通过Dify快速搭建本地AI智能体开发平台
1. 安装Docker Desktop
访问 Docker官网 点击Download Docker Desktop,直接按照官方要求来就可以。
# 这串命令就像魔法咒语,在黑色窗口(命令提示符)里输入就能检查安装是否成功
docker --version2.安装dify
3.运行 Ollama
大模型安装,安装也可以先看看本地是否有相关大模型
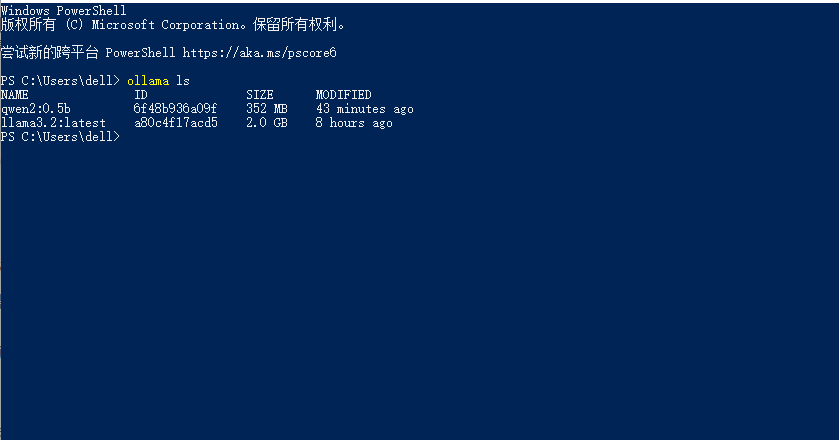
ollama run qwen2:0.5b,开新安装。
启动成功后,ollama 在本地 11434 端口启动了一个 API 服务,可通过 http://localhost:11434 访问。也可以自己随便设置一个。
4.Dify 中接入 Ollama
4.1 添加模型
在 设置 > 模型供应商 > Ollama 添加模型:
填写 LLM 信息:
模型名称:以 ollama 返回的为准
$ ollama ls
NAME ID SIZE MODIFIED
qwen2:0.5b 6f48b936a09f 352 MB 44 minutes ago
llama3.2:latest a80c4f17acd5 2.0 GB 8 hours ago
那就得填写:qwen2:0.5b或者llama3.2:latest,一句话填你拥有的大模型。
基础 URL:http://:11434
此处需填写 Ollama 服务地址。如果填写公开 URL 后仍提示报错,请参考常见问题,修改环境变量并使得 Ollama 服务可被所有 IP 访问。
若 Dify 为:http://192.168.65.0:11434
Docker 部署,建议填写局域网 IP 地址,如:http://192.168.1.100:11434 或 Docker 容器的内部 IP 地址,例如:http://host.docker.internal:11434
若为本地源码部署,可填 http://localhost:11434
模型类型:对话
模型上下文长度:4096
模型的最大上下文长度,若不清楚可填写默认值 4096。
最大 token 上限:4096
模型返回内容的最大 token 数量,若模型无特别说明,则可与模型上下文长度保持一致。
是否支持 Vision:是
当模型支持图片理解(多模态)勾选此项,如 llava。
点击 “保存” 校验无误后即可在应用中使用该模型。
Embedding 模型接入方式与 LLM 类似,只需将模型类型改为 Text Embedding 即可。
4.2 使用 Ollama 模型
进入需要配置的 App 提示词编排页面,选择 Ollama 供应商下的 llava 模型,配置模型参数后即可使用:



