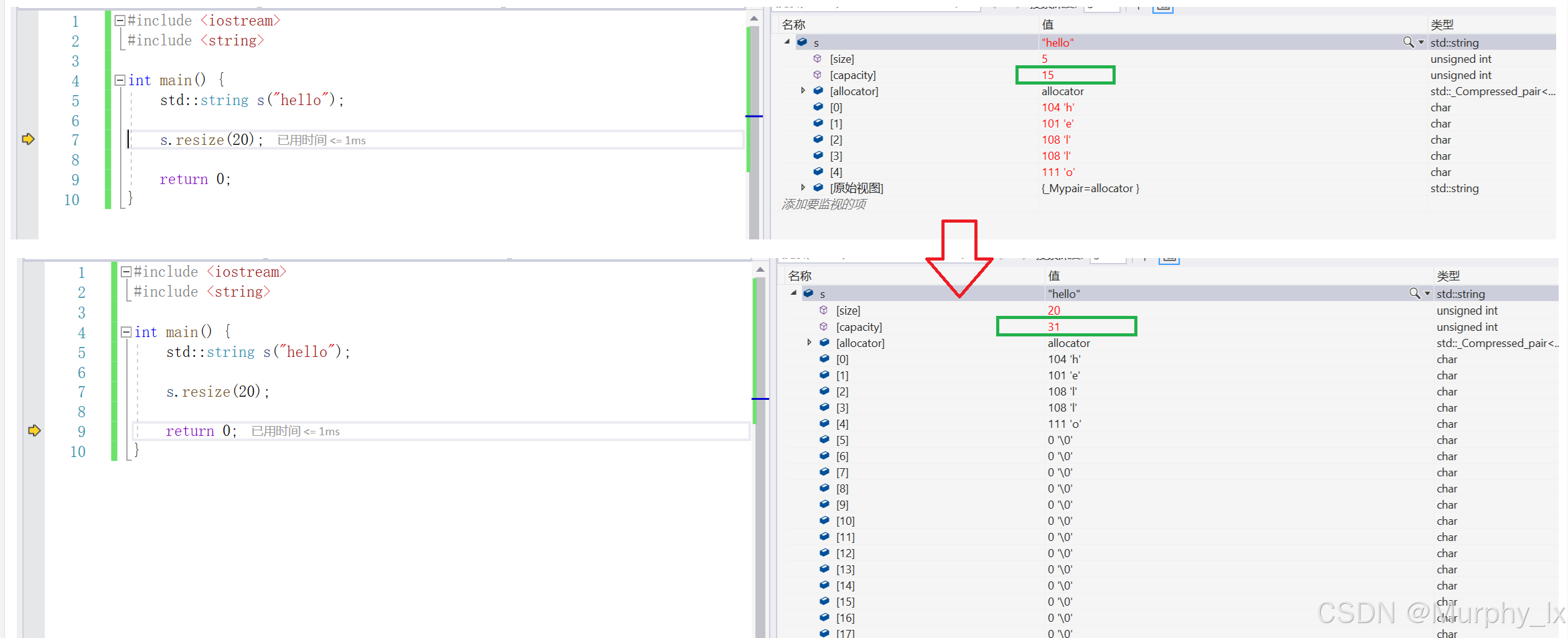
这幅图的重点是绿色框框圈起来的capacity, 也就是容量大小的的变化, 可以看到, 原来一开始编译器开了15个有效空间, 但是大家注意了, 实际上开空间的时候, 是16, 因为还有一个字符串的标识符'\0'要存储, 不过'\0'不会被算进去(后续底层复现会说), 所以这边的容量显示是15, 而且不同厂商的编译器, 初始容量开多少是不一定相同的, 而且后续扩容的逻辑也是不一样的. 这个等会会给大家展示. 这里我们先看着容量capacity的变化, 从15变成了31, 结合上一张图, 在vs编译器里面, 当容量足够的时候是不会去扩容的, 当容量不够了就会去扩容, 目前看到vs扩容的逻辑是2倍扩容.
- 效率:扩展字符串时,若当前容量不足,会触发内存重新分配,可能影响性能。若已知大致长度,可先用
reserve预分配内存。 - 字符填充:第一个重载用空字符
'\0'填充,第二个重载用指定字符c填充,二者语义不同,需根据需求选择。
通过 resize,可以方便地调整字符串长度,截断或扩展字符串内容,满足不同场景下对字符串长度的动态调整需求。
总结一下就是: resize()主要干的什么事情呢? :
一点就是: 插入数据, 当容量不足的时候会去扩容.
另外一点, 大家需要额外留意就是: resize()会删除数据, 它会根据你指定的参数n去选择插入数据或者截断数据, 这里大家是要额外留意的.
5. std::string::capacity
std::string::capacity 是 std::string 类的一个成员函数,用于返回当前字符串在不重新分配内存的情况下,能够容纳的最大有效字符数量。
函数定义
size_t capacity() const;
- 返回类型:
size_t(无符号整数类型),表示当前分配内存可容纳的有效字符数。 - 常量性:
const成员函数,不会修改字符串对象,可用于const std::string。
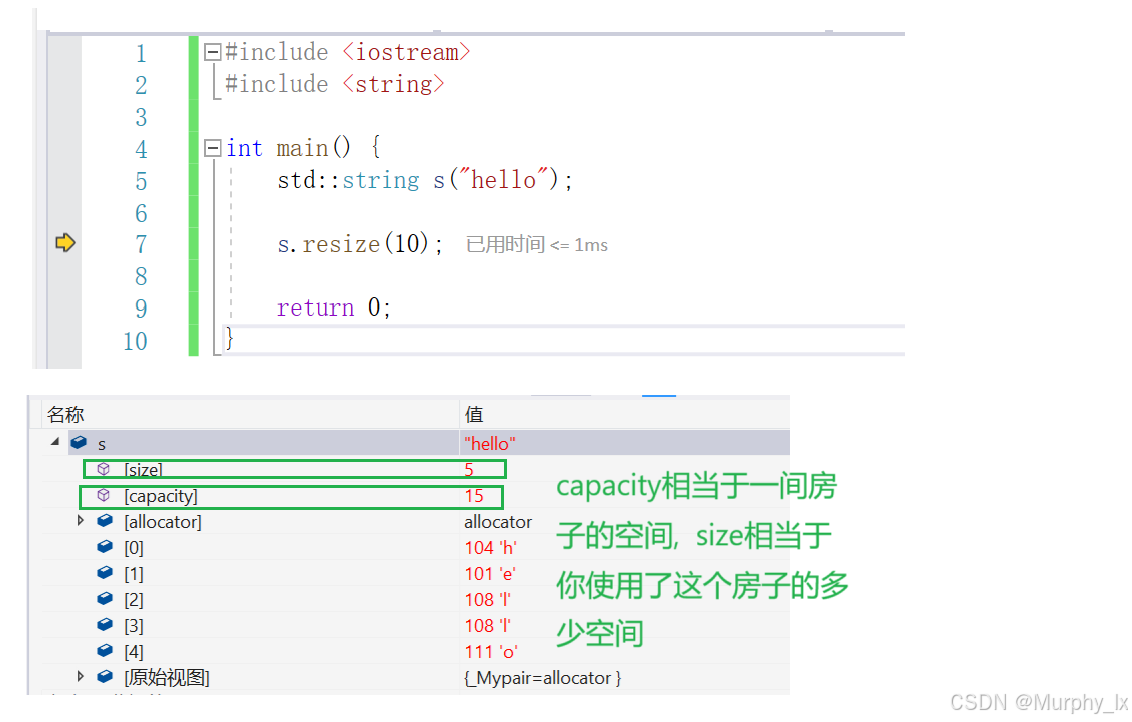
核心作用
-
内存优化:
std::string会预先分配一定内存(即capacity),避免每次添加字符都重新分配内存,从而提升操作效率。例如,向字符串添加字符时,若未超过capacity,可直接利用已分配内存,无需耗时的重新分配。 -
与
size的区别:size():返回字符串中实际存储的字符数(长度)。capacity():表示当前已分配内存最多能存储的字符数,是内存分配的容量值,通常大于或等于size()。
示例
#include <iostream>
#include <string> int main() { std::string s = "hello"; std::cout << "Size: " << s.size() << " (实际字符数)\n"; std::cout << "Capacity: " << s.capacity() << " (当前分配内存可容纳的最大字符数)\n"; s.reserve(100); // 手动调整容量 std::cout << "After reserve, Capacity: " << s.capacity() << "\n"; return 0;
}
注意事项
- 内存分配策略:不同标准库实现中,
capacity的增长策略可能不同(如常见的翻倍策略),但目的都是减少重新分配次数。//这里说的其实就是不同编译器厂商对于这一块实现的逻辑可能不一样.
#include <iostream>
#include <string>
using std::cout;
using std::endl;
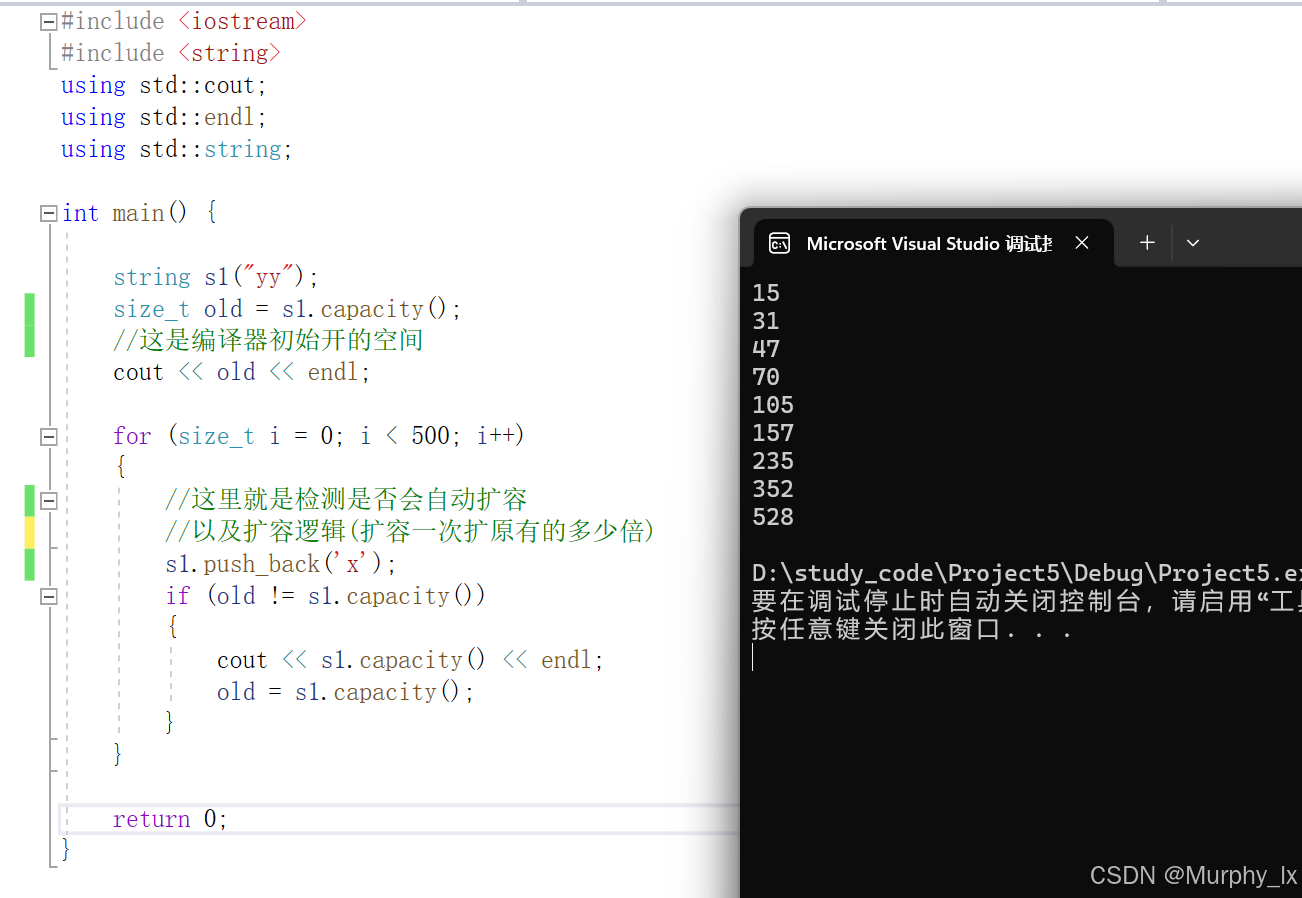
using std::string;int main() {string s1("yy");size_t old = s1.capacity();//这是编译器初始开的空间cout << old << endl;for (size_t i = 0; i < 500; i++){//这里就是检测是否会自动扩容//以及扩容逻辑(扩容一次扩原有的多少倍)s1.push_back('x');if (old != s1.capacity()){cout << s1.capacity() << endl;old = s1.capacity();}}return 0;
}
这是vs2019下的:
然后下面是Linux系统使用g++编译的:
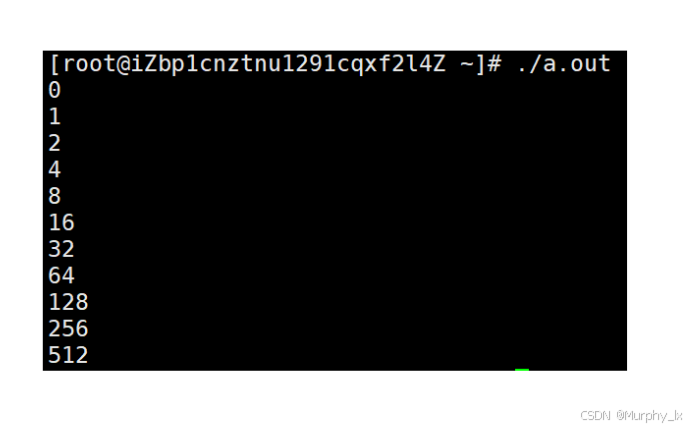
所以可以看到就是, 当容量不够的时候, 是会自动扩容的, 但是不同编译器扩容的逻辑不同, vs的编译器除了第一次扩容是2被扩容以外, 后面的都是按照原有容量的1.5倍去扩容的.
而使用g++编译, 扩容逻辑则一直都是2倍扩容, 而且我们可以看到, 使用g++编译, 它初始容量是为0的, 这也和vs不同.
在这里大家应该就可以很明显的看出不同编译器的一个差别, 功能是类似的, 但是底层逻辑是可能不同的, 这一点大家需要留意一下.
不过这种操作其实是不太好的, 频繁的去扩容会降低程序性能嘛, 下面也说了, 我们最好提前确定要用多少的空间, 提前开好, 这个函数, 就讲.
- 手动调整:可通过
reserve(n)提前分配内存,避免多次扩容。例如,已知需存储约 100 个字符时,reserve(100)可优化性能。 - 不保证永远足够:
capacity是当前状态下的容量,若持续添加字符超过它,std::string会自动重新分配更大内存,capacity也会随之更新。
std::string::capacity 帮助理解字符串的内存使用情况,合理利用它(如配合 reserve)可优化程序性能,减少内存操作的开销。
6. std::string::reserve
std::string::reserve 是 std::string 类的成员函数,用于为字符串对象预先分配内存,以优化后续字符添加操作的效率。
其定义为 void reserve(size_t n = 0);
核心作用
- 减少内存重分配:字符串在添加字符时,若当前容量(
capacity)不足,会触发内存重新分配(申请更大内存、复制数据),耗时较高。reserve(n)可提前分配至少容纳n个字符的内存,避免多次重分配。 - 仅调整容量:该操作不改变字符串的长度(
size),新分配的内存不会用字符填充,仅预留空间。例如:
std::string s;
s.reserve(100); // 容量至少变为 100,但 s.size() 仍为 0
参数说明
- n:期望的最小容量。
- 若
n > 当前容量,则调整容量(具体实现可能分配大于n的空间)。 - 若
n ≤ 当前容量,函数不执行任何操作。//它是不会像resize()那样截断数据的, 这个函数只能改变空间, 而且只能扩容. 不能缩小容量
- 若
示例
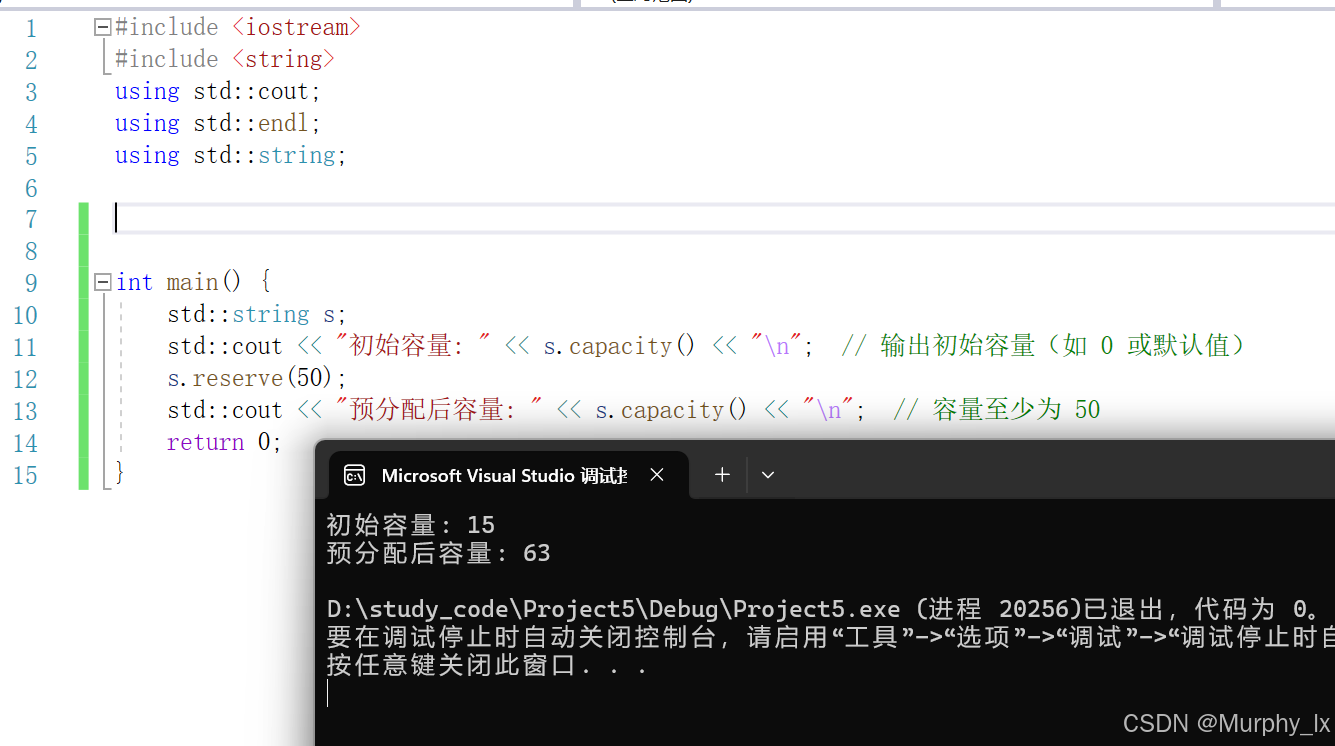
#include <iostream>
#include <string> int main() { std::string s; std::cout << "初始容量: " << s.capacity() << "\n"; // 输出初始容量(如 0 或默认值) s.reserve(50); std::cout << "预分配后容量: " << s.capacity() << "\n"; // 容量至少为 50 return 0;
}
好, 这里全体注意了, 不同编译器操作不同, 下面图片是vs2019的;
下面那个是g++编译的:
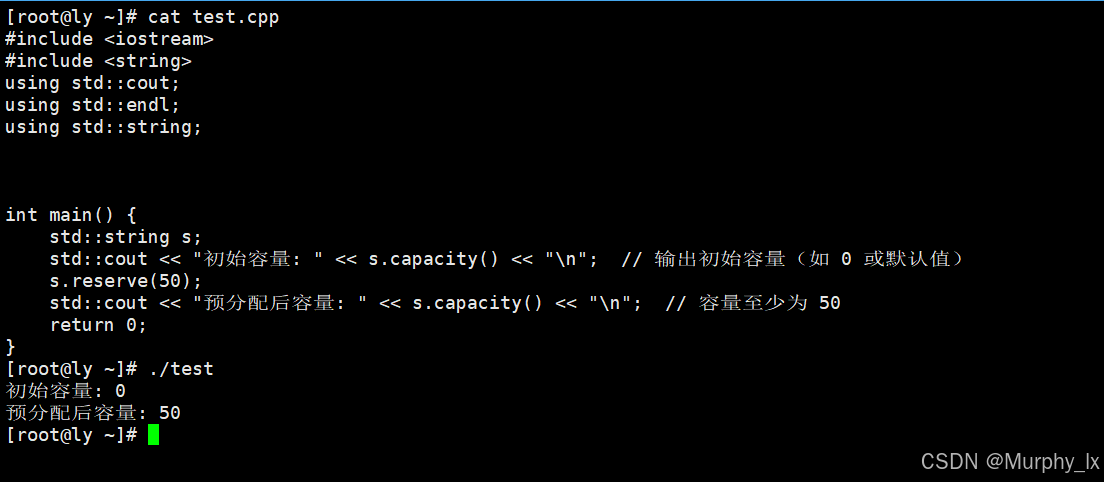
可以看到, vs2019是不会严格的按照你你指定的容量去扩容的, 但是g++会, g++编译出来的, 就是完全根据你的要求去分配空间的.
注意事项
- 不影响长度和内容:
reserve仅改变内存分配,字符串的长度(size)和内容保持不变。 - 合理估算
n:若n远大于实际需求,会浪费内存;若n过小,仍可能触发后续重分配。需根据实际场景估算。
通过 reserve,可在已知大致字符数量时,优化字符串操作性能,避免频繁内存重分配带来的开销。
7. std::string::clear
这个东西没啥说的, 它的作用就是: 删除字符串的内容,使其变为空字符串(长度为0个字符)。
8. std::string::empty
这个也是没啥说的, 它是判断这个字符串是否为空, 即是: 返回字符串是否为空(即其长度是否为0)。
这两个函数, 涉猎一下即可, 重点是前面6个函数大家需要熟悉.
6. 迭代器
接下来我们看这一块:

std::string 提供了多种迭代器,用于遍历和操作字符串中的字符,这些迭代器本质上是指针或其封装,支持类似指针的操作(如解引用 *、递增 ++ 等)。这里, 我们不细说, 我们先知道迭代器是什么, 以及知道怎么使用先, 后续我们复现底层的时候再去详细说道说道.
1. begin() 和 end()
begin():返回指向字符串第一个字符的迭代器。若字符串为const限定,返回const_iterator;否则返回iterator。这里的类型需要大家注意一下了.- 如果你不用auto推导变量类型, 你要自己写,迭代器不是有两种嘛, 一种是这样的:
iterator begin();这种呢, 就和平常指针类似, 你可以修改迭代器指向位置的东西.
#include <iostream>
#include <string>
using std::cout;
using std::endl;
using std::string;int main() {std::string s = "hello";cout << s << endl;// 正向遍历并修改for (std::string::iterator it = s.begin(); it != s.end(); ++it) {*it = std::toupper(*it); // 修改为大写}// s 变为 "HELLO"cout << s << endl;return 0;
}
-
另一种
const_iterator begin() const;第一, 大家要注意的就是它要用是这样的:std::string::const_iterator it = s.begin(), 千万注意啊, 是const_iterator, 而不是const iterator, 不是std::string::const iterator it = s.begin(). -
其次就是, 你不能这样写:
const std::string::iterator it = s.begin() -
const_iterator:指向const字符的迭代器(即字符不可修改,但迭代器可移动)。 -
const std::string::iterator:迭代器本身不可移动,但字符可修改。这样const修饰的就是迭代器本身了, 迭代器就不能变了, 迭代器不能变, 那迭代器就废了. 因为这里的迭代器其实就是相当于指针遍历字符串, 迭代器不能移动, 就不能遍历. -
std::string::const_iterator cit = s.begin(); // 字符不可修改(等价于 const_iterator) const std::string::iterator it = s.begin(); // 迭代器不可移动 //这里给大家比较一下吧: //std::string::const_iterator cit = s.begin();这个玩意其实相当于: const int* a = nullptr//这里的const修饰的是指针a指向的变量,指向的那个东西不能变 //const std::string::iterator it = s.begin();这个东西呢,相当于: int* const a = nullptr;//这里const修饰的是指针a,指针a不能变. //有点绕,但是大家得理顺 -
const_iterator(字符不可变)用于遍历const字符串。 -
普通
iterator(迭代器和字符均可变)用于需要修改字符的场景。 -
end():返回指向字符串最后一个字符的下一个位置(理论上紧跟最后一个字符的 “哨兵” 位置)的迭代器。搭配begin()使用可指定包含所有字符的范围。
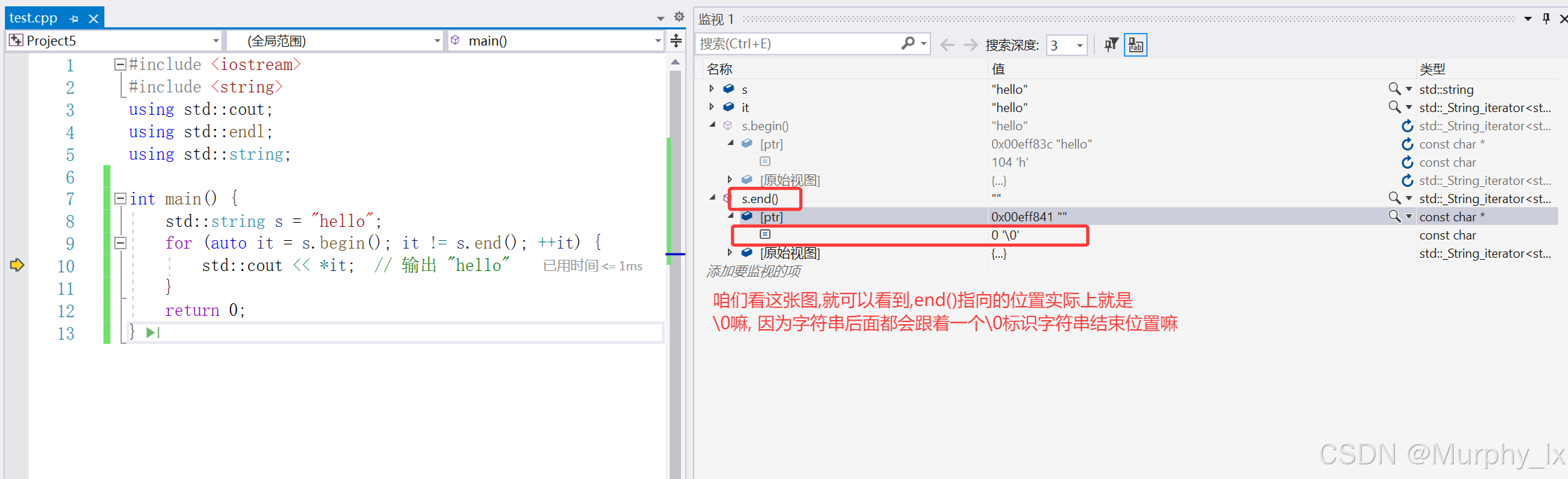
#include <iostream>
#include <string>
int main() { std::string s = "hello";//这里auto的类型实际上是://std::string::iteratorfor (auto it = s.begin(); it != s.end(); ++it) { std::cout << *it; // 输出 "hello" } return 0;
}
这里的auto前面和大家讲过, 好像是讲c++的第一集, 这里就是自动识别变量类型, 因为类型直接写很长嘛,用auto自动识别类型, 就会便捷一些, 不过这样写的一个不太好的地方就是读者读代码就可能不太方便, 你写代码这样写确实是爽, 读代码的人可能就不太爽, 这就看各位考虑了.
2. rbegin() 和 rend()
rbegin():返回反向迭代器,指向字符串的最后一个字符(即反向遍历的起始位置)。反向迭代器递增时向字符串开头移动。rend():返回反向迭代器,指向字符串第一个字符的前一个位置(反向遍历的结束位置)。
#include <iostream>
#include <string>
int main() { std::string s = "hello"; for (auto rit = s.rbegin(); rit != s.rend(); ++rit) { std::cout << *rit; // 输出 "olleh" } return 0;
}
这个呢就是方向反了一下.
3. cbegin() 和 cend()(C++11 引入)
cbegin():返回指向字符串第一个字符的const_iterator,用于**只读访问 **,不能通过该迭代器修改字符。cend():返回指向字符串最后一个字符下一个位置的const_iterator。
#include <iostream>
#include <string>
int main() { const std::string s = "hello"; for (auto it = s.cbegin(); it != s.cend(); ++it) { std::cout << *it; // 输出 "hello",但不能修改 *it } return 0;
}
4. crbegin() 和 crend()(C++11 引入)
crbegin():返回指向字符串最后一个字符的const_reverse_iterator,用于反向只读访问。crend():返回指向字符串第一个字符前一个位置的const_reverse_iterator。
#include <iostream>
#include <string>
int main() { const std::string s = "hello"; for (auto rit = s.crbegin(); rit != s.crend(); ++rit) { std::cout << *rit; // 输出 "olleh",不能修改 *rit } return 0;
}
begin()原本不是两类型嘛, 一个正常的, 一个const_iterator. 后面就明确了. begin()你依旧可以使用两种类型, 但是呢, 我现在给你新增了一个cbegin(), 这个新的cbegin()就明确了是const_iterator这种. 这样可能有人会觉得这样好区分一些. 别的同理, 什么cend()等等.
这里大家想怎么用就怎么用, 不影响, 看大家喜好, 觉得使用cbegin()清楚就用, 不喜欢就不用, 都是支持的.
#include <iostream>
#include <string> int main() { std::string s = "hello"; // 非 const 版本:可读写 for (auto it = s.begin(); it != s.end(); ++it) { *it = static_cast<char>(std::toupper(*it)); // 转为大写 } std::cout << s << "\n"; // 输出 "HELLO" const std::string cs = "world"; // const 版本:仅能读取 for (auto cit = cs.begin(); cit != cs.end(); ++cit) { std::cout << *cit; // 输出 "world",不能修改 *cit } return 0;
}
可以看到, auto是可以推出正确类型的begin()的, 说实在的, 其实我有点偏向服务读者, 我是比较喜欢写清楚代码的, 要是我, 我肯定喜欢使用cbegin(), 清楚嘛, 你用auto, 人家也知道你这个是const_iterator. 不过我老师说没啥人喜欢用, 当然了, 看大家爱好.
总结:
然后我们总结一下迭代器这个东西:
一、迭代器的作用
-
统一遍历方式:为不同数据结构(如数组、链表、集合等)提供一致的元素访问接口。例如,不管是连续存储的
vector还是非连续的list,都能用迭代器按顺序遍历元素,使代码更通用。所以这就是为什么我们都可以使用[]像数组那样用下标访问,像数组那样遍历字符串了,为什么还要有迭代器这个东西,因为迭代器在任何容器,不管你内存空间是不是连续的,都可以使用迭代器去遍历,去访问。但是数组那种使用[]遍历只有在内存空间是连续的时候才可以使用, 遇到像"树"这种内存空间不连续的就不行了. 使用迭代器, 任何数据结构可以遍历. -
分离容器与算法:在 STL(标准模板库)中,算法通过迭代器操作容器,无需关心容器内部实现。如
std::for_each算法,可作用于任意支持迭代器的容器,增强了算法的复用性。//算法这部分我们还没讲, 后面会说的. -
隐藏实现细节:程序员只需通过迭代器的通用操作(如
*解引用、++移动)访问元素,无需了解容器内存分配、节点链接等细节。//就是我们使用迭代器的方式都是一样的, 一样的使用方式可以遍历不同类型的数据结构, 我们是不需要根据数据结构的类型去改变迭代器的使用方式的, 所以就不用关系数据结构的底层. //但是我们得知道哈, 这个我们得学的, 还是要知道它的细节的, 怎么实现的, 等等.
二、迭代器存在的原因
不同容器物理结构差异大(如 vector 类似数组、list 是链表),若直接操作底层(如指针、节点),代码会因容器类型不同而复杂。迭代器通过抽象化访问逻辑(如为 list 的迭代器类重载 ++ 运算符来模拟节点跳转),使上层代码以统一方式处理所有容器,提升开发效率与代码简洁性。
三、迭代器可理解为
- 广义指针:行为类似指针,支持解引用(
*)、移动(++)等操作,但功能更强大。例如,list的迭代器本质是类,通过重载运算符实现对不连续节点的遍历,而普通指针无法直接处理链表。 - 抽象访问接口:将容器元素的遍历逻辑封装成统一接口,无论容器内部如何复杂,都通过迭代器的标准操作(如
begin()指向开头、end()指向末尾之后)进行遍历,屏蔽了底层差异。
7. 修改功能的接口
我们接下来看修改功能方面的东西, 也就是下面这一块:

1. std::string::operator+=
在 C++ 中,std::string::operator+= 是用于拼接字符串的重载运算符,提供了三种形式,方便将不同类型内容追加到当前 std::string 对象末尾:
string& operator+=(const string& str)
将另一个std::string对象str的内容追加到当前字符串后。
示例:
std::string s1 = "hello", s2 = "world";
s1 += s2; // s1 变为 "helloworld"
返回当前对象的引用(string&),支持链式操作(如 a += b += c)。
string& operator+=(const char\* s)
接受 C 风格字符串(以'\0'结尾的字符数组),将其内容追加到当前字符串。
示例:
std::string s = "abc";
s += "def"; // s 变为 "abcdef"
便于直接拼接字符串字面值(如 "hello")。
string& operator+=(char c)
将单个字符c追加到当前字符串末尾。
示例:
std::string s = "a";
s += 'b'; // s 变为 "ab"
2. std::string::append
std::string::append 是 C++ 中用于向 std::string 对象追加内容的成员函数,提供了多种重载形式
string& append(const string& str)
将另一个std::string对象str的全部内容追加到当前字符串末尾。
示例:
std::string s1 = "hello";
std::string s2 = "world";
s1.append(s2); // s1 变为 "helloworld"
返回当前对象的引用(string&),支持链式操作。
string& append(const string& str, size_t subpos, size_t sublen)
从str的subpos位置(数组下标)开始,取长度为sublen的子串追加到当前字符串。
注意:若subpos超过str长度,行为未定义;若subpos + sublen超过str长度,实际取到str末尾。
示例:
std::string str = "abcdef";
std::string s = "start";
s.append(str, 1, 3); // 取 "bcd",s 变为 "startbcd"
string& append(const char* s)
追加 C 风格字符串(以'\0'结尾的字符数组)。
示例:
std::string s = "prefix";
s.append("suffix"); // s 变为 "prefixsuffix"
string& append(const char* s, size_t n)
追加s指向的字符数组的前n个字符,无视'\0'。
示例:
char arr[] = {'a', 'b', 'c', '\0', 'd'};
std::string s;
s.append(arr, 4); // 追加 "abcd"(取前 4 个字符)
string& append(size_t n, char c)
追加n个字符c。
示例:
std::string s = "repeat_";
s.append(3, 'x'); // s 变为 "repeat_xxx"
template <class InputIterator> string& append(InputIterator first, InputIterator last)
追加迭代器[first, last)范围内的所有字符。适用于任何输入迭代器(如vector<char>、list<char>的迭代器)。
示例:
#include <vector>
std::vector<char> vec = {'a', 'b', 'c'};
std::string s;
s.append(vec.begin(), vec.end()); // s 变为 "abc"
append 函数相比 operator+= 更灵活,能精确控制追加内容的来源、长度或范围,适用于多样化的字符串拼接场景,且所有重载均返回当前对象的引用,便于连续操作。
常用的其实就前面的几个, 效果也和+=效果差不多, 大家根据各自喜好去用就行了, 后面那些不常用的, 知道就行.
3. std::string::push_back
std::string::push_back 是 C++ 中 std::string 类的成员函数,用于在字符串末尾添加单个字符,其定义为 void push_back (char c);。
- 功能:将字符
c追加到当前std::string对象的末尾,直接修改原字符串。 - 参数:仅接受一个
char类型的字符c,表示要添加的字符。 - 返回值:
void,不返回任何值,操作完成后原字符串已被修改。
示例:
#include <string>
#include <iostream>
int main() { std::string str = "hello"; str.push_back('!'); // 向 str 末尾添加字符 '!' std::cout << str << std::endl; // 输出 "hello!" return 0;
}
与 std::string::operator+=(字符版本)相比,push_back 功能更专注于单个字符的添加,二者都能实现字符追加,但 push_back 返回 void,而 operator+= 返回 std::string&(支持链式操作)。该函数是 std::string 灵活操作字符的基础接口之一。//相当于这就是一个比较泛用的螺丝钉, 哪里都可以用, 是一个比较底层的接口.
4. std::string::assign
std::string::assign 是 C++ 中 std::string 类用于赋值的成员函数,可替换字符串原有内容
string& assign(const string& str)
将另一个std::string对象str的全部内容赋给当前字符串。
示例:
std::string s1 = "old", s2 = "new";
s1.assign(s2); // s1 变为 "new"
string& assign(const string& str, size_t subpos, size_t sublen)
从str的subpos位置开始,取长度为sublen的子串赋值给当前字符串。若subpos超出str长度,行为未定义;若subpos + sublen超出str长度,实际取到str末尾。
示例:
std::string str = "abcdef";
std::string s;
s.assign(str, 1, 3); // 取 "bcd",s 变为 "bcd"
string& assign(const char\* s)
用 C 风格字符串(以'\0'结尾的字符数组)赋值给当前字符串。
示例:
std::string s;
s.assign("hello"); // s 变为 "hello"
string& assign(const char\* s, size_t n)
取s指向的字符数组的前n个字符赋值,无视'\0'。
示例:
char arr[] = {'a', 'b', 'c', '\0', 'd'};
std::string s;
s.assign(arr, 4); // 赋值 "abcd"
string& assign(size_t n, char c)
用n个字符c填充当前字符串。
示例:
std::string s;
s.assign(5, 'x'); // s 变为 "xxxxx"
template <class InputIterator> string& assign(InputIterator first, InputIterator last)
将迭代器范围[first, last)内的字符赋值给当前字符串,适用于任何输入迭代器(如vector<char>、list<char>的迭代器)。
示例:
#include <vector>
std::vector<char> vec = {'a', 'b', 'c'};
std::string s;
s.assign(vec.begin(), vec.end()); // s 变为 "abc"
所有重载形式均返回 std::string&,支持链式操作。assign 比简单的 = 赋值更灵活,能精确控制赋值内容的来源、长度或范围,满足多样化的字符串赋值需求。
看到这里大家应该就可以发现, c++的接口其实都差不多的, 写的很规范, 而且参数什么的, 也都差不多, 所以说看懂string类, 后面的容器就很容易去看明白了.
而且大家应该也可以发现, 其实很多东西写出来是没啥用的, 现实生活中很少有用到一些功能, 这就是string不太好的地方, 或者说冗余吧.
为啥写的全面还不好呢? 因为, wc, 你学习花的时间就多了呀, 都快给我写懵了.
5. std::string::insert
std::string::insert 是 C++ 中用于在 std::string 指定位置插入内容的成员函数
string& insert(size_t pos, const string& str)
在pos(起始索引为0)位置插入字符串str的全部内容。若pos超过当前字符串长度,内容将追加到末尾。
示例:
std::string s = "abc";
s.insert(1, "de"); // s 变为 "adebc"
string& insert(size_t pos, const string& str, size_t subpos, size_t sublen)
从str的subpos位置开始,取长度为sublen的子串插入到pos处。若subpos超出str长度,行为未定义;若subpos + sublen超出str长度,取到str末尾。
示例:
std::string str = "12345";
std::string s = "a";
s.insert(1, str, 1, 2); // 取 "23",s 变为 "a23"
string& insert(size_t pos, const char\* s)
在pos处插入 C 风格字符串(以'\0'结尾的字符数组)。
示例:
std::string s = "test";
s.insert(0, "hello_"); // s 变为 "hello_test"
string& insert(size_t pos, const char\* s, size_t n)
插入s所指字符数组的前n个字符(无视'\0')。
示例:
char arr[] = {'a', 'b', '\0', 'c'};
std::string s;
s.insert(0, arr, 3); // 插入 "abc"
string& insert(size_t pos, size_t n, char c)
在pos处插入n个字符c。
示例:
std::string s = "base";
s.insert(4, 3, '_'); // s 变为 "base___"
void insert(iterator p, size_t n, char c)
通过迭代器 p 指定位置,插入 n 个字符 c。
iterator insert(iterator p, char c)
在迭代器p指向的位置插入单个字符c,返回新的迭代器(指向插入的字符)。
示例:
std::string s = "abcd";
auto it = s.begin() + 2;
s.insert(it, 'x'); // s 变为 "abx cd"(实际为 "abxcd")
void insert(iterator p, InputIterator first, InputIterator last)
将迭代器范围[first, last)内的字符插入到p指向的位置。适用于任何输入迭代器(如vector<char>、list<char>的迭代器)。
示例:
#include <vector>
std::vector<char> vec = {'x', 'y', 'z'};
std::string s = "12";
s.insert(s.begin() + 1, vec.begin(), vec.end()); // s 变为 "1xyz2"
这些重载形式中,返回 string& 的版本支持链式操作,而部分返回 void 或 iterator 的版本则专注于特定场景的插入操作。使用时需确保索引或迭代器合法,避免越界导致未定义行为。
6. std::string::erase
std::string::erase 是 C++ 中用于删除 std::string 中字符的成员函数
string& erase(size_t pos = 0, size_t len = npos);- 从位置
pos(起始索引为0)开始,删除长度为len的字符。 pos默认值为0,len默认值为npos(表示删除至字符串末尾)。- 若
pos超过字符串长度,不执行删除;若pos + len超过字符串长度,仅删除至末尾。 - 示例:
- 从位置
std::string s = "abcdef";
s.erase(1, 3); // 从索引 1 开始删 3 个字符,s 变为 "aef"
iterator erase(iterator p);- 删除迭代器
p指向的单个字符。 - 返回一个迭代器,指向被删除字符的下一个字符。
- 示例:
- 删除迭代器
std::string s = "abc";
auto it = s.erase(s.begin() + 1); // 删除 'b',s 变为 "ac",it 指向 'c'
iterator erase(iterator first, iterator last);- 删除迭代器范围
[first, last)内的所有字符(包含first,不包含last)。 - 返回迭代器
last(指向删除范围之后的位置)。 - 示例:
- 删除迭代器范围
std::string s = "abcdef";
s.erase(s.begin() + 1, s.begin() + 3); // 删除 'b' 和 'c',s 变为 "aef"
这些操作会直接修改原字符串,缩短其长度。同时,操作后指向字符串的迭代器、指针和引用可能失效(删除位置之后的部分),使用时需注意。
7. std::string::replace
std::string::replace 是 C++ 中用于替换 std::string 中指定字符序列的成员函数
我真的无语了, 又tm来一个替换
string& replace(size_t pos, size_t len, const string& str);- 从位置
pos(起始索引为0)开始,删除len个字符,然后插入字符串str。 - 若
pos超过字符串长度,不执行操作;若pos + len超过长度,仅删除至末尾。 - 示例:
- 从位置
std::string s = "abcde";
s.replace(1, 2, "xy"); // 删 "bc",插入 "xy",s 变为 "axyde"
string& replace(iterator i1, iterator i2, const string& str);- 删除迭代器区间
[i1, i2)(左闭右开)内的字符,插入str。 - 示例:
- 删除迭代器区间
std::string s = "abcde";
s.replace(s.begin() + 1, s.begin() + 3, "x"); // 删 "bc",插入 "x",s 变为 "axe"
string& replace(size_t pos, size_t len, const string& str, size_t subpos, size_t sublen);- 从
str的subpos位置开始,取长度为sublen的子串,替换原字符串中从pos开始、长度为len的字符。 - 若
subpos超过str长度,行为未定义;若subpos + sublen超过str长度,取到str末尾。 - 示例:
- 从
std::string str = "abcdef";
std::string s = "123";
s.replace(1, 2, str, 1, 2); // 取 "bc",替换 "23",s 变为 "1bc"
string& replace(size_t pos, size_t len, const char\* s);- 用 C 风格字符串
s替换原字符串中从pos开始、长度为len的字符。 - 示例:
- 用 C 风格字符串
std::string s = "test";
s.replace(0, 2, "hello"); // 删前 2 字符,插入 "hello",s 变为 "hellot"
string& replace(iterator i1, iterator i2, const char\* s);- 删除
[i1, i2)区间的字符,插入 C 风格字符串s。 - 示例:
- 删除
std::string s = "abc";
s.replace(s.begin(), s.begin() + 1, "xyz"); // 删 "a",插入 "xyz",s 变为 "xyzbc"
后面的就不想写了, 本来就不怎么用了. 了解一下就好.
8. std::string::swap
std::string::swap 是 std::string 类的成员函数,定义为 void swap(string& str);,作用是交换当前 std::string 对象与另一个 std::string 对象 str 的内容,包括字符序列、长度、容量等。这种交换操作非常高效,因为它通常仅交换内部数据指针、长度和容量等元数据,而非实际复制字符序列。
这样, 大家, 这样理解一下: 这里string里面的swap呢, 相当于两辆货车的车厢直接交换, 一共a, b两辆货车, 然后a, b两辆货车交换车厢.
而不是将a货车的车厢中的货物一个个搬下来和b货车车厢中的货物交换, 明白嘛. 是这个意思. 这个还是比较重要的哈. 大家需要理解一下.
示例:
#include <string>
int main() { std::string s1 = "hello", s2 = "world"; s1.swap(s2); // 交换后,s1 变为 "world",s2 变为 "hello" return 0;
}
与标准库 swap 算法的区别
(算法里面也有一个swap函数) 标准库 swap 是定义在 <utility> 头文件中的模板函数,即 template <class T> void swap(T& a, T& b);,用于交换两个同类型对象 a 和 b 的值。对于 std::string,它会调用 std::string::swap 以实现高效交换。两者的主要区别如下:
| 维度 | std::string::swap | 标准库 swap |
|---|---|---|
| 调用方式 | 成员函数,通过对象调用(如 s1.swap(s2);)。 | 全局模板函数,需传入两个对象(如 std::swap(s1, s2);)。 |
| 通用性 | 仅适用于 std::string 对象。 | 是通用模板函数,适用于所有支持交换的类型(如基本类型、vector、自定义类等)。 |
| 实现机制 | 专门针对 std::string 优化,直接交换内部数据。 | 对于 std::string,内部会调用 std::string::swap 优化;对于其他类型,若未自定义 swap,则通过拷贝赋值等方式实现。 |
#include <string>
#include <utility>
int main() { std::string s1 = "hello", s2 = "world"; s1.swap(s2); // 使用成员函数交换 std::swap(s1, s2); // 使用标准库 swap 交换(等价于上一行) return 0;
}
简而言之,std::string::swap 是 std::string 类的专属成员函数,而标准库 swap 是更通用的模板函数。
9. std::string::pop_back
std::string::pop_back 是 C++11 引入的成员函数,用于删除 std::string 对象末尾的字符,其定义为 void pop_back();。
功能特点
- 无参数无返回值:直接修改调用它的
std::string对象,缩短其长度,不返回任何值。 - 操作对象:移除字符串的最后一个字符。例如:
#include <string>
#include <iostream>
int main() { std::string s = "hello"; std::cout << "Before: " << s << "\n"; // 输出 "Before: hello" s.pop_back(); std::cout << "After: " << s << "\n"; // 输出 "After: hell" return 0;
}
注意事项
- 若对空字符串调用
pop_back,会导致未定义行为。使用前建议通过empty()或size()检查字符串是否非空:
std::string s;
if (!s.empty()) { s.pop_back();
}
pop_back 为字符串末尾字符的删除操作提供了简洁的实现,使用时需确保字符串非空,以避免潜在问题。
8. 非成员函数重载
接下来看这一块:

operator+:用于拼接字符串。可连接两个std::string、std::string与 C 风格字符串(const char*)、std::string与单个字符等,返回新的字符串。relational operators:实现字符串的关系比较(如==、!=、<、>等),按字典序比较字符序列。swap:交换两个std::string对象的内容,高效且不涉及元素复制。operator>>:从输入流(如std::cin)中读取字符串,遇空白字符(空格、制表符、换行等)停止。operator<<:将字符串插入输出流(如std::cout),用于输出字符串内容。getline:从输入流读取一整行到std::string,包括空格,以换行符为结束标志(换行符不存入字符串)。
1. operator+(字符串拼接)
示例:
#include <string>
#include <iostream>
int main() { std::string s1 = "Hello, "; std::string s2 = "World!"; std::string result = s1 + s2; // 拼接成 "Hello, World!" std::cout << result << std::endl; return 0;
}
注意事项:
- 会生成一个新的字符串,原字符串
s1和s2内容不变。 - 频繁拼接大字符串时性能较低,因为每次操作都新建对象,可考虑
+=或append替代。
2. relational operators(关系运算符,如 ==、< 等)
示例:
#include <string>
#include <iostream>
int main() { std::string a = "apple"; std::string b = "banana"; if (a < b) { std::cout << "apple is lexicographically less than banana" << std::endl; } return 0;
}
注意事项:
- 按字典序比较字符,区分大小写(如
"Apple"与"apple"视为不同)。 - 所有字符都相同才返回
==,否则按首个不同字符的 ASCII 值判断大小。
3. swap(交换两个字符串内容)
示例:
#include <string>
#include <iostream>
int main() { std::string x = "foo"; std::string y = "bar"; std::swap(x, y); // x 变为 "bar",y 变为 "foo" std::cout << "x: " << x << ", y: " << y << std::endl; return 0;
}
注意事项:
- 两个操作数必须是
std::string类型。 - 操作高效,仅交换内部数据(如指针、长度、容量),不复制字符。
4. operator>>(从流中提取字符串)
示例:
#include <string>
#include <iostream>
int main() { std::string str; std::cin >> str; // 输入 "hello world",实际读取到 "hello"(遇空格停止) std::cout << "Read: " << str << std::endl; return 0;
}
注意事项:
- 遇空白字符(空格、制表符、换行)停止读取,空白字符留在流中。
- 若输入流错误(如文件结束或格式错误),流会处于错误状态,后续操作需检查
cin状态(如if (cin.fail()))。
5. operator<<(将字符串插入流)
示例:
#include <string>
#include <iostream>
int main() { std::string s = "Hello, C++!"; std::cout << s << std::endl; // 输出 "Hello, C++!" return 0;
}
注意事项:
- 若流处于错误状态(如
cout关联的缓冲区已满),插入操作可能失败,需检查流状态。 - 支持链式操作,如
std::cout << "Value: " << 42 << std::endl;。
6. getline(从流中读取一行到字符串)
示例:
#include <string>
#include <iostream>
int main() { std::string line; std::getline(std::cin, line); // 输入 "hello world",读取整行(包括空格) std::cout << "Line: " << line << std::endl; return 0;
}
注意事项:
- 默认以换行符
\n为结束标志,换行符不存入字符串。 - 若流一开始就失败(如文件已结束),
line内容不变,需检查流状态(如if (cin.eof()))。
9. 字符串操作

1. std::string::data
std::string::data 是 std::string 类的成员函数,其定义为 const char* data() const;,作用是返回一个指向字符串内部字符数组的 常量指针,该字符数组以空字符 '\0' 结尾,可用于兼容 C 风格字符串的操作(如传递给接受 const char* 的函数)。
示例
#include <string>
#include <iostream>
int main() { std::string s = "hello"; const char* ptr = s.data(); std::cout << ptr << std::endl; // 输出 "hello" return 0;
}
注意事项
- 常量指针:返回的
const char*不允许通过指针修改字符串内容,若尝试修改(如*ptr = 'a';),会导致编译错误。 - 指针有效性:只要
std::string对象未被销毁或修改(如push_back、resize等操作可能使指针失效),指针始终有效。 - 空字符结尾:确保返回的字符数组以
'\0'结尾,符合 C 风格字符串规范,便于与 C 语言函数交互。
2. std::string::copy
std::string::copy 是 std::string 类的成员函数,用于将字符串中的字符序列复制到指定的字符数组中,定义为:
size_t copy (char* s, size_t len, size_t pos = 0) const;
功能与参数
char\* s:目标字符数组的指针,用于接收复制的字符。size_t len:要复制的字符数量。size_t pos = 0:复制的起始位置(默认为0)。
返回值
实际复制的字符数(不超过 len,若 pos 超过字符串长度,返回 0;若 pos + len 超过字符串长度,仅复制至末尾)。
示例
#include <string>
#include <iostream>
int main() { std::string str = "hello world"; char arr[6]; // 预留足够空间(如复制 5 个字符) std::size_t copied = str.copy(arr, 5, 0); arr[copied] = '\0'; // 手动添加终止符 std::cout << arr << std::endl; // 输出 "hello" return 0;
}
注意事项
- 缓冲区溢出:确保目标数组
s有足够空间容纳len个字符,否则会导致未定义行为。 - 起始位置合法性:
pos不能超过字符串长度,否则返回0且不复制任何字符。 - 无自动终止符:函数不会自动添加
'\0',若需将目标数组作为 C 风格字符串使用,需手动添加终止符。 - 灵活复制:可指定复制长度和起始位置,相比
data()方法(返回以'\0'结尾的完整字符串),更适合按需复制部分内容。
该函数在需要精确控制复制字符数量和起始位置,且兼容 C 风格字符数组操作时非常有用,但需注意手动管理终止符和缓冲区空间。
3. 一坨查找函数find()

1. std::string::find
std::string::find 是 C++ 中用于在 std::string 中查找特定内容的成员函数,提供了四种重载形式
size_t find(const string& str, size_t pos = 0) const;- 功能:从位置
pos(默认从0开始)起,查找子串str在当前字符串中首次出现的位置。 - 示例:
- 功能:从位置
std::string s = "hello world";
auto pos = s.find("ll", 0); // 查找子串 "ll",返回 2
-
- 注意:若未找到,返回
std::string::npos,使用前需检查返回值。
- 注意:若未找到,返回
-
size_t find(const char* s, size_t pos = 0) const;- 功能:从位置
pos起,查找 C 风格字符串s在当前字符串中首次出现的位置。 - 示例:
std::string s = "hello world"; auto pos = s.find("world", 0); // 查找 "world",返回 6- 注意:
s需以'\0'结尾,否则行为未定义。
- 功能:从位置
-
size_t find(const char* s, size_t pos, size_t n) const;- 功能:从位置
pos起,查找s所指字符数组的前n个字符(无视'\0')在当前字符串中首次出现的位置。 - 示例:
- 功能:从位置
char arr[] = {'w', 'o', 'r'};
std::string s = "hello world";
auto pos = s.find(arr, 0, 3); // 查找前 3 个字符 "wor",返回 6
-
- 注意:
n不能为0,否则可能导致未定义行为。
- 注意:
size_t find(char c, size_t pos = 0) const;- 功能:从位置
pos起,查找字符c在当前字符串中首次出现的位置。 - 示例:
- 功能:从位置
std::string s = "hello world";
auto pos = s.find('w', 0); // 查找字符 'w',返回 6
-
- 注意:字符需为
char类型,区分大小写(如'W'与'w'视为不同)。
- 注意:字符需为
所有重载形式均返回 size_t 类型的位置索引,若未找到则返回 std::string::npos。使用时务必检查返回值,避免对 npos 进行非法操作(如作为索引访问字符串)。
2. std::string::rfind
这个就是反方向找.
size_t rfind(const string& str, size_t pos = npos) const;- 从位置
pos(默认为npos,即整个字符串)开始,向前查找子串str在当前字符串中最后一次出现的位置。 - 示例:
- 从位置
std::string s = "hello world";
auto pos = s.rfind("l"); // 查找字符 'l' 最后一次出现的位置,返回 9
//其实就是理解成, 从最后一个字符开始向前找, 只要目标一出现出现, 就返回目标位置, 这里就以这个例子讲:
//从后面开始向前找"l", "l"首次出现的位置就是下标9.
//就理解成反方向的find就行了.
size_t rfind(const char* s, size_t pos = npos) const;- 从位置
pos开始,向前查找 C 风格字符串s(以'\0'结尾)在当前字符串中最后一次出现的位置。 - 示例:
- 从位置
std::string s = "hello world";
auto pos = s.rfind("world"); // 查找 "world",返回 6
size_t rfind(const char* s, size_t pos, size_t n) const;- 从位置
pos开始,向前查找s所指字符数组的前n个字符(无视'\0')在当前字符串中最后一次出现的位置。 - 示例:
- 从位置
char arr[] = {'w', 'o', 'r'};
std::string s = "hello world";
auto pos = s.rfind(arr, s.size(), 3); // 查找前 3 个字符 "wor",返回 6
size_t rfind(char c, size_t pos = npos) const;- 从位置
pos开始,向前查找字符c在当前字符串中最后一次出现的位置。 - 示例:
- 从位置
std::string s = "abcabc";
auto pos = s.rfind('a'); // 查找字符 'a',返回 3
注意事项
- 若未找到目标内容,所有重载形式均返回
std::string::npos,使用前需检查返回值,避免对npos进行非法操作(如作为索引访问字符串)。 pos的取值范围应合理,虽为向前查找,但pos不能超过字符串长度,否则可能导致未定义行为。
rfind 函数为字符串中字符或子串的逆向查找提供了灵活的方式,适用于需要定位最后一次出现位置的场景(如清理后缀、查找最后匹配项等)。
3. std::string::find_first_of
std::string::find_first_of 用于在 std::string 中查找第一个属于指定字符集合的字符,有四种重载形式:
size_t find_first_of(const string& str, size_t pos = 0) const;- 从位置
pos开始,在当前字符串中查找第一个出现在str子串中的字符。 - 示例:
- 从位置
std::string s = "hello123world";
std::string chars = "123";
size_t pos = s.find_first_of(chars); // 查找 "123" 中任意字符,返回 5(字符 '1' 的位置)
if (pos != std::string::npos) { std::cout << "Found at: " << pos << std::endl;
}
size_t find_first_of(const char* s, size_t pos = 0) const;- 从位置
pos开始,查找 C 风格字符串s中任意字符在当前字符串中首次出现的位置。 - 示例:
- 从位置
std::string s = "abc123";
size_t pos = s.find_first_of("12x"); // 查找 "12x" 中任意字符,返回 3(字符 '1' 的位置)
size_t find_first_of(const char* s, size_t pos, size_t n) const;- 从位置
pos开始,查找s所指字符数组的前n个字符中任意一个在当前字符串中首次出现的位置(无视'\0')。 - 示例:
- 从位置
char arr[] = {'x', 'y', 'z', 'a'};
std::string s = "abcde";
size_t pos = s.find_first_of(arr, 0, 3); // 查找前 3 个字符 "xyz",返回 0(字符 'a' 不在前 3 个,实际这里假设 arr 是其他情况,重新举例:若 s="xyabc",则找前 3 个字符,返回 0)
size_t find_first_of(char c, size_t pos = 0) const;- 从位置
pos开始,查找字符c在当前字符串中首次出现的位置。 - 示例:
- 从位置
std::string s = "hello";
size_t pos = s.find_first_of('l'); // 查找字符 'l',返回 2
注意事项
- 若未找到匹配字符,所有重载形式均返回
std::string::npos,使用前需检查返回值,避免对npos进行非法操作(如作为索引访问字符串)。 - 只要找到字符集合中的任意一个字符即停止查找,返回其位置,与集合中其他字符无关。
find_first_of 函数在需要定位字符串中特定字符集合的首个字符时非常实用,例如验证字符串是否包含某些字符或提取特定字符前的内容等场景。
4. std::string::find_last_of
和上面那个差不多
5. std::string::find_first_not_of
std::string::find_first_not_of 用于在 std::string 中查找第一个 不属于 指定字符集合的字符,有四种重载形式:
size_t find_first_not_of(const string& str, size_t pos = 0) const;- 从位置
pos开始,在当前字符串中查找第一个 不属于str子串中任意字符的位置。 - 示例:
- 从位置
#include <string>
#include <iostream>
int main() { std::string s = "hello world"; std::string chars = "hel"; size_t pos = s.find_first_not_of(chars); if (pos != std::string::npos) { std::cout << "First character not in 'hel': " << pos << std::endl; // 输出 4(字符 'o' 的位置) } return 0;
}
size_t find_first_not_of(const char* s, size_t pos = 0) const;- 从位置
pos开始,查找 不属于 C 风格字符串s(以'\0'结尾)中任意字符的首个位置。 - 示例:
- 从位置
#include <string>
#include <iostream>
int main() { std::string s = "abc123"; size_t pos = s.find_first_not_of("abc"); if (pos != std::string::npos) { std::cout << "First character not in 'abc': " << pos << std::endl; // 输出 3(字符 '1' 的位置) } return 0;
}
size_t find_first_not_of(const char* s, size_t pos, size_t n) const;- 从位置
pos开始,查找 不属于s所指字符数组前n个字符(无视'\0')的首个位置。 - 示例:
- 从位置
#include <string>
#include <iostream>
int main() { char arr[] = {'a', 'b', 'c'}; std::string s = "abcd123"; size_t pos = s.find_first_not_of(arr, 0, 3); if (pos != std::string::npos) { std::cout << "First character not in first 3 of arr: " << pos << std::endl; // 输出 3(字符 'd' 的位置) } return 0;
}
size_t find_first_not_of(char c, size_t pos = 0) const;- 从位置
pos开始,查找第一个 不是 字符c的位置。 - 示例:
- 从位置
#include <string>
#include <iostream>
int main() { std::string s = "aaaaab"; size_t pos = s.find_first_not_of('a'); if (pos != std::string::npos) { std::cout << "First character not 'a': " << pos << std::endl; // 输出 5(字符 'b' 的位置) } return 0;
}
注意事项
- 若所有字符都属于指定集合,函数返回
std::string::npos。使用前需检查返回值,避免对npos进行非法操作(如作为索引访问字符串)。 - 该函数常用于过滤或验证字符串前缀(如去除前缀中特定字符)。
find_first_not_of 函数为字符串中特定字符集合的排除查找提供了灵活方式,适用于需要定位首个非匹配字符的场景(如清理前缀、验证字符串格式等)。
6. std::string::find_last_not_of
和上面那个差不多
ok, 这一集就这样吧, 大家先知道这些是什么东西, 以及先用起来先, 底层后面会讲的.
总结
这里面的操作其实总结起来就是我们先前学习数据结构的时候都操作, 增删查改. 不过这里提供给我们的接口丰富些, 规范些. 不过总的来说就是这些操作.