ES(Elasticsearch) 基本概念(一)
Elasticsearch作为当前最流行的开源搜索和分析引擎,广泛应用于日志分析、全文搜索、业务智能等领域。Elasticsearch是一个基于 Apache Lucene 构建的分布式搜索和分析引擎、可扩展数据存储和矢量数据库。它针对生产级工作负载的速度和相关性进行了优化。使用 Elasticsearch 可以近乎实时地搜索、索引、存储和分析各种类型和大小的数据。Kibana是 Elasticsearch 的图形用户界面。它是一款强大的工具,可用于可视化和分析数据,以及管理和监控 Elastic Stack。本文将带你系统学习Elasticsearch的核心概念和基本用法。
一、Elasticsearch基础概念
在开始实际操作前,我们需要了解几个核心概念:
- 文档(Document)
- ES是面向文档的,文档是所有可搜索数据的最小单元
- 文档会被序列化成JSON格式存储
- 每个文档都有唯一ID,可自定义或自动生成
- 支持数组和嵌套结构
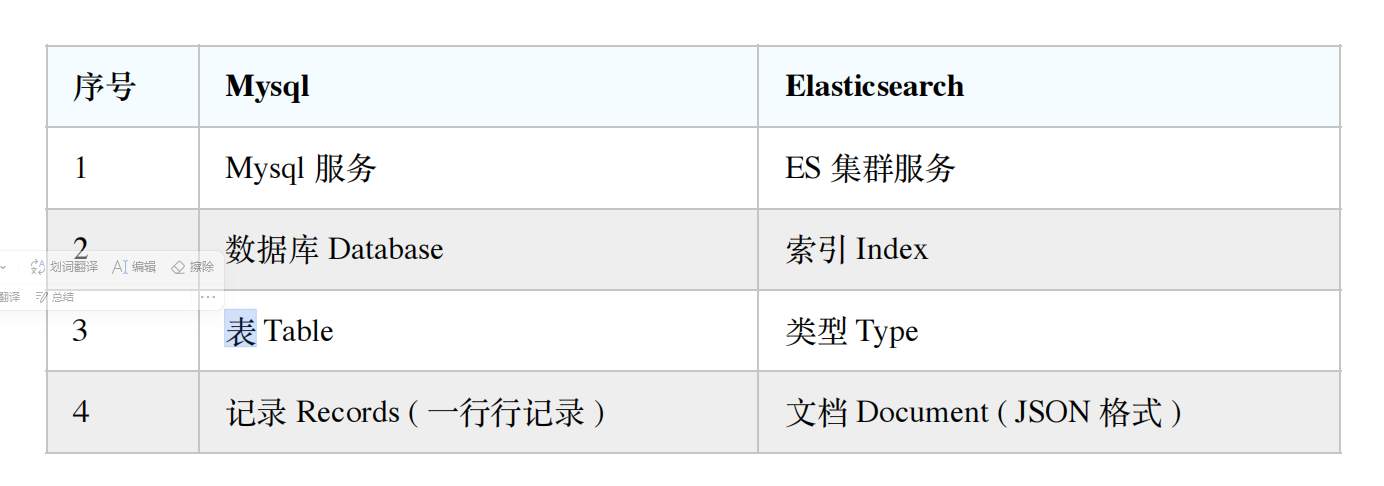
- 索引(Index)
- 相当于MySQL中的数据库
- 名称必须全部小写
- 包含mapping(定义字段类型)和setting(定义数据分布)
- 节点(Node)与分片(Shard)
- 节点:是 一个ES实例,本质是一个Java进程
- Master Eligible节点:参与选主,管理集群状态
- Data节点:存储数据
- Coordinating节点:接收客户端请求
- 节点的名称可以通过配置文件配置,或者在启动的时候使用-E node.name=ropledata指定,默认是随机分配的。建议咱们自己指定,因为节点名称对于管理目的很重要,咱们可以通过节点名称确定网络中的哪些服务器对应于ES集群中的哪些节点;
- 分片:将索引水平拆分为多个部分
- 主分片数在创建索引时指定,后续不能修改
- 副本分片提供高可用性,可动态调整数量
- 节点:是 一个ES实例,本质是一个Java进程
- 类型:就相当于MySql里的表,我们知道MySql里一个库下可以有很多表,最原始的时候ES也是这样,一个索引下可以有很多类型,但是从6.0版本开始,type已经被逐渐废弃,但是这时候一个索引仍然可以设置多个类型,一直到7.0版本开始,一个索引就只能创建一个类型了(_doc)。 Elasticsearch7 去掉 tpye 概念ES7.x 版本:URL 中的 type 参数为可选。 ES8.x 版本:不⽀持 URL 中的 type 参数
注意:虽然在实际存储上,文档存在于某个索引里,但是文档必须被赋予一个索引下的
二、什么是倒排索引?
倒排索引(Inverted Index)是搜索引擎最核心的数据结构,也是Elasticsearch实现高效全文搜索的基础。它与我们熟悉的传统"正排索引"形成鲜明对比:
- 正排索引(正向索引):文档文档(Document)
- ES是面向文档的,文档是所有可搜索数据的最小单元
- 文档会被序列化成JSON格式存储
- 每个文档都有唯一ID,可自定义或自动生成
- 支持数组和嵌套结构
- 索引(Index)
- 相当于MySQL中的数据库
- 名称必须全部小写
- 包含mapping(定义字段类型)和setting(定义数据分布)
- 节点(Node)与分片(Shard)
- 节点:一个ES实例,本质是一个Java进程
- Master Eligible节点:参与选主,管理集群状态
- Data节点:存储数据
- Coordinating节点:接收客户端请求
- 分片:将索引水平拆分为多个部分
- 主分片数在创建索引时指定,后续不能修改
- 副本分片提供高可用性,可动态调整数量
- 节点:一个ES实例,本质是一个Java进程
- → 包含的词
- 类似书籍的目录,通过章节找内容
- 如:文档1包含"大话"、"西游"
- 倒排索引(反向索引):词 → 出现的文档
- 类似书籍的索引页,通过关键词找章节
- 如:"西游" → 文档1、文档2、文档3...
三、倒排索引的构建过程
3.1 原始数据示例
以电影片名为例:
| 文档ID | 电影名称 |
| 1 | 大话西游 |
| 2 | 大话西游外传 |
| 3 | 解析大话西游 |
| 4 | 西游降魔外传 |
| 5 | 梦幻西游独家解析 |
3.2 分词处理
中文需要先进行分词(使用分词器将句子拆分为词语):
- "大话西游" → ["大话", "西游"]
- "大话西游外传" → ["大话", "西游", "外传"]
- "解析大话西游" → ["解析", "大话", "西游"]
- "西游降魔外传" → ["西游", "降魔", "外传"]
- "梦幻西游独家解析" → ["梦幻", "西游", "独家", "解析"]
3.3 构建倒排列表
对分词结果进行反向记录:
| 词项 | 文档ID列表(Posting List) | 其他信息(如词频、位置等) |
| 西游 | 1,2,3,4,5 | 在1中出现1次,在2中出现1次... |
| 大话 | 1,2,3 | 在1中出现1次,在2中出现1次... |
| 外传 | 2,4 | 在2中出现1次,在4中出现1次... |
| 解析 | 3,5 | 在3中出现1次,在5中出现1次... |
| 降魔 | 4 | 在4中出现1次 |
| 梦幻 | 5 | 在5中出现1次 |
| 独家 | 5 | 在5中出现1次 |
三、倒排索引的搜索过程
3.1 搜索示例:查询"独家大话西游"
- 查询分词:
- "独家大话西游" → ["独家", "大话", "西游"]
- 查找倒排列表:
- "独家" → 文档5
- "大话" → 文档1,2,3
- "西游" → 文档1,2,3,4,5
- 合并结果:
- 文档1:包含"大话"、"西游"
- 文档2:包含"大话"、"西游"
- 文档3:包含"大话"、"西游"
- 文档5:包含"独家"、"西游"
- 文档4:只包含"西游"
相关性评分(简化版):
评分公式:
得分 = 命中词数 / 文档总词数
-
-
文档1:命中2词("大话"、"西游"),总词数2 → 2/2=1.0
-
文档2:命中2词,总词数3 → 2/3≈0.67
-
文档3:命中2词,总词数3 → 2/3≈0.67
-
文档5:命中2词("独家"、"西游"),总词数4 → 2/4=0.5
-
文档4:命中1词("西游"),总词数3 → 1/3≈0.33
-
结果排序:
1. 大话西游 (1.0)
2. 大话西游外传 (0.67)
3. 解析大话西游 (0.67)
4. 梦幻西游独家解析 (0.5)
5. 西游降魔外传 (0.33)
基础操作
索引管理
// 创建索引
PUT /ropledata
{"settings": {"number_of_shards": "2","number_of_replicas": "3"}
}// 删除索引
DELETE /ropledata// 修改副本数
PUT ropledata/_settings
{"number_of_replicas": "2"
}什么是映射?
映射(Mapping)是ElasticSearch中用于定义文档及其包含字段如何存储和索引的机制。它相当于关系型数据库中的表结构定义,决定了:
- 哪些字段应该被当作全文检索字段
- 哪些字段包含数字、日期或地理位置信息
- 日期值的格式
- 自定义规则来控制动态添加字段的映射
映射的核心作用
- 字段类型定义:指定每个字段的数据类型(如text、keyword、integer等)
- 索引控制:决定字段是否被索引(可搜索)
- 分析器配置:指定文本字段使用的分词器
- 格式设置:如日期字段的格式
- 多字段支持:一个字段可以有不同的索引方式
映射类型
1. 显式映射
单级属性映射
用户明确定义字段的映射规则:

PUT /my-index
{"mappings": {"properties": {"age": { "type": "integer" }, "email": { "type": "keyword" },"name": { "type": "text" }}}
}多级属性映射
PUT /my-index
{"mappings": {"properties": {"age": { "type": "integer" },"email": { "type": "keyword" },"name": { "type": "text" },"address": {"type": "nested","properties": {"street": { "type": "text" },"city": { "type": "keyword" },"zipcode": { "type": "keyword" },"coordinates": {"type": "object","properties": {"lat": { "type": "float" },"lon": { "type": "float" }}}}},"skills": {"type": "nested","properties": {"name": { "type": "keyword" },"level": { "type": "integer" },"certifications": {"type": "nested","properties": {"name": { "type": "text" },"year": { "type": "short" }}}}},"employment_history": {"type": "nested","properties": {"company": { "type": "keyword" },"position": { "type": "text" },"duration_months": { "type": "integer" }}}}}
}这个映射定义包含:
- 基本字段:age(integer), email(keyword), name(text)
- 嵌套地址对象:包含街道(text)、城市(keyword)、邮编(keyword)和坐标对象
- 嵌套技能数组:包含技能名(keyword)、等级(integer)和嵌套的认证数组
- 嵌套工作经历数组:包含公司(keyword)、职位(text)和持续时间(integer)
所有嵌套关系都使用 "type": "nested" 来确保数组中的对象被独立索引和查询。
2. 动态映射
当索引新文档时,ES会自动检测并添加新字段:
PUT /my-index/_doc/1
{"age": 25,"email": "user@example.com","name": "John Doe"
}ES会自动推断:
age → long
email → keyword
name → text
常用字段类型
| 类型 | 说明 |
| text | 全文检索字段,会被分词 |
| keyword | 精确值字段,不分析,用于过滤、排序和聚合 |
| long/integer | 长整型/整型数值 |
| double/float | 双精度/单精度浮点数 |
| date | 日期类型,可指定格式 |
| boolean | 布尔值 |
| object | JSON对象 |
| nested | 嵌套对象,保持数组中对象的独立性 |
| geo_point | 经纬度坐标 |
映射操作示例
查看映射
GET /my-index/_mapping添加新字段映射
PUT /my-index/_mapping
{"properties": {"employee-id": {"type": "keyword","index": false}}
}更新映射注意事项
重要:已存在字段的映射类型不能直接修改,必须:
- 创建新索引并定义新映射
- 使用_reindex API迁移数据
POST _reindex
{"source": { "index": "old-index" },"dest": { "index": "new-index" }
}映射参数详解
常用参数
- index:是否索引该字段(true/false)
- analyzer:指定文本分析器
- search_analyzer:指定搜索时分析器
- format:日期格式(如"yyyy-MM-dd")
- copy_to:将字段值复制到目标字段
- fields:多字段特性,允许一个字段有多种索引方式
多字段示例
{"mappings": {"properties": {"city": {"type": "text","fields": {"raw": { "type": "keyword"}}}}}
}这样city可以用于全文搜索,city.raw可用于精确匹配和聚合。
索引数据
- 预先定义映射:生产环境建议预先定义映射,避免动态映射的不确定性
- 合理使用keyword:不需要分词的字段应设为keyword类型
- 控制动态映射:可通过
dynamic参数控制(true/false/strict) - 避免频繁修改:映射特别是字段类型不宜频繁变更
- 使用别名:便于重建索引时无缝切换映射是ElasticSearch高效工作的基础,合理的映射设计能显著提升搜索性能和结果的准确性。
一、数据插入操作
1. 不指定文档ID插入
Elasticsearch 会自动生成唯一ID
POST /ropledata/_doc/
{"id":1,"name":"且听_风吟","page":"https://ropledata.blog.csdn.net","say":"欢迎点赞,收藏,关注,一起学习"
}2. 指定文档ID插入
适用于需要自定义ID的场景
POST /ropledata/_doc/101
{"id":1,"name":"且听_风吟","page":"https://ropledata.blog.csdn.net","say":"欢迎点赞,收藏,关注,一起学习"
}二、数据删除操作
删除指定ID的文档:
DELETE /ropledata/_doc/101三、数据更新操作
1. 全局更新(覆盖更新)
会完全替换原有文档内容
PUT /ropledata/_doc/101
{"id":1,"name":"且听_风吟","page":"https://ropledata.blog.csdn.net","say":"再次欢迎点赞,收藏,关注,一起学习"
}2. 局部更新
只更新指定字段,性能优于全局更新
POST /ropledata/_update/101
{"doc": {"say":"奥力给"}
}四、数据查询操作
1. 基础查询(默认返回10条)
GET /ropledata/_search2. 带条件的全局查询
POST /ropledata/_search
{"query": {"match_all": {}},"sort": [{"id": {"order": "asc"}}]
}五、索引重建操作
POST _reindex
{"source": { "index": "twitter" },"dest": { "index": "new_twitter" }
}关键知识点总结
- 插入数据:
- 不指定ID时ES自动生成
- 指定ID适用于业务关联场景
- 更新机制:
- ES文档不可变,更新实质是新版本覆盖旧版本
- 局部更新(
_update)比全局更新(PUT)性能更好
- 查询特点:
- 默认返回10条结果
- 可通过
sort参数控制排序 match_all查询全部文档
- 版本兼容性:
- 本文示例适用于Elasticsearch 7.x版本
- 6.x及以下版本语法可能有差异
- 性能建议:
- 频繁更新的字段考虑单独索引
- 大文档更新优先使用局部更新
提示:在实际开发中,建议结合业务场景选择合适的操作方式,批量操作(Bulk API)能显著提高大批量数据处理的效率。