使用Langfuse和RAGAS,搭建高可靠RAG应用
大家好,在人工智能领域,RAG系统融合了检索方法与生成式AI模型,相比纯大语言模型,提升了准确性、减少幻觉且更具可审计性。不过,在实际应用中,当建好RAG系统投入使用时,如何判断接收信息是否正确、模型回复是否与输入一致,又该怎么衡量和优化系统性能,答案是可观测性。
本文将介绍如何搭建整合Langfuse可观测性与RAGAS评估指标的RAG系统,前者用于监控系统各阶段,后者能衡量回复质量。通过二者结合,打造可不断评估优化的RAG系统。后续会解析各组件、说明其作用并给出整合代码 。
1.RAG
RAG系统主要包含四个组件,各组件依次协同工作,共同实现系统功能。
在“文档处理”阶段,原始文档会被转化为可处理、可索引的格式,为后续流程奠定基础。接着进入“分块和索引”阶段,文档被分割成较小片段,借助向量嵌入技术创建可搜索索引,方便快速定位相关信息。
随后的“检索”阶段,系统依据用户查询,从索引中精准找到最匹配的文档片段。最后在“生成”阶段,系统将检索到的信息与原始查询融合,进而生成全面且准确的答案。
2.Langfuse
Langfuse是一个专为大语言模型应用程序设计的开源可观测性平台,提供了以下详细的可见性:
-
追踪:贯穿整个堆栈的完整请求生命周期
-
指标:性能、成本和质量指标
-
评估:自动评估回复质量
-
实验跟踪:不同配置的A/B测试
对于我们的RAG系统,Langfuse能帮助监控从文档处理到最终回复生成的所有过程,提供持续改进系统所需的见解。
3.RAGAS
RAGAS(检索增强生成评估)是专为评估RAG系统输出而设计的开源框架。
RAGAS评估RAG系统的两个主要方面:检索质量和生成质量。在我们的实现中,会特别使用两个重要指标:
-
忠实度:该指标衡量生成的答案与检索到的文档中的信息的忠实程度。高忠实度分数表明模型是根据我们手头的资源提供答案,而不是凭空捏造。
-
答案相关性:该指标评估生成的答案对用户原始查询的回应程度。高相关性分数表明答案与问题直接相关,满足了用户的信息需求。
通过这些指标,可以定量评估RAG系统的性能,并随着时间的推移进行改进。将RAGAS指标与Langfuse可观测性相结合,我们可以全面了解系统的工作原理和工作效果。
4.实践项目
首先下载使用的库:
pip install langchain langchain_openai faiss-cpu ragas pypdf langfuse
然后进行必要的导入:
import os
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy
from langfuse import Langfuse
from langchain_openai import OpenAIEmbeddings
from langchain_openai import OpenAI as OpenAILLM
from dotenv import load_dotenvload_dotenv()
在编写代码之前,创建Langfuse账户并获取API密钥。为此,需要在https://langfuse.com/上注册,创建一个项目,并获取公钥和私钥。可以在“设置”部分查看API密钥。
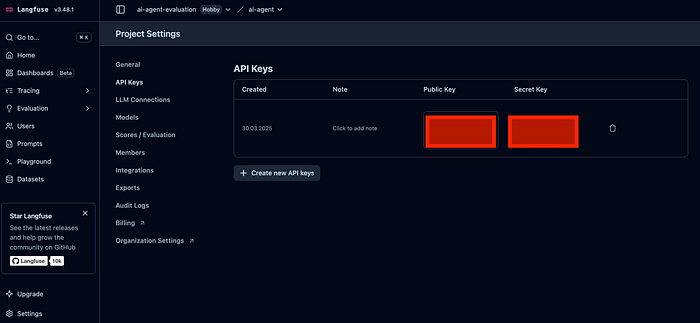
然后创建一个.env文件,在其中加载这些信息,并创建Langfuse对象。
# 直接初始化Langfuse
langfuse = Langfuse(public_key=os.environ.get("LANGFUSE_PUBLIC_KEY"),secret_key=os.environ.get("LANGFUSE_SECRET_KEY"),host=os.environ.get("LANGFUSE_HOST", "https://cloud.langfuse.com")
)# 根据需要设置LangChain追踪
os.environ["LANGCHAIN_TRACING_V2"] = "true"
现在开始创建RAG系统来测试监控和评估系统。
# 加载你的PDF文件
print("Loading PDF...")
loader = PyPDFLoader("data/documents/mamba model.pdf")
pages = loader.load()# 为整个过程创建一个追踪
main_trace = langfuse.trace(name="rag_pdf_process",user_id="user-001",metadata={"file": "mamba model.pdf"}
)
首先,加载PDF文档,并创建主Langfuse追踪来跟踪整个过程。
document_splitting = main_trace.span(name="document_splitting",input={"page_count": len(pages)}
)splitter = CharacterTextSplitter(chunk_size=200,chunk_overlap=20
)chunks = splitter.split_documents(pages)document_splitting.update(output={"chunk_count": len(chunks)}
)document_splitting.end()
分块步骤中,在Langfuse中启动一个跨度来监控这个特定操作。首先记录输入,即要处理的页面数量。分块过程完成后,用输出(即创建的块数)更新跨度。最后,显式结束跨度,以捕获和记录整个分块过程的持续时间。
vectorization = main_trace.span(name="vectorization",input={"chunk_count": len(chunks)}
)embedding = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embedding)
retriever = vectorstore.as_retriever(search_kwargs={"k": 3}
)vectorization.end()
同样,在向量化步骤中,创建一个跨度来跟踪这个操作。首先记录过程中涉及的相关输入。接下来,生成嵌入并构建向量存储。最后,结束跨度,以捕获整个向量化步骤的时间信息。
在准备好文档块并创建向量存储后,下一个关键步骤是设置将处理用户查询的问答链。这段代码设置了语言模型,并配置了与检索系统的交互方式:
# 构建RAG链
chain_setup = main_trace.span(name="chain_setup")llm = OpenAILLM(model_name="gpt-4o",max_tokens=256,temperature=0
)qa = RetrievalQA.from_chain_type(llm=llm,chain_type="stuff",retriever=retriever,return_source_documents=True
)chain_setup.end()
创建名为“chain_setup”的跨度,以便在Langfuse中进行追踪。然后指定要使用的模型。最后,使用langchain结构创建一个RAG链。提出一个问题:
query = "What are the main topics covered in the PDF?"
RAG系统最重要的组件是以下处理用户查询并生成回复的函数。
def ask_with_langfuse(query, trace):query_generation = trace.generation(name="query_execution",model="gpt-4o",model_parameters={"max_tokens": 256},input={"query": query})try:# 执行查询result = qa({"query": query})# 提取源文档,以便以可序列化的格式进行日志记录source_docs = []for doc in result["source_documents"][:2]:# 确保元数据是可序列化的metadata = {}for key, value in doc.metadata.items():if isinstance(value, (str, int, float, bool, list, dict)) or value isNone:metadata[key] = valuesource_docs.append({"content": doc.page_content,"metadata": metadata})# 用结果更新生成的内容query_generation.end(output={"answer": result["result"]},metadata={"source_count": len(result["source_documents"])})return resultexcept Exception as e:# 记录任何错误query_generation.end(error={"message": str(e), "type": type(e).__name__})trace.update(status="error")raise e
这个函数与Langfuse集成工作,并记录每个步骤发生的事情。当函数开始工作时,它首先在Langfuse中创建一个监控点。这个监控点记录技术细节,如使用的模型、最大令牌数和用户的原始查询。
然后,它使用我们之前设置的问答链处理用户的查询。在此过程中,从向量数据库中提取相关的文档片段,并将这些信息传输到语言模型以生成回复。系统接收生成的回复和用于创建此回复的源文档。
源文档可能无法直接保存到Langfuse中,因为包含复杂的数据结构。因此,该函数将文档转换为Langfuse可以处理的简单格式。当成功生成回复时,回复本身以及使用的源文档数量等信息都会保存在Langfuse中。
如果在过程中发生任何错误,该函数也会在Langfuse中记录此错误。这有助于稍后检测和解决问题。通过这种方式,可以确切地看到系统每次运行时的状况,评估其性能,并进行必要的改进。
在设置好系统并定义了查询函数后,进入运行系统并评估其性能的阶段。在下面的代码块中,可以看到使用RAGAS进行查询处理和评估的过程:
# 运行查询
print("Running query...")
response = ask_with_langfuse(query, main_trace)
print("Answer:", response["result"])# 🧪 使用RAGAS进行评估
print("Evaluating with RAGAS...")
eval_span = main_trace.span(name="ragas_evaluation")contexts = [doc.page_content for doc in response["source_documents"][:2]]
# 创建与RAGAS兼容的数据集
eval_dataset = Dataset.from_dict({"question": [query],"answer": [response["result"]],"contexts": [contexts],"ground_truth": ["Summary of main PDF topics"]
})
在本节中,首先通过调用之前定义的ask_with_langfuse函数来处理查询。这个函数从向量数据库中检索相关文档,生成回复,并在Langfuse中记录整个过程。生成回复后,将其显示在控制台中。
然后,为RAGAS评估做准备。在Langfuse中启动名为“ragas_evaluation”的新监控间隔。为了进行评估,我们取出生成回复时使用的前两个文档片段,并创建一个RAGAS数据集。这个数据集包含四个基本元素:查询、生成的回复、使用的上下文(文档片段)和参考回复(真实答案)。
# 运行评估
try:result = evaluate(eval_dataset,metrics=[faithfulness, answer_relevancy])# 将评估结果转换为简单格式metrics = {}# 根据结果对象的字符串表示处理结果对象result_str = str(result)print("RAGAS result:", result_str)# 如果可能,尝试直接提取值try:# 首先尝试像字典一样访问metrics["faithfulness"] = float(result["faithfulness"])metrics["answer_relevancy"] = float(result["answer_relevancy"])except (TypeError, KeyError):# 如果失败,尝试解析字符串表示import refaithfulness_match = re.search(r"faithfulness[^\d]+([\d\.]+)", result_str)relevancy_match = re.search(r"answer_relevancy[^\d]+([\d\.]+)", result_str)if faithfulness_match:metrics["faithfulness"] = float(faithfulness_match.group(1))if relevancy_match:metrics["answer_relevancy"] = float(relevancy_match.group(1))# 用指标更新评估跨度eval_span.update(output={"metrics": metrics})print("Evaluation metrics:", metrics)
except Exception as e:print(f"RAGAS evaluation error: {e}")eval_span.update(error={"message": str(e), "type": type(e).__name__})
在评估代码中,使用RAGAS的evaluate函数评估数据集中的回复。使用两个重要指标:忠实度和答案相关性。这些指标衡量回复的准确性和相关性。
由于RAGAS结果对象在不同版本中可能有不同的结构,尝试几种不同的方法来获取指标。首先,尝试将结果对象当作字典使用。如果失败,尝试使用正则表达式从结果的文本表示中提取值。这种方法使我们能够在不同版本的RAGAS中工作。
在Langfuse的评估追踪中更新结果指标。如果发生任何错误,也会在Langfuse中记录错误。
eval_span.end()
# 结束主追踪
main_trace.update(status="success")
print("RAG process completed and logged to Langfuse")
最后,关闭评估追踪,并将主Langfuse追踪标记为成功。这表明整个RAG流程已成功完成并记录在Langfuse中。
试用一下这个系统,提出以下问题:
query = "What are the main topics covered in the PDF?"
Langfuse主页看起来会像这样。因为问了两个问题,所以出现了2条追踪记录。
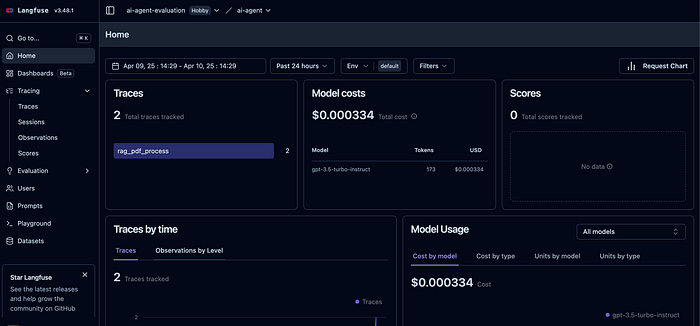
然后从左侧导航栏中选择“Traces”(追踪)。
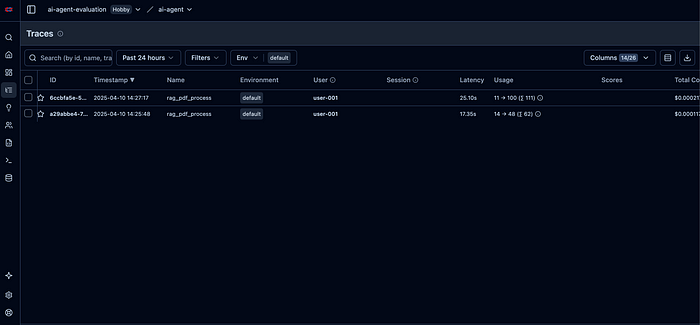
这个页面包含进行的所有事务的追踪记录。当点击其中任何一个时,会打开详细信息页面。
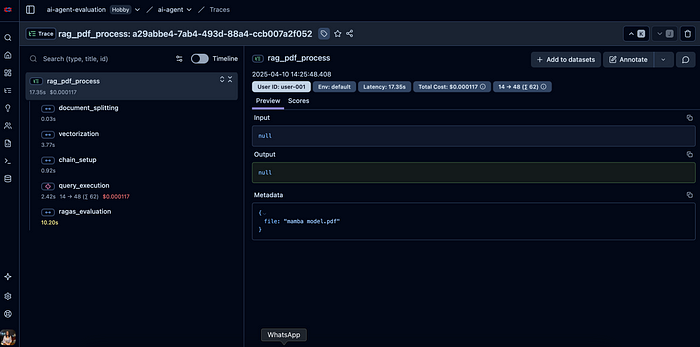
在这个页面上,左侧“rag_pdf_process”下有我们确定并创建了跨度的步骤。你还可以在右侧观察到“Total cost”(总成本)和“Latency”(延迟)等指标。当在左侧选择“query_execution”时,可以看到模型给出的答案。
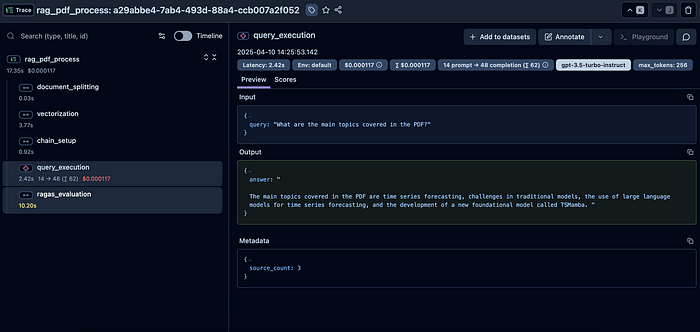
如果想查看RAGAS指标,也可以从“ragas_evaluation”部分进行查看。
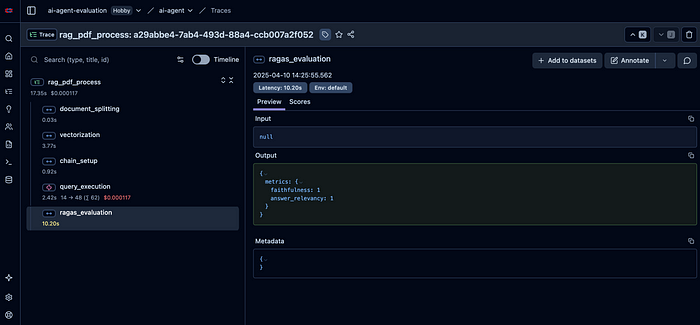
可以尝试使用不同的示例和问题来开发这个系统。