5.15 学习日志
1.SST(总平方和)、SSR(回归平方和)、SSE(残差平方和)之间的关系。

在使用线性回归模型时,经常提到的统计量MSE(Mean Squared Error、均方误差):是 SSE 的平均值,也就是每个样本的平均误差平方。
R²(R square、决定系数) 是衡量回归模型预测效果的一个统计量,反映的是 模型解释了因变量变化的比例。
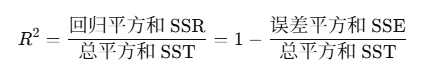
-------------------------------------------------------------------------------------------------------------------------------
2.python中和统计相关的库。
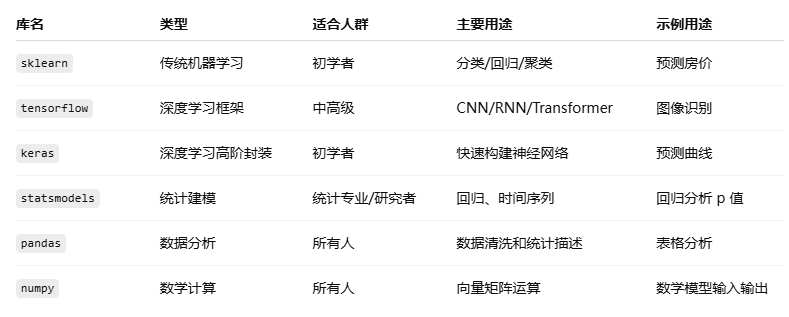 (1)sklearn是比较初级的用于传统机器学习的库,常见的用法包括下面的线性回归模型:
(1)sklearn是比较初级的用于传统机器学习的库,常见的用法包括下面的线性回归模型:
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error# 输入数据
x = [[1], [2], [3], [4]]
y = [2, 4, 6, 8]model = LinearRegression()
model.fit(x, y)
pred = model.predict([[5]])
print("预测结果:", pred)
还有以下其他的回归模型:
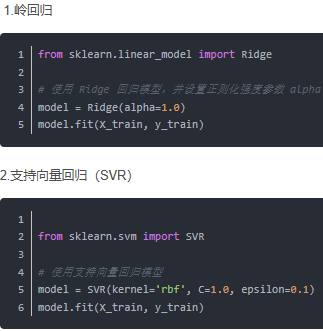
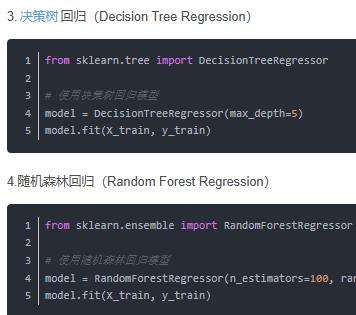
sklearn的代码套路为:用from--import从sklearn库里面导出相应统计模型,然后把这个模型设置给model,也就是令model=****,****为sklearn导入出来的,可以加上适当参数,然后把这个模型和数据进行fit,然后模型就跑好了,可以拿这个模型进行之后的操作,比如预测(predict)什么的。
(2) tensorflow和keras是常用的深度学习要用到的库,Keras 是 TensorFlow 的高层 API,Keras 是为人设计的,TensorFlow 是为机器设计的,那我们就先研究keras。
比如我之前学习的lstm模型,就是用的keras,比如下面:
from keras.models import Sequential
from keras.layers import Dense, SimpleRNN # 引入层相关,输出层与 RNN 层model = Sequential() # 创建实例
model.add(SimpleRNN(units=5, input_shape=(time_step, 1), activation='relu')) # RNN 层
model.add(Dense(units=1, activation='linear')) # 输出层,回归任务直接使用 linear 激活函数
model.compile(optimizer='adam', loss='mean_squared_error') # 回归使用mse评测
model.summary() keras.models 是 Keras 中用于构建模型的模块,里面主要包括:

Sequential 是 Keras 中最常用的模型类型,适合像积木一样一层接一层地堆叠。
keras.layers 是神经网络的构建模块库,里面包含了各种层(Layer)类型,如:
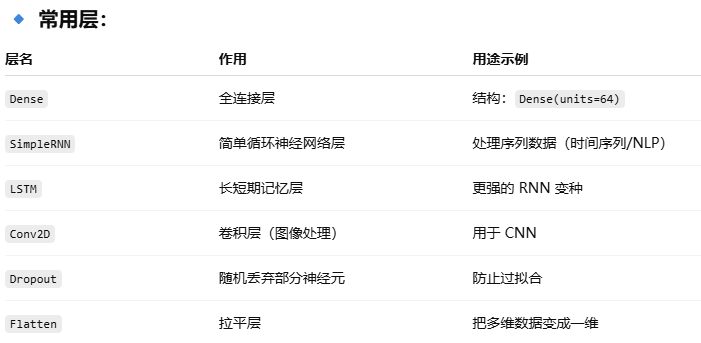
keras的代码套路为用from--import加载出keras的models和layers,models用于构建模型,layers则是一些常用层。
先用keras从models导出的模型令为model,然后再在model上加上layers的层,相当于比sklearn多了一个加层的概念。
就像上面的代码一样,模型的结构为:输入 -> SimpleRNN层 -> Dense层 -> 输出。
这里还要多一步用compile编译模型,编译好就可以像sklearn一样带入数据进行fit了。
然后把fit好的模型拿去之后的操作,比如predict。

(3)statsmodels 是一个用于统计建模、推断和数据探索的 Python 库。它提供了大量的统计模型和检验工具,强调的是:
-
模型的可解释性(输出 p 值、置信区间等)
-
统计检验完整性(如 F 检验、t 检验、DW 检验等)
-
拟合结果的详细描述(如 R²、调整 R²、AIC、BIC)
以下是statmodels的常见用法
import statsmodels.api as sm
import numpy as np# 输入数据
x = np.array([1, 2, 3, 4, 5])
y = np.array([2, 4, 5, 4, 5])# 添加常数项(截距)
x = sm.add_constant(x)# 拟合 OLS(普通最小二乘)模型
model = sm.OLS(y, x).fit()# 输出结果摘要
print(model.summary())# 其中model = sm.OLS(y, x).fit()可以看成:# ols_model = sm.OLS(y, x)
# 创建模型对象(未训练),我要用这些 x 去拟合这些 y,用 OLS(最小二乘法)做线性回归。# model = ols_model.fit() # 用样本数据拟合参数(训练模型)这里sm.add_constant()提醒这个模型要提供截距项。
statsmodels适用于统计分析与回归建模,优点是精细统计结果、适合科研,缺点是不适合复杂深度模型。
值得注意的是,statsmodels的普通最小二乘模型和sklearn的线性回归模型作用一样,也就是说sklearn的线性回归也是用的最小二乘法,得到的模型一致,statsmodels会提供更多有用的统计量。
还有一点值得注意,区别于sklearn的model.fit(x,y)把数据放在fit()里面,即sklearn 的风格是先创建模型(不带数据),然后调用 .fit(X, y) 训练
statsmodels 的风格是:在创建模型那一刻就把数据给进去,.fit() 只负责参数求解。
(4)numpy和pandas更像是为了前面三个库,为更高级的统计建模或者机器学习提供数据准备,可以用来预处理数据,得到整理好的数据,用于之后的操作。
------------------------------------------------------------------------------------------------------------------------------
3.cnn、rnn、lstm的区别和联系
CNN(Convolutional Neural Network,卷积神经网络):适用于图像、语音识别、视频、局部模式识别(也可用于文本)
RNN(Recurrent Neural Network,循环神经网络):适用于序列数据(时间序列、语音、文本、传感器数据等),当前的输出不仅取决于当前输入,还依赖于上一个时间点的状态,容易“遗忘”较远的信息(梯度消失),不适合很长的序列。
LSTM(Long Short-Term Memory,长短期记忆网络):适用于长序列学习任务(如自然语言处理、语音识别、股价预测等),RNN 的改进版本,引入“门结构(gate)”来控制记忆的保留和遗忘。
RNN比普通的单层结构(由x到y)多出一个h(hidden state隐状态)。
LSTM 通过引入细胞状态和门控机制(遗忘门、输入门和输出门),实现了信息的线性传递,避免了多次非线性激活导致的梯度消失。
-----------------------------------------------------------------------------------------------------------------------
4.假设检验
假设检验是一种统计方法,用于根据样本数据判断一个假设是否成立。其流程包括:提出原假设(H₀)和备择假设(H₁)、设定显著性水平(α),然后通过样本数据计算统计量和p值。如果p值小于α,则拒绝原假设,认为存在显著差异;否则接受原假设。
常见的检验类型有Z检验、t检验、卡方检验等。假设检验广泛用于验证两组数据是否有显著差异,帮助做出基于数据的推断。
主要步骤
提出假设:确定原假设(H₀)和备择假设(H₁),如“没有差异”和“有差异”。
设定显著性水平(α):通常设定为0.05或0.01,表示可容忍的最大错误概率。
计算检验统计量:通过样本数据计算统计量(如t值、z值)并得到p值。
作出决策:若p值小于设定的α,拒绝原假设,认为数据有显著差异;否则,接受原假设。
这体现出“疑罪从无“原则,除非你有显著的原因(统计量小于显著性水平)证明被告有罪(接受备择假设),不然就认定被告无罪(接受原假设)。
5.自然语言处理(NLP, Natural Language Processing)
NLP自然语言处理是让计算机读懂人类语言、并做出有用反应的技术,核心包括文本理解 + 信息提取 + 智能决策。
-----------------------------------------------------------------------------------------------------------------------
6 .爬虫
爬虫(Web Crawler 或 Spider)是一种自动化程序,用来模拟人访问网页并获取网页数据,比如文本、图片、视频、表格等。
URL(Universal Resource Locator)统一资源定位符
HTTP(Hypertext Transfer Protocol)超文本传输协议
网页通常由三部分组成(HTML骨架、CSS皮肤、JavaScript肌肉)
cookie(客户端)、session(服务器端)。
代理服务器和VPN

区分被墙网站和境外网站,境外网站不一定被墙,举例介绍:
 下面是我用的梯子clash的介绍,一般有三个模式:
下面是我用的梯子clash的介绍,一般有三个模式:

最常用的还是规则模式,作用和原理如下:

对于境外网站和被墙网站,还有一点说法,也就是“规则代理”的原理:
