PostgreSQL 初体验
目录
一、PostgreSQL
1. 简介
2. 特点
(1) 开源免费(Open Source)
(2)标准兼容(SQL Compliance)
(3) 丰富的数据类型(Data Types)
(4) 强大的事务与并发控制(Transactions & Concurrency)
(5)高度可扩展(Extensibility)
(6)企业级安全性(Security)
3. 优势
4. 架构
5. 应用场景
6. 结论
二、安装PostgreSQL
1. 编译安装
(1)安装编译安装所需环境
(2)编译安装
(3)配置环境变量
(4)登录数据库
三、PostgreSQL 结构
1. PG 的逻辑结构编辑
2. PG 的物理结构
(1)软件安装目录
(2)数据库目录结构编辑
(3)数据库有两个基础的对象,一个是oid, 一个是表空间
(4)base 的物理布局设计
(5)表空间跟数据库关系
一、PostgreSQL
1. 简介
PostgreSQL(简称Postgres)是一款功能强大的开源对象-关系型数据库管理系统(ORDBMS),强调对SQL标准的全面支持,并逐渐发展成为兼具关系型数据库严谨性和面向对象灵活性的开源数据库。
其核心设计理念包括高度可扩展性、数据完整性及对复杂查询的支持,广泛应用于企业级应用、数据分析、地理信息系统(GIS)等领域
2. 特点
(1) 开源免费(Open Source)
- 基于 PostgreSQL License(类 BSD 协议),允许自由使用、修改和商业发布,无版权限制。
- 社区驱动开发,全球开发者贡献代码,版本迭代活跃(如近年新增 JSONB 全文索引、向量存储等前沿功能)。
(2)标准兼容(SQL Compliance)
- 支持 ANSI SQL 标准(如窗口函数、CTE、事务隔离级别),同时扩展了大量企业级特性(如递归查询、行级锁)。
- 兼容 SQL/JSON 标准,JSONB 类型支持高效索引和查询,适合现代 Web 应用的半结构化数据场景。
(3) 丰富的数据类型(Data Types)
- 基础类型:除传统数值、字符串、日期外,支持数组(Array)、枚举(Enum)、范围类型(如 int4range 表示整数区间)。
- 高级类型:
- 空间数据:通过 PostGIS 扩展支持几何图形(Point、LineString、Polygon)和地理信息系统(GIS)功能。
- 全文搜索:内置 tsvector/tsquery 类型,支持分词、模糊匹配和相关性排序。
- 新兴类型:支持 JSONB(可索引的 JSON)、XML、IPv6、UUID,以及 PostgreSQL 15 + 新增的向量类型(用于 AI / 机器学习场景)。
(4) 强大的事务与并发控制(Transactions & Concurrency)
- ACID 强一致性:通过预写日志(WAL, Write-Ahead Logging)保证数据持久化,崩溃恢复机制可靠。
- MVCC(多版本并发控制):默认隔离级别为 Read Committed,通过版本号实现无锁读,避免写锁阻塞读操作,适合高并发场景(如电商订单、实时分析)。
- 细粒度锁控制:支持表级锁、行级锁(SELECT ... FOR UPDATE)和 advisory lock(自定义应用层锁)。
(5)高度可扩展(Extensibility)
- 插件生态:通过 CREATE EXTENSION 机制快速集成功能,例如:
- PostGIS:空间数据处理,用于地图服务、物流轨迹分析。
- pg_cron:定时任务调度,替代 Linux cron。
- Citus:分布式扩展,支持分库分表,提升大数据量下的查询性能。
- pg_stat_statements:SQL 性能分析,定位慢查询。
- 自定义函数:支持 PL/pgSQL、Python、Java 等多语言编写存储过程,甚至动态加载 C 语言扩展。
- 存储过程与触发器:支持复杂业务逻辑下沉到数据库层,减少应用层压力。
(6)企业级安全性(Security)
- 认证机制:支持 LDAP、Kerberos、SCRAM-SHA-256 密码认证,兼容多认证源(如 AWS IAM 数据库认证)。
- 权限控制:基于角色(ROLE)的细粒度权限管理,支持表级、列级权限(如敏感字段隐藏)和行级安全策略(RLS, Row-Level Security),实现 “不同用户看到不同数据”。
- 加密能力:
- 传输层:支持 SSL/TLS 加密连接,防止数据窃听。
- 存储层:通过 pgcrypto 扩展实现字段级加密,或集成云服务商的透明数据加密(TDE)。
- 审计日志:内置日志记录功能,可追踪 SQL 操作,满足合规性要求(如 GDPR、等保 2.0)。
3. 优势
-
高性能:PostgreSQL 通过优化查询计划、支持并行查询、分区表等特性,提供卓越性能表现,即使处理大规模数据和高并发访问时,也能保持高效响应速度。
-
高可用性:支持主从复制、流复制和逻辑复制等多种复制方式,使数据库系统轻松实现高可用性和容灾备份,故障时能快速恢复服务,确保业务连续性。
-
灵活性:丰富的数据类型和高级特性使其能灵活应对各种复杂业务场景,无论是结构化数据还是非结构化数据,都能提供强大支持。
-
社区支持:拥有活跃的开发者社区和丰富生态系统,社区中有大量教程、文档和插件可供使用,众多经验丰富的开发者也愿意分享经验、解答问题。
-
成本效益:作为开源软件,降低了企业成本投入,其卓越性能和广泛应用场景使其成为许多企业的首选数据库产品。
4. 架构
逻辑层面包含数据库集群、表空间、数据库、Schema、表、索引等结构;
物理层面包括数据文件、日志文件、参数文件、控制文件等存储方式,其中数据块(Page)作为数据读写基本单位,在 PostgreSQL 中扮演关键角色。通过优化数据块的读写效率和布局方式,PostgreSQL 能进一步提高性能表现。
5. 应用场景
-
企业应用:如ERP、CRM、HRM等系统,需要处理复杂的事务和查询操作;postgresql凭借其高性能和事务处理能力,能够为企业应用提供稳定可靠的数据支持。
-
数据分析:在数据仓库和商业智能领域,PostgreSQL 凭借其丰富的数据类型和高级查询特性,能够轻松应对大规模数据分析和挖掘任务。
-
web 应用:对于需要高并发访问和实时数据处理的 Web 应用来说,PostgreSQL 的 MVCC 机制和扩展性特性使得其成为了一个理想的选择。
-
地理信息系统:通过 PostGIS 扩展,PostgreSQL 能够支持地理空间数据的存储和分析功能,为 GIS 应用提供了强大的数据支持。
-
物联网与大数据:随着物联网和大数据技术的不断发展,PostgreSQL 凭借其高性能、可扩展性和丰富的数据类型特性,在物联网和大数据领域中也得到了广泛的应用。
6. 结论
PostgreSQL 是一款功能强大、开源的数据库管理系统,在信息化建设中发挥越来越重要的作用,其丰富的特性、卓越的性能、灵活的应用场景以及强大的社区支持使它成为了众多企业与开发者的首选数据库产品。
二、安装PostgreSQL
1. 编译安装
(1)安装编译安装所需环境
1.下载依赖包 dnf -y install gcc libicu libicu-devel readline-devel zlib zlib-devel
2. 解压 tar zxvf
3. 切换进目录(2)编译安装
配置编译 ./configure --prefix=/usr/local/pgsql
make && make install(3)配置环境变量
5.创建用户 useradd postgres
6.创建数据存储目录 mkdir /usr/local/pgsql/data
7.改目录归属 chown -R postgres /usr/local/pgsql/data
8.配置环境变量 vim /etc/profile函数库路径 export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/loacl/pgsql/lib命令路径 export PATH=$PATH:/usr/local/pgsql/bin
9.刷新环境变量 source /etc/profile
查看 echo $PATH/LD_LIBRARY_PATH(4)登录数据库
10.初始化
切换用户 su - postgres
初始 /usr/local/pgsql/bin/initdb -D /usr/local/pgsql/data
11.启动数据库
启动程序 /usr/local/pgsql/bin/pg_ctl -D /usr/local/pgsql/data -l logfile start
12.登录
psql三、PostgreSQL 结构
1. PG 的逻辑结构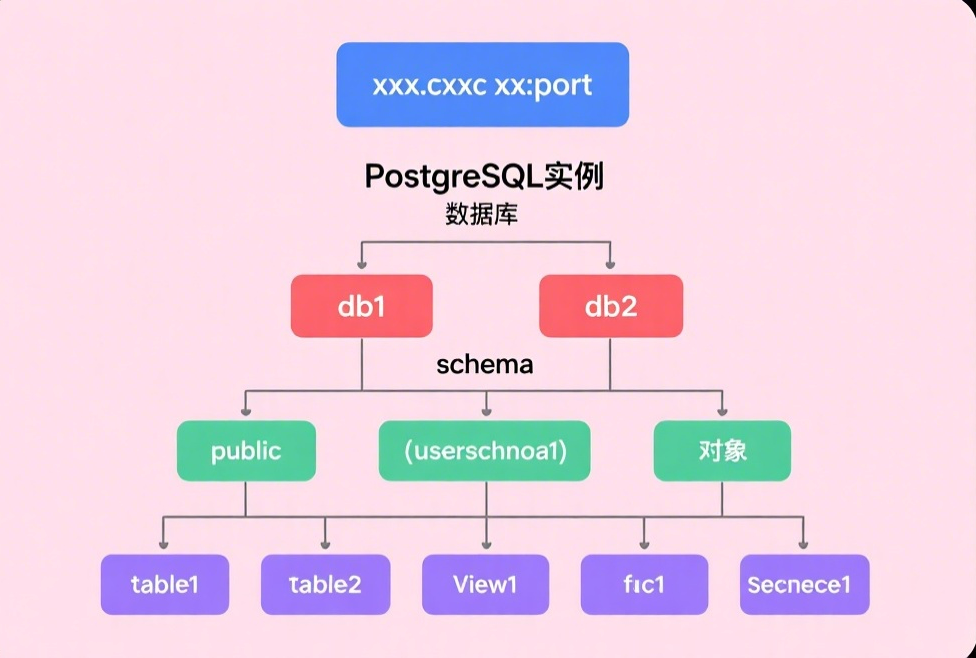
-
集群(Cluster):
-
一个 PostgreSQL 服务实例对应一个集群,包含多个数据库。
-
通过
initdb初始化时创建,是物理数据存储的顶层容器。
-
-
数据库(Database):
-
集群内可创建多个数据库,每个数据库独立(默认不共享数据)。
-
用户通过
CREATE DATABASE创建,不同数据库通过名称隔离。
-
-
模式(Schema):
-
每个数据库包含多个模式(类似于命名空间),用于逻辑分组表、视图等对象。
-
默认模式为
public,可通过CREATE SCHEMA创建新模式
-
-
User 用户:
-
postgres 用户是默认创建的超级管理员;每个数据库都有一个 OWNER 用户,每个用户可以 OWNER 多个数据库。
-
-
数据库对象:
-
包含 table、index、view、序列、函数等,数据最终存储在表中。表由多个 page[block]组成,一个 page 包含(页头信息、空闲空间、Tuple),实际存储数据的区域对应到物理层面上是文件,由 page 构成。
-
模式内包含具体对象,如表、视图、索引、函数等。
-
对象通过
<schema>.<object>格式引用(如public.users
-
-
tablespace:存储数据库的一个逻辑空间,可以存放不同的数据库,对应在物理层面上是一个目录。
-
OID:所有数据库对象都有各自的 oid(object identifiers),oid 是一个无符号的四字节整数,相关对象的 oid 存放在相关的 system catalog 表中,如数据库的 oid 和表的 oid 分别存放在 pg_database、pg_class 表中。
- 总结:
(1)从大小排列:database cluster --> databases --> schema --> objects。
(2)Tablespace 是数据最大的存储空间,Database 是构成表空间的存储单元,pages 是 PostgreSQL 数据库中最小的 IO 单元。
2. PG 的物理结构
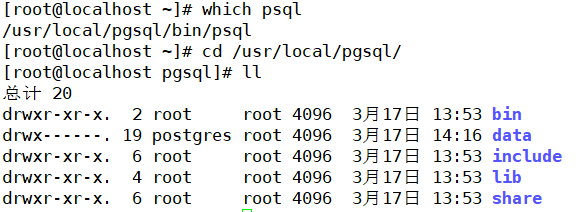
(1)软件安装目录
其中各个目录里的内容及用途:
- bin:二进制可执行文件,是 PG 数据库的所有相关命令所在,为方便使用需设置到环境变量中
- lib:动态库目录,PostgreSQL 运行所需要的动态库都在此目录下
- share:放有文档和配置模板文件,一些拓展插件的 SQL 文件在此目录下的 extension 中
- data:目录是数据库集群的物理存储核心,包含用户数据、元数据和配置文件
- include:目录则提供编译扩展和客户端程序所需的 C 语言头文件
(2)数据库目录结构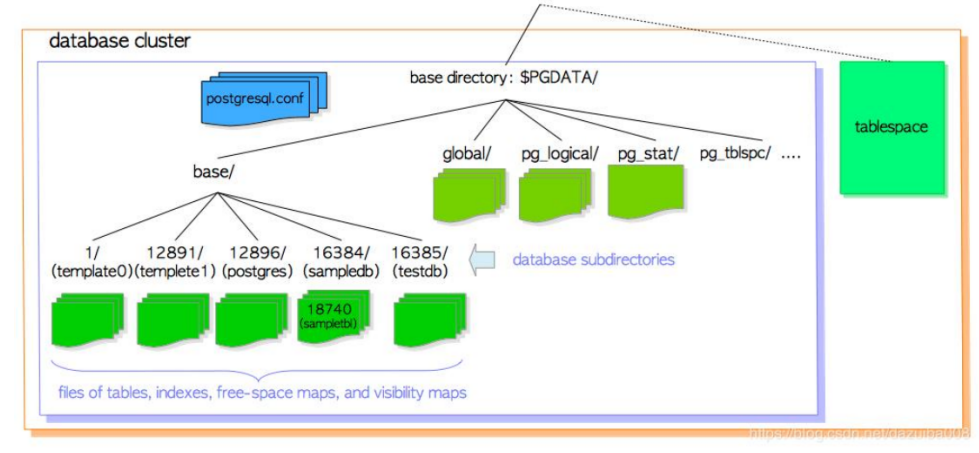
-bash - 4.2$ tree -L 1 -d /usr/local/pgsql/data/
/usr/local/pgsql/data/ —— 数据目录├── base —— 表和索引文件存放目录
├── global —— 影响全局的系统表存放目录
├── pg_commit_ts —— 事务提交时间戳数据存放目录
├── pg_dynshmem —— 被动态共享所使用的文件存放目录
├── pg_logical —— 用于逻辑复制的状态数据
├── pg_multixact —— 多事务状态的数据
├── pg_notify —— LISTEN/NOTIFY 状态的数据
├── pg_replslot —— 复制槽数据存放目录
├── pg_serial —— 已提交的可序列化信息存放目录
├── pg_snapshots —— 快照
├── pg_stat —— 统计信息
├── pg_stat_tmp —— 统计信息子系统临时文件
├── pg_subtrans —— 子事务状态数据
├── pg_tblspc —— 表空间
├── pg_twophase —— 预备事务状态文件
├── pg_wal —— 事务日志(预写日志)
└── pg_xact —— 日志提交状态的数据存放目录#是最小化系统,可以临时安装包管理器进行查看 yum install -y tree
#或手动解析成树状图 find /usr/local/pgsql/data/ -type d | sed 's/[^-][^\/]*\//--/g; s/^/ /; s/\/$/|/'
#非树状 ls -R /usr/local/pgsql/data/ 通过 -R 参数递归显示目录层级文件和目录相关作用描述
| files | description |
|---|---|
| PG_VERSION | 包含 PostgreSQL 主版本号的文件 |
| pg_hba.conf | 控制 PostgreSQL 客户端验证的文件,控制 PG 客户端认证主机、数据库、用户、IP 地址 |
| pg_ident.conf | 控制 PostgreSQL 用户名映射的文件,配置操作系统用户和数据库服务器上的用户映射 |
| postgresql.conf | 配置参数文件 |
| postgresql.auto.conf | 用于存储在 ALTER SYSTEM(版本 9.4 及更高版本)中设置的配置参数的文件 |
| postmaster.opts | 记录服务器上一次启动的命令行选项 |
| subdirectories | description |
| base/ | 包含每个数据库子目录的子目录 |
| global/ | 包含集群范围表的子目录,例如 pg_database 和 pg_control |
| pg_commit_ts/ | 包含事务提交时间戳数据的子目录。9.5 版本以后 |
| clog / 或 pg_xact(9.6 及 earlier) | 包含事务提交状态数据的子目录,它在版本 10 中重命名为 pg_xact。CLOG 将在 5.4 章节中讲解。 |
| dynshmem/ | 包含动态共享内存子系统使用的文件的子目录。9.4 版本以后 |
| logical/ | 包含逻辑解码的状态数据的子目录。9.4 版本以后 |
| pg_multixact/ | 包含多事务状态数据的目录(用于共享行锁) |
| pg_notify/ | 包含 LISTEN/NOTIFY 状态数据的子目录 |
| pg_replslot/ | 包含复制槽数据的子目录(9.4 版本以后) |
| pg_serial/ | 包含已提交的可序列化事务信息(9.1 版本以后)信息的子目录 |
| pg_snapshots/ | 包含导出快照的子目录(9.2 版本以后)。PostgreSQL 的函数 pg_export_snapshot 在此子目录中创建快照信息文件 |
| pg_stat/ | 包含统计子系统永久文件的子目录 |
| pg_stat_tmp/ | 包含统计子系统临时文件的子目录 |
| pg_subtrans/ | 包含子事务状态数据的子目录 |
| pg_tblspc/ | 表空间符号链接目录 |
| pg_twophase/ | 包含 prepare 事务的状态文件 |
| pg_wal/(Version 10 or later) | 包含 WAL(Write Ahead Logging)段文件的子目录。在版本 10 中从 pg_xlog 重命名而来。 |
| pg_xact/(Version 10 or later) | 包含事务提交状态数据的子目录。在版本 10 中从 pg_clog 重命名而来。CLOG 将在 5.4 章节中详解。 |
| pg_xlog/(Version 9.6 or earlier) | 包含 WAL(Write Ahead Logging)段文件的子目录。在版本 10 中重命名为 pg_wal。 |
(3)数据库有两个基础的对象,一个是oid, 一个是表空间
-
OID(Object Identifier):
-
每个数据库对象(如表、索引)分配唯一的 32 位整数标识符。
-
系统表(如
pg_class)记录 OID 与对象名的映射。
-- 查看表的 OID SELECT oid, relname FROM pg_class WHERE relname = 'users'; -
-
表空间(Tablespace):
-
定义数据文件的存储路径,允许将数据分散到不同磁盘。
-
默认表空间:
-
pg_default:存储用户数据(对应base目录)。 -
pg_global:存储集群级系统表(对应global目录)。
-
-
(4)base 的物理布局设计
-
base目录:-
每个数据库在
base下有一个以数据库 OID 命名的子目录。 -
示例:数据库 OID 为
16384→ 目录为base/16384。
-
-
数据文件:
-
每个表或索引对应一个或多个文件(文件名为
relfilenode值)。 -
文件命名规则:
<relfilenode>(如12345)。 -
大表可能被拆分为多个文件(如
12345.1,12345.2)。
-
(5)表空间跟数据库关系
- 在 Oracle 数据库中:一个表空间只属于一个数据库使用,而一个数据库可以拥有多个表空间,属于 “一对多” 的关系。
- 在 PostgreSQL 集群中:一个表空间可以让多个数据库使用,而一个数据库可以使用多个表空间,属于 “多对多” 的关系。
系统自带表空间:
- 表空间 pg_default 是用来存储系统目录对象、用户表、用户表 index、临时表、临时表 index、内部临时表的默认空间,对应存储目录 $PGDATA/base/。
- 表空间 pg_global 用来存放系统字典表,对应存储目录 $PGDATA/global/。