基于Transformers与深度学习的微博评论情感分析及AI自动回复系统
前言
这个项目存在cookie没有自动更新问题,后续可能会发出来解决教程,还有微博网页版的话最多看到300条评论,而且回复别人信息的话最多回复15条就要休息5分钟左右才能评论
1. 项目概述
本项目实现了一个微博评论自动化处理系统,主要功能包括:
-
微博评论区数据爬取
-
文本内容清洗过滤
-
使用预训练模型进行情感分析
-
违法内容检测与AI法律条文回复
-
数据存储(MySQL+Excel)
-
异常情况短信提醒
技术栈:
-
Python
-
Transformers(情感分析模型)
-
DeepSeek API(智能回复生成)
-
MySQL(数据存储)
-
Requests(微博接口请求)
2. 核心功能模块
2.1 数据爬取模块
class WeiboSpider:def get_id(self, theme): ... # 获取微博IDdef get_comments(self, com_id): ... # 分页爬取评论def filter_text(self, text): ... # 正则过滤非法字符特点:
-
模拟浏览器请求头
-
自动处理分页逻辑
-
支持多种括号内容过滤
2.2 情感分析模块
def ana_com(self, sample_comments):sentiment_pipeline = pipeline("sentiment-analysis", model=self.model_name)# 使用uer/roberta-base-finetuned-jd模型模型选择:
-
使用在中文电商评论上微调的RoBERTa模型
-
支持二分类(positive/negative)
2.3 AI智能回复模块
def ai_com(self, sample_comment):client = OpenAI(api_key="your_key",base_url="https://api.deepseek.com")# 调用DeepSeek法律专家模型2.4 数据存储模块
class MySQLStorage:def insert_comment(...): # MySQL存储
def store_to_excel(...): # Excel备份3. 关键代码解析
3.1 评论过滤逻辑
def filter_text(text):# 删除多种括号内容text = re.sub(r'<[^>]*>|\{[^}]*\}|\[...]', '', text)# 保留中文、英文、数字及常用标点pattern = re.compile(r'[^\u4e00-\u9fa5a-zA-Z0-9,。!?...]+')return re.sub(pattern, '', text)3.2 违法内容检测
def zhengzhi_com(self, text):inputs = self.tokenizer(text, return_tensors="pt",truncation=True)outputs = self.model(**inputs)return torch.argmax(probs).item() # 1表示违法内容3.3 自动回复流程
if self.zhengzhi_com(comment) == 1:content = self.ai_com(comment)self.replay_comments(weibo_id, cid, content)if 负面评论超过阈值:self.send_mess() # 触发短信报警4. 环境配置指南
4.1 依赖安装
pip install transformers requests pandas openai mysql-connector-python5. 效果展示
5.1 运行示例
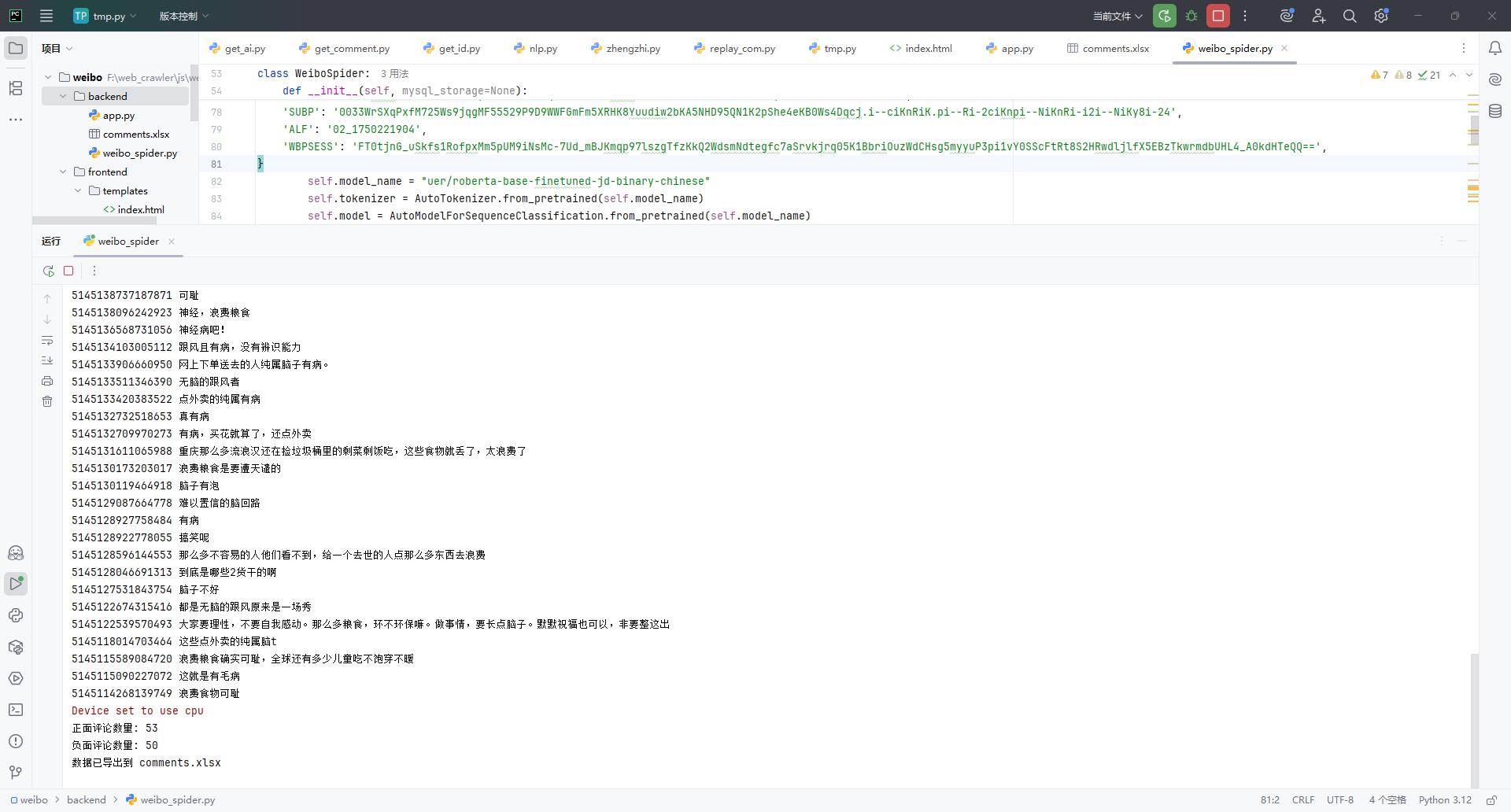
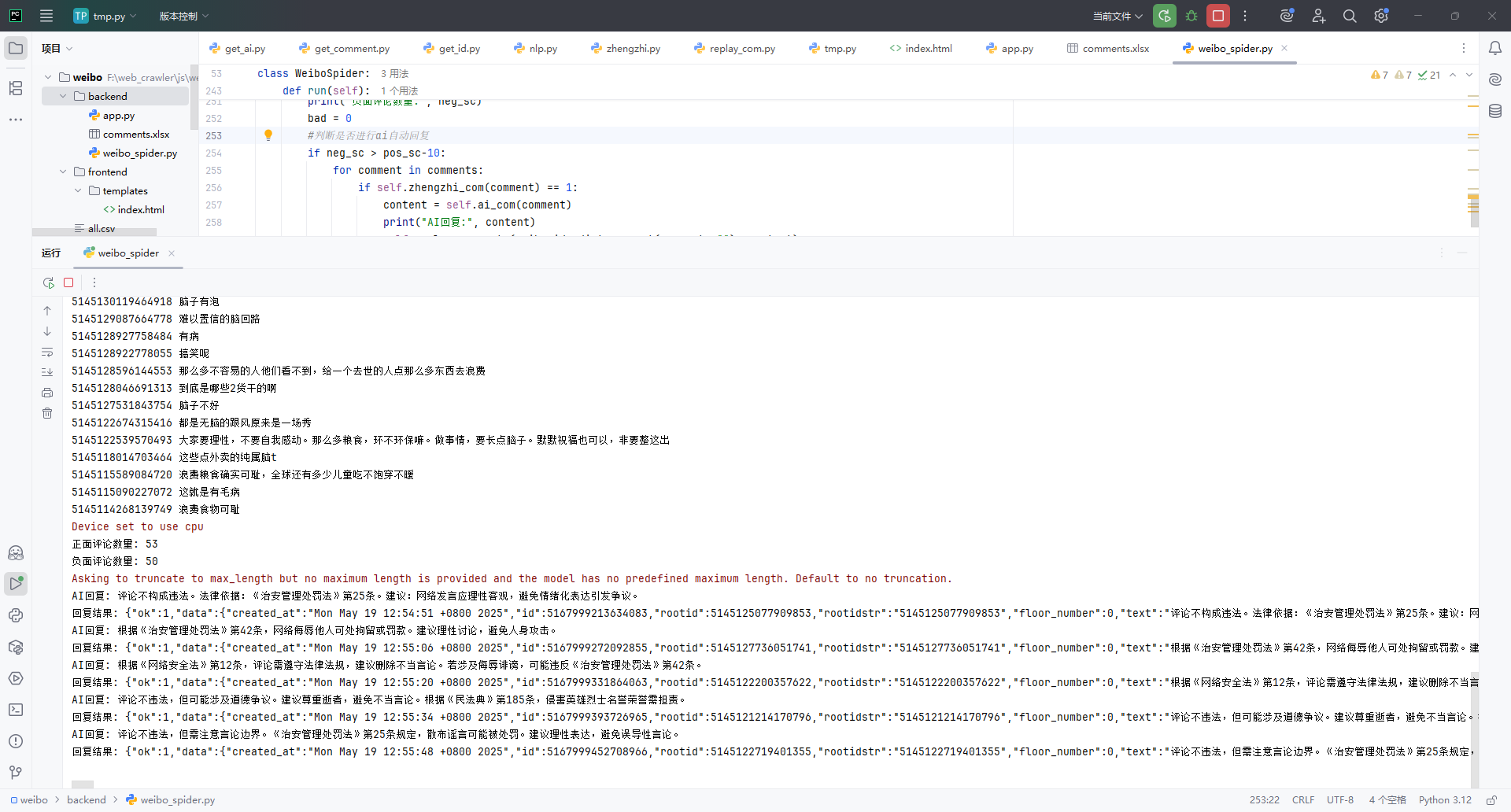
6. 优化方向
-
反爬策略增强:
-
添加IP代理池
-
实现Cookie自动更新
-
-
模型优化:
-
使用更大规模的中文预训练模型
-
加入自定义训练数据
-
-
功能扩展:
-
支持多微博同时监控
-
添加可视化分析面板
-
7. 总结
本项目实现了微博评论的自动化处理闭环,主要创新点:
-
将情感分析与法律条文回复相结合
-
双存储方案保证数据可靠性
-
智能阈值判断降低误报率
代码
import re
import time
import requests
import pandas as pd
from transformers import pipeline, AutoModelForSequenceClassification, AutoTokenizer
import torch
from openai import OpenAI # 请确保已安装并正确配置 OpenAI SDK
import logging
import mysql.connector
from mysql.connector import Errorclass MySQLStorage:def __init__(self, host, user, password, database):self.host = hostself.user = userself.password = passwordself.database = databaseself.connection = Nonedef connect(self):try:self.connection = mysql.connector.connect(host=self.host,user=self.user,password=self.password,database=self.database)if self.connection.is_connected():logging.info("MySQL连接成功")except Error as e:logging.error("连接MySQL出错: %s", e)self.connection = Nonedef insert_comment(self, comment_id, comment_text, classification, reply):if not self.connection:self.connect()try:cursor = self.connection.cursor()sql = "INSERT INTO comments (comment_id, comment_text, classification, reply) VALUES (%s, %s, %s, %s)"values = (comment_id, comment_text, classification, reply)cursor.execute(sql, values)self.connection.commit()logging.info("插入评论ID %s 成功", comment_id)except Error as e:logging.error("插入评论时出错: %s", e)def close(self):if self.connection:self.connection.close()logging.info("MySQL连接关闭")class WeiboSpider:def __init__(self, mysql_storage=None):self.headers = {'accept': 'application/json, text/plain, */*','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6','cache-control': 'no-cache','client-version': 'v2.47.42','pragma': 'no-cache','priority': 'u=1, i','referer': 'https://weibo.com','sec-ch-ua': '"Chromium";v="134", "Not:A-Brand";v="24", "Microsoft Edge";v="134"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"','sec-fetch-dest': 'empty','sec-fetch-mode': 'cors','sec-fetch-site': 'same-origin','server-version': 'v2025.03.13.1','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0','x-requested-with': 'XMLHttpRequest','x-xsrf-token': 'dSkqzhoyOR93G8syKpQJyAK6',}self.cookies = {'PC_TOKEN': 'b7063fd6a8','SCF': 'ApLwKgU7wH8un2lyl7onZ1dcBvI3q1epuPNFSFxuMr2n8iv6RrnGBsMOizTQ8qxB5kNTwzX0lUmeqa8SNPeh8ME.','SUB': '_2A25FLscfDeRhGeFH6lMV8yfNzz-IHXVmQkbXrDV8PUNbmtAbLUP3kW9Ne-lAJhc5FMVOy_Y3MCs3-DA0aRSLKoTc','SUBP': '0033WrSXqPxfM725Ws9jqgMF55529P9D9WWFGmFm5XRHK8Yuudiw2bKA5NHD95QN1K2pShe4eKB0Ws4Dqcj.i--ciKnRiK.pi--Ri-2ciKnpi--NiKnRi-i2i--NiKy8i-24','ALF': '02_1750221904','WBPSESS': 'FT0tjnG_uSkfs1RofpxMm5pUM9iNsMc-7Ud_mBJKmqp97lszgTfzKkQ2WdsmNdtegfc7aSrvkjrq05K1BbriOuzWdCHsg5myyuP3pi1vY0SScFtRt8S2HRwdljlfX5EBzTkwrmdbUHL4_A0kdHTeQQ==',
}self.model_name = "uer/roberta-base-finetuned-jd-binary-chinese"self.tokenizer = AutoTokenizer.from_pretrained(self.model_name)self.model = AutoModelForSequenceClassification.from_pretrained(self.model_name)#self.mysql_storage = mysql_storage # 可选:MySQL 存储对象self.excel_data = [] # 用于Excel存储@staticmethoddef filter_text(text):# 1. 删除括号及其中的内容(支持 < > { } [ ] ())text = re.sub(r'<[^>]*>|\{[^}]*\}|\[[^\]]*\]|\([^)]*\)', '', text)# 2. 只保留汉字、英文字母、数字和常见标点符号pattern = re.compile(r'[^\u4e00-\u9fa5a-zA-Z0-9,。!?、;:“”‘’()—…《》〈〉【】]+')filtered_text = re.sub(pattern, '', text)return filtered_textdef get_id(self, theme):try:params = {'id': theme,'locale': 'zh-CN','isGetLongText': 'true',}response = requests.get('https://weibo.com/ajax/statuses/show', params=params,cookies=self.cookies, headers=self.headers).json()weibo_id = response.get('id')if not weibo_id:raise ValueError("未获取到微博ID")return weibo_idexcept Exception as e:logging.error("get_id 出错: %s", e)return Nonedef get_comments(self, com_id):max_id = 0all_texts = []user_dict = {}try:while True:params = {'is_reload': '1','id': com_id,'is_show_bulletin': '2','is_mix': '0','max_id': max_id,'count': '10','uid': '1798653494','fetch_level': '0','locale': 'zh-CN',}response = requests.get('https://weibo.com/ajax/statuses/buildComments', params=params,cookies=self.cookies, headers=self.headers).json()max_id = response.get('max_id', 0)datas = response.get('data', [])if not datas:breakfor data in datas:cid = str(data.get('id', ''))text = str(data.get('text', ''))text = self.filter_text(text)all_texts.append(text)user_dict[text] = cid# 同时记录到Excel数据中self.excel_data.append({'comment_id': cid,'comment_text': text,})print(cid, text)if max_id == 0:breaktime.sleep(3)except Exception as e:logging.error("get_comments 出错: %s", e)return all_texts, user_dictdef replay_comments(self, com_id, user_id, content):data = {'id': com_id,'cid': user_id,'comment': content,'pic_id': '','is_repost': '0','comment_ori': '0','is_comment': '0',}try:response = requests.post('https://weibo.com/ajax/comments/reply',cookies=self.cookies, headers=self.headers, data=data)print("回复结果:", response.text)except Exception as e:logging.error("replay_comments 出错: %s", e)time.sleep(5)def ana_com(self, sample_comments):pos_score = 0neg_score = 0try:sentiment_pipeline = pipeline("sentiment-analysis", model=self.model_name)results = sentiment_pipeline(sample_comments)for comment, result in zip(sample_comments, results):label = result.get('label', '')if label.startswith("negative"):neg_score += 1else:pos_score += 1except Exception as e:logging.error("ana_com 出错: %s", e)return pos_score, neg_scoredef zhengzhi_com(self, text):try:inputs = self.tokenizer(text, return_tensors="pt", truncation=True, padding=True)outputs = self.model(**inputs)probs = torch.softmax(outputs.logits, dim=-1)result = torch.argmax(probs, dim=-1).item()return 1 if result == 1 else 0except Exception as e:logging.error("zhengzhi_com 出错: %s", e)return 0def ai_com(self, sample_comment):try:client = OpenAI(api_key="你自己的key", base_url="https://api.deepseek.com")response = client.chat.completions.create(model="deepseek-chat",messages=[{"role": "system","content": "你是一个精通法律且经常上网冲浪的人,懂得网友回复,帮我判断微博评论的违法性,并给出法律条文回复和建议,要求简洁精炼,字数不能超过50字,否则无法回复,法律条文可以说的不具体"},{"role": "user", "content": sample_comment},],stream=False)reply = response.choices[0].message.contentreturn replyexcept Exception as e:logging.error("ai_com 出错: %s", e)return "无法生成回复"def send_mess(self):# 这里填写短信发送逻辑,可调用第三方短信APIprint("发送短信提醒...")def store_to_mysql(self):if self.mysql_storage:for data in self.excel_data:comment_text = data.get('comment_text', '')comment_id = data.get('comment_id', '')classification = "不当" if self.zhengzhi_com(comment_text) == 1 else "正常"reply = ""if classification == "不当":reply = self.ai_com(comment_text)self.replay_comments(comment_id, comment_id, reply)self.mysql_storage.insert_comment(comment_id, comment_text, classification, reply)def store_to_excel(self, excel_file="comments.xlsx"):try:df = pd.DataFrame(self.excel_data)df.to_excel(excel_file, index=False)print("数据已导出到", excel_file)except Exception as e:logging.error("store_to_excel 出错: %s", e)def run(self):weibo_id = self.get_id('PiV4XoZZM')if not weibo_id:print("获取微博ID失败")returncomments, dict_com = self.get_comments(weibo_id)pos_sc, neg_sc = self.ana_com(comments)print("正面评论数量:", pos_sc)print("负面评论数量:", neg_sc)bad = 0#判断是否进行ai自动回复if neg_sc > pos_sc-10:for comment in comments:if self.zhengzhi_com(comment) == 1:content = self.ai_com(comment)print("AI回复:", content)self.replay_comments(weibo_id, dict_com.get(comment, ""), content)bad += 1if neg_sc >= pos_sc and bad > pos_sc/2:self.send_mess()# 将数据分别存储到 MySQL 和 Excel#self.store_to_mysql()self.store_to_excel()time.sleep(60)
if __name__ == '__main__':weibo_spider = WeiboSpider()weibo_spider.run()