Mysql数据库相关命令及操作
目录
一.基本操作
1.SQL分类
2.相关命令及作用
二.数据类型
三.修饰符
四.函数及相关命令
1.数学函数
2. 聚合函数
3.字符串函数
4.group by 分组
5.order by 排序
6.limit
7.having
8.视图view
9.正则表达式
五.多表查询
1.子查询
2.联合查询 纵向合并
3.交叉连接 横向合并
4.内连接
5.外连接
6.自连接
六.用户管理
1 存放用户信息的表
2.查看当前使用用户
3.新建用户
4.修改用户名称
5.删除用户
6.修改用户密码
7.破解密码
8.远程登录
9.用户权限管理
10.撤销权限
一.基本操作
1.SQL分类
-
数据库:database
-
表:table,行:row 列:column
-
索引:index
-
视图:view
-
存储过程:procedure
-
存储函数:function
-
触发器:trigger
-
事件调度器:event scheduler,任务计划
-
用户:user
-
权限:privilege
SQL语言规范
-
在数据库系统中,SQL 语句不区分大小写,建议用大写
-
SQL语句可单行或多行书写,默认以 " ; " 结尾
-
关键词不能跨多行或简写 select drop create
-
用空格和TAB 缩进来提高语句的可读性
-
子句通常位于独立行,便于编辑,提高可读性
SQL语句分类
-
DDL: Data Defination Language 数据定义语言
CREATE,DROP,ALTER
-
DML: Data Manipulation Language 数据操纵语言
INSERT,DELETE,UPDATE
软件开发:CRUD
-
DQL:Data Query Language 数据查询语言
SELECT
-
DCL:Data Control Language 数据控制语言
GRANT,REVOKE
-
TCL:Transaction Control Language 事务控制语言
COMMIT,ROLLBACK,SAVEPOINT
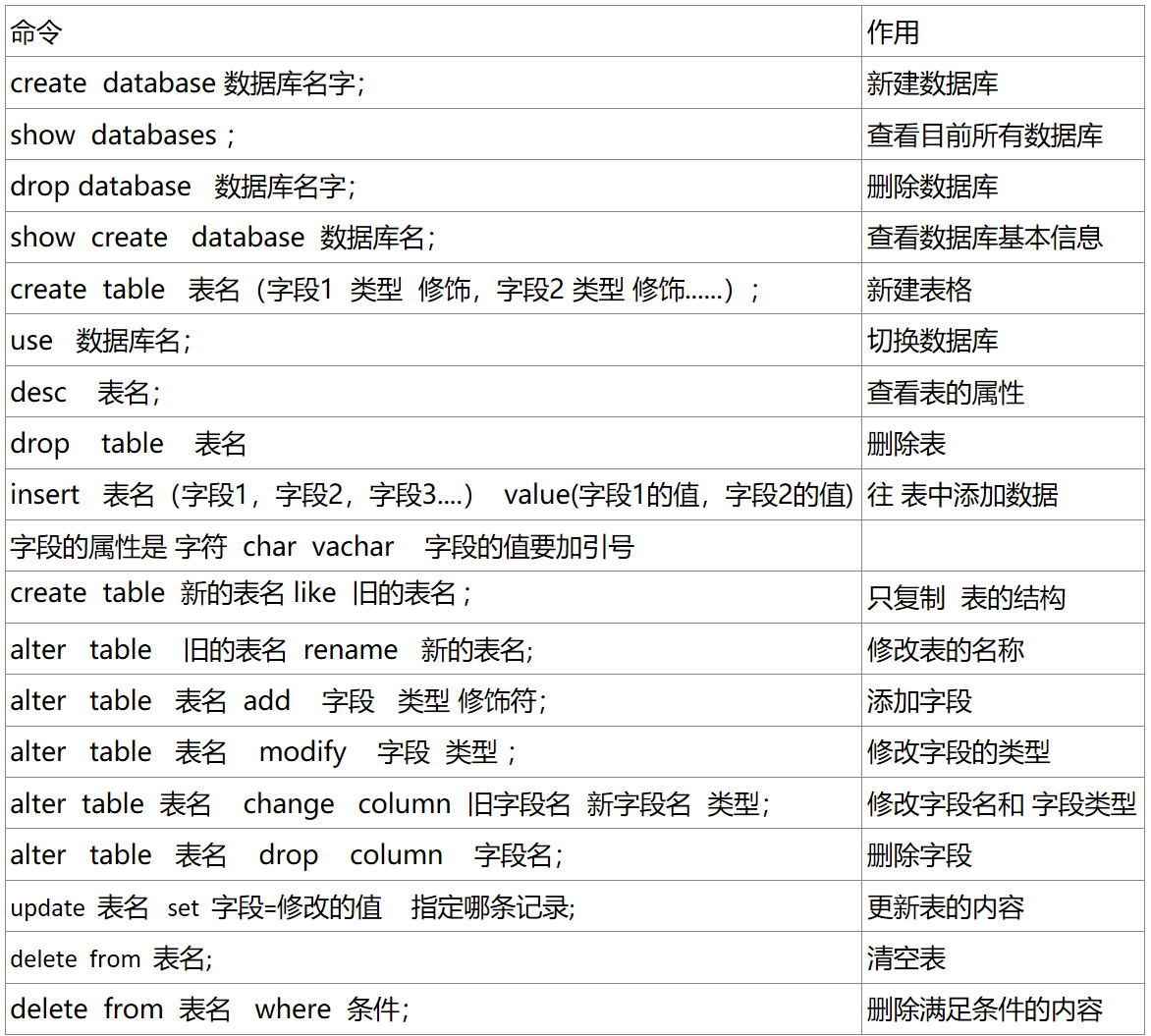
2.相关命令及作用
二.数据类型
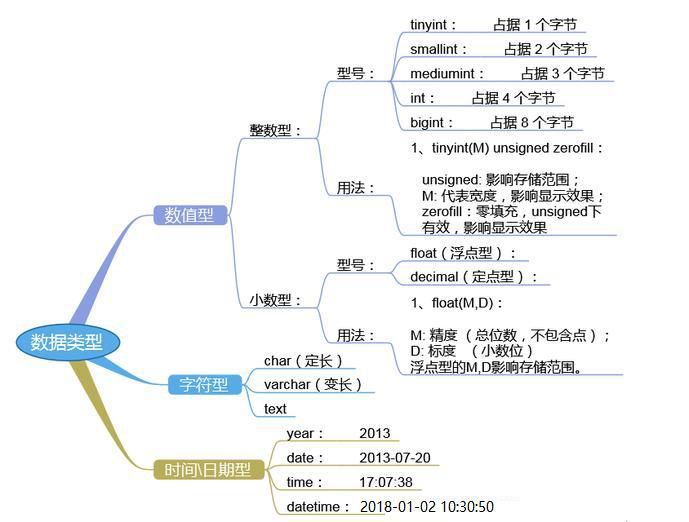
选择正确的数据类型对于获得高性能至关重要,三大原则:
-
更小的通常更好,尽量使用可正确存储数据的最小数据类型
-
简单就好,简单数据类型的操作通常需要更少的CPU周期
-
尽量避免NULL,包含为NULL的列,对MySQL更难优化
三.修饰符
| 名称 | 含义 |
|---|---|
| NULL | 数据列可包含NULL值,默认值 |
| NOT NULL | 数据列不允许包含NULL值,*为必填选项 |
| DEFAULT | 默认值 |
| PRIMARY KEY | 主键,所有记录中此字段的值不能重复,且不能为NULL 一张表中只有一个主键 |
| UNIQUE KEY | 唯一键,所有记录中此字段的值不能重复,但可以为NULL |
| CHARACTER SET | name 指定一个字符集 |
四.函数及相关命令
1.数学函数
| 函数名 | 函数值 |
|---|---|
| abs(x) | 返回 x 的绝对值 |
| rand() | 返回 0 到 1 的随机数 |
| mod(x,y) | 返回 x 除以 y 以后的余数 |
| power(x,y) | 返回 x 的 y 次方 |
| round(x ) | 返回离 x 最近的整数 |
| round(x,y) | 保留 x 的 y 位小数四舍五入后的值 |
| sqrt(x) | 返回 x 的平方根 |
| truncate(x,y) | 返回数字 x 截断为 y 位小数的值 |
| ceil(x) | 返回大于或等于 x 的最小整数 |
| floor(x) | 返回小于或等于 x 的最大整数 |
| greatest(x1,x2...) | 返回集合中最大的值,也可以返回多个字段的最大的值 |
| least(x1,x2...) | 返回集合中最小的值,也可以返回多个字段的最小的值 |
例子:
select abs(-100); #取绝对值
select rand(); #随机数 0到1 间
select mod(10,3); #10 除3 取余数
select power(2,3) #求2的3次方
select round(2.6); #返回离2.6最近的整数3
select sqrt(9); #返回9 的平方根
select truncate (1.235,2); #返回前两位值
select ceil (1.5); #返回大于等于1.5 的值
select floor (1.5); #返回小于等于1.5 的值
select greatest(1,2,3); #返回集合中的 最大值
select least(1,2,3); #返回集合中的最小值
2. 聚合函数
| 函数名 | 函数意 |
|---|---|
| avg() | 返回指定列的平均值 |
| count() | 返回指定列中非 NULL 值的个数 |
| min() | 返回指定列的最小值 |
| max() | 返回指定列的最大值 |
| sum(x) | 返回指定列的所有值之和 |
语法格式:
select 函数(*) from 表名; # * 代表所有字段
select 函数(单个字段) from 表名;
-
avg
例子: avg 平均值
select avg(age) from students; #avg 所有人的平均值
select avg(age) from students where classid=1; #求1班年龄平均值
-
count
例子: count 返回指定列中非 NULL 值的个数
select count(classid) from students; #统计非空classid 字段 一共有多少行记录
select count(distinct classid) from students; #一共有几个班级 去重
select count(classid) from students; #统计一共有多少个班级
select count(*) from students; #统计一共有多少条数据
聚合函数 count() 括号中是具体的字段 如果有null 值不统计
count() 括号中是 * 会统计 null
#count(*) 包括了所有的列的行数,在统计结果的时候,不会忽略列值为 NULL
#count(列名) 只包括列名那一列的行数,在统计结果的时候,会忽略列值为 NULL 的行
-
min
例子 : min 最小值
select min(age) from students;
-
max
例子:max 最小值
select max(classid) 班级最大序号 from students;
-
sum
例子:sum 求和
select sum(age) from students; #求年龄总和
select sum(age) from students where classid=1; #求1班的年龄总和
3.字符串函数
| 函数名 | 函数意义 |
|---|---|
| concat(x,y) | 将提供的参数 x 和 y 拼接成一个字符串 |
| substr(x,y) | 获取从字符串 x 中的第 y 个位置开始的字符串, |
| substr(x,y,z) | 获取从字符串 x 中的第 y 个位置开始长度为 z 的字符串 |
| length(x) | 返回字符串 x 的长度 |
| replace(x,y,z) | 将字符串 z 替代字符串 x 中的字符串 y |
| upper(x) | 将字符串 x 的所有字母变成大写字母 |
| lower(x) | 将字符串 x 的所有字母变成小写字母 |
| left(x,y) | 返回字符串 x 的前 y 个字符 |
| right(x,y) | 返回字符串 x 的后 y 个字符 |
| repeat(x,y) | 将字符串 x 重复 y 次 |
| space(x) | 返回 x 个空格 |
| strcmp(x,y) | 比较 x 和 y,返回的值可以为-1,0,1 |
| reverse(x) | 将字符串 x 反转 |
-
concat
例子:
#concat
select concat(name,classid) from students where stuid=1; #将姓名字段和班级字段合在一起
select concat(name,' ',classid) from students whereere classid=1; #加空格
-
substr
select substr(name,1,3) from students; # 获取name 字段的 前1到3 个字符
select name from students where stuid=25; #
select substr(name,3) from students where stuid=25;
select substr(name,1,3) from students where stuid=25;
其他
select length(name) from students where stuid=1; #返回数据的长度
select replace(name,"y",11) from students where stuid=1; # 将name 字段中的 y 换成11
select left(name,3) from students where stuid=1; #显示name字段左边三个字符 即最开始的三个
select right(name,3) from students where stuid=1; #显示name字段 右边三个字符 即最后三个
select repeat(name,2) from students where stuid=1; #将name 字段 重复显示2次
select lower(name) from students; #返回结果全是小写字母
select reverse(name) from students where stuid=1; # 反向显示字符串
4.group by 分组
语法:
SELECT "字段1", 聚合函数("字段2") FROM "表名" GROUP BY "字段1";
例子:
select gender,avg(age) from students group by gender; #按性别分组 求平均值
select classid,avg(age) from students group by classid; #班级的年龄平均值
5.order by 排序
语法:
SELECT "字段" FROM "表名" [WHERE "条件"] ORDER BY "字段" [ASC, DESC];
#ASC 是按照升序进行排序的,是默认的排序方式。
#DESC 是按降序方式进行排序。
例子:
select * from students order by age; #年龄升序排列
select * from students order by age desc; #年龄降序排
select * from students order by age desc limit 3;
select * from students where classid=1 order by age; #找出1班的人按升序排序
6.limit
select * from students order by age limit 5; #取前5个数据
select * from students limit 3,5; #跳过前3个 往后取 5个
7.having
HAVING 语句的存在弥补了 WHERE 关键字不能与聚合函数联合使用的不足
例子:
select classid,count(classid) from students group by classid having classid > 3;
select classid,count(classid) from students where classid > 3 group by classid;
select classid,count(classid) from students group by classid where classid > 3;
8.视图view
视图:数据库中的虚拟表,这张虚拟表中不包含真实数据,只是做了映射
格式:
create view 视图名 as 查询结果
例子:
create view v1 as select * from students where age > 50;
show tables;
select * from v1;
update students set age=90 where stuid=25;
select * from v1;
9.正则表达式
匹配 描述
^ 匹配文本的开始字符
$ 匹配文本的结束字符
. 匹配任何单个字符
* 匹配零个或多个在它前面的字符
+ 匹配前面的字符 1 次或多次字符串 匹配包含指定的字符串
p1|p2 匹配 p1 或 p2
[…] 匹配字符集合中的任意一个字符
[^…] 匹配不在括号中的任何字符
{n} 匹配前面的字符串 n 次
{n,m} 匹配前面的字符串至少 n 次,至多 m 次
{,m} 最多m次
{n,} 最少n次
? 匹配一个字符
例子:
select name from students where name regexp '^s'
select name from students where name regexp 's';
select name from students where name regexp 's.i';
select name from students where name regexp '^s|l';
五.多表查询
1.子查询
例子: 先求出平均年龄 然后再找出比平均年龄大的
select avg(age) from students; #求平均年龄
select * from students where age > (select avg(age) from students); #再找出比平均年龄大的
例子: 利用子查询更新数据
SELECT avg(Age) FROM teachers #先计算出 教师表的 平均年龄
update students set Age=(SELECT avg(Age) FROM teachers) where stuid=25; # 再把第25个学生的年龄改成 教师表的平均年龄
例子: 将students 表里的 平均年龄,作为 值 赋给teacher表
update teachers set age= (select avg(age) from students) where tid=4;
#将students 表里的 平均年龄,作为 值 赋给teacher表
2.联合查询 纵向合并
联合查询 Union 实现的条件,多个表的字段数量相同,字段名和数据类型可以不同,但一般数据类型是相同的.
例子: 合并两张表 纵向合并
select name,age from students union select name,age from teachers;
默认union 是会自动去重的
select * from teachers union select *from teachers;
union all 是不会去重的
select * from teachers union all select *from teachers;
3.交叉连接 横向合并
例子:
select * from students cross join teachers;
select * from students
cross join
teachers;
4.内连接
例子:
select * from students inner join teachers on students.teacherid=teachers.tid;
update students set teacherid=2 where stuid=7;
update students set teacherid=2 where stuid=22;
select *from students inner join teachers on students.teacherid=teachers.tid;
5.外连接
例子:
select * from students s left join teachers t on s.teacherid=t.tid;
select * from students s right join teachers t on s.teacherid=t.tid;
6.自连接
#构建新表
create table emp (id int, name varchar(10),leaderid int);
insert emp values(1,'cxk',null),(2,'wyf',1),(3,'zhang',2),(4,'li',3);
select * from emp e left join emp l on e.leaderid=l.id;
select e.name emp_name, l.name leader_name from emp e left join emp l on e.leaderid=l.id;
六.用户管理
1 存放用户信息的表
mysql 的用户 放在mysql数据库中的user表中
select user,host,authentication_string from mysql.user;
+---------------+-----------+
| user | host |
+---------------+-----------+
| mysql.session | localhost |
| mysql.sys | localhost |
| root | localhost |
+---------------+-----------+
root@localhost 默认存在的, 并且只能 本地登录无法远程登录
#新版本
select user,host,authentication_string from mysql.user;
2.查看当前使用用户
(root@localhost) [(none)]> select user();
3.新建用户
格式:
CREATE USER '用户名'@'来源地址' [IDENTIFIED BY [PASSWORD] '密码'];
----------------------------------------------------------------------------------------------------------
'用户名':指定将创建的用户名
'来源地址':指定新创建的用户可在哪些主机上登录,可使用IP地址、网段、主机名的形式,本地用户可用localhost,允许任意主机登录可用通配符%
'密码': 若使用明文密码,直接输入'密码',插入到数据库时由Mysql自动加密;
若使用加密密码,需要先使用SELECT PASSWORD('密码'); 获取密文,再在语句中添加 PASSWORD '密文';
若省略“IDENTIFIED BY”部分,则用户的密码将为空(不建议使用)
----------------------------------------------------------------------------------------------------------
'USERNAME'@'HOST'
'用户名'@'来源地址'
@'HOST': 主机名: user1@'web1.kgc.org'
IP地址或Network
通配符: % _
示例:zhou@172.16.%.%
user2@'192.168.1.%'
kgc@'10.0.0.0/255.255.0.0'
例子:
mysql -u用户名 -p密码 -h远程主机 -P端口号
set global validate_password_policy=0;
set global validate_password_length=1;
create user test@'192.168.%.%'; #建立远程登录用户
create user zhou@'192.168.91.%' identified by '123123'; #可以后面加密码
create user test1 identified by '123123';
select user,host,password from mysql.user; #查看字段 密码为空
mysql -utest -h192.168.91.100 -p密码 #使用其他主机登录
alter user test@'192.168.91.%' identified by 'abc123; # 修改密码 新版可以 旧版的mariadb 不可以
ALTER USER test@'192.168.%.%' IDENTIFIED BY 'centos';
4.修改用户名称
格式:
rename user '旧名字' to '新名字;
例子:
rename user 'zhangsan'@'192.168.91.%' to 'lisi'@'192.168.91.%';
5.删除用户
格式:
drop user 用户名@主机名
例子:
drop user liwu@'%';
6.修改用户密码
密码有安全性策略可以修改取消
set global validate_password_policy=0;
set global validate_password_length=1;
#修改密码策略
格式:
SET PASSWORD = PASSWORD('abc123'); #只能改自己当前
set password for '用户' = password('密码'); #
例子:
set password = 'abc123'; #给当前用户修改密码
set password for 'lisi'@'192.168.91.%' = 'abc123'; #给其他用户修改密码
7.破解密码
修改配置文件
vim /etc/my.cnf
[mysqld]
skip-grant-tables
#数据库的单用户模式 此模式下权限受到限制,很多功能无法使用, 除了破解密码不要加此项
skip-networking #MySQL8.0不需要
#然后清空密码
update mysql.user set authentication_string='' where user='root' and host='localhost';
#注意刷新后生效
flush privileges;
8.远程登录
mysql -utest -h192.168.91.100 -p'密码' -P端口号
例子:
vim /etc/my.cnf
[mysqld]
port = 9527
systemctl restart mysqld
客户机
mysql -utest -h192.168.91.100 -p'Admin@123' -P9527
9.用户权限管理
权限类别:
-
管理类
-
程序类
-
数据库级别
-
表级别
-
字段级别
管理类:
-
CREATE USER
-
FILE
-
SUPER
-
SHOW DATABASES
-
RELOAD
-
SHUTDOWN
-
REPLICATION SLAVE
-
REPLICATION CLIENT
-
LOCK TABLES
-
PROCESS
-
CREATE TEMPORARY TABLES
库和表级别:针对 DATABASE、TABLE
-
ALTER
-
CREATE
-
CREATE VIEW
-
DROP INDEX
-
SHOW VIEW
-
WITH GRANT OPTION:能将自己获得的权限转赠给其他用户
数据操作
-
SELECT
-
INSERT
-
DELETE
-
UPDATE
字段级别
-
SELECT(col1,col2,...)
-
UPDATE(col1,col2,...)
-
INSERT(col1,col2,...)
所有权限
-
ALL PRIVILEGES 或 ALL
查看权限
SHOW GRANTS FOR 'lisi'@'%';
#USAGE权限只能用于数据库登陆,不能执行任何操作;USAGE权限不能被回收,即 REVOKE 不能删除用户。
授予权限
GRANT语句:专门用来设置数据库用户的访问权限。当指定的用户名不存在时,GRANT语句将会创建新的用户;当指定的用户名存在时, GRANT 语句用于修改用户信息。
格式:
GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'来源地址' [IDENTIFIED BY '密码'];
----------------------------------------------------------------------------------------------------------
#权限列表:用于列出授权使用的各种数据库操作,以逗号进行分隔,如“select,insert,update”。使用“all”表示所有权限,可授权执行任何操作。
#数据库名.表名:用于指定授权操作的数据库和表的名称,其中可以使用通配符“*”。例如,使用“kgc.*”表示授权操作的对象为 kgc数据库中的所有表。
#'用户名@来源地址':用于指定用户名称和允许访问的客户机地址,即谁能连接、能从哪里连接。来源地址可以是域名、IP地址,还可以使用“%”通配符,表示某个区域或网段内的所有地址,如“%.kgc.com”、“192.168.80.%”等。
#IDENTIFIED BY:用于设置用户连接数据库时所使用的密码字符串。在新建用户时,若省略“IDENTIFIED BY”部分,则用户的密码将为空。
----------------------------------------------------------------------------------------------------------
例子:
GRANT select ON kgc.* TO 'zhangsan'@'localhost' IDENTIFIED BY '123456';
#允许用户 zhangsan 在本地查询 kgc 数据库中 所有表的数据记录,但禁止查询其他数据库中的表的记录。
GRANT ALL [PRIVILEGES] ON *.* TO 'lisi'@'%' IDENTIFIED BY '123456';
#允许用户 lisi 在所有终端远程连接 mysql ,并拥有所有权限。
grant all on *.* to lisi@'192.168.91.%';
grant all on *.* to test@'192.168.91.%';
flush privileges;
#不要忘记刷新
quit
GRANT ALL ON *.* TO 'cxk'@'%' IDENTIFIED BY '123456';
10.撤销权限
格式:
REVOKE 权限列表 ON 数据库名.表名 FROM 用户名@来源地址;
例子:
REVOKE ALL ON *.* FROM 'cxk'@'%';
revoke all on *.* from zhou@"192.168.91.%";