重排序模型解读:gte-multilingual-reranker-base 首个GTE系列重排模型诞生
模型介绍
gte-multilingual-reranker-base 模型是 GTE 模型系列中的第一个 reranker 模型,由阿里巴巴团队开发。
模型特征:
- Model Size: 306M
- Max Input Tokens: 8192
benchmark
关键属性:
- 高性能:与类似大小的 reranker 模型相比,在多语言检索任务和多任务表示模型评估中实现最先进的 (SOTA) 结果。
- 训练架构:使用仅编码器 transformers 架构进行训练,从而获得更小的模型尺寸。与以前基于仅解码 LLM 架构的模型(例如 gte-qwen2-1.5b-instruct)不同,该模型对推理的硬件要求较低,推理速度提高了 10 倍。
- 长上下文:支持高达 8192 个令牌的文本长度。
- 多语言功能:支持 70 多种语言。
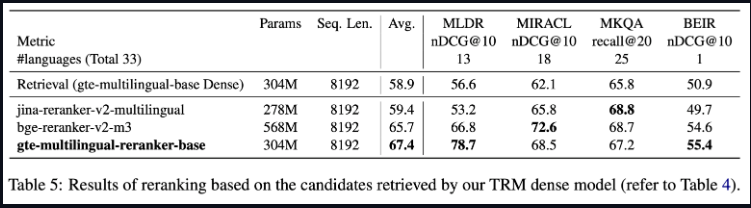
评价
还处于新出现的阶段,是新晋的GTE重排序模型,模型综合性能可以,商业化需要在生产/测试环境中实测过才好上生产。
huggingface:https://huggingface.co/Alibaba-NLP/gte-multilingual-reranker-base
paper:https://arxiv.org/pdf/2407.19669
建议安装 xformers 并启用 unpadding 来加速,参考enable-unpadding-and-xformers
地址:https://huggingface.co/Alibaba-NLP/new-impl#recommendation-enable-unpadding-and-acceleration-with-xformers
除了开源的GTE系列机型外,GTE系列机型在阿里云上也以商业API服务的形式提供。请注意,商业 API 背后的模型与开源模型并不完全相同。
用法示例
python 调用示例:
使用 Huggingface transformers (transformers>=4.36.0)
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizermodel_name_or_path = "Alibaba-NLP/gte-multilingual-reranker-base"tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, trust_remote_code=True,torch_dtype=torch.float16
)
model.eval()pairs = [["中国的首都在哪儿","北京"], ["what is the capital of China?", "北京"], ["how to implement quick sort in python?","Introduction of quick sort"]]
with torch.no_grad():inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)scores = model(**inputs, return_dict=True).logits.view(-1, ).float()print(scores)# tensor([1.2315, 0.5923, 0.3041])
云api地址:https://help.aliyun.com/zh/model-studio/text-rerank-api