怎样用 esProc 生成定长时间窗口列表并统计
某库表的 Time 字段是时间,Value 字段是需要统计的值。
| Time | Value |
| 10:10:05 | 3 |
| 10:11:06 | 4 |
| 10:13:13 | 5 |
| 10:13:19 | 9 |
| 10:13:32 | 8 |
| 10:14:35 | 2 |
现在要将数据按每分钟分成一个窗口,补上缺失的窗口,对每个窗口统计 4 个值:start_value,前一个窗口的最后一条;本窗口的最后一条;本窗口的最小值;本窗口的最大值。首个窗口的 start_value 用第一条记录的值代替;如果缺少某窗口的统计值,则用本窗口的 start_value 代替。
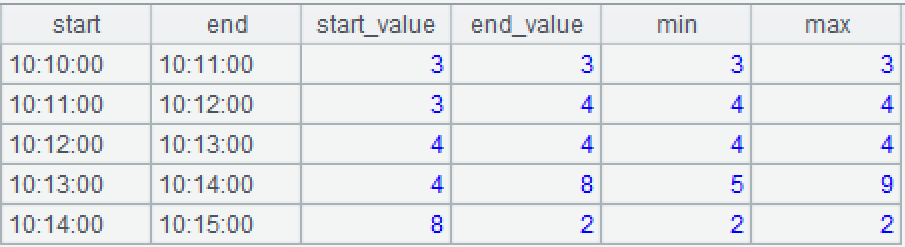
上例的计算结果如下:
| start | end | start_value | end_value | min | max |
| 10:10:00 | 10:11:00 | 3 | 3 | 3 | 3 |
| 10:11:00 | 10:12:00 | 3 | 4 | 4 | 4 |
| 10:12:00 | 10:13:00 | 4 | 4 | 4 | 4 |
| 10:13:00 | 10:14:00 | 4 | 8 | 5 | 9 |
| 10:14:00 | 10:15:00 | 8 | 2 | 2 | 2 |
涉及到生成时间序列、按时间序列对齐并分组、保持分组子集、按相对位置从子集取记录,SQL 很难直接实现。
esProc 提供了丰富的计算函数,包括生成时间序列,按序列对齐、保持分组子集、按位置访问:esProc Web Try
| A | |
| 1 | $select * from main.txt order by Time |
| 2 | =A1.run(Time=time@m(Time)) |
| 3 | =list=periods@s(A2.min(Time),A2.max(Time),60) |
| 4 | =A2.align@a(list,Time) |
| 5 | =A4.new(list(#):start, elapse@s(start,60):end, sv=ifn(end_value[-1],~.Value):start_value, ifn(~.m(-1).Value, sv):end_value, ifn(~.min(Value),sv):min, ifn(~.max(Value),sv):max) |
A1:加载数据。
A2:将 Time 字段修改为整分钟数,比如 10:10:05->10:10:00。函数 run 用于循环修改记录,函数 time 可以格式化时间,@m 表示取整分钟数。
A3:根据起止时间,生成连续分钟数的时间序列。函数 periods 用于生成时间序列,@s 表示间隔单位是秒。
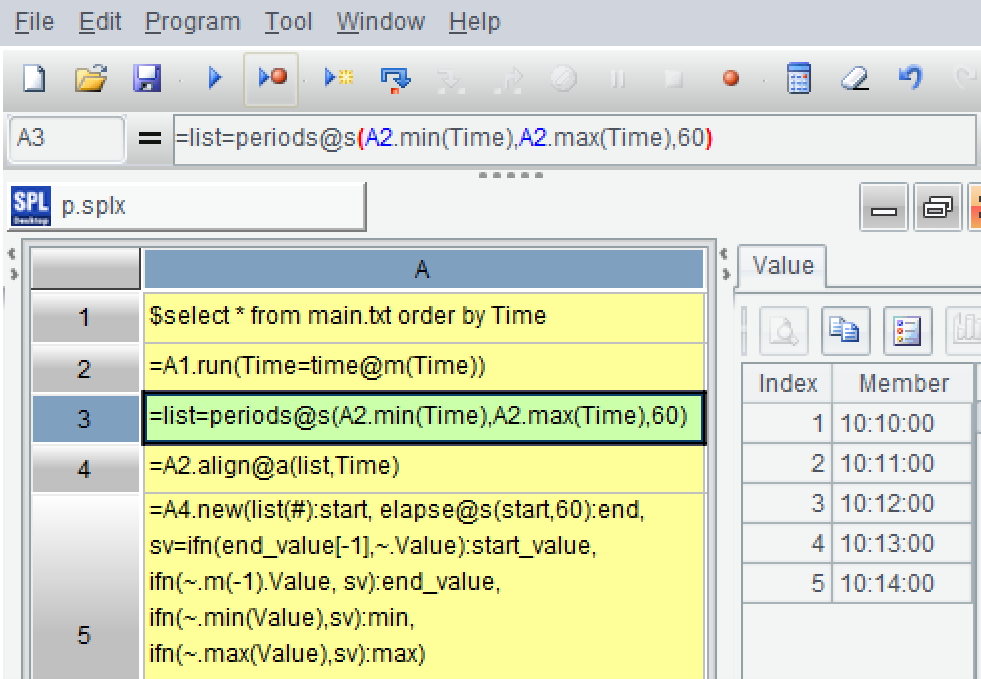
A4:将数据按时间序列对齐,每组是一个窗口的数据,有些窗口是空集,没有对应的记录,比如 10:12:00。函数 align 可将记录按指定序列对齐,默认取各组第 1 条记录,@a 表示取所有记录。对齐后不能立刻汇总,而是要保持分组子集,用于进一步计算。
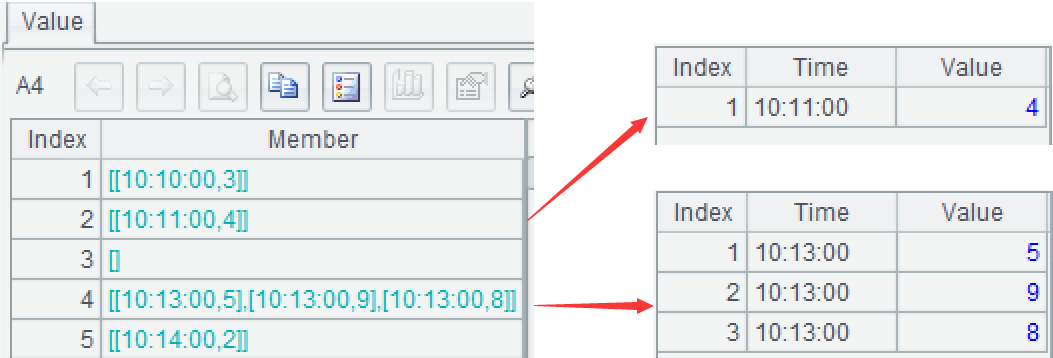
A5:用 new 函数生成新二维表,A4 的每组数据(每个窗口)对应一条新记录。
start 是当前窗口的起始时间,list(#) 表示按位置从 list 取成员,# 是当前窗口的序号。
end 是当前窗口的终止时间,elapse@s(start,60) 表示起始时间加 60 秒钟后的时间,函数 elapse 用于时间加减,@s 表示单位为秒。
start_value是前一个窗口的最后一条,sv=ifn(end_value[-1],~.Value)表示取上一个窗口的 end_value(后面有解释),如果该值为空,则取本窗口默认(第 1 条记录)的 Value;最后将变量 sv 赋值为 start_value。函数 ifn 返回首个非空的参数。[-1] 表示上一条记录 / 上一组 / 上一个窗口。~ 表示当前记录 / 当前组 / 当前窗口。
end_value 是本窗口的最后一条,ifn(~.m(-1).Value, sv)表示取本窗口的最后一条的 Value,如果该值为空,则取 sv。函数 m 可按绝对位置取成员,m(-1)表示倒数第 1 条,m(n)是正数第 n 条,可以简写做 (n),前面的 list(#) 就是这种用法。
min是本窗口的最小值,ifn(~.min(Value),sv) 表示取本窗口的最小值,如果该值为空,则取 sv。max 是本窗口最大值,代码类似。
esProc是开源免费的,下载试用~~