LLM: 多模态LLM动态分辨率
文章目录
- 前言
- 一、Qwen VL 动态分辨率逻辑
- 1. Resize
- 2. Rescale
- 3. normalize and patch
- 二、internvl VL 动态分辨率逻辑
- 三、Deepseek VL2动态分辨率
- 总结
前言
动态分辨率目前在VLLM中已经普及开来,最早的VLLM模型通常是通过将图像resize 到固定尺寸后送入,这种做法虽然简单,但是对于分辨率多样的图片很容易导致失真导致图像信息丢失。本文主要针对目前几个常用的VLLM的动态分辨率进行分析。
一、Qwen VL 动态分辨率逻辑
首先以qwen2vl(vision backbone 下采样 28 倍)为例, 动态分辨率核心要考虑三个点
图像在resize的时候,既需要考虑图像尺寸是 28 的整数倍,也需要考虑尽可能的保证图像resize不失真,也就是保持宽高比。比如512x512的图像,如果resize 到了128x2048,那么图像就会严重失真。
其次就是训练的泛化性,推理的时候输入更小/大的图像(尤其视频帧),模型能不能外推。
基本步骤如下:
1. Resize
# 第一步 resize
if do_resize:resized_height, resized_width = smart_resize(height,width,factor=self.patch_size * self.merge_size,min_pixels=self.min_pixels,max_pixels=self.max_pixels,)image = resize(image, size=(resized_height, resized_width), resample=resample, input_data_format=input_data_format)其中smart_resize函数主要确定最终图像尺寸,尺寸为28倍数的同时尽量避免图像失真,操作如下:
h_bar = round(height / factor) * factor
w_bar = round(width / factor) * factor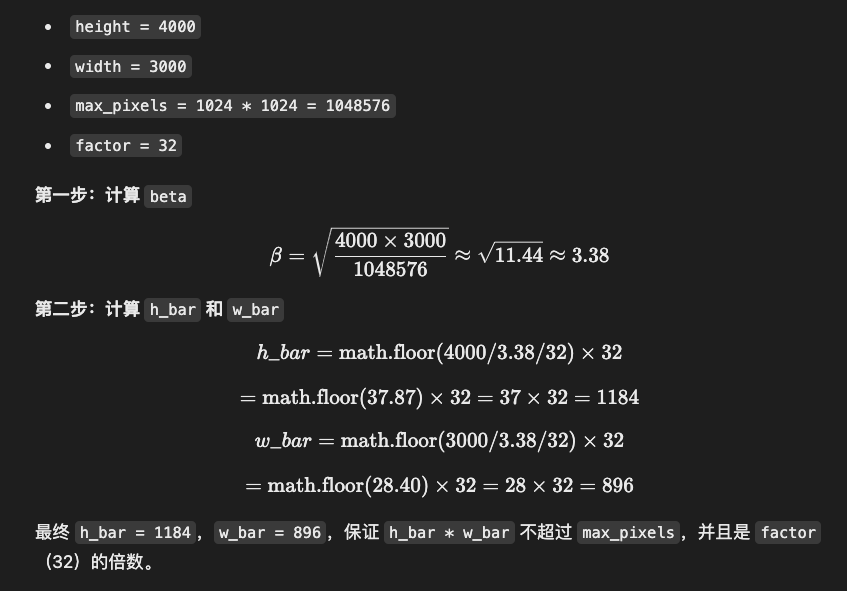
关于最大像素和最小像素:
qwen2vl 系列模型的min_pixel是3136,max_pixel是12845056,等同于从 56 56 到 3584x3584的图像输入*。对于video的每帧,考虑到多帧情况,最大是16384。并且由于scale到了min_pixels 和 max_pixels之间。实际训练中也发现了,调整小max_pixel,对性能影响不大,因此对于显存不够的情况,可以适当调小max_pixel ,能够有效节省显存。
2. Rescale
这一步有一个关键的参数,rescale_factor。qwen2vl 默认取 0.00392156862745098(其实就是1/255),得到的结果就是 rescale_factor 逐元素相乘 image。
image = self.rescale(image, scale=rescale_factor, input_data_format=input_data_format)
3. normalize and patch
按照mean,std归一化
qwen的vit最开始的embed方式是一个2x3x3的conv,所以需要把单图copy成2份,比如对于(1, 3, 924, 1232) 的图像就变成了(2, 3, 924, 1232)。
patches = np.tile(patches, (self.temporal_patch_size, 1, 1, 1))
二、internvl VL 动态分辨率逻辑
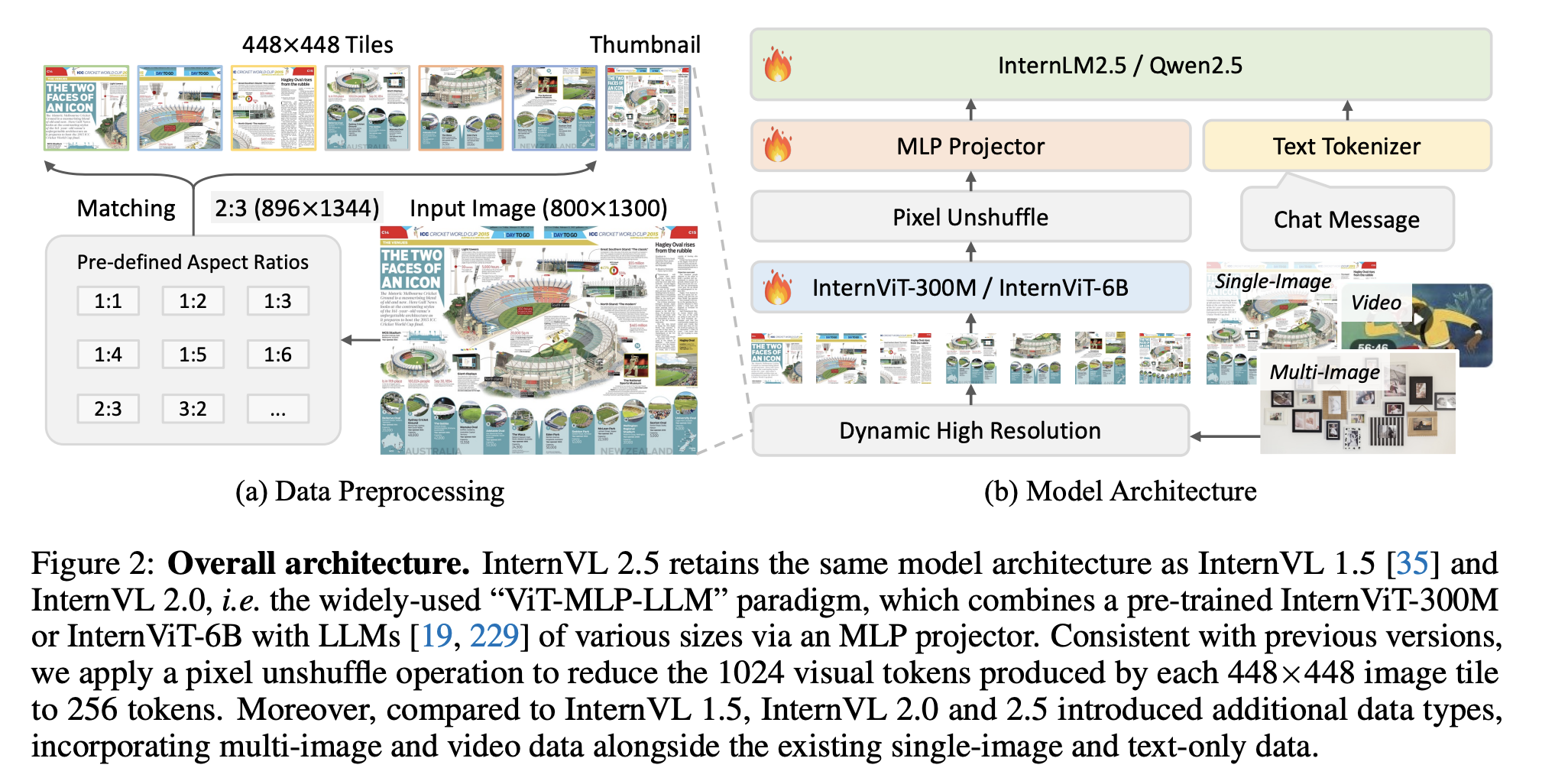
intervl的动态分辨率处理逻辑相比qwen vl更复杂一些,它的基本逻辑如下:
intervl会预设一些图像比例,对于一张image,首先找到最接近图像尺寸的比例,然后进行resize。且resize后的图像尺寸应为448的倍数,随后按照448的尺寸进行patch切分,同时如果patch数量大于1,则按照448尺寸对原图生成一张缩略图。
def load_image(image_file, input_size=448, max_num=12):image = Image.open(image_file).convert('RGB')# 第一步 transformtransform = build_transform(input_size=input_size)# 第二步 动态分辨率images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)pixel_values = [transform(image) for image in images]# 第三步 堆叠pixel_values = torch.stack(pixel_values)return pixel_values核心函数在于dynamic_preprocess
首先找到合适的宽高比
target_ratios = [(1, 1), (1, 2), (2, 1), (3, 1), (1, 3), (2, 2), (4, 1), (1, 4), (5, 1), (1, 5), (1, 6), (6, 1), (3, 2), (2, 3), (7, 1), (1, 7), (4, 2), (2, 4), (1, 8), (8, 1), (1, 9), (3, 3), (9, 1), (2, 5), (5, 2), (10, 1), (1, 10), (11, 1), (1, 11), (12, 1), (3, 4), (4, 3), (1, 12), (6, 2), (2, 6)]aspect_ratio = orig_width / orig_heighttarget_aspect_ratio = find_closest_aspect_ratio(aspect_ratio, target_ratios, orig_width, orig_height, image_size)target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
确定新图的尺寸后,进行resize,然后按照patch进行切分。最后将这些patch和缩略图stack即可。
三、Deepseek VL2动态分辨率
Deepseek VL2的动态分辨率和inter vl的核心思想基本一致,都是通过缩略图+patch方式作为输入。
先看看原文的说法
对于视觉组件,引入了一种动态平铺视觉编码策略,有效地处理不同长宽比的高分辨率图像。这种方法改进了。DeepSeek-VL的混合视觉编码器,它从两个固定的图像中提取特征分辨率(384 × 384和1024 × 1024)。
从已建立的inter vl中获得灵感,我们的系统动态地将高分辨率输入分割为局部块,通过共享视觉转换器处理每个块,并将提取的特征无缝集成到语言模型中。本设计保留了视觉变换具有局部关注的优点,无需局部关注即可实现丰富的特征提取。
原始的DeepSeek-VL采用混合视觉编码器,结合SigLIP进行384 × 384分辨率的粗粒度特征提取,SAM-B进行1024 × 1024分辨率的细粒度特征提取,而这种融合方法 生成适合于各种视觉语言任务的丰富的视觉表示,它是有限的受固定1024 × 1024分辨率约束。这种限制对于
处理具有较大分辨率和极端宽高比的图像,例如在 信息图vqa,密集OCR和详细的视觉接地任务。
Deepseek VL2 预训练的SigLIP以384 × 384的基本分辨率运行。来为了适应不同的纵横比,我们定义了一组候选分辨率:𝑅={(𝑚·384,𝑛·384) |𝑚∈N,𝑛∈N, 1≤𝑚,𝑛,𝑚𝑛≤9},𝑚:𝑛代表了长宽比。流程如下:

通过该策略将产生 (1+mn) 个384384的patch,每个patch产生27*27个视觉编码。当处理多个图像时,策略将关闭。
(视觉编码还会经过Vision-Language Adaptor 对视觉编码进行进一步压缩和处理,详情可以参考论文)
总结
其实目前的动态分辨率主要思想都是将图像按照预设比例resize后进行patch切分。其实在操作上都大差不差,不过对于我来说更喜欢qwen2vl的动态分辨率策略,因为qwen2vl 的 max_pixel 可以设置的小一些,个人测试没什么太大影响,训练性能提升还是很大的。