【ComfyUI】关于ComfyUI的一些基础知识和入门设置以及快捷键小技巧【简单易懂】
文章目录
- 一、SD WebUI和SD ComfyUI的区别
- 二、Stable Diffusion的底层原理
- 扩散算法
- CLIP
- Latent Space潜空间
- Unet
- VAE解码器
- 三、ComfyUI更新方法
- 四、各种小设置及快捷键
- 1、双击鼠标左键,调出搜索框
- 2、更换搜索框样式
- 3、菜单栏样式
- 4、调CLIP文本编码器字体大小
- 5、加载预设
- 6、ALT+ 1~9: 加载节点预设并设置成一个组
- 7、Shift+上/下/左/右:对其选中的节点
- 8、Shift+r:卸载节点缓存,与菜单栏里的清除缓存按钮功能相同,用于清理缓存
- 9、Shift+g:将选中的节点添加一个组
- 10、ctrl+B:关掉不想用的节点
- 11、节点重新连接
- 12、节点线优化
一、SD WebUI和SD ComfyUI的区别
SD:Stable Diffusion (稳定扩散)
WebUI和ComfyUI都是基于Stable Diffusion的,只是UI呈现方式不同
WebUI = 选择题 和 填空题
ComfyUI = 简答题
配置要求:
ComfyUI配置要求低于WebUI配置要求,而且是低非常多
相同显卡下:ComfyUI渲染速度比WebUI更快,启动程序和出图的速度要比WebUI更快
如果说WebUI要求的显存是在6GB到8GB以上。那么ComfyUI的显存要求可以低到4GB,它对显存的占用资源更节省。很多高清大图,比如说4k在WebUI很容易爆显存,但是在ComfyUI你可以甚至把它扩到8k的分辨率也不爆显存,不过在做大尺寸的图像时还是需要更多显存来支撑渲染的,但是没有那么多的显存也没关系,不需要你必须是16 GB、24 GB,显存当然越高越好了,建议是在有限的预算中,选择显存最高的那一款,性能是大于显存的,因为即使你出图再快,显存不足,还是生成不出图片的。
ComfyUI也是支持Windows、Linux和Mac系统,不过如果你的显卡是AMD显卡,则必须使用Linux系统,否则无法调用你的显卡,只能用CPU来渲染,英伟达显卡支持Windows和Linux系统。
Windows系统有专门的ComfyUI键整合包
整合包是什么呢?
就是把所有安装需要的环境和必备插件都整理在了一起,我们只需要下载解压即可使用。而另外两个系统Linux和Mac系统,暂时没有人做出这个整合包,需要纯本地部署,纯本地部署的意思就是需要安装他们需要的环境。
使用难度ComfyUI可以当做WebUI的进阶版,逻辑是互通的,但是使用的方式完全不同:
在WebUI内,只需要去选择或填写生图时用到的参数和模型等,这就对应着我前面讲到的选择题和填空题。
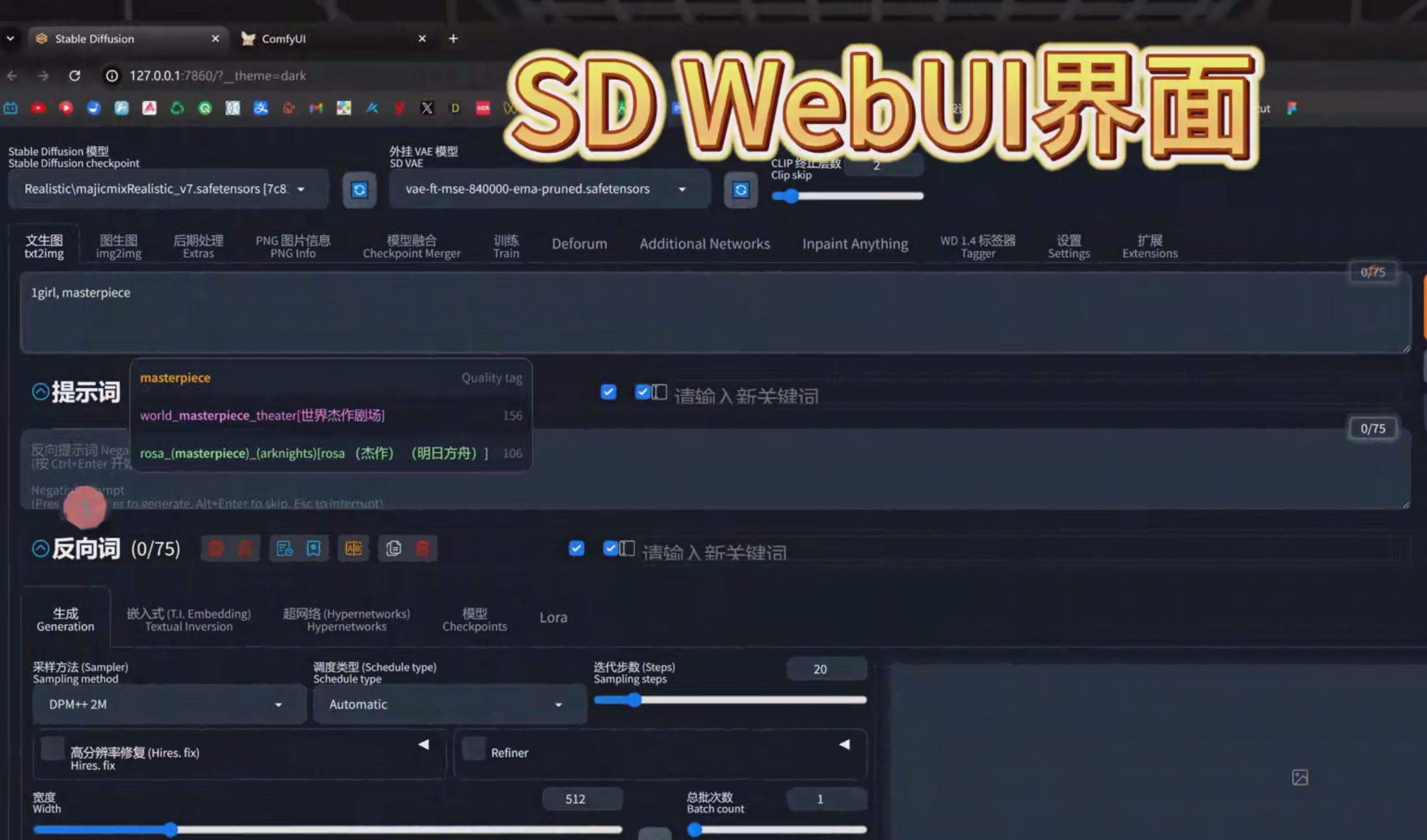
ComfyUI则需要自己搭建节点来生图。像图生图,高清分辨率修复等这些功能,在ComfyUI都是需要自己一个一个节点串联起来,在WebUI里边,我们只需要勾选它就代表打开高分辨率修复了。但是在ComfyUI想要做高分辨率修复,就要自己搭建一个一个节点去使用。
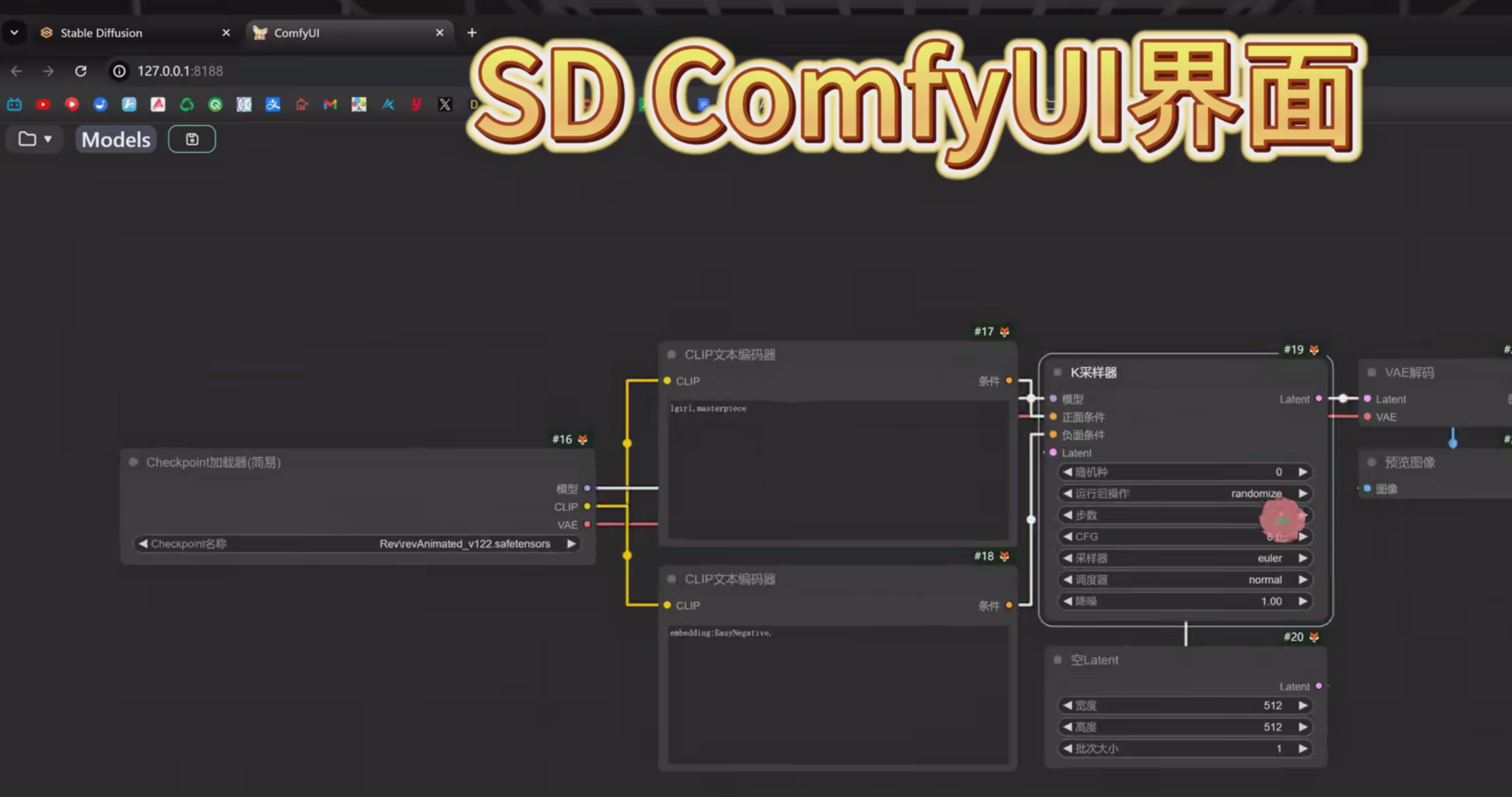
ComfyUI可以100%的复刻别人的工作流。甚至他们具体每个节点放置在什么位置都能一比一的还原,好多时候我们觉得节点搭建非常困难,其实我们只需要拿别人的工作流直接用就可以了。
更新迭代速度ComfyUI的更新迭代速度是非常快的,基本上是每天更新好几次
功能的区别:几乎所有插件WebUI能用ComfyUI也能用。不过,功能和可控性方面ComfyUI是更胜一筹的,因为ComfyUI的灵活度很高。一个节点可以和不同的节点去做配合,并且对功能的拆解也更多,
总结:
ComfyUI和WebUI相比:
优点:对显存的要求更低,生图速度更快,同时也可以做到WebUI做不到的事情。
缺点:更新频率比较快。使用难度稍微比WebUI难一些。
二、Stable Diffusion的底层原理
Stable :稳定的 Diffusion:扩散
基本概念: SD基于扩散算法(diffusion)生成图像,中文译为"稳定的扩散"
扩散算法
核心过程:简单来讲就是生噪和去噪的过程
实现方式: 先将图片铺满噪点,然后根据步数逐步降噪,最终得到目标图像
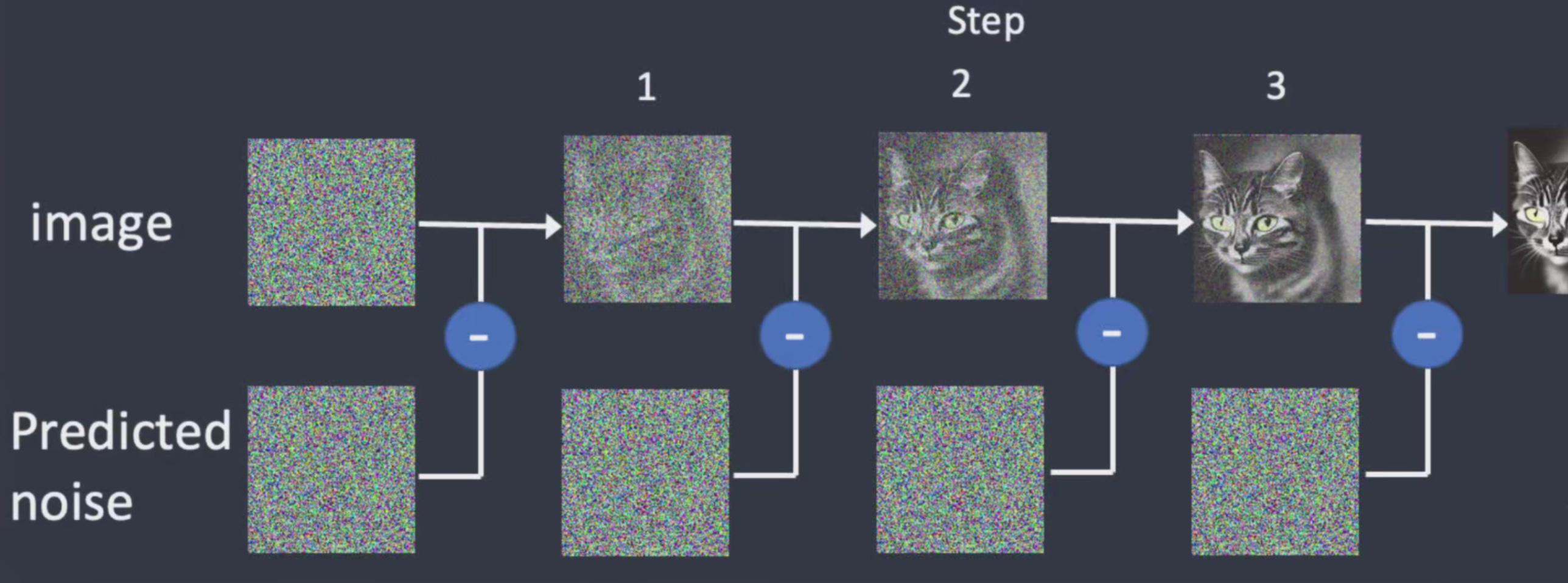
正向扩散: 生噪过程,增加噪点
反向扩散: 去噪过程,消除噪点
CLIP
Text Encoder文本编码器的一种
功能作用: 将人类语言翻译为计算机能理解的数字化描述(函数/向量)
实现原理:
文本信息(如"美丽女孩") → 数字化描述
根据模型训练经验识别特征(大眼睛、好身材等)
重要性: 使AI能捕捉文本含义,是SD工作流的关键组件
Latent Space潜空间
clip算法会根据此模型被训练调教的经验,大概感知到美丽的女孩。会有哪些特征?当我们的文本编码后,这些刚刚翻译成计算机能懂的这些语言,就会进入到latent space里。
功能:压缩图像
必要性:
512×512像素图片有786,432个数据(RGB三通道)
民用显卡难以直接计算如此大量数据
压缩方式:
原始: 512×512×3=786,432
压缩后: 64×64×4=16,384
优势: 大幅降低算力需求,使图像生成可行
Unet
核心功能: 在潜空间内对噪点进行引导和去噪
随机种子Seed:
范围: 0-4294967295
作用: 相同参数生成不同图片的原因
原理: 不同种子产生不同噪点模式
工作位置: 与采样器、调度器等参数共同在潜空间工作
VAE解码器
功能作用: 将计算机理解的向量数据解码为人类可识别的图像
工作流程:
编码器:人类语言→计算机理解
解码器:计算机数据→人类可视图像
必要性: 潜空间数据需要解压才能呈现最终结果
案例:
文生图工作流
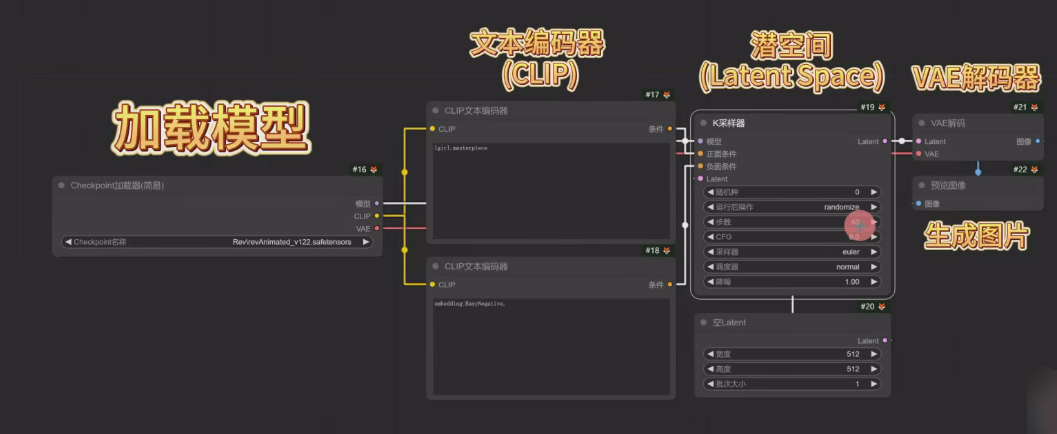
总结:
流程:关键词 -> 文本编码器(翻译)-> 潜在空间(压缩)-> U-net(去噪)-> VAE解码器(解压)-> 生成图像
三、ComfyUI更新方法
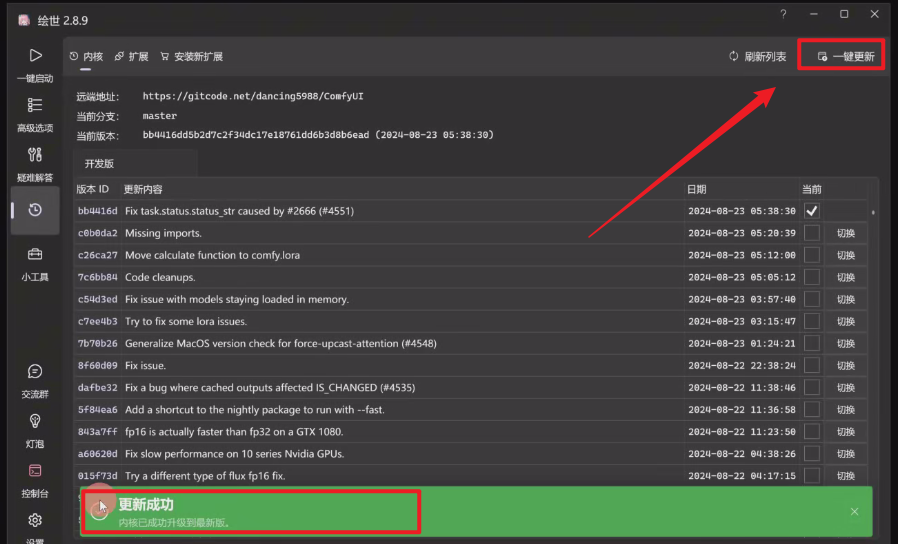
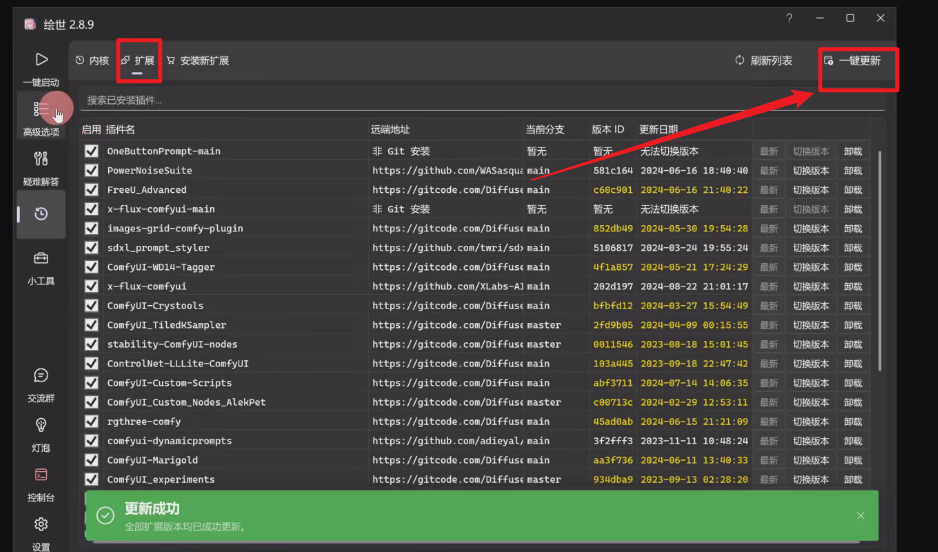
更新完毕!
四、各种小设置及快捷键
1、双击鼠标左键,调出搜索框
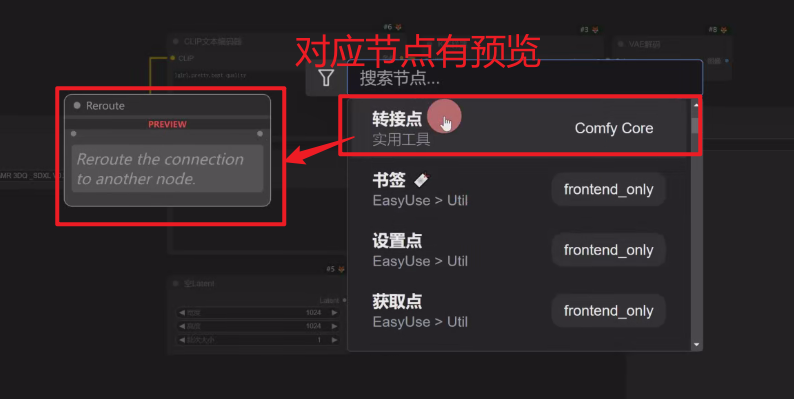
提示:如果中文搜索不到,说明不支持中文搜索,可能与中英翻译AIGodlike节点包有冲突
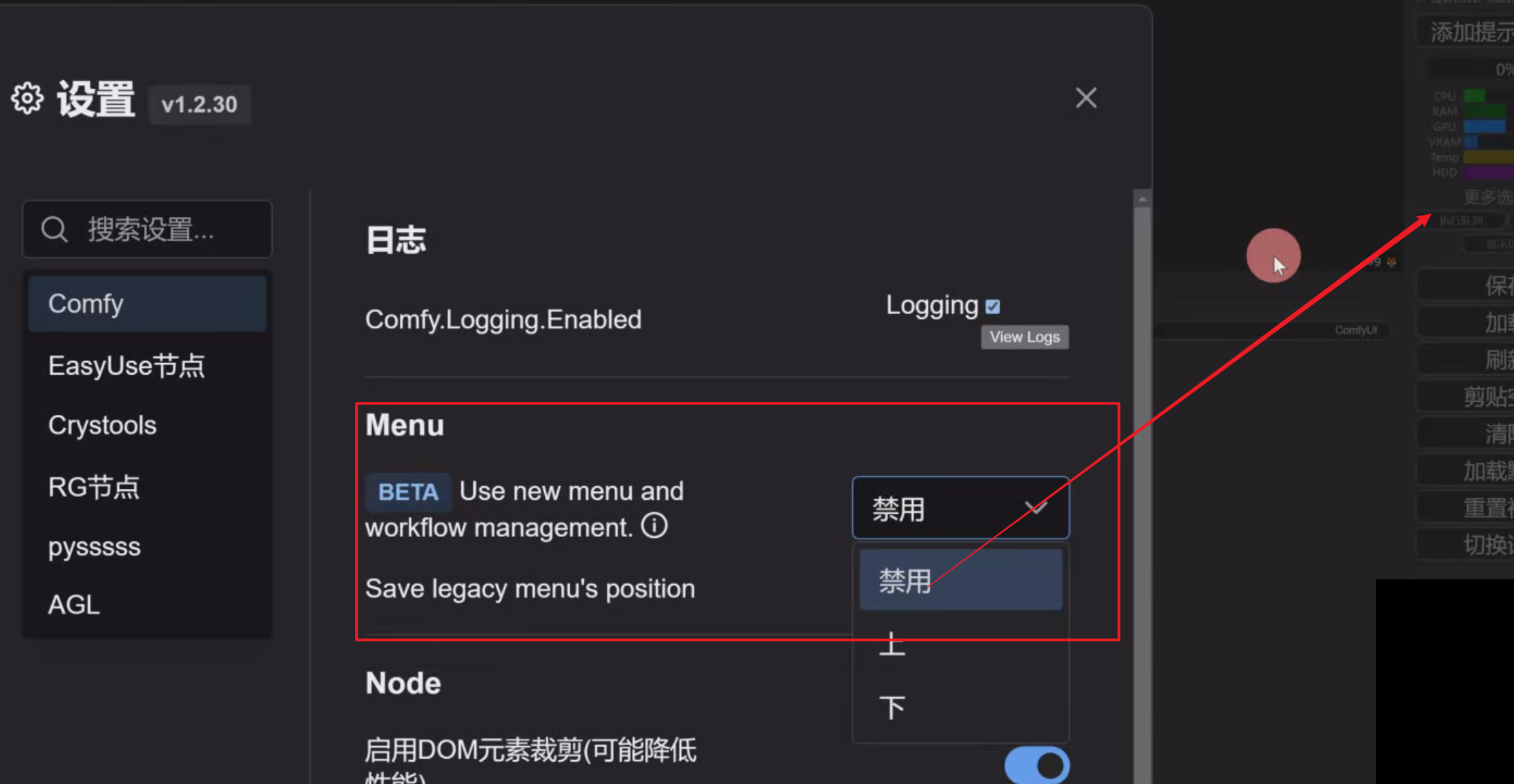
2、更换搜索框样式
到设置里面,找到BETA Node search box implementation 将默认改成 litegraph
BETA: 代表刚更新后的测试版本,非正式的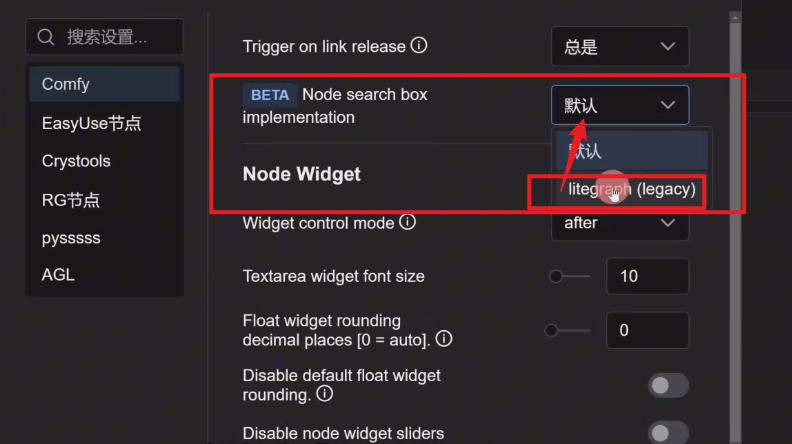
改完之后:
3、菜单栏样式
禁用:
上:



下:
菜单栏与“上”一样,只不过是在底部展示
4、调CLIP文本编码器字体大小
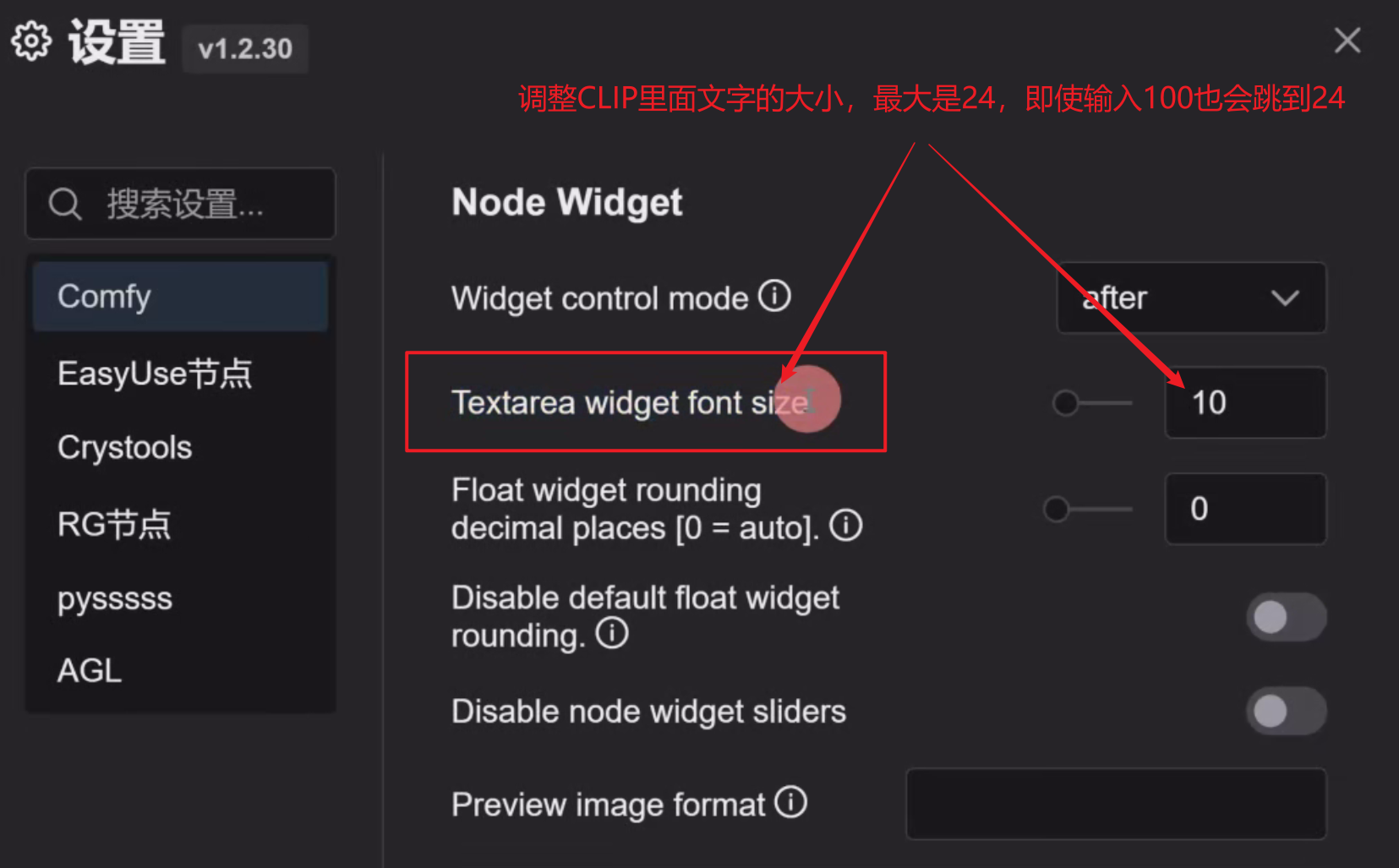
5、加载预设
传统设置预设方式:
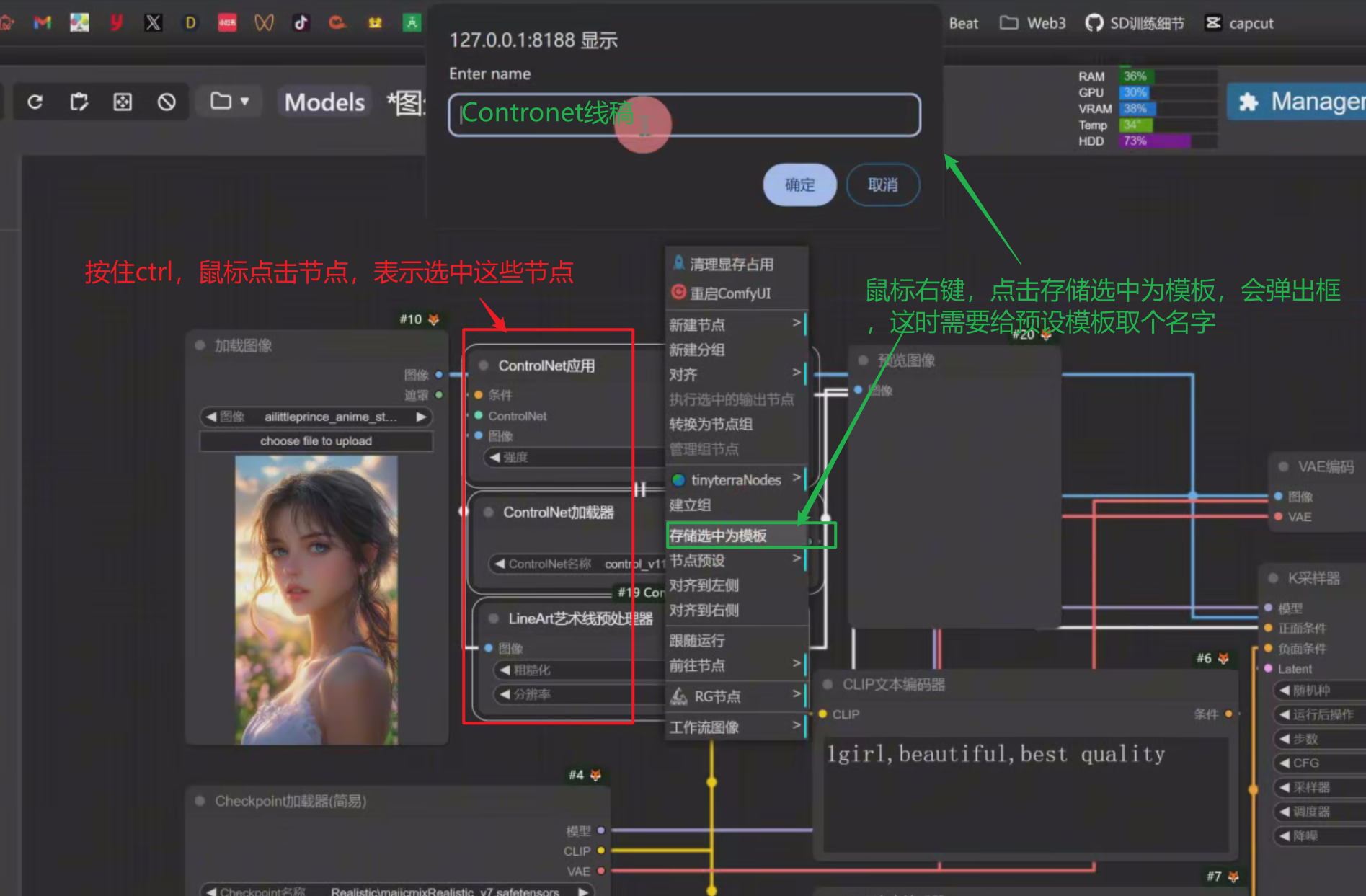
传统加载预设方式:
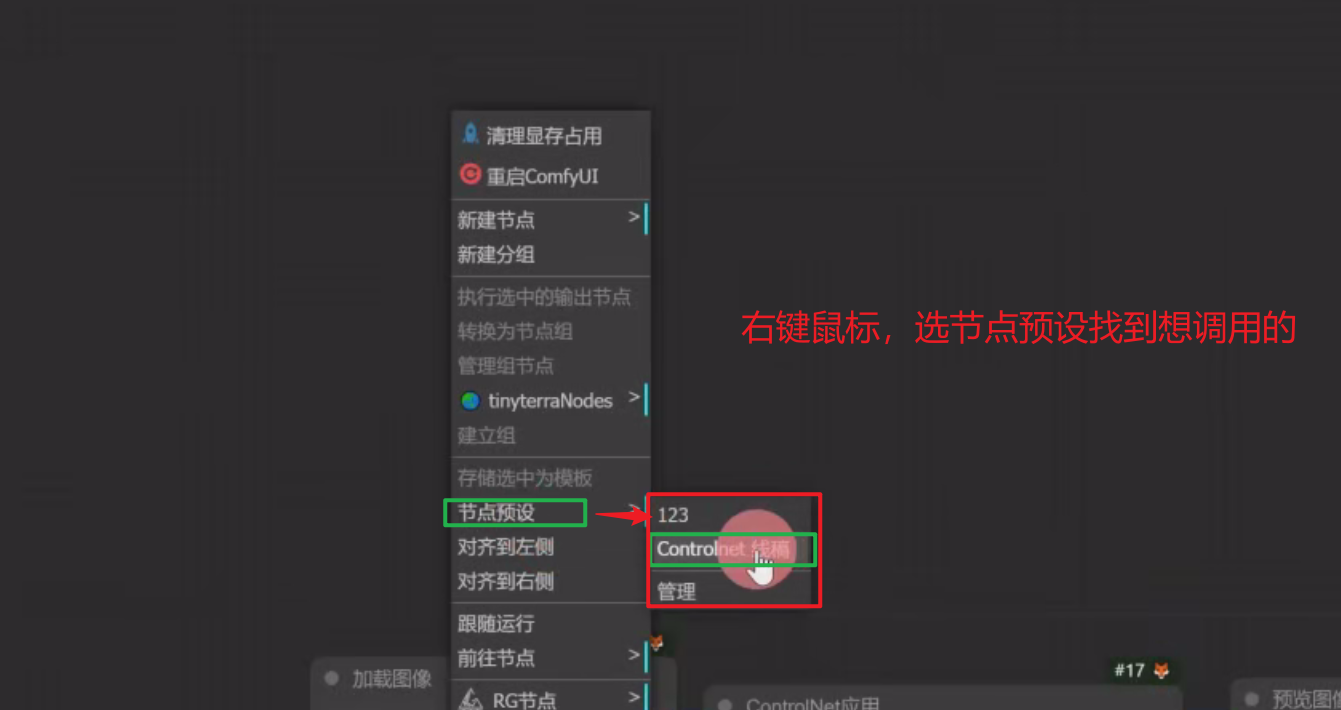
6、ALT+ 1~9: 加载节点预设并设置成一个组
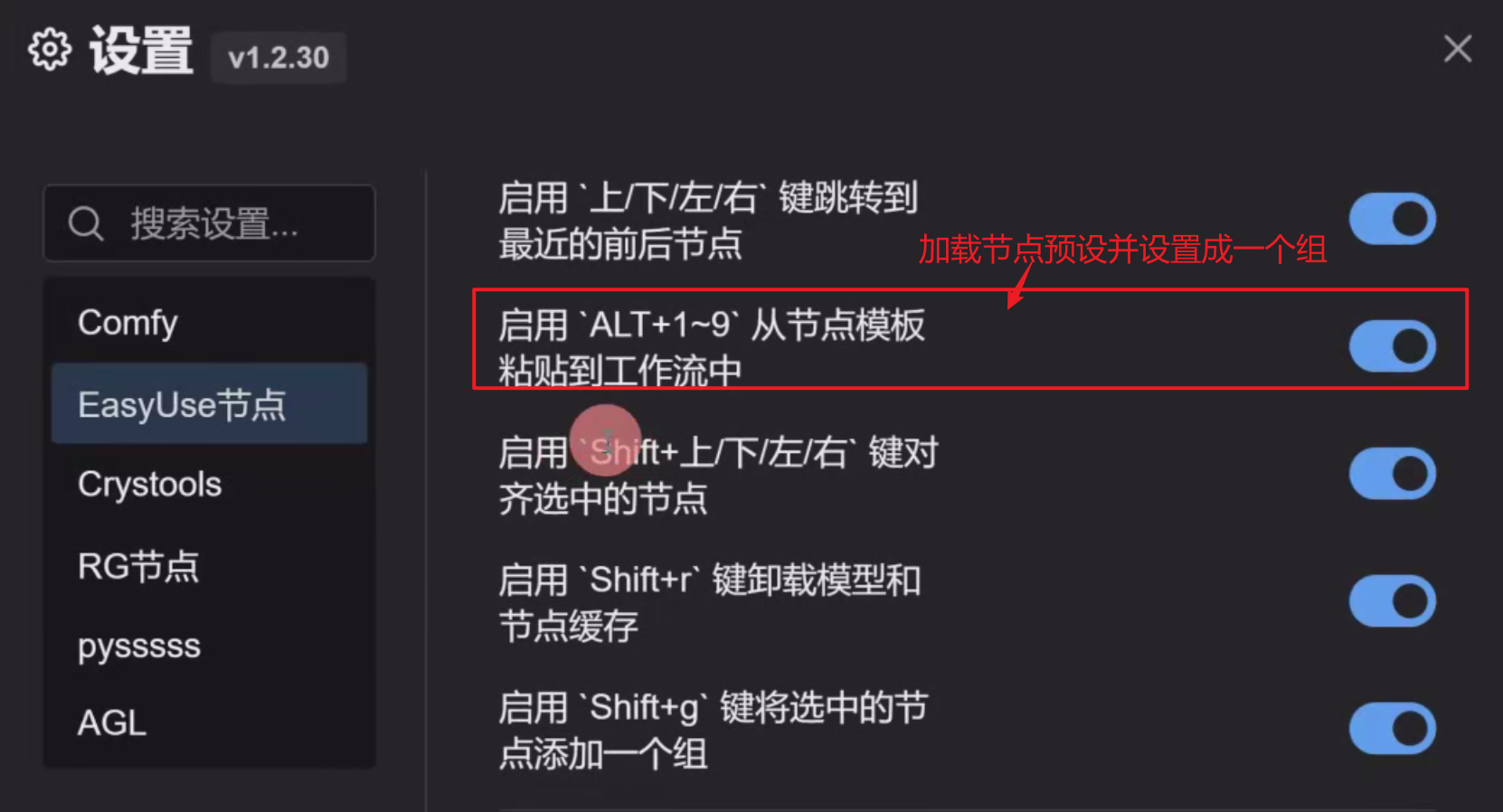
右键节点预设,有两个
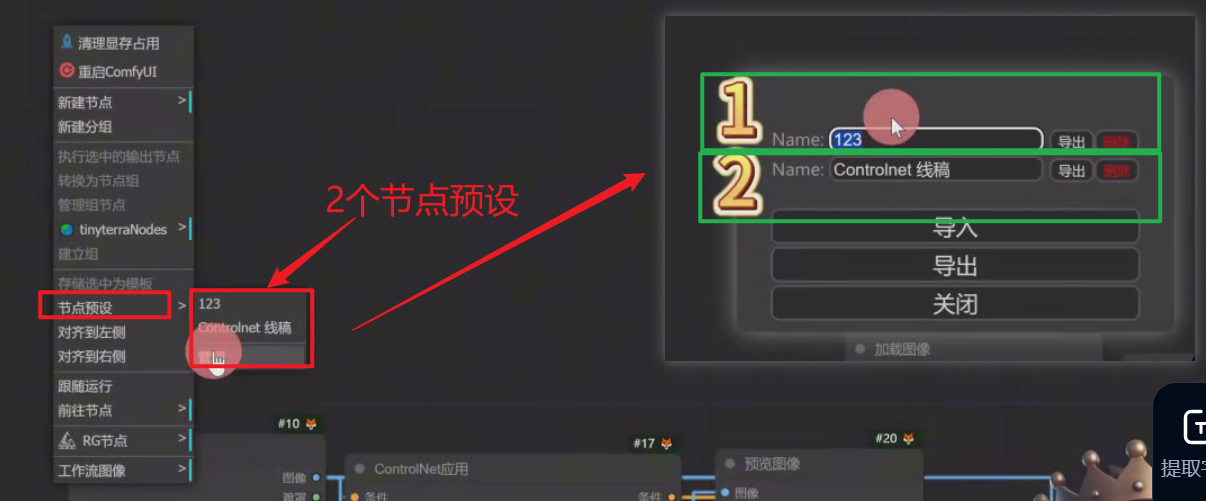
调出第一个节点预设:ALT+1
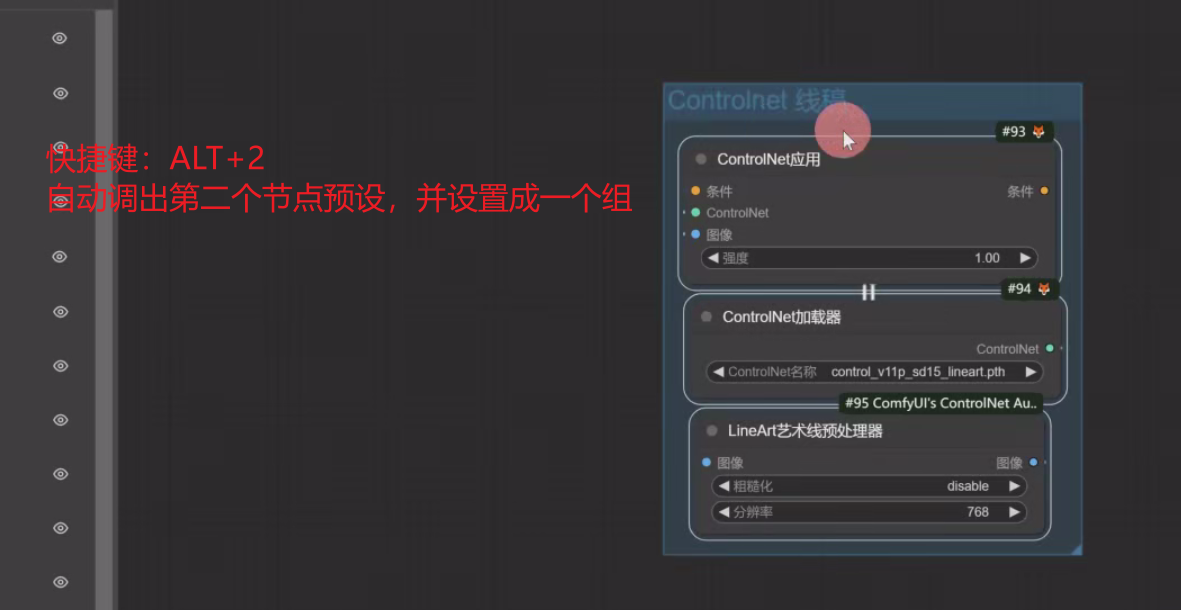
调出第二个节点预设:ALT+2 (如下图)
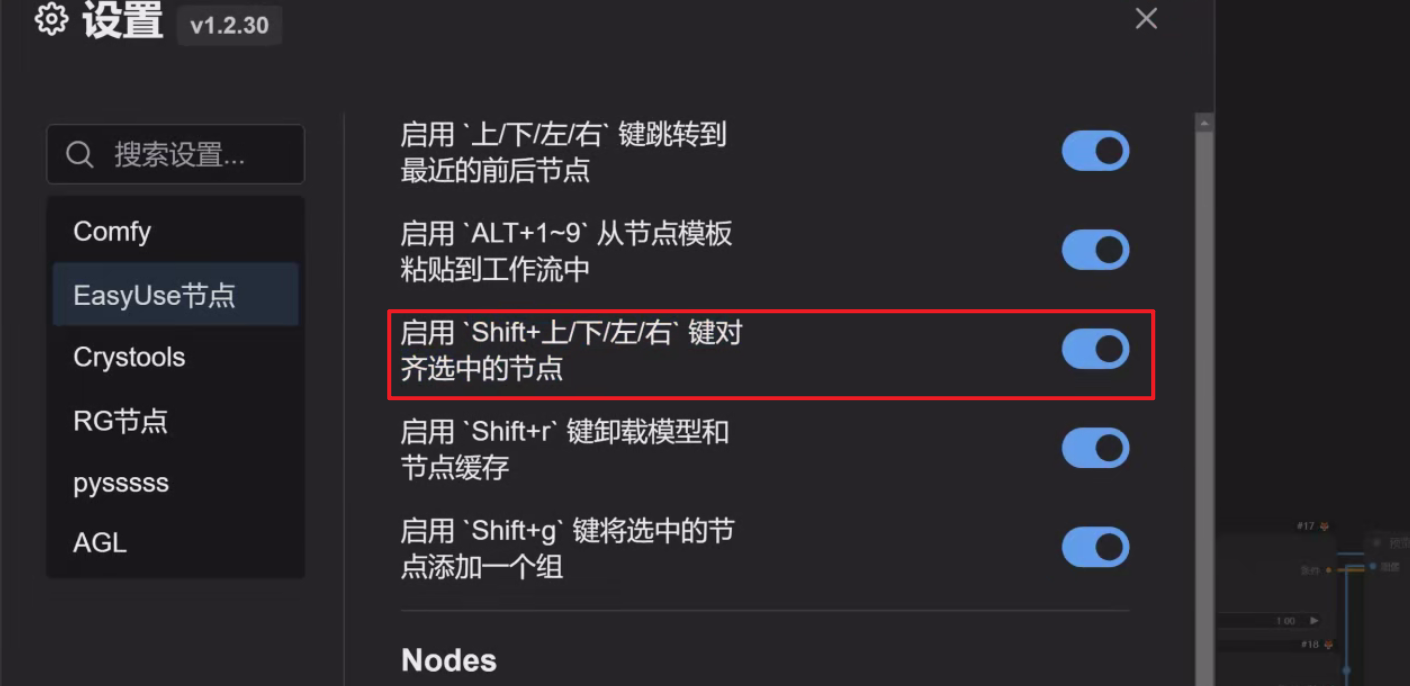
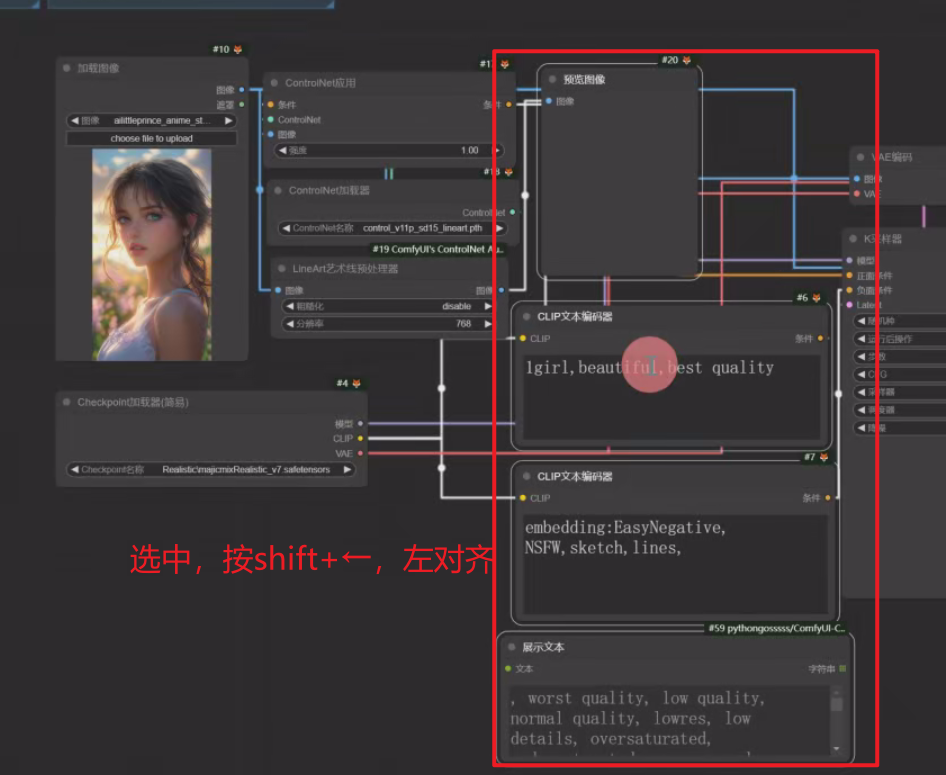
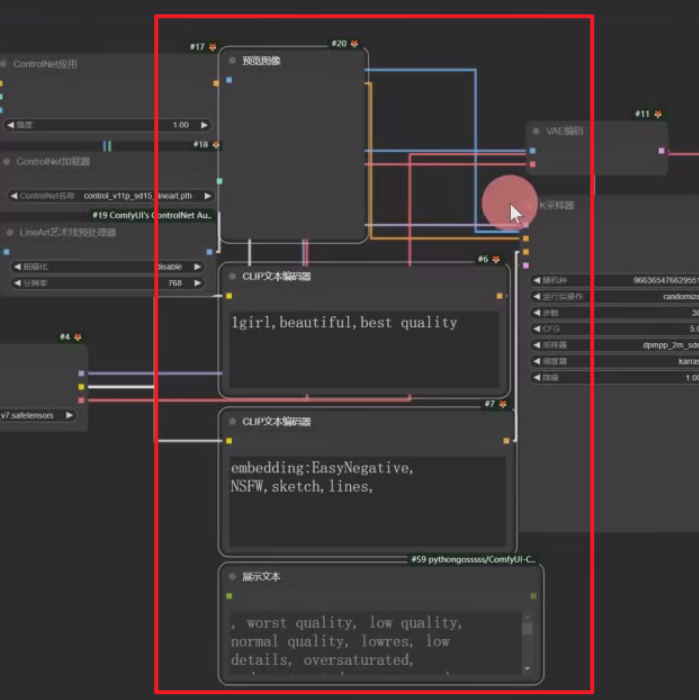
7、Shift+上/下/左/右:对其选中的节点
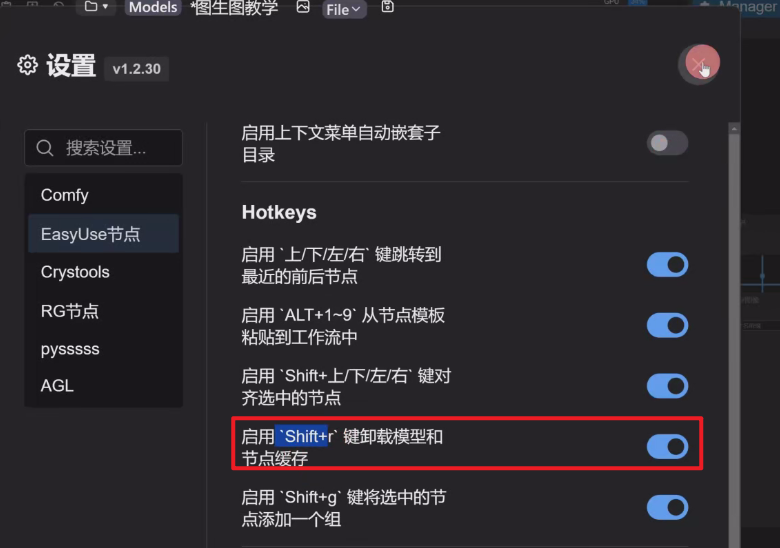
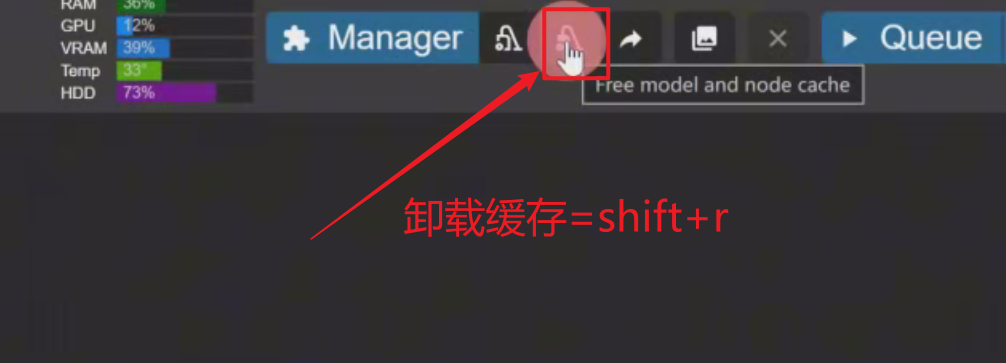
8、Shift+r:卸载节点缓存,与菜单栏里的清除缓存按钮功能相同,用于清理缓存
9、Shift+g:将选中的节点添加一个组
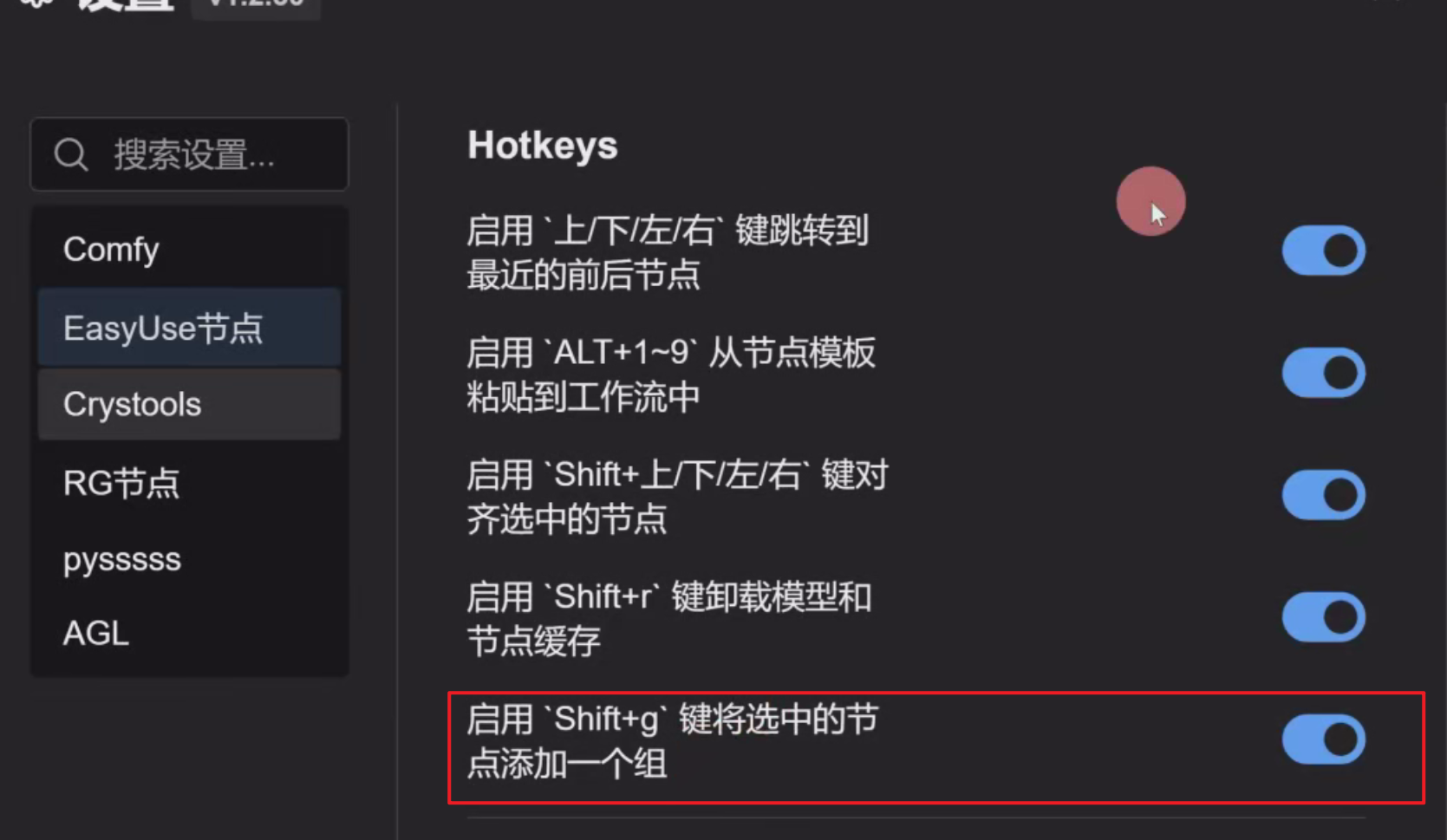
传统打组:右键->新建分组 -> 取分组名 -> 出现蓝色框,拉取放大,然后将节点拉进蓝色框里
快捷键打组:选中要打组的节点 -> shift + g
10、ctrl+B:关掉不想用的节点
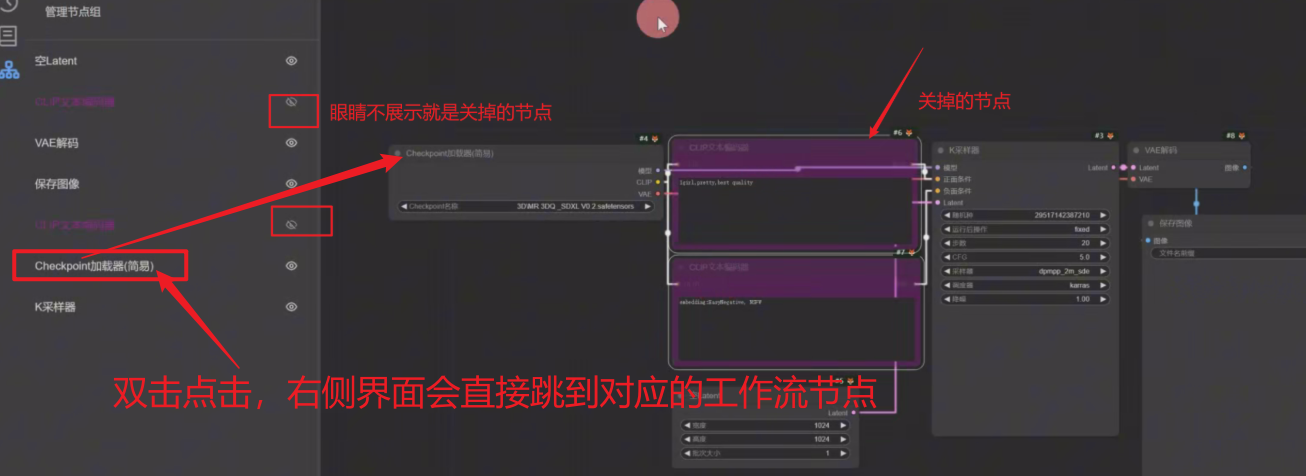
11、节点重新连接
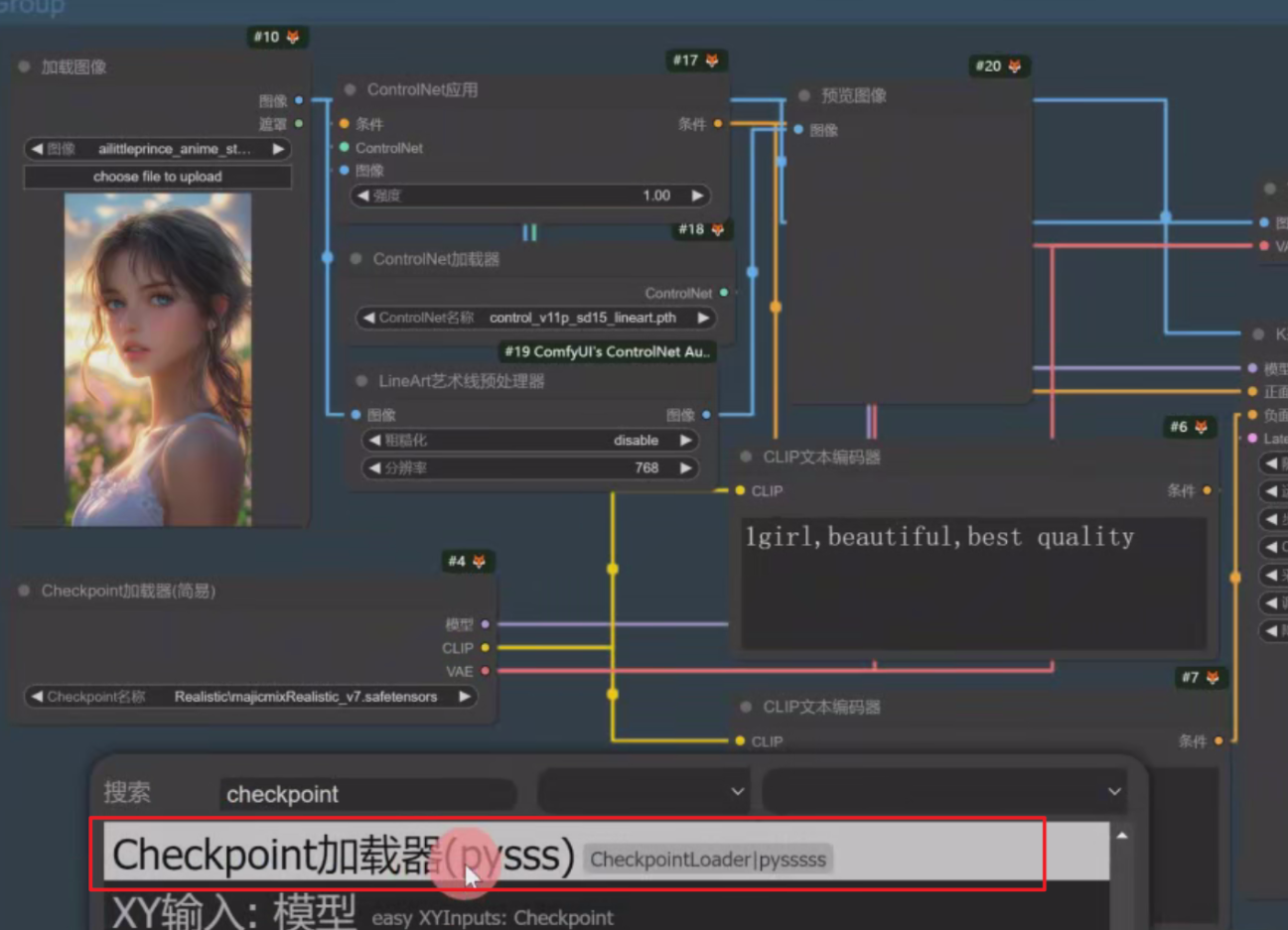
想让所有工作流里的节点模型都改成pysss加载器
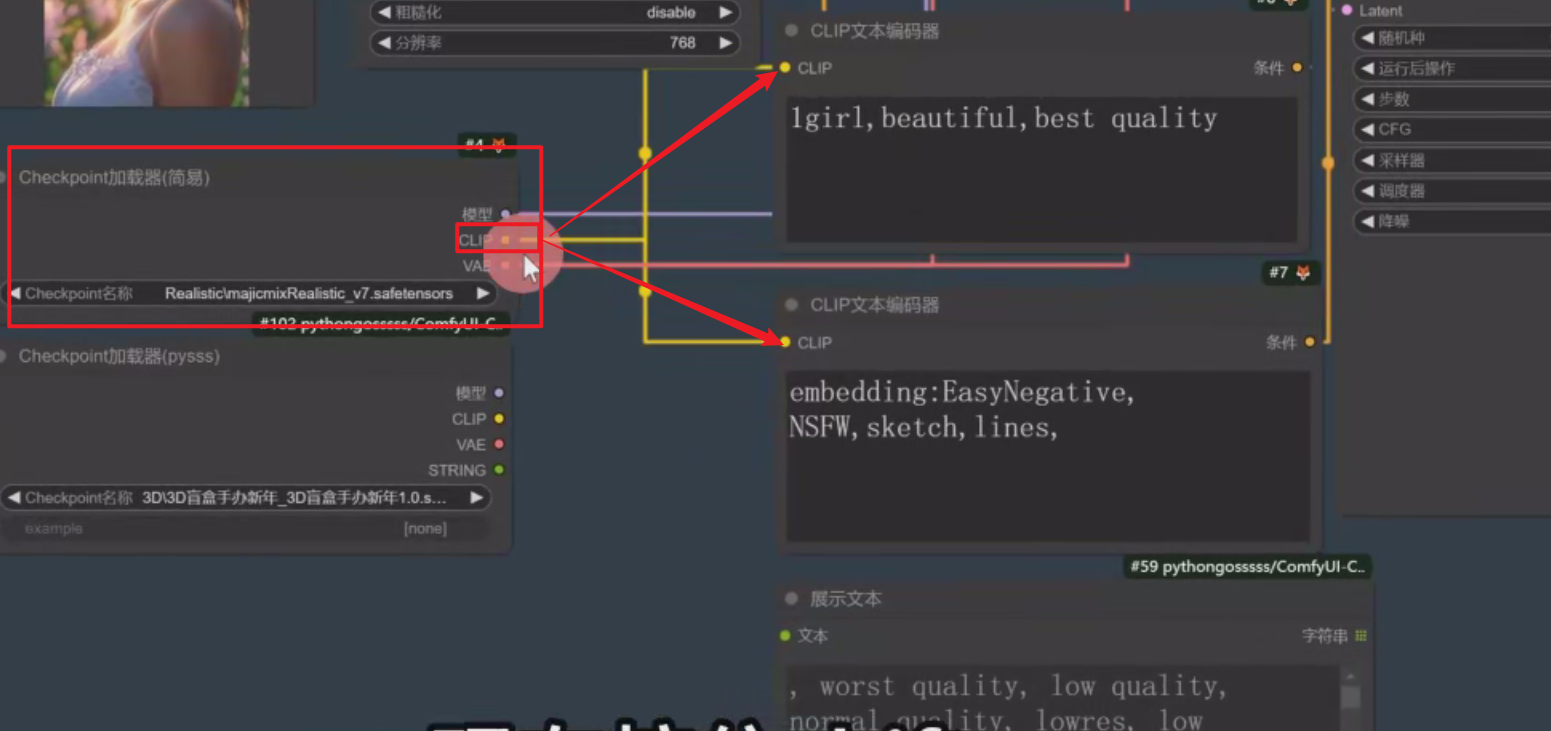
之前要一个一个到CLIP。现在按住shift,还有原来它的节点,把它直接拉过来,这样子原本在checkpoint加载器(简易)里的节点就直接同步过来了,并且会自动把之前的给删掉
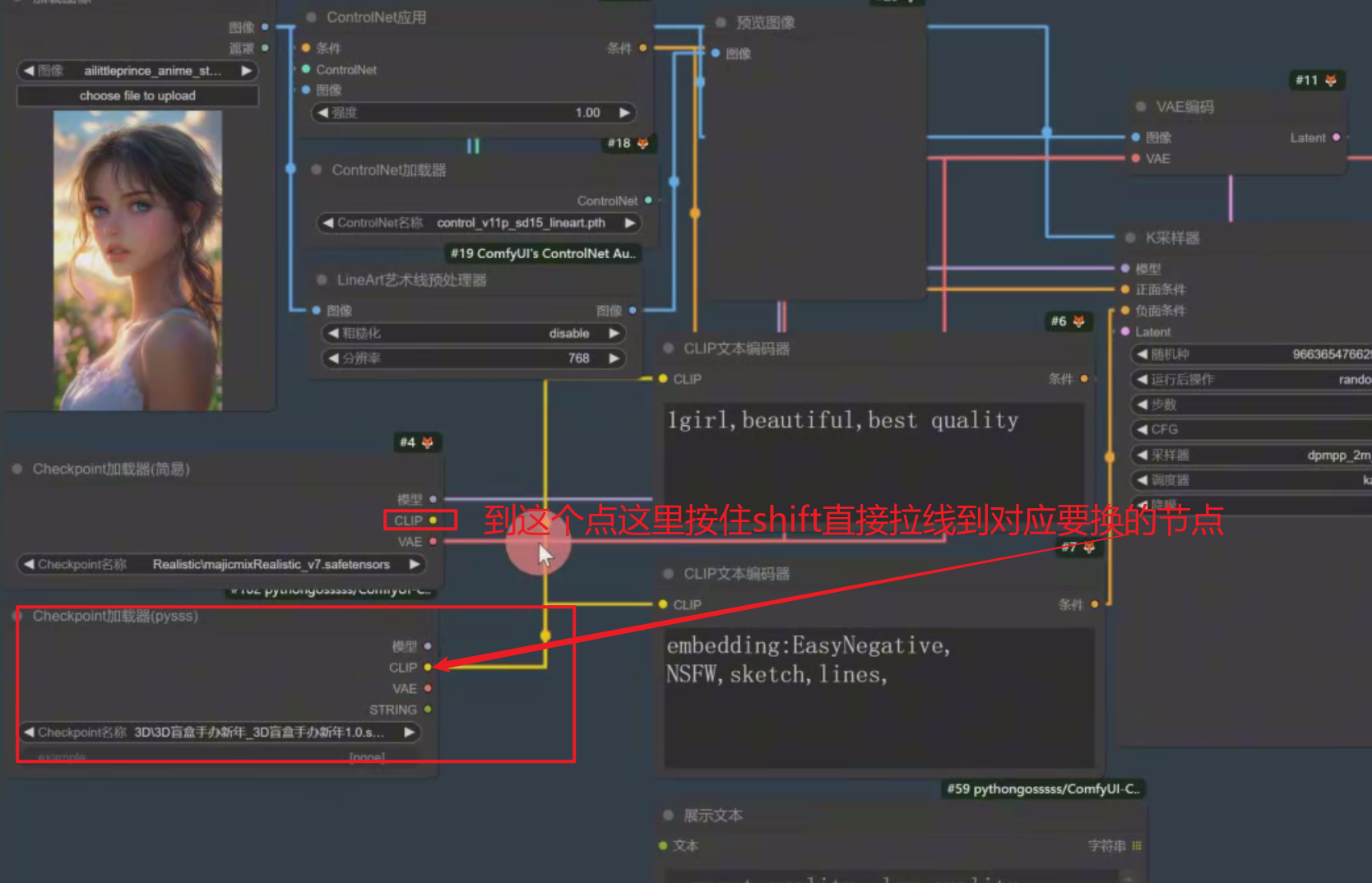
12、节点线优化
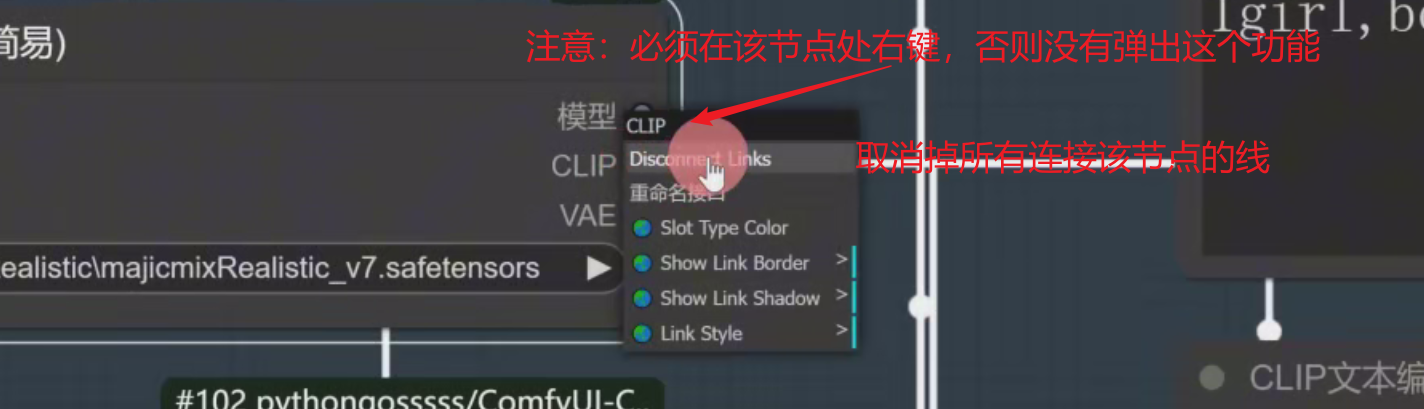
注意:必须在该节点处右键,否则没有弹出相应的功能
Disconnect Links:取消掉所有连接该节点的线
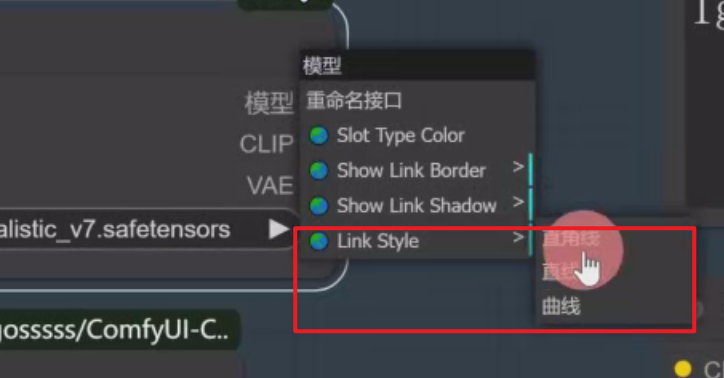
还可以直接选择Link Style,可以将连线改成直角线、直线、曲线
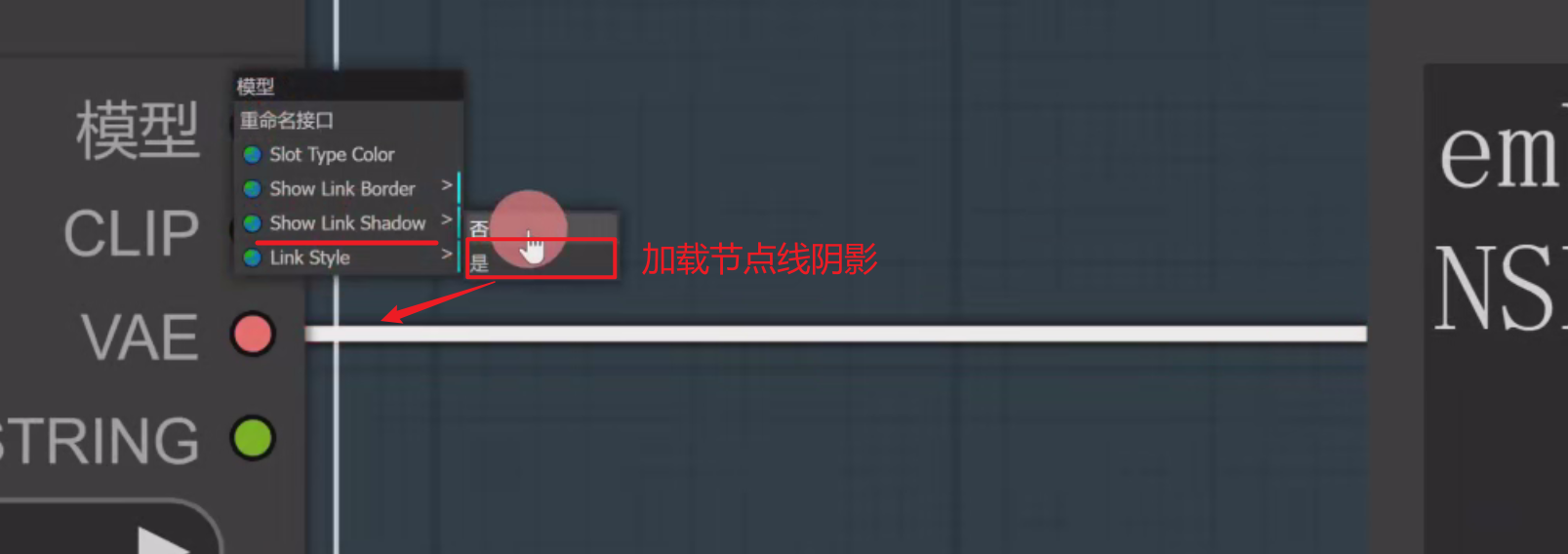
Show Link Shadow展示节点的阴影,可以把shadow显示出来,这样子更有3d化的效果
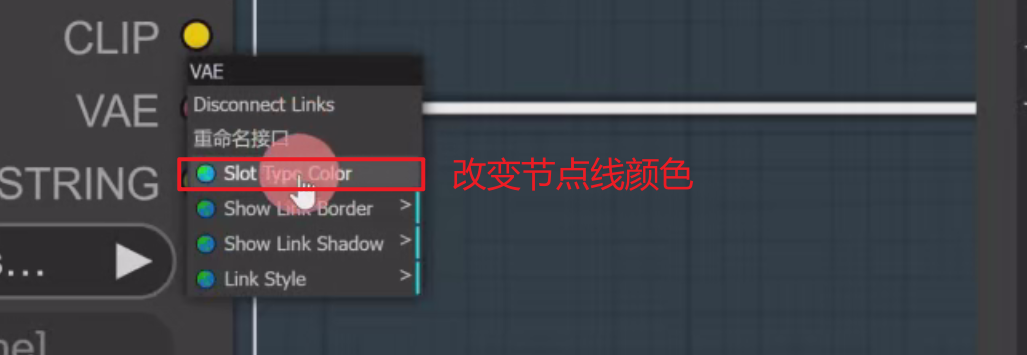
Slow Type Color:改变节点线的颜色
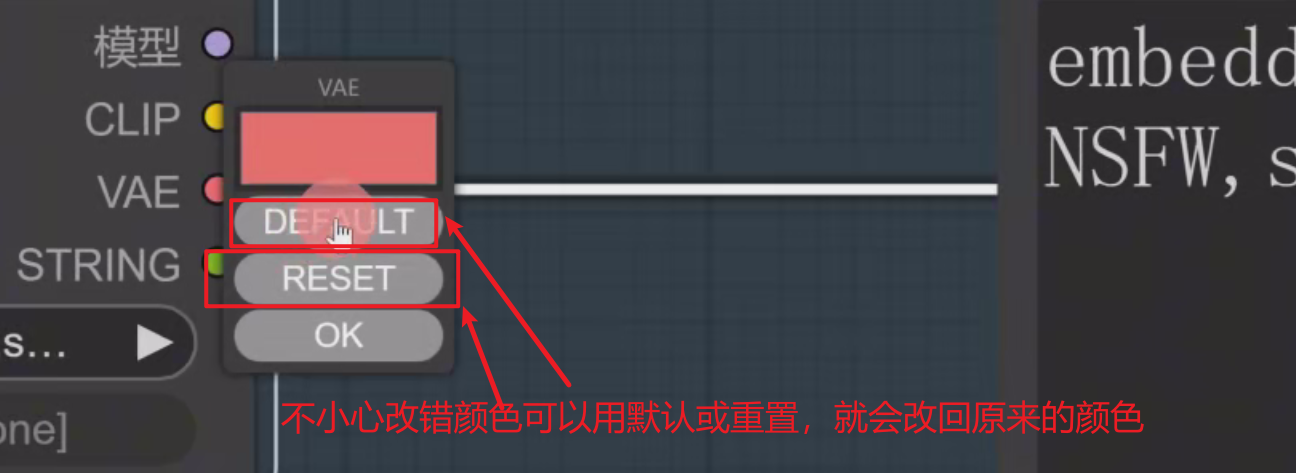
 DEFAULT或者RESET:默认或重置节点线颜色
DEFAULT或者RESET:默认或重置节点线颜色
show link border:将节点线变得更粗

结束!
如有问题,欢迎评论区留言📩📩,喜欢的可以收藏+关注🐳🐳,后续我有其他想法会持续更新!✌️✌️🥰🥰