II-Medical-8B论文速读:课程SFT,DPO和RL 为长思维链推理从无到有
Light-R1: Curriculum SFT, DPO and RL for Long COT from Scratch and Beyond
一、引言
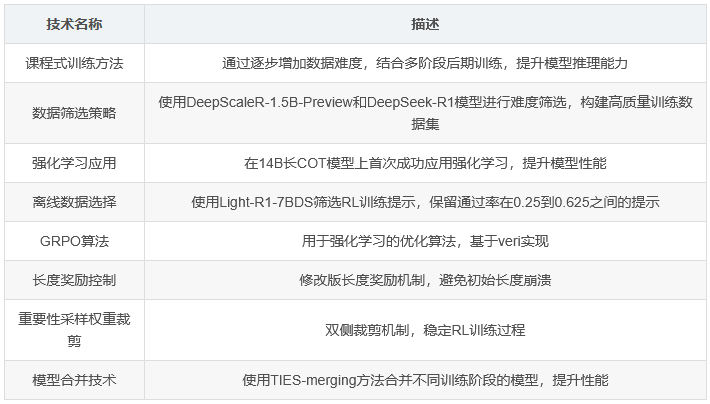
Light-R1论文介绍了一个开源套件,用于使用可重现且成本效益高的方法训练长推理模型。该研究旨在解决大型推理模型(如DeepSeek-R1)在部署时面临的计算成本高昂问题,提出了利用公共数据和模型的替代方法。研究团队通过课程训练逐步增加数据难度,并结合多阶段后期训练,成功开发出LightR1-32B模型,该模型在数学推理方面优于DeepSeek-R1-DistillQwen-32B。
研究背景表明,自DeepSeek-R1发布以来,长推理链(Chain-of-Thought, COT)在基础AI模型和各种工业AI应用中广受欢迎。然而,部署完整的R1级模型(通常具有70B+参数)需要 prohibitive computational costs。因此,研究团队致力于开发在几十亿参数内即可执行长COT的紧凑型模型,这对于数学问题解决、算法规划和科学分析至关重要。
Light-R1系列模型的开发包括三个主要挑战:
-
编制高效的后期训练数据集
-
优化数据集的使用
-
实施强化学习以进一步提升模型性能
研究团队通过创新的算法和工程进步,系统地解决了这些挑战,并开源了模型、训练数据和代码,以促进复杂推理模型在实际应用中的可访问性和可实现性。
二、方法
数据准备
研究团队收集了约1000k道带有正确答案的数学问题作为种子集,并进行了数据去重和多样化处理。通过内部标签系统对问题进行分类,并对数据量过多的类别进行下采样。在数据去重方面,团队发现MATH500数据集存在大量被破坏的问题,而AIME24和25数据集保持未受污染。Light-R1采用了全面的去重方法,包括精确匹配和N-gram(N=32)匹配,以确保数据集的纯净性。
在数据生成方面,团队为监督微调(SFT)生成了全面的COT响应。通过使用DeepScaleR-1.5B-Preview模型对每个问题生成响应,并选择通过率低于α的问题进行DeepSeek-R1查询,最终构建了一个包含70k+示例的SFT数据集。然而,直接在此数据集上训练并未取得满意结果,因此团队实施了第二阶段的难度筛选,使用完整的DeepSeekR1模型保留通过率低于α的问题,形成了包含约3k示例的第二阶段SFT数据集。
课程式后期训练
Light-R1的课程式后期训练包括三个阶段:
-
SFT阶段1:在76k筛选后的数学问题上训练
-
SFT阶段2:在3k最具挑战性的问题上微调
-
DPO优化:使用验证的响应对进行基于偏好的优化
SFT阶段采用课程数据策略,DPO阶段则使用半策略内方法和NCA损失函数。对于被拒绝的响应,团队从SFT阶段2模型中采样并验证其不正确的答案。由于一些被拒绝的响应长度达到32k tokens或更多,团队采用了具有序列并行性的DPO实现。
强化学习
研究团队在DeepSeek-R1-Distill-Qwen-14B模型上进行了强化学习实验。这是首次公开记录在已经长COT的14B模型上通过强化学习显著提升性能的工作。团队采用了两阶段过程:
-
离线数据选择:使用Light-R1-7BDS对RL训练提示进行采样,保留通过率在0.25到0.625之间的提示
-
在线强化学习:在筛选后的数据集上应用GRPO算法
团队还采用了两种技术来稳定RL训练过程:修改版的长度奖励和重要性采样权重裁剪。长度奖励方面,当答案正确时限制缩短奖励,以防止初始长度崩溃。重要性采样权重裁剪方面,实施了更广泛的双侧裁剪机制,以限制极端值的影响并稳定训练过程。
三、实验
Light-R1-32B的训练结果
实验结果显示,Light-R1-32B模型在课程SFT和DPO后期训练阶段均表现出一致的改进。在DPO之后,使用TIES-merging方法合并来自SFT阶段2、DPO和另一个DPO变体的模型,合并后的模型展现出额外的性能提升。尽管数学专注训练导致一些未训练的GPQA科学问题上的泛化能力有所下降,但Light-R1-32B仍显示出强大的泛化能力。
具体性能提升如下:
-
SFT阶段1后,AIME24和AIME25的分数分别为69.0和57.4
-
SFT阶段2后,分数提升至73.0和64.3
-
DPO优化后,分数进一步提升至75.8和63.4
-
模型合并后,最终分数达到76.6和64.6
Light-R1-14B-DS的强化学习结果
强化学习训练表现出预期行为:响应长度和奖励分数同时增加。RL训练曲线显示,第一和第二轮似乎没有带来太多改进,但健康的训练曲线为继续训练提供了信心。最终,Light-R1-14B-DS在第三轮RL训练后,AIME24和AIME25的分数分别达到74.0和60.2。
四、结论
Light-R1系列模型成功解决了在资源限制下训练长推理模型的挑战。通过课程训练策略,研究团队从头开始训练了一个长COT模型。精心策划的3K数据集在各种模型尺寸上展现出显著的迁移能力,显著提升了DeepSeek-R1-Distill模型,并为7B、14B和32B参数的模型设立了新的性能基准。此外,团队还研究了在多阶段微调的强基模型上应用强化学习的有效性,在保持稳定响应长度增长的同时实现了卓越性能。
研究团队开源了模型、数据集和代码,旨在加速开发紧凑但强大的推理系统,特别是针对资源受限的应用。未来的工作将探索增强长推理模型的泛化能力,并进一步优化强化学习训练效率。
核心技术汇总