大模型之RAG知识库
当我们将大模型应用于实际业务场景时会发现,通用的基础大模型基本无法满足实际业务需求,主要有以下几方面原因:
- 知识的局限性:模型自身的知识完全源于它的训练数据,而现有的主流大模型(deepseek、文心一言、通义千问…)的训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或离线的数据是无法获取到的。
- 幻觉问题:所有的AI模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它经常会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。
- 数据安全性:对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。
RAG的四个核心工作流程?
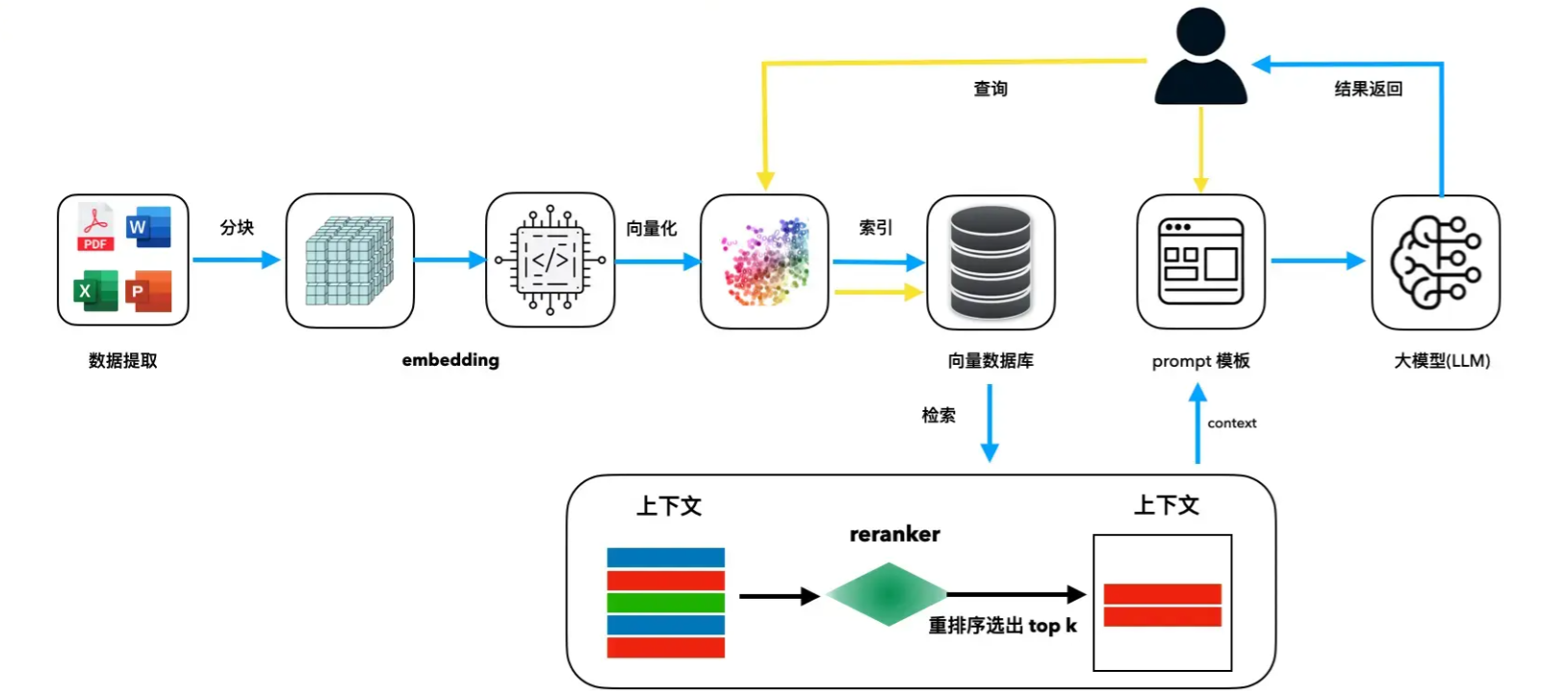
- 索引化(Indexing) :将原始数据清洗、分块并编码为向量,存储在向量数据库(如Faiss、Milvus)中,形成可检索的知识库。
- 检索(Retrieval):混合检索(向量+关键词)、元数据增强、子查询优化。
- 后检索重排(Reranking):将检索后的关联文本,及前置信息进行筛选、过滤、重排。
- 生成(Generation):结合检索结果与LLM生成答案,引用来源提高可信度。
如何更好分块?
Transformer模型具有固定的输入序列长度,即使输入上下文窗口很大,一个或几个句子的向量也比几页文本的平均向量更好地表示其语义,因此需要对数据进行分块。分块将初始文档分割成一定大小的块,尽量不要失去语义含义,将文本分割成句子或段落,而不是将单个句子分成两部分。有多种文本分割器实现能够完成此任务。
块的大小是一个需要考虑的重要参数-它取决于您使用的嵌入模型及其令牌容量,标准转换器编码器模型(例如基于BERT的句子转换器)最多需要512个令牌。OpenAI ada-002能够处理更长的序列,如8191个标记,但这里就需要权衡是留有足够的上下文供大语言模型进行推理,还是留足够具体的文本表征以便有效地执行检索。
例如,在语义搜索中,我们对文档语料库进行索引,每个文档都包含有关特定主题的有价值的信息。通过应用有效的分块策略,我们可以确保我们的搜索结果准确地捕捉用户查询的本质。如果我们的块太小或太大,可能会导致搜索结果不精确或错过显示相关内容的机会。根据经验,如果文本块在没有周围上下文的情况下对人类有意义,那么它对语言模型也有意义。因此,找到语料库中文档的最佳块大小对于确保搜索结果的准确性和相关性至关重要
如果常见的分块方法(例如固定分块)无法轻松应用于用例,那么这里有一些提示可以帮助您找到最佳的分块大小。
预处理数据:在确定应用程序的最佳块大小之前,您需要首先预处理数据以确保质量。例如,如果您的数据是从网络检索的,您可能需要删除HTML标签或只会增加噪音的特定元素。
选择块大小范围:数据经过预处理后,下一步是选择要测试的潜在块大小范围。如前所述,选择应考虑内容的性质(例如,短消息或冗长的文档)、您将使用的嵌入模型及其功能(例如,令牌限制)。目标是在保留上下文和保持准确性之间找到平衡。首先探索各种块大小,包括用于捕获更精细语义信息的较小块(例如,128或256个标记)和用于保留更多上下文的较大块(例如,512或1024个标记)。
评估每个块大小的性能:为了测试各种块大小,您可以使用多个索引或具有多个命名空间的单个索引。使用代表性数据集,为要测试的块大小创建嵌入并将它们保存在索引中。然后,您可以运行一系列查询,可以评估其质量,并比较不同块大小的性能。这很可能是一个迭代过程,您可以针对不同的查询测试不同的块大小,直到可以确定内容和预期查询的最佳性能块大小
Embedding干什么?
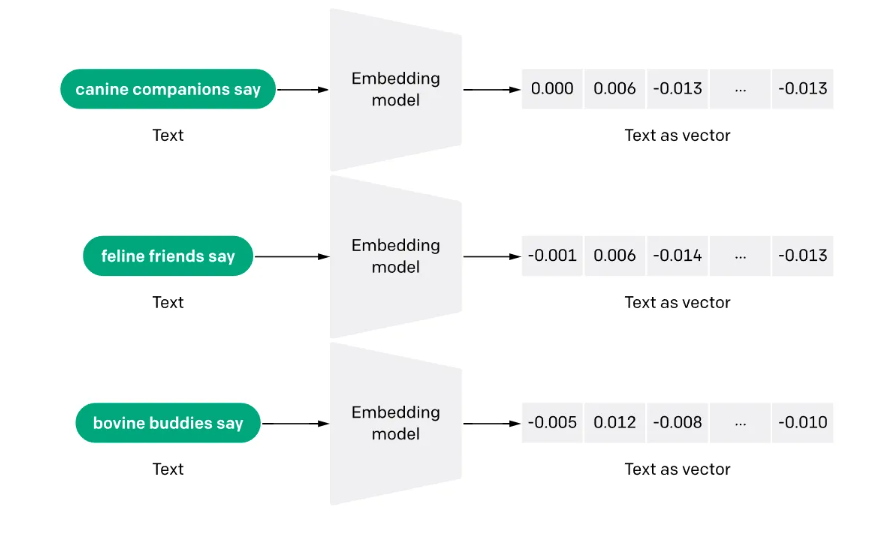
Embedding 是一种将文字序列(如词、句子或文档)转换为向量表示(固定维度的向量)的技术
模型目标:使得具有相似语义的文字序列对应的向量尽可能接近(即相似度高),而语义不同的文字序列对应的向量尽可能远离(即相似度低)
作用:通过数学计算向量之间的距离,快速检索出相似度最高的文字序列。
如何索引?
- 分块策略(Chunking Strategy):将文档分割成固定数量的标记(例如 100、256、512 个 tokens)的块(chunks)
- 元附加数据(Metadata Attachments):给文本块附加元数据信息,如页码、文件名、作者、类别时间戳,以及段落摘要、潜在问题等,以便基于这些元数据过滤检索,限制检索范围
- 结构化索引(Structural Index):建立文档的层次结构或图结构,如对文本分块后建立文本块间的父子关系,或者以文本单元(段落、表格、页等)为节点、以语义/文本相似度为边来构建文档的图谱
检索阶段如果优化?
检索阶段是RAG的基石,直接影响生成结果的质量。优化方向包括:
1. 检索器(Retriever)的增强
- 混合检索策略:结合关键词检索(如BM25)和稠密向量检索(如DPR、Sentence-BERT),利用两者的互补性。例如,BM25擅长精确匹配关键词,向量检索擅长语义相似性。
- 重排序(Re-ranking):对检索结果进行二次排序,使用更精细的模型(如Cross-Encoder、ColBERT)计算相关性得分,提升Top-K结果的精度。
- 多模态检索:扩展检索内容到图像、表格等多模态数据,例如用CLIP模型对齐文本和图像的嵌入空间。
2. 数据预处理优化
- 分块策略:根据数据类型调整文本分块(Chunking)策略:
- 固定长度分块:适用于通用场景,但可能切断语义。
- 动态分块:基于语义边界(如段落、标题)分割,或使用NLP模型(如Spacy)识别句子边界。
- 重叠分块:相邻块间添加重叠部分(如10%长度),避免信息截断。
- 元数据增强:为每个数据块附加元数据(如来源、时间、实体),检索时通过元数据过滤无关内容。
- 数据清洗:去除噪声(如HTML标签、重复文本)、规范化(小写化、拼写校正)、实体识别(链接到知识库)。
3. 向量嵌入(Embedding)优化
- 领域适配微调:在领域数据上微调预训练嵌入模型(如BERT、RoBERTa),提升语义表示能力。
- 多向量编码:对长文档生成多个向量(如按段落),检索时综合多个向量得分。
- 量化与压缩:使用PQ(Product Quantization)或二进制编码减少向量存储和计算开销。
4. 检索后处理
- 去重与聚合:合并相似或重复的检索结果,避免冗余信息干扰生成。
- 假设性文档嵌入(HyDE):让LLM生成一个“假设答案”,用其向量检索真实文档,提升对模糊查询的鲁棒性。
生成阶段如何优化?
生成阶段需确保结果与检索内容一致且符合用户需求:
1. 提示工程(Prompt Engineering)
结构化指令:明确要求生成内容基于检索结果,例如:
- 少样本学习(Few-shot):在提示中加入示例,引导模型模仿格式和逻辑。
- 链式思考(Chain-of-Thought):要求模型先输出推理过程,再生成最终答案,提升可解释性。
2. 生成模型优化
- 领域微调:在领域数据上微调生成模型(如GPT-3、Llama 2),使其更适应特定术语和风格。
- 约束生成:通过前缀树(Trie)限制输出词汇,或使用API强制引用检索结果中的实体。
- 多步生成:先生成草稿,再基于检索内容进行修订,或分解复杂问题为子问题逐步回答。
3. 后处理与验证
- 事实性校验:对比生成结果与检索内容,通过NLI(自然语言推理)模型检测矛盾。
- 引用溯源:自动标注生成内容对应的检索文档片段,方便用户验证。
- 毒性过滤:使用分类模型过滤生成内容中的有害信息。
如何提升RAG的效率和可扩展性?
1. 缓存与索引
- 结果缓存:缓存高频查询的检索和生成结果,减少重复计算。
- 增量索引:对新数据实时更新索引,避免全量重建。
2. 异步流水线
- 并行化检索与生成:在生成模型处理当前结果时,预加载下一组检索内容。
- 分布式架构:将检索器与生成器部署为独立服务,通过负载均衡应对高并发。
3. 延迟与资源权衡
- 分级检索:先快速返回粗粒度结果,再异步补充细节。
- 模型蒸馏:用蒸馏后的轻量模型(如TinyBERT)替代原始大模型,降低计算成本。