梁文锋署名,DeepSeek-V3新论文揭秘:低成本大模型训练如何突破算力瓶颈?
近日,DeepSeek团队发布了DeepSeek-V3的最新论文,重点讨论了在大规模人工智能模型训练中遇到的扩展挑战以及与硬件架构相关的思考。这篇长达14页的论文不仅总结了 DeepSeek 在开发 V3过程中的经验与教训,还为未来的硬件设计提供了深刻的见解。

值得注意的是,DeepSeek的CEO梁文锋也参与了论文的撰写。
DeepSeek-V3仅需2048块H800显卡、总训练成本278.8万GPU小时,便实现6710亿参数模型的训练,成本仅为同级别模型的1/10。
而这份由梁文锋参与署名的技术报告,则针对此揭示了低成本训练的密码,更预示着AI军备竞赛可能迎来范式转折。
具体而言,团队主要通过以下几个方面的核心技术实现了突破:
内存优化:多头潜在注意力机制
传统Transformer架构的内存瓶颈在DeepSeek-V3手中找到了解药。
模型采用的多头潜在注意力机制,通过投影矩阵将所有注意力头的键值对压缩为低维潜在向量,使每个token的KV缓存从行业平均的490KB骤降至70KB。
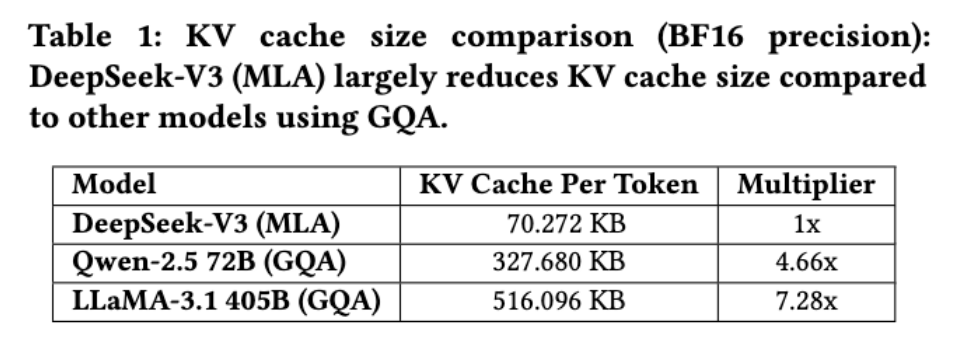
这种压缩并非简单删减,而是通过联合训练让模型学会在潜在空间中保留关键信息。测试数据显示,在处理64K长度文本时,内存占用仅为Llama-3.1的1/7,直接破解了长文本训练的内存瓶颈。
更多设想藏在了论文的末章。用3D堆叠DRAM技术可将内存芯片垂直堆叠在计算单元上,使单卡内存容量提升4倍。这种硬件架构的革新若与MLA机制结合,理论上可支持百万token级别的超长文本训练,为Agent处理长篇小说或代码库铺平道路。
计算范式突破:MoE架构的进化论
混合专家模型并非新概念,但DeepSeek-V3将其推向了新高度。
模型采用DeepSeekMoE架构,将6710亿参数拆分为256个路由专家和1个共享专家,每个token仅激活8个专家。
这种设计实现两个突破:其一,激活参数量控制在370亿,使训练计算量仅为稠密模型的1/10;其二,通过无辅助损失的负载均衡策略,避免专家过载或闲置,训练稳定性提升3倍。
通信优化:多层网络拓扑与低延迟设计
在通信优化层面,DualPipe流水线并行技术将计算与通信完全重叠。当GPU处理当前批次的MLA计算时,上一批次的专家路由通信已在后台完成。这种时空折叠技术使集群整体利用率突破92%,在2048卡规模下实现线性加速比。
更值得关注的是,论文首次验证了FP8精度在万亿参数模型训练中的可行性,通过分块压缩和动态误差补偿,将精度损失控制在0.25%以内。
与此同时,DeepSeek-V3采用两层胖树网络拓扑,将传统三层网络中的核心层与汇聚层合并,使节点间通信带宽提升3倍。实测数据显示,在256卡规模下,All-Reduce操作的延迟从4.2μs降至1.3μs。这种架构创新与NVLink+IB的混合组网策略结合,使跨节点通信带宽利用率达到92%,远超行业平均水平。
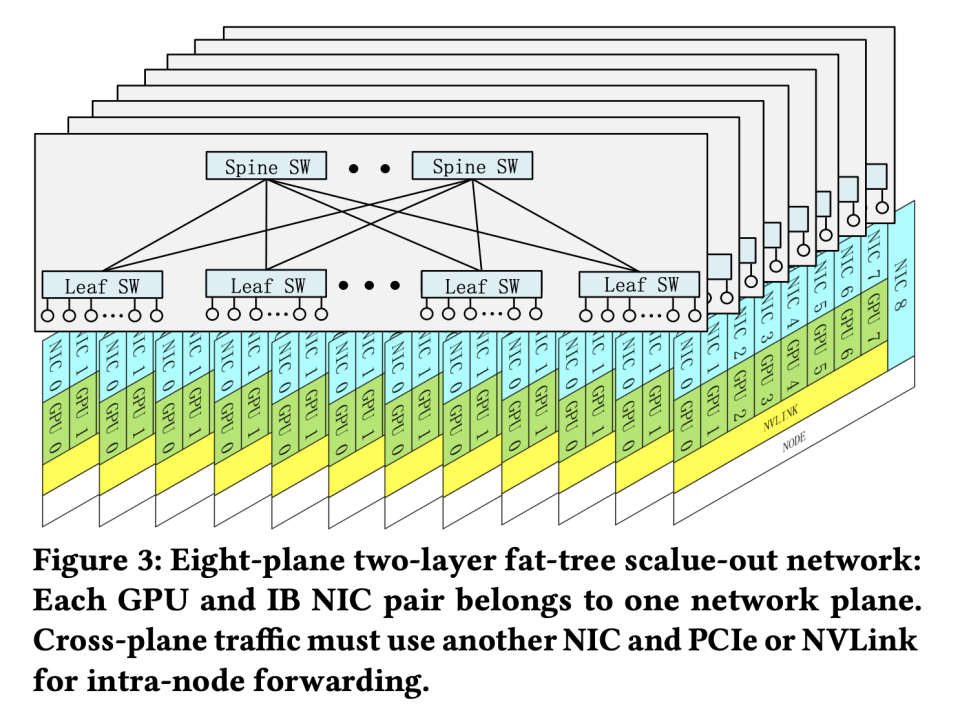
论文还提出革命性设想:未来的AI硬件应整合节点内纵向扩展与节点间横向扩展,通过统一网络适配器实现计算、存储、通信的三维融合。这种设计若实现,万亿参数模型的训练时间可从月级压缩至周级,彻底改写大模型研发周期。
推理加速双引擎:MTP与硬件协同
在推理阶段,DeepSeek-V3祭出了多token预测(MTP)技术。
模型在生成当前token时,会并行预测后续2-3个候选token,通过轻量级验证网络筛选最优结果。这种前瞻性计算使生成速度提升1.8倍,实测显示每秒可生成18个token,且保持80%以上的准确率。
更关键的是,MTP与消费级GPU的Tensor Core深度适配,使模型能在单块RTX 4090显卡上实现近20 TPS的性能,将大模型部署成本从万美元级拉低至千元级。
最后,论文还对下一代硬件进行展望:支持FP32累加的AI加速器、集成通信协处理器的DPU、具备自愈能力的光互联网络,这些构想如果成为现实,将彻底消除当前AI训练中的三座大山——内存墙、计算墙、通信墙。
这份论文不仅是一份技术说明书,更像一份宣言书——在AI军备竞赛的下半场,智慧比算力更珍贵。由此看来,DeepSeek的价值已超越技术本身。
论文地址:https://arxiv.org/pdf/2505.09343