LangChain框架核心技术:从链式工作流到结构化输出的全栈指南
LangChain 核心概念与实践指南:链、LCEL表达式与输出解析器
导读:在大模型应用开发的浪潮中,LangChain已成为构建AI应用的主流框架。本文深入解析了LangChain最核心的三大技术:Chain链式处理、LCEL表达式和输出解析器,为开发者提供从理论到实践的全方位指导。
文章首先揭示了Chain链的设计本质和工作原理,解释了为何链式结构能有效解决大模型应用的复杂性问题;接着介绍了更为现代化的LCEL表达式语法,展示了如何用简洁优雅的管道符来替代传统的链式调用;随后探讨了流式响应技术如何在保持代码简洁的同时大幅提升用户体验;最后详细阐述了各类输出解析器如何将自由文本转化为结构化数据,便于程序处理和业务集成。
文中不仅提供了丰富的代码示例,还分享了实战经验和性能优化技巧,如何在不同场景选择合适的组件组合?如何避免常见的开发陷阱?阅读本文,你将掌握构建从简单问答到复杂推理系统的全套技术路线图。
1. Chain链:大模型应用的核心构建模块
1.1 Chain链的概念与本质
Chain(链)是LangChain框架中最基础的构建模块,它将多个组件按照特定顺序连接起来,形成完整的处理流程。链的概念源自软件工程中的责任链模式和工作流引擎,但在大语言模型(LLM)应用中有其独特性。
链的本质是将复杂任务分解成多个独立处理单元,实现模块化、可复用的工作流程。这种设计理念使得开发者可以灵活组合各种组件,构建从简单问答到复杂推理的各类应用。
技术背景:传统软件开发中的责任链模式要求每个处理单元只负责自己的工作,然后将结果传递给下一环节。LangChain的链式设计沿袭了这一理念,将其应用于LLM应用场景,使复杂的语言处理任务变得可管理、可扩展。
1.2 LLMChain深度解析
LLMChain是最基础的链类型,它主要负责将提示模板与LLM模型结合,生成预期的输出。虽然在最新版本(0.3+)中,LangChain推荐使用LCEL(LangChain表达式语言)替代传统的LLMChain,但理解其工作原理对掌握整个框架仍然至关重要。
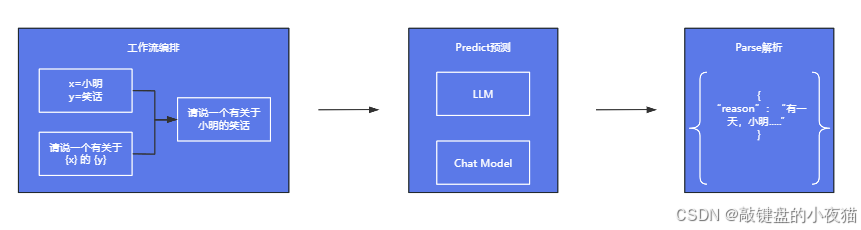
核心组件与工作原理:
- 提示模板(Prompt Template):定义与LLM交互的文本格式,包含变量占位符
- 语言模型(LLM):处理提示词并生成回复的核心引擎
- 输出解析器(Output Parser):可选组件,将LLM的原始输出转换为结构化数据
从软件设计角度看,LLMChain遵循了依赖注入的设计模式,将关键组件作为参数传入,增强了灵活性和可测试性。
核心参数对比
| 参数 | 类比Java场景 | 示例值 |
|---|---|---|
| llm | 依赖注入的模型对象 | new OpenAI() |
| prompt | 预定义的模板 | PromptTemplate(“回答: {input}”) |
| output_parser | 结果解析器 | new CommaSeparatedListOutputParser() |
实际应用示例:
from langchain_core.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.chains import LLMChain# 1. 创建提示词模板
prompt_template = PromptTemplate(input_variables=["name"],template="你是一个文案高手,专门为{name}设计文案,列举3个卖点"
)# 2. 初始化大语言模型
model = ChatOpenAI(model_name="qwen-plus",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",api_key="sk-xxxxxxxxxxxxxxxxxxx",temperature=0.7 # 控制创造性,越高越创造性但可能偏离主题
)# 3. 构建LLMChain
chain = LLMChain(llm=model,prompt=prompt_template
)# 4. 执行调用
result = chain.invoke("智能手机")
print(result) # 将输出产品文案要点
实践说明:LLMChain类似于传统后端开发中的Service层,将输入经过一系列处理后产生输出。
invoke()方法替代了早期版本的run()方法,是当前推荐的调用方式。
2. LCEL表达式:声明式AI流程编排
2.1 LCEL概述与优势
LCEL(LangChain Expression Language)是LangChain 0.3+版本推出的一种声明式编程语言,用于简化AI应用流程编排。它采用管道符(|)连接各组件,使代码更简洁、直观。
LCEL的核心优势:
- 简洁易读:通过管道符(|)连接组件,代码结构一目了然
- 原生流支持:支持流式响应,用户无需等待完整结果生成
- 接口标准化:所有组件具有统一的输入输出接口,支持无缝连接
- 并发与异步:原生支持异步操作,增强处理效率
- 自动追踪:与LangSmith集成,提供完整的可观察性能力
2.2 LLMChain与LCEL对比分析
传统的LLMChain与现代LCEL在语法、功能和适用场景上有显著差异:
| 特性 | 0.2 版本(LLMChain) | 0.3+ 版本(LCEL) |
|---|---|---|
| 构建方式 | 类继承(Chain 子类) | LCEL 表达式语法(Runnable 接口) |
| 组合方法 | SequentialChain 类v管道操作符 | |
| 执行模式 | 主要支持同步 | 原生支持 异步/流式处理 |
| 核心模块 | langchain.chains | langchain_core.runnables |
| 代码复杂度 | 高(需显式定义多个组件) | 低(管道符简化组合) |
| 调试与监控 | 有限 | 强大(集成LangSmith) |
| 适用场景 | 简单原型、单步处理任务 | 复杂工作流、生产级应用 |
2.3 LCEL实战案例
下面通过一个简单的问答系统展示LCEL的简洁强大:
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser# 1. 定义提示模板
prompt = ChatPromptTemplate.from_template("回答问题: {question}")# 2. 初始化模型
model = ChatOpenAI(model_name="qwen-plus",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxx",temperature=0.7
)# 3. 定义输出解析器
parser = StrOutputParser()# 4. 使用管道符构建LCEL链
chain = prompt | model | parser# 5. 调用链获取结果
result = chain.invoke({"question": "如何学习AI大模型?"})
print(result)
技术洞察:LCEL的管道语法借鉴了Unix管道操作符的设计理念,将一个组件的输出直接作为下一个组件的输入。这种设计不仅使代码更简洁,还提高了组件的可复用性和组合灵活性。
3. 流式响应:提升用户体验的关键技术
3.1 流式响应原理与价值
传统的LLM调用采用"请求-等待-响应"模式,用户需等待完整结果生成后才能看到回复,体验较差。流式响应(Streaming Response)则采用逐步返回的方式,实时传递生成内容,显著提升用户体验。
技术原理:流式响应基于HTTP的分块传输编码(Chunked Transfer Encoding),允许服务器在生成每个内容块后立即发送,而不必等待整个内容生成完毕。
3.2 流式响应实现方式
LangChain提供了两种实现流式响应的方式:
- 直接模型流式输出:适用于简单场景
- LCEL流式链:适用于复杂处理流程
基础案例:故事生成器
from langchain_openai import ChatOpenAI# 初始化支持流式输出的模型
model = ChatOpenAI(model_name="qwen-plus",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxx",temperature=0.7
)# 流式输出故事,逐字显示
for chunk in model.stream("讲一个关于人工智能的短故事"):print(chunk.content, end="", flush=True)
高级案例:LCEL流式科普助手
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser# 1. 定义提示模板
prompt = ChatPromptTemplate.from_template("用100字解释以下概念: {concept}")# 2. 初始化支持流式的模型
model = ChatOpenAI(model_name="qwen-plus",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",api_key="sk-xxxxxxxxxxxxxxxxxx",temperature=0.7,streaming=True # 启用流式输出
)# 3. 构建流式链
streaming_chain = prompt | model | StrOutputParser()# 4. 执行流式调用并实时输出
for chunk in streaming_chain.stream({"concept": "量子计算"}):print(chunk, end="", flush=True)
3.3 流式响应的优势与限制
优势:
- 用户体验大幅提升,消除等待焦虑
- 节省内存资源,避免一次性加载大量数据
- 支持多种交互模式(同步、异步、事件驱动)
限制:
- 某些复杂操作节点可能造成延迟
- 需处理更复杂的错误情况和状态管理
- 对网络稳定性要求更高
最佳实践:流式响应特别适用于内容生成、聊天机器人等交互场景,能显著提升用户感知体验。对于内部API调用或批处理任务,传统的非流式调用可能更为合适。
4. 输出解析器:结构化大模型响应的关键
4.1 输出解析器的价值与工作原理
大语言模型默认输出自由文本,而实际应用通常需要结构化数据。输出解析器(Output Parser)的核心作用是将LLM生成的文本转换为程序可处理的结构化数据。
工作原理:
- 在提示模板中加入格式指导(通过占位符变量)
- LLM按格式要求生成文本
- 解析器将文本转换为特定数据结构(如JSON、列表、对象等)
4.2 输出解析器的核心接口
输出解析器提供三个关键方法:
解析器核心接口
| 方法 | 功能描述 |
|---|---|
| parse() | 将原始文本解析为结构化数据 |
| parse_with_prompt() | 结合提示词上下文进行解析,适用于多轮对话 |
| get_format_instructions() | 生成提示词指南,告诉LLM如何格式化输出 |
4.3 常用解析器分析与实践
字符串解析器(StrOutputParser)
最基础的解析器,保留原始文本输出,适用于无需特殊处理的场景。
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate# 定义生成诗歌的链
prompt = ChatPromptTemplate.from_template("写一首关于{topic}的诗")
model = ChatOpenAI(model_name="qwen-plus",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",api_key="sk-xxxxxxxxxxxxxxxxxxx",temperature=0.7
)
parser = StrOutputParser()chain = prompt | model | parser
result = chain.invoke({"topic": "秋天"})
print(result) # 输出完整诗歌文本
逗号分隔列表解析器(CommaSeparatedListOutputParser)
将逗号分隔的文本转换为Python列表,适用于标签、选项等场景。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import CommaSeparatedListOutputParser
from langchain_openai import ChatOpenAI# 获取格式指令
parser = CommaSeparatedListOutputParser()
format_instructions = parser.get_format_instructions()# 创建包含格式要求的提示模板
prompt = ChatPromptTemplate.from_template("列出5个与{topic}相关的关键词。\n{format_instructions}"
)model = ChatOpenAI(model_name="qwen-plus",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",api_key="sk-xxxxxxxxxxxxxxxxxx",temperature=0.7
)# 构建完整链并执行
chain = prompt.partial(format_instructions=format_instructions) | model | parser
result = chain.invoke({"topic": "人工智能"})
print(result) # 输出: ['深度学习', '机器学习', '神经网络', '自然语言处理', '计算机视觉']
print(type(result)) # 输出: <class 'list'>
JSON解析器(JsonOutputParser)
将模型输出解析为JSON对象,适用于需要复杂结构化数据的场景。
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI# 定义提示模板
prompt = ChatPromptTemplate.from_template("""返回JSON格式的商品信息:{"name": "商品名称","price": 商品价格(数字),"features": ["特点1", "特点2", "特点3"]}商品描述:{input}"""
)model = ChatOpenAI(model_name="qwen-plus",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",temperature=0.7
)# 构建JSON解析链
chain = prompt | model | JsonOutputParser()
result = chain.invoke({"input": "这是一款新上市的超薄笔记本电脑,搭载最新处理器,重量仅1.2kg,含触控屏"})
print(result)
# 输出: {'name': '超薄触控笔记本', 'price': 5999, 'features': ['超薄设计', '最新处理器', '触控屏']}# 访问结构化数据
print(f"商品名称: {result['name']}")
print(f"价格: {result['price']}元")
print(f"特点: {', '.join(result['features'])}")
4.4 高级应用:问答系统答案提取
结合JSON解析器构建能提供答案与置信度的问答系统:
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI# 定义JSON格式要求的提示模板
prompt = ChatPromptTemplate.from_template("""回答以下问题,返回JSON格式:
{"answer": "详细的答案内容","confidence": 置信度[0-1],"sources": ["信息来源1", "信息来源2"] // 如有
}问题:{question}
""")model = ChatOpenAI(model_name="qwen-plus",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",api_key="sk-xxxxxxxxxxxxxxxxxxx",temperature=0.7
)# 构建问答链
qa_chain = prompt | model | JsonOutputParser()# 执行提问
result = qa_chain.invoke({"question": "地球的平均半径是多少?"})
print(result)
# {'answer': '地球的平均半径约为6,371公里。', 'confidence': 0.98, 'sources': ['NASA', 'National Geographic']}# 根据置信度决定是否采用答案
if result['confidence'] > 0.8:print(f"高可信度答案: {result['answer']}")if 'sources' in result:print(f"信息来源: {', '.join(result['sources'])}")
else:print("答案置信度不足,建议进一步验证")
技术挑战:虽然输出解析器能指导LLM生成特定格式的输出,但仍可能遇到格式不符合要求的情况,导致解析错误。实践中应添加错误处理机制,必要时让模型重试或对输出进行修复。
5. 总结与最佳实践
5.1 LangChain核心组件选择指南
针对不同场景,选择合适的组件组合方式:
| 应用场景 | 推荐组件 | 说明 |
|---|---|---|
| 简单文本生成 | LCEL + StrOutputParser | 最简洁的实现方式 |
| 结构化数据处理 | LCEL + JsonOutputParser | 便于后续程序处理 |
| 实时交互应用 | 流式响应 + LCEL | 提升用户体验 |
| 复杂工作流 | LCEL + 条件分支 | 灵活处理多种情况 |
| 原型快速开发 | LLMChain (旧版) | 简单场景仍可使用 |
5.2 性能与稳定性优化建议
- 合理使用流式响应:在用户交互场景开启,批处理场景可关闭
- 添加错误处理与重试机制:特别是在使用输出解析器时
- 调整温度参数:根据任务性质设置合适的temperature值
- 事实类查询:0.0-0.3
- 创意内容生成:0.7-1.0
- 缓存常见查询结果:减少API调用次数和延迟
- 异步处理大批量请求:避免阻塞主线程
5.3 LangChain发展趋势与展望
随着LangChain的不断发展,我们可以预见以下趋势:
- 更强大的LCEL表达式:支持更复杂的流程编排和条件处理
- 多模态模型支持增强:整合文本、图像、音频等多种模态
- 边缘部署优化:支持在低资源环境中高效运行
- 与开发工具深度集成:IDE插件、调试工具等助力开发效率
- 企业级特性增强:安全控制、角色权限、审计日志等
实践建议:随着LangChain快速迭代,建议开发者关注官方文档更新,通常新版本会带来更高效的实现方式。在设计AI应用时,采用模块化架构便于随新版本升级各组件。
6. 拓展阅读与学习资源
- LangChain官方文档:最新API和最佳实践
- LangSmith:LangChain应用调试与监控平台
- LCEL设计理念:深入理解LCEL表达式
- 输出解析器进阶指南:更多解析器类型与自定义方法