Google机器学习实践指南(训练与损失函数篇)
🔥 Google机器学习(4)-训练与损失函数解析
Google机器学习实战(4)-掌握模型训练核心机制,吃透损失函数设计
一、训练机制
▲ 模型训练三要素:
参数初始化→损失计算→梯度下降
二、核心概念解析
1. 模型训练本质
✅ 定义
通过优化算法在特征空间搜索最优参数组合,使预测值最大程度逼近真实标签的数学过程
✅ 损失函数
θ ∗ = arg m i n θ 1 N ∑ i = 1 N L ( y i , f θ ( x i ) ) θ^* = \arg min_{θ} \frac{1}{N}\sum_{i=1}^N L(y_i, f_θ(x_i)) θ∗=argminθN1∑i=1NL(yi,fθ(xi))
十大常用损失函数
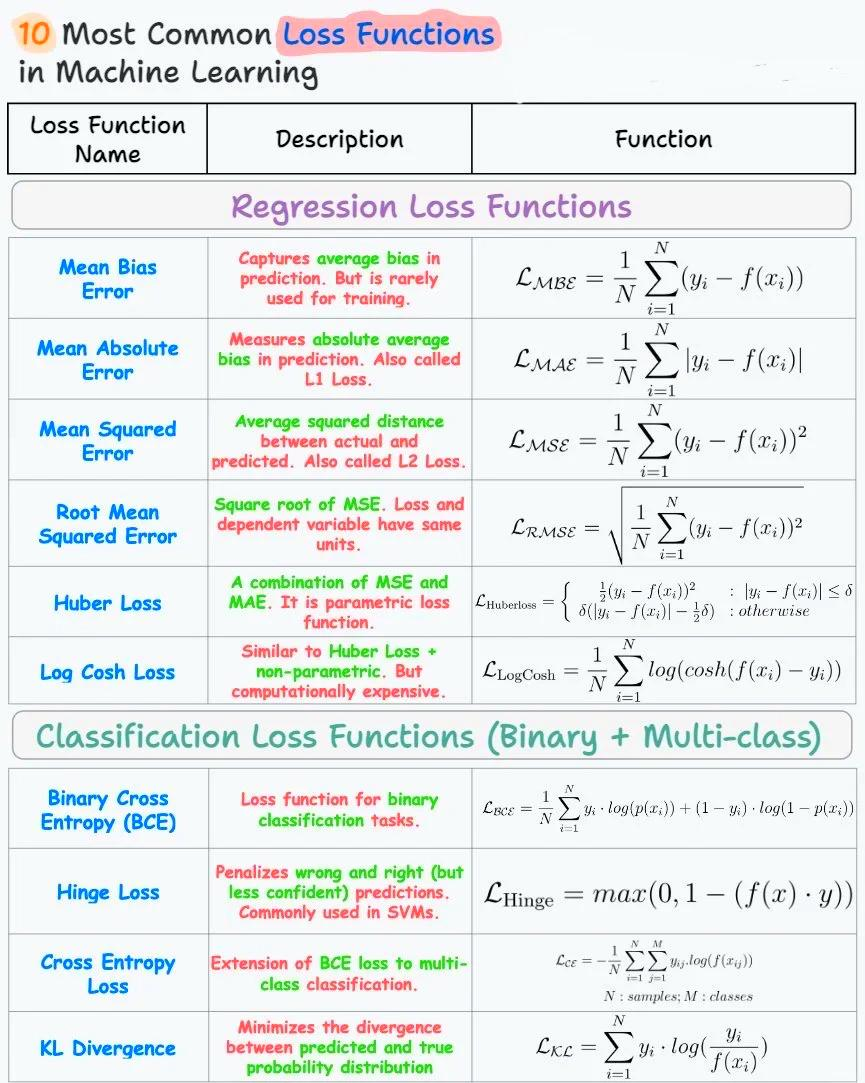
2. 损失函数演进
# TensorFlow损失计算示例
loss_object = tf.keras.losses.MeanSquaredError()
loss = loss_object(y_true, y_pred)
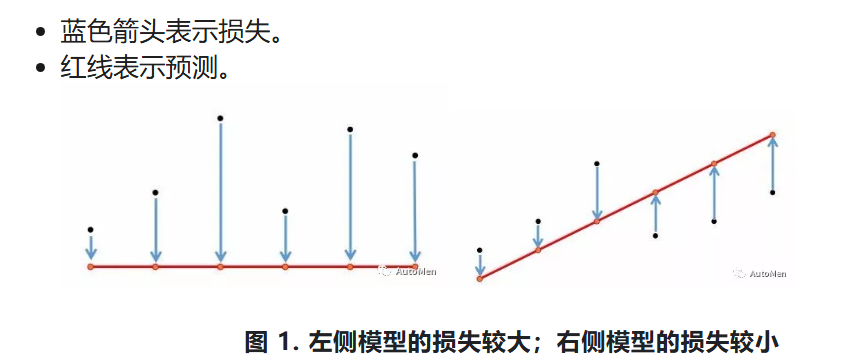
▲ 左:高损失模型(预测偏差大) 右:低损失模型(预测精准)
三、损失函数体系
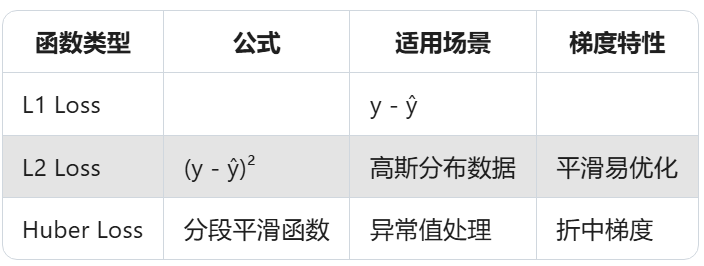
1. 平方损失(L2 Loss)
L ( y , y ^ ) = ( y − y ^ ) 2 L(y, \hat{y}) = (y - \hat{y})^2 L(y,y^)=(y−y^)2
✅ 特性分析
- 对异常值敏感(平方放大误差)
- 适用于高斯分布数据
- 梯度平滑易优化
2. 均方误差(MSE)
M S E = 1 N ∑ i = 1 N ( y i − y ^ i ) 2 MSE = \frac{1}{N}\sum_{i=1}^N (y_i - \hat{y}_i)^2 MSE=N1∑i=1N(yi−y^i)2
✅ 参数说明

四、损失函数对比
▲ 不同损失函数在房价预测中的表现差异可达12%
# 技术问答 #
Q:如何防止模型过拟合?
A:推荐使用L2正则化或早停策略
Q:何时选择MAE代替MSE?
A:当数据存在异常值时,MAE的鲁棒性更优