OpenCv高阶(十四)——LBPH人脸识别
文章目录
- 前言
- 一、LBPH原理
- 1. LBP(局部二值模式)特征提取
- 2. 图像分块处理
- 3. 生成直方图
- 4. 人脸识别(匹配阶段)
- 5. LBPH的特点
- 6. 变种与优化
- 二、LBPH人脸识别简单实现
- (一)LBPH人脸识别
- 1、图像读取(灰度转换)
- 2、创建识别器
- 3、模型训练
- 4、预测阶段
- (二)摄像头人脸识别
- 1. 中文文本叠加函数
- 2. 训练数据准备
- 3. LBPH识别器初始化
- 4. 实时人脸检测与识别
- 总结
前言
在人工智能技术蓬勃发展的今天,深度学习模型(如CNN、Transformer)在人脸识别领域占据主导地位。然而,在计算资源有限或需要快速部署的场景中,经典算法依然展现出独特的价值。LBPH(Local Binary Patterns Histograms) 作为一种基于纹理特征的人脸识别算法,凭借其简洁的原理、高效的实现和对光照变化的鲁棒性,成为传统方法中的代表性技术。
LBPH的核心思想源于对图像局部纹理特征的捕捉。它不依赖复杂的数学模型,而是通过比较像素邻域的灰度关系,生成具有判别性的特征向量。这种“轻量化”特性使其在嵌入式设备、实时监控系统等场景中依然广泛应用。本文将深入解析LBPH的原理、实现流程及其实际应用,并通过代码实践展示如何构建一个实时人脸识别系统。无论是希望理解传统图像处理技术的本质,还是寻求在资源受限环境中部署高效算法的开发者,都能从中获得启发。
一、LBPH原理
LBPH(Local Binary Patterns Histograms,局部二值模式直方图)是一种基于纹理特征的人脸识别算法,其核心思想是通过提取图像的局部纹理信息,并结合空间分布特征进行人脸匹配。以下是其原理的详细分步解释:
1. LBP(局部二值模式)特征提取
基本思想:将图像的每个像素与其邻域像素进行对比,生成二进制模式,描述局部纹理特征。
具体步骤:
邻域选择:以中心像素 (xc,yc) 为中心,选择一个邻域(如3×3的正方形或圆形邻域)。
二值化:将邻域像素值与中心像素值比较,若邻域像素值大于等于中心值,标记为1;否则标记为0。
二进制转十进制:按固定顺序(如顺时针)排列二值结果,形成一个二进制数,再转换为十进制作为该中心像素的LBP值。
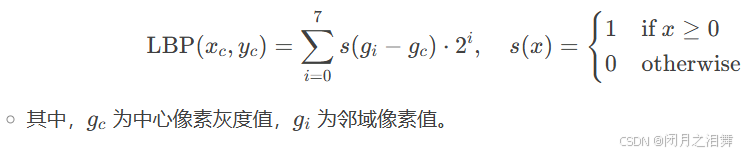
2. 图像分块处理
目的:保留局部特征的空间分布信息,避免全局直方图丢失位置信息。
方法:将人脸图像划分为多个子区域(如16×16的块),每个子区域单独计算LBP特征。
3. 生成直方图
子区域直方图:对每个子区域内的所有像素LBP值统计直方图。假设LBP取值范围为0~255(8位邻域),则每个子区域直方图有256个维度。
全局特征向量:将所有子区域的直方图按顺序连接,形成整张图像的LBPH特征向量。例如,若图像分为4×4=16个子区域,则特征维度为16×256=4096。
4. 人脸识别(匹配阶段)
训练阶段:存储每个人脸样本的LBPH特征向量到数据库。
识别阶段:
提取待识别人脸的LBPH特征向量。
与数据库中所有特征向量进行相似度计算,常用距离度量包括:
卡方距离(Chi-Square):
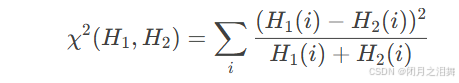
直方图交集(Histogram Intersection):
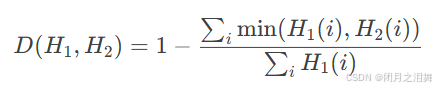
选择距离最小的样本作为识别结果。
5. LBPH的特点
优点:
对光照变化鲁棒(依赖相对灰度而非绝对亮度)。
计算简单,适合实时应用。
缺点:
对姿态、表情变化敏感。
分块策略影响性能(需平衡子区域大小和特征维度)。
6. 变种与优化
均匀模式(Uniform Patterns):减少二进制模式数量,仅保留跳变次数≤2的模式(如从256维降至59维),降低计算量。
多尺度LBP:使用不同半径的邻域提取多尺度纹理特征。
结合其他特征:与HOG、深度学习特征融合提升性能。
二、LBPH人脸识别简单实现
(一)LBPH人脸识别
# 导入OpenCV和NumPy库
import cv2
import numpy as np# 准备训练数据
image = []
# 读取多张训练图像(灰度模式),薛之谦(xzq)、刘亦菲(lyf)、彭逸畅(pyc)各2张
image.append(cv2.imread('../data/face-detect/xzq1.png', 0)) # 参数0表示以灰度模式读取
image.append(cv2.imread('../data/face-detect/xzq2.png', 0))
image.append(cv2.imread('../data/face-detect/lyf1.png', 0))
image.append(cv2.imread('../data/face-detect/lyf2.png', 0))
image.append(cv2.imread('../data/face-detect/pyc1.png', 0))
image.append(cv2.imread('../data/face-detect/pyc2.png', 0))# 定义标签(与图像顺序对应):0-薛之谦,1-刘亦菲,2-彭逸畅
labels = [0, 0, 1, 1, 2, 2]# 创建标签与名称的映射字典(-1表示未知)
dic = {0: '薛之谦', 1: "刘亦菲", 2: "彭逸畅", -1: '无法识别'}# 读取待预测图像(灰度模式)
predict_image = cv2.imread('../data/face-detect/lyf.png', 0)# 创建LBPH人脸识别器(底层实现LBPH算法)
# 可选参数:radius(邻域半径)、neighbors(邻域点数)、grid_x/grid_y(分块数量)
recognizer = cv2.face.LBPHFaceRecognizer_create()# 训练模型(核心步骤)
# 输入:图像列表 + 标签数组(需转换为numpy数组)
recognizer.train(image, np.array(labels))# 进行预测
# 返回:预测标签、置信度(数值越小置信度越高)
label, confidence = recognizer.predict(predict_image)# 输出结果
print("这位是", dic[label]) # 根据标签获取姓名
print("置信度", confidence) # 显示置信度(理想值通常小于60)
1、图像读取(灰度转换)
cv2.imread('path', 0) # 0表示灰度模式
作用:将图像转换为单通道灰度图,符合LBPH对灰度特征的需求
原理关联:LBP依赖像素间的相对灰度值比较
2、创建识别器
cv2.face.LBPHFaceRecognizer_create()
参数说明(默认值):
radius=1:邻域半径
neighbors=8:邻域点数(圆形采样)
grid_x=8, grid_y=8:图像分块数量
3、模型训练
recognizer.train(image, np.array(labels))
内部操作:
对每个图像提取LBPH特征(分块统计直方图)
存储特征向量与标签的映射关系
4、预测阶段
recognizer.predict(predict_image)
内部操作:
提取待识别图像的LBPH特征
与所有训练特征进行距离计算(默认使用卡方距离)
返回最近邻的标签和置信度
(二)摄像头人脸识别
1. 中文文本叠加函数
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFontdef cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=30):""" 向OpenCV图像添加中文文本(解决OpenCV不支持中文的问题)"""if isinstance(img, np.ndarray): # 判断输入是否为OpenCV的numpy数组格式# 将BGR格式的OpenCV图像转换为RGB格式的PIL图像img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))draw = ImageDraw.Draw(img) # 创建PIL绘图对象# 加载中文字体文件(需要确保simhei.ttf文件存在)fontStyle = ImageFont.truetype("../data/simhei.ttf", textSize, encoding="utf-8")draw.text(position, text, textColor, font=fontStyle) # 绘制文本# 将PIL图像转换回OpenCV的BGR格式return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
作用:解决OpenCV无法直接显示中文的问题,通过PIL库实现中文渲染
2. 训练数据准备
# 加载训练图像(灰度模式)
image = []
image.append(cv2.imread('../data/face-detect/xzq1.png', 0)) # 薛之谦样本
image.append(cv2.imread('../data/face-detect/xzq2.png', 0))
image.append(cv2.imread('../data/face-detect/lyf1.png', 0)) # 刘亦菲样本
image.append(cv2.imread('../data/face-detect/lyf2.png', 0))
image.append(cv2.imread('../data/face-detect/pyc1.png', 0)) # 彭逸畅样本
image.append(cv2.imread('../data/face-detect/pyc2.png', 0))
image.append(cv2.imread('../data/face-detect/lyf4.png', 0)) # 新增样本
image.append(cv2.imread('../data/face-detect/lyf5.png', 0))
image.append(cv2.imread('../data/face-detect/pyc3.png', 0))
image.append(cv2.imread('../data/face-detect/pyc4.png', 0))
image.append(cv2.imread('../data/face-detect/pyc5.png', 0))# 定义标签(存在潜在问题:标签3未在字典中定义)
labels = [0, 0, 1, 1, 2, 2, 1,1,2,2,2] # 前6个对应0/1/2,后续3对应3(未定义)
dic = {0: '薛之谦', 1: "刘亦菲", 2: "彭逸畅", -1: '无法识别'} # 缺少标签3的映射
这里面的数据可以更换成待识别的人脸图片,注意需要转换成灰度图片。
3. LBPH识别器初始化
#创建LBPH人脸识别器,设置置信度阈值为70
recognizer = cv2.face.LBPHFaceRecognizer_create(threshold=70)
recognizer.train(image, np.array(labels)) # 训练模型
参数说明:
threshold=70:当预测置信度超过该值时返回-1(无法识别)
训练时会将每个图像的LBPH特征与标签关联存储
4. 实时人脸检测与识别
# 加载Haar级联分类器(需要确保xml文件路径正确)
faceCascade = cv2.CascadeClassifier(r'./myface-detect/haarcascade_frontalface_alt.xml')# 初始化摄像头
cap = cv2.VideoCapture(0)
if not cap.isOpened():print('视频打开失败')exit()while True:ret, frame = cap.read() # 读取视频帧frame = cv2.flip(frame, 1) # 水平翻转(镜像效果)gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 转换为灰度图# 人脸检测(使用Haar级联分类器)faces = faceCascade.detectMultiScale(gray,scaleFactor=1.05, # 图像缩放因子(用于多尺度检测)minNeighbors=16, # 候选框最少邻居数(值越大检测越严格)minSize=(8, 8) # 最小人脸尺寸)# 遍历检测到的人脸for (x, y, w, h) in faces:cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 2), 2) # 绘制矩形框# 提取人脸区域(ROI),扩展20像素边界roi = gray[y-20:y+h+20, x-20:x+w+20] # 注意可能超出图像边界# LBPH识别预测label, confidence = recognizer.predict(roi)# 添加中文标签(存在标签3未定义的风险)frame = cv2AddChineseText(frame, dic[label], (x-10, y-20), (0, 255, 0), 16)cv2.imshow('image', frame) # 显示结果if not ret: breakif cv2.waitKey(1) == 27: break # ESC键退出cap.release()
cv2.destroyAllWindows()
效果
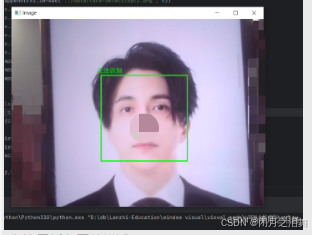
这里图片库内的图片数量较少,所以导致识别效果很差.
总结
LBPH算法以其独特的局部二值模式,为图像特征提取提供了一种高效且直观的解决方案。通过本文的探讨,我们可以总结以下关键点:
技术优势
低计算开销:无需GPU加速,适合边缘计算场景。光照鲁棒性:依赖相对灰度值,对光照变化具有天然适应性。可解释性:直方图特征直观,便于调试和优化。
应用场景
嵌入式设备(如门禁系统、智能摄像头)快速原型开发(结合OpenCV等工具链)与其他算法融合(如作为深度学习模型的预处理模块)
局限性
对姿态和表情变化敏感,需配合人脸对齐技术。特征维度较高,需通过分块策略平衡精度与效率。
尽管深度学习在准确率上远超传统方法,但LBPH的“轻量化哲学”仍为开发者提供了重要启示:在追求性能的同时,不应忽视算法的简洁性与可部署性。未来,将LBPH与轻量级神经网络结合,或利用其纹理特征增强模型鲁棒性,可能是值得探索的方向。
无论是作为学习计算机视觉的入门课题,还是作为实际项目的技术备选,LBPH都值得开发者深入理解与实践。毕竟,在技术迭代的浪潮中,经典算法的智慧始终熠熠生辉。