学习笔记(C++篇)—— Day 6
1.内部类
如果一个类定义在另一个类的内部,就叫做内部类。
例如下面一个代码示例:
class A
{
private:static int _k;int _h = 1;
public:class B // B默认就是A的友元{public:void foo(const A& a){cout << _k << endl; //OKcout << a._h << endl; //OK}private:int _b;};
};代码运行结果为:
所以在这种类中,不计算类中类的大小。
①内部类是一个独立的类,跟定义在全局相比,他只是受外部类类域限制和访问限定符限制,所以外部类定义的对象中不包含内部类。
②内部类默认是外部类的友元类。
③内部类本质也是一种封装,当A类跟B类紧密关联,A类实现出来主要就是给B类使用,那么可以考虑把A类设计为B的内部类,如果放到private/protected位置,那么A类就是B类的专属内部类,其他地方都用不了。
2.匿名对象
例如以下示例:
class A
{
public:A(int a = 0):_a(a){cout << "A(int a)" << endl;}~A(){cout << "~A()" << endl;}
private:int _a;
};class Solution {
public:int Sum_Solution(int n) {//...return n;}
};
int main()
{A aa1;// 不能这么定义对象,因为编译器无法识别下面是一个函数声明,还是对象定义//A aa1();// 但是我们可以这么定义匿名对象,匿名对象的特点不用取名字,// 但是他的生命周期只有这一行,我们可以看到下一行他就会自动调用析构函数A();A(1);A aa2(2);// 匿名对象在这样场景下就很好用,当然还有一些其他使用场景,这个我们以后遇到了再说Solution().Sum_Solution(10);return 0;
}在这其中A() 和 A(1)都是匿名对象。
匿名对象可以引用,但和临时对象一样具有常性,不能直接给,需要使用const。但被引用了后,生命周期会变长。
3.对象拷贝时编译器优化
①现代编译器会为了尽可能提高程序的效率,在不影响正确性的情况下会尽可能减少一些传参和传返回值的过程中可以省略的拷贝。
②如何优化C++标准并没有严格规定,各个编译器会根据情况自行处理。当前主流的相对新一点的编译器对于连续一个表达式步骤中的连续拷贝会进行合并优化,有些更新更"激进"的编译器还会进行跨行跨表达式的合并优化。
class A
{
public:A(int a = 0):_a1(a){cout << "A(int a)" << endl;}A(const A& aa):_a1(aa._a1){cout << "A(const A& aa)" << endl;}A& operator=(const A& aa){cout << "A& operator=(const A& aa)" << endl;if (this != &aa){_a1 = aa._a1;}return *this;}~A(){cout << "~A()" << endl;}
private:int _a1 = 1;
};void f1(A aa)
{}
A f2()
{A aa;return aa;
}int main()
{//优化A aa1 = 1;cout << endl;//传值传参A aa1;f1(aa1);cout << endl;cout << "#################" << endl;// 传值返回// 返回时一个表达式中,连续拷贝构造+拷贝构造->优化一个拷贝构造 (vs2019 debug)// 一些编译器会优化得更厉害,进行跨行合并优化,直接变为构造。(vs2022 debug)f2();cout << endl;// 返回时一个表达式中,连续拷贝构造+拷贝构造->优化一个拷贝构造 (vs2019 debug)// 一些编译器会优化得更厉害,进行跨行合并优化,直接变为构造。(vs2022 debug)A aa2 = f2();cout << endl;// 一个表达式中,连续拷贝构造+赋值重载->无法优化aa1 = f2();cout << endl;return 0;
}4.C++内存管理
4.1 C/C++内存分布
程序经过编译之后才可以变为可执行程序。
1. 栈又叫堆栈--非静态局部变量/函数参数/返回值等等,栈是向下增长的。
2. 内存映射段是高效的I/O映射方式,用于装载一个共享的动态内存库。用户可使用系统接口
创建共享共享内存,做进程间通信。(Linux课程如果没学到这块,现在只需要了解一下)
3. 堆用于程序运行时动态内存分配,堆是可以上增长的。
4. 数据段--存储全局数据和静态数据。
5. 代码段--可执行的代码/只读常量。
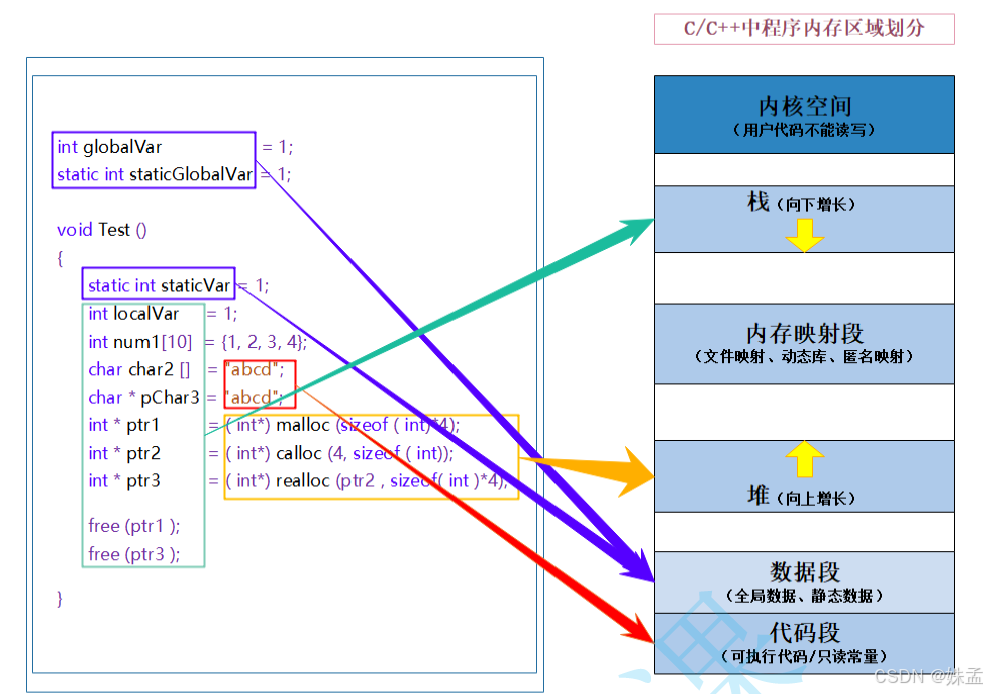
根据上述图形可以更直观地了解各个位置的存储类型。
4.2 C语言中动态内存管理方式:malloc/calloc/realloc/free
三者的区别请参考其他的相关文章。
4.3 C++内存管理方式
4.3.1 操作内置类型
C语言的内存管理方式可以在C++中应用,但是有些地方,C++具有自己的内存管理方式:通过 new 和 delete 操作符来进行动态内存管理。
new 和 delete 的使用方法示例:
void Test()
{//管理对象int* ptr4 = new int;int* ptr5 = new int(3);//初始化delete ptr4;delete ptr5;//管理对象数组int* ptr6 = new int[3];//此处的3是对象个数int* ptr7 = new int[5] = { 1, 2, 3 };//此处是数组的初始化delete[] ptr6;
}4.3.2 操作自定义类型
class A
{
public:A(int a = 0): _a(a){cout << "A()" << this << endl;}~A(){cout << "~A():" << this << endl;}
private:int _a;
};int main()
{//申请空间A* p1 = (A*)malloc(sizeof(A));//申请空间+构造函数A* p2 = new A(1);A* p3 = new A(1);//只释放空间free(p1);//析构函数 + 释放空间delete p2;delete p3;return 0;
}注意:在申请自定义类型的空间时,new会调用构造函数,delete会调用析构函数,而malloc与free不会。
由于C++的这些用法,用C++写链表会使得过程更加简便。
4.4 operator new与operator delete函数(重要点进行讲解)
4.4.1 operator new 与 operator delete函数(重点)
new和delete是用户进行动态内存申请和释放的操作符,operator new 和operator delete是
系统提供的全局函数,new在底层调用operator new全局函数来申请空间,delete在底层通过
operator delete全局函数来释放空间。