卷积神经网络基础(十)
之前我们学习了SGD、Momentum和AdaGrad三种优化方法,今天我们将继续学习Adam方法。
6.1.6 Adam
我们知道Momentum参照的是小球在碗中滚动的物理规则进行移动而实现的,AdaGrad为参数的每个元素适当地调整更新步伐。那如果我们将这两种方法融合在一起会不会得到一个更加有效的方法呢?这就是Adam方法的基本思路。
Adam于2015年提出,虽然理论较为复杂,但直观来讲,就是融合了Momentum和AdaGrad方法。组合二者之间的优点,实现参数空间的高效搜索。此外,对超参数进行“偏置矫正”也是其特征。
Adam解决最优化问题的结果如下所示:
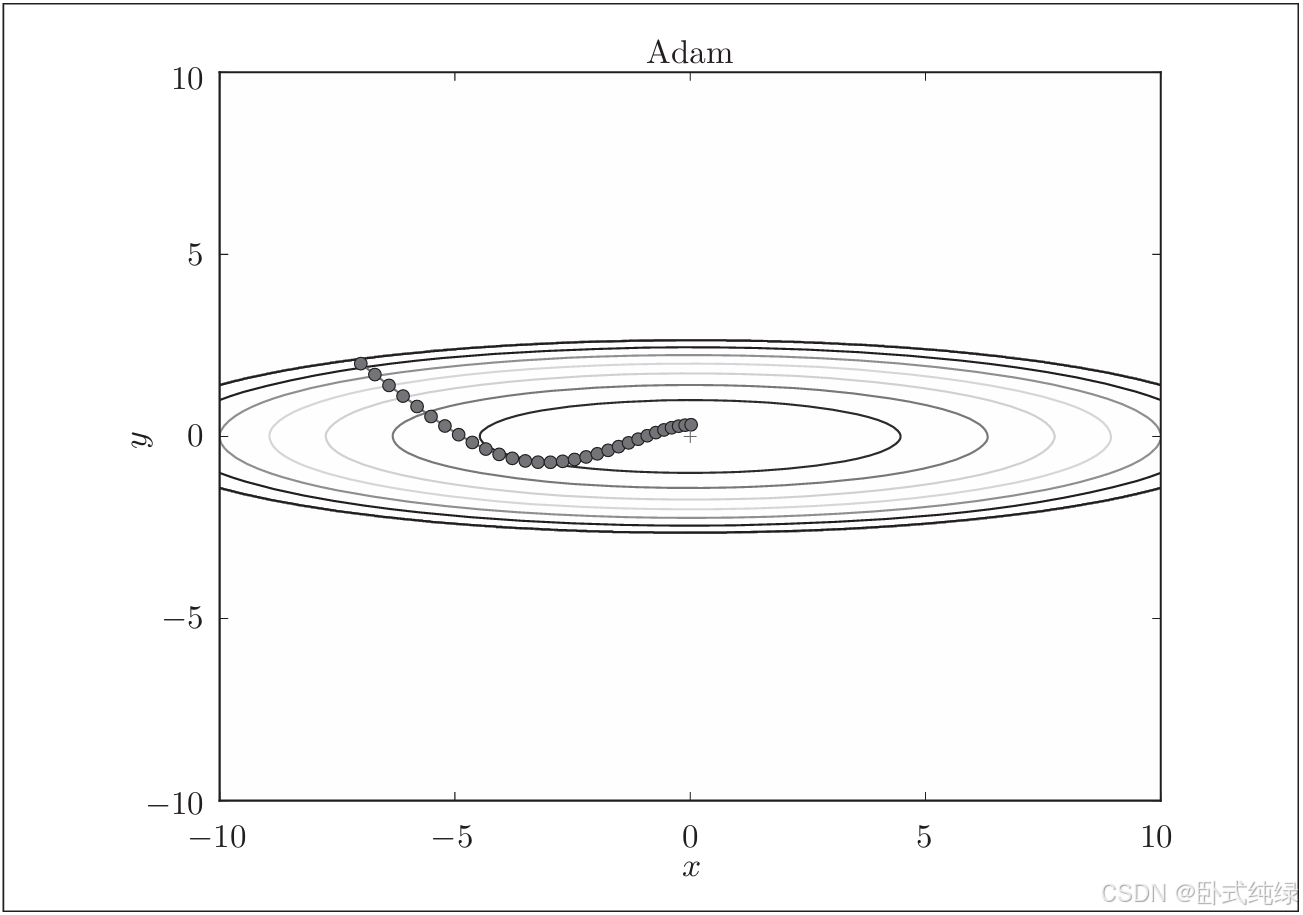
Adam的更新过程就像小球在碗中滚动一样,虽然也有类似Momentum的移动,但是相比之下Adam的左右摇晃程度减轻,得益于学习的更新程度被适当的调整了。
Adam会设置三个超参数,一个是学习率α,另外两个是momentum系数β1和二次momentumβ2.论文中这两个momentum系数分别设置为0.9和0.999.设置了这些值后,大多数情况下都能顺利运行。
6.1.7 如何选择更新方法
目前为止,我们学习了四种更新方法:SGD、Momentum、AdaGrad和Adam。四种方法的参数更新路径不同,超参数设置不同结果也会发生变化。更新路径如下所示:
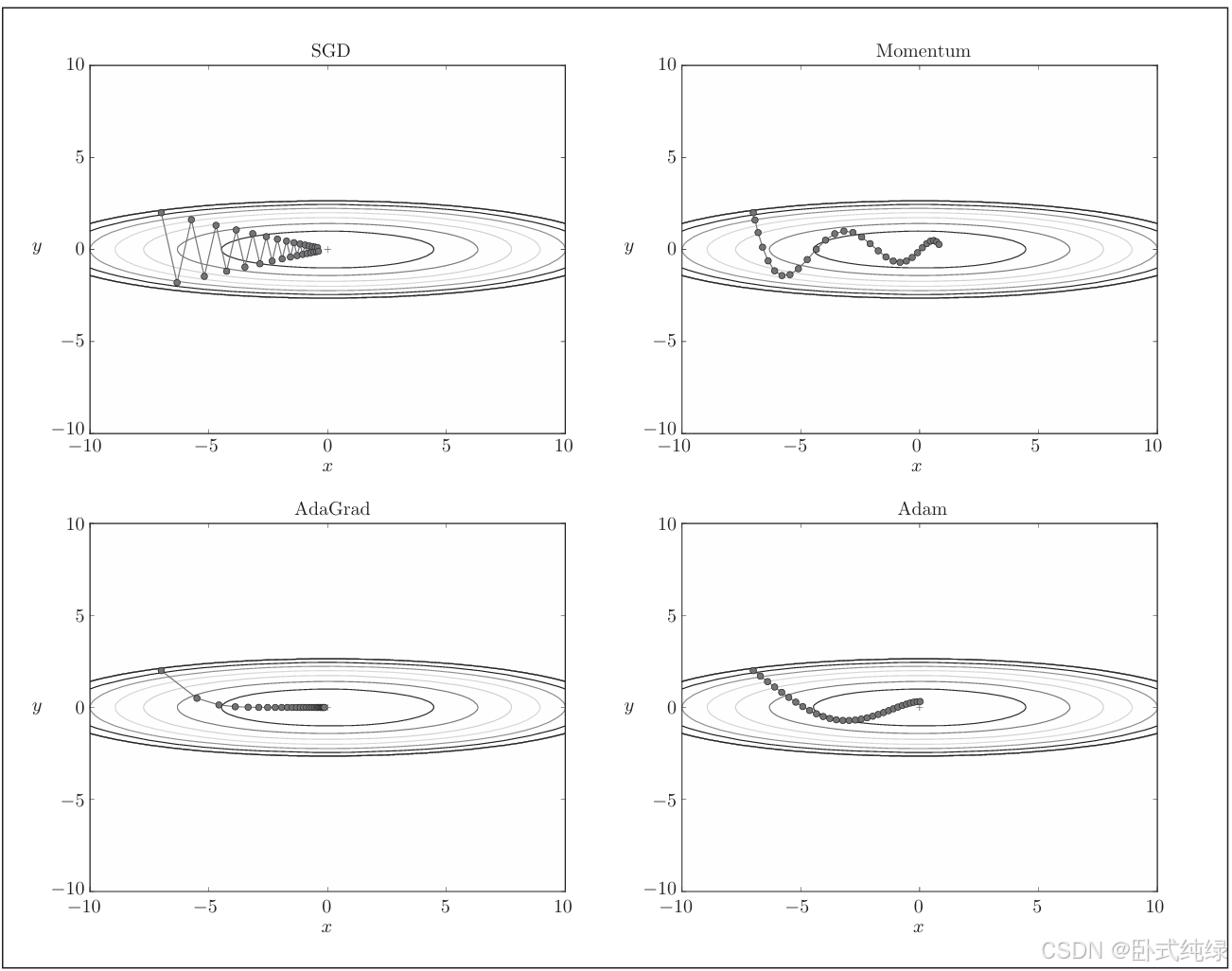
很遗憾的是,没有一种方法在所有情况下都能表现良好,各有各的特点,要根据具体的问题选择合适的方法。很多研究中至今仍在使用SGD,Momentum和AdaGrad也值得一试。另外最近很多研究人员和技术人员喜欢使用Adam。本书中主要使用的是SGD和Adam。
6.1.8 基于MNIST数据集的更新方法比较
首先我们以手写数字识别为例子来比较这四种方法,并确认不同方法在学习进展上有多大程度的差异。先来看结果:
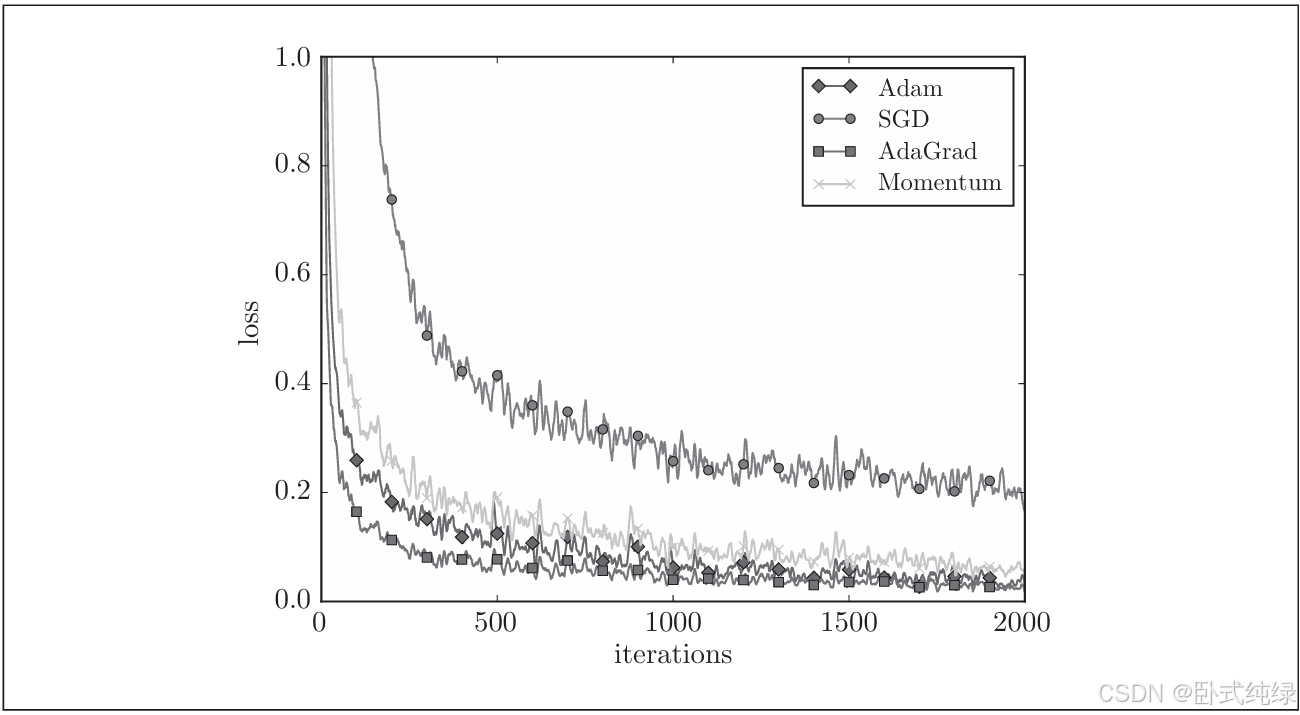
其中横轴为迭代次数,纵轴为损失函数的值(loss)。
这个实验以一个五层神经网络为对象,其中每层100个神经元,激活函数为ReLU。
从结果来看,相比于SGD,另外三种方法收敛的更快,而且速度基本相同。仔细来看的花AdaGrad学习稍微快一点。需要注意的是:实验结果会随学习率等超参数、神经网络结构的不同而发生变化。一般而言,与SGD相比,其他三种方法学习更快。