Python 训练营打卡 Day 20-奇异值SVD分解
一.奇异值分解(SVD)的输入和输出
输入:一个任意的矩阵 A,尺寸为 m × n(其中 m是行数,n 是列数,可以是矩形矩阵,不必是方阵)
奇异值分解(SVD)得到的三个矩阵 U、Σ 和 V^T各有其特定的意义和用途,下面我简要说明它们的作用:
U(奇异值向量矩阵):
是一个m×m的正交矩阵,列向量是矩阵AA^T的特征向量
作用:表示原始矩阵 A 在行空间(样本空间)中的主方向或基向量。简单来说,U$的列向量描述了数据在行维度上的“模式”或“结构”。
应用:在降维中,U 的前几列可以用来投影数据到低维空间,保留主要信息(如在图像处理中提取主要特征)
Σ (奇异值矩阵):
是一个m×n的对角矩阵,对角线上的奇异值,按降序排列,非负
作用:奇异值表示原始矩阵 A在每个主方向上的“重要性”或“能量”。较大的奇异值对应更重要的特征,较小的奇异值对应噪声或次要信息
应用:通过选择前 k个较大的奇异值,可以实现降维,丢弃不重要的信息(如数据压缩、去噪)
V^T(右奇异向量矩阵的转置):
是V的转置,V是一个n×n的正交矩阵,列向量是矩阵A^TA的特征向量
作用:表示原始矩阵 A在列空间(特征空间)中的主方向或基向量。简单来说,V的列向量描述了数据在列维度上的“模式”或“结构”
应用:类似U,V的前几列可以用来投影数据到低维空间,提取主要特征
整体作用:
结合起来,A = UΣV^T意味着原始矩阵A可以被分解为一系列主方向(U和V)和对应的权重(Σ )的组合。这种分解揭示了数据的内在结构。
U、Σ和 V^T提供了数据的核心结构信息,帮助我们在保留主要信息的同时简化数据处理
二.奇异值的应用
奇异值分解(SVD)后,原始矩阵 A被分解为 A = UΣV^T,这种分解是等价的,意味着通过 U、Σ和 V^T的乘积可以完全重构原始矩阵 A,没有任何信息损失
但在实际应用中,我们通常不需要保留所有的奇异值和对应的向量,而是可以通过筛选规则选择排序靠前的奇异值及其对应的向量来实现降维或数据压缩。以下是这个过程的核心思想:
1.奇异值的排序:
在Σ矩阵中,奇异值(对角线上的值)是按降序排列的。靠前的奇异值通常较大,代表了数据中最重要的信息或主要变化方向;靠后的奇异值较小,代表次要信息或噪声
奇异值的大小反映了对应向量对原始矩阵A的贡献程度
2.筛选规则:
我们可以根据需求选择保留前k个奇异值(k是一个小于原始矩阵秩的数),并丢弃剩余的较小奇异值
常见的筛选规则:
固定数量:直接选择前 k个奇异值(例如,前 10 个)
累计方差贡献率:计算奇异值的平方(代表方差),选择累计方差贡献率达到某个阈值(如 95%)的前 k个奇异值
奇异值下降幅度:观察奇异值下降的“拐点”,在下降明显变缓的地方截断
3.降维与近似
保留前k个奇异值后,我们只取U矩阵的前k列(记为U_k,尺寸为 m×k)、 Σ矩阵的前 k个奇异值(记为 Σ_k,尺寸为 k×k)、以及 V^T矩阵的前k行(记为 V_k^T,尺寸为 k ×n)
近似矩阵为 A_k = U_kΣ_k V_k^T,这个矩阵是原始矩阵A的低秩近似,保留了主要信息,丢弃了次要信息或噪声
这种方法在降维(如主成分分析 PCA)、图像压缩、推荐系统等领域非常常用。
4.对应的向量
U的列向量和V的列向量分别对应左右奇异向量。保留前 k个奇异值时,U_k的列向量代表数据在行空间中的主要方向,V_k的列向量代表数据在列空间中的主要方向
这些向量与奇异值一起,构成了数据的主要“模式”或“结构”
总结:
SVD 分解后原始矩阵是等价的,但通过筛选排序靠前的奇异值和对应的向量,我们可以实现降维,保留数据的主要信息,同时减少计算量和噪声影响。这种方法是许多降维算法(如 PCA)和数据处理技术的基础
三.矩阵降维案例
import numpy as np# 创建一个矩阵 A (5x3)
A = np.array([[1, 2, 3],[4, 5, 6],[7, 8, 9],[10, 11, 12],[13, 14, 15]])
print("原始矩阵 A:")
print(A)# 进行 SVD 分解
U, sigma, Vt = np.linalg.svd(A, full_matrices=False)
print("\n奇异值 sigma:")
print(sigma)# 保留前 k=1 个奇异值进行降维
k = 1
U_k = U[:, :k] # 取 U 的前 k 列,因为要保持行数不变
sigma_k = sigma[:k] # 取前 k 个奇异值
Vt_k = Vt[:k, :] # 取 Vt 的前 k 行,因为要保持列数不变# 近似重构矩阵 A,常用于信号or图像筛除噪声
A_approx = U_k @ np.diag(sigma_k) @ Vt_k
print("\n保留前", k, "个奇异值后的近似矩阵 A_approx:")
print(A_approx)# 计算近似误差
error = np.linalg.norm(A - A_approx, 'fro') / np.linalg.norm(A, 'fro')
print("\n近似误差 (Frobenius 范数相对误差):", error)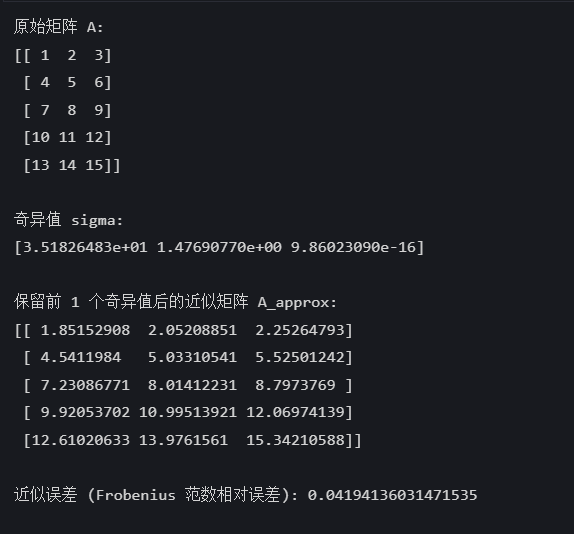
四.以心脏病数据为例进行操作
1.数据预处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sans
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 导入心脏病项目的数据
data = pd.read_csv(r'C:\Users\ggggg\Desktop\python60-days-challenge-master (1)\python60-days-challenge-master\heart.csv')
# 查看数据
data.info()
data.head()
data.isnull().sum()
continuous_features = [col for col in data.columnsif data[col].dtype in ['float64', 'int64']and data[col].nunique()/len(data) > 0.1] # 唯一值超过10%
# 离散特征:非数值型或低基数数值
# 原代码中 continuous_feature 变量名拼写错误,此处修正为正确的变量名
discrete_features = [col for col in data.columnsif col not in continuous_features]
print(discrete_features)
print(continuous_features)
for feature in discrete_features:print(f"\n{feature}的唯一值:")print(data[feature].value_counts())nominal_features = ['sex','fbs', 'target'] # 不存在顺序关系的特征
# 独热编码
data = pd.get_dummies(data, columns=nominal_features, drop_first=True)
data2 = pd.read_csv("data.csv") # 重新读取数据,用来做列名对比
list_final = [] # 新建一个空列表,用于存放独热编码后新增的特征名
for i in data.columns:if i not in data2.columns:list_final.append(i) # 这里打印出来的就是独热编码后的特征名
for i in list_final:data[i] = data[i].astype(int)cp_mapping = {0: 0, 1: 1, 2: 2, 3: 3}
if 'cp' in data.columns:data['cp'] = data['cp'].map(cp_mapping)continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist() for feature in continuous_features:mode_value = data[feature].mode()[0]data.loc[:, feature] = data[feature].fillna(mode_value)from sklearn.model_selection import train_test_split
X = data.drop(['target_1'], axis=1) # 特征,axis=1表示按列删除
y = data['target_1']
# 划分数据集,20%作为测试集,随机种子为42
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练集和测试集的形状
print(f"训练集形状:{X_train.shape}, 测试集形状:{X_test.shape}")2.标准化数据
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import seaborn as sns# 标准化数据(聚类前通常需要标准化)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# X_scaled3.对训练集进行SVD降维
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score# 设置随机种子以便结果可重复
np.random.seed(42)# 模拟数据:1000 个样本,50 个特征
n_samples = 1000
n_features = 50
X = np.random.randn(n_samples, n_features) * 10 # 随机生成特征数据
y = (X[:, 0] + X[:, 1] > 0).astype(int) # 模拟二分类标签# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(f"训练集形状: {X_train.shape}")
print(f"测试集形状: {X_test.shape}")# 对训练集进行 SVD 分解
U_train, sigma_train, Vt_train = np.linalg.svd(X_train, full_matrices=False)
print(f"Vt_train 矩阵形状: {Vt_train.shape}")# 选择保留的奇异值数量 k
k = 10
Vt_k = Vt_train[:k, :] # 保留前 k 行,形状为 (k, 50)
print(f"保留 k={k} 后的 Vt_k 矩阵形状: {Vt_k.shape}")# 降维训练集:X_train_reduced = X_train @ Vt_k.T
X_train_reduced = X_train @ Vt_k.T
print(f"降维后训练集形状: {X_train_reduced.shape}")# 使用相同的 Vt_k 对测试集进行降维:X_test_reduced = X_test @ Vt_k.T
X_test_reduced = X_test @ Vt_k.T
print(f"降维后测试集形状: {X_test_reduced.shape}")# 训练模型(以逻辑回归为例)
model = LogisticRegression(random_state=42)
model.fit(X_train_reduced, y_train)# 预测并评估
y_pred = model.predict(X_test_reduced)
accuracy = accuracy_score(y_test, y_pred)
print(f"测试集准确率: {accuracy}")# 计算训练集的近似误差(可选,仅用于评估降维效果)
X_train_approx = U_train[:, :k] @ np.diag(sigma_train[:k]) @ Vt_k
error = np.linalg.norm(X_train - X_train_approx, 'fro') / np.linalg.norm(X_train, 'fro')
print(f"训练集近似误差 (Frobenius 范数相对误差): {error}")
@浙大疏锦行