电商热销榜的5种实现方案
文章目录
- 1. MySQL 聚合查询:传统统计法
- 2. Redis Sorted Set:内存排行榜
- 3. Elasticsearch 实时聚合:搜索专家
- 4. 缓存+异步更新:榜单的幕后推手
- 5. 大数据离线批处理:夜间魔法师
博主介绍:全网粉丝10w+、CSDN合伙人、华为云特邀云享专家,阿里云专家博主、星级博主,51cto明日之星,热爱技术和分享、专注于Java技术领域
🍅文末获取源码联系🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
在电商平台中,展示“热销榜”是常见功能:哪些商品卖得最火?不同场景下有不同的实现思路。下面我们用幽默轻松的方式,介绍五种实现方案,包括它们的适用场景、优劣势以及技术选型建议,并附上简洁的代码示例。
1. MySQL 聚合查询:传统统计法
场景与原理:最直观的方法是直接用 MySQL 在订单表或销售记录表上做 GROUP BY 聚合,统计各商品销量后排序。比如:
SELECT product_id, SUM(quantity) AS total_sales
FROM order_items
WHERE order_date BETWEEN '2025-05-01' AND '2025-05-15'
GROUP BY product_id
ORDER BY total_sales DESC
LIMIT 10;
-
适用场景:数据量较小或业务量不大时,可以用这种「直接查」的方式,开发成本最低。适合中小型电商、离峰时间定时统计等场景。
-
优势:实现简单,代码容易理解;数据高度一致(强一致性)。使用索引、分区、物化视图等还能做一定优化。
-
劣势:面对海量数据时十分“煎熬”。例如,假设平台有50万用户、500万商品,如果订单行为记录有数亿条,对整个表做统计查询会非常耗时。查询太慢,写入时还可能因为锁表或锁行影响并发(例如点赞时需要更新计数列,会造成写冲突)。总之,用一个大锅把所有数据煮在一起再端出来,性能瓶颈明显。
-
技术建议:如果使用此方案,应尽量限制统计范围(如时间范围、热门品类)。可以考虑把历史数据分表分库,或者提前把每日/每月统计结果预先汇总到一个汇总表。还可以在业务角度做缓存——比如每天晚上离峰期预先统计好第二天的榜单,缩短展示延迟。
-
示例代码:下面用 Python 演示通过数据库查询热销榜(伪代码):
import mysql.connectorconn = mysql.connector.connect(host='db', database='shop', user='root', password='secret') cursor = conn.cursor() # 查询过去一周每个商品的总销量,取前10 cursor.execute("""SELECT product_id, SUM(quantity) AS total_salesFROM order_itemsWHERE order_date BETWEEN %s AND %sGROUP BY product_idORDER BY total_sales DESCLIMIT 10 """, ('2025-05-08', '2025-05-15')) for product_id, total in cursor.fetchall():print(product_id, total)这段代码直观易懂,但当
order_items表有数亿条记录时,查询很可能超时。
2. Redis Sorted Set:内存排行榜
场景与原理:Redis 的有序集合(ZSet)非常适合排行榜场景。可以把每个商品作为成员(member),销量作为分值(score),每次订单时用 ZINCRBY 更新分值,展示榜单时用 ZREVRANGE(按分值降序)取 TopN。这样排行榜信息都在内存中,查询极快。
ZINCRBY sales_rank 1 product_12345 # 商品ID为product_12345,销量加1
ZINCRBY sales_rank 2 product_67890 # 另一个商品销量加2
ZREVRANGE sales_rank 0 9 WITHSCORES # 获取销量最高的前10个商品及销量
-
适用场景:适合需要实时更新和查询的排行榜,比如秒杀活动、游戏积分榜、热销榜等。只要内存够用,Redis 的性能非常高,可以毫秒级完成更新和排序操作。
-
优势:读写速度快(Redis 基于内存),支持原子更新,无需复杂锁;获取 TopN 非常高效(底层跳表实现)。能方便地实现日榜、周榜、月榜等不同时间段的排行榜(只需按日期拆分不同的 ZSet key)。
-
劣势:数据是存内存的,需要足够内存存储排行数据。如果商品和时间维度很多,ZSet 的 key 数量会成倍增加,每次更新也要遍历多个 key(例如日榜、周榜、月榜都要加分);而且内存数据易丢失(需要持久化方案)。Redis 也不适合超大数据量的全量统计。
-
技术建议:适合对实时性要求高、单机数据量可控的场景。可结合定时持久化或 AOF 保存防止数据丢失。为节省内存,只存需要排行榜的热门商品,其他商品不入 Redis。榜单长度一般固定在 TopN,因此 Memory 不会“特别大”。
-
示例代码:下面用 Python 和
redis-py演示排行榜更新与查询:import redisr = redis.Redis(host='localhost', port=6379, db=0) # 模拟订单发生时更新排行榜 product_id = "product_12345" r.zincrby("sales_rank", 1, product_id) # 商品销量 +1 r.zincrby("sales_rank", 1, "product_67890") # 获取销量榜前10 top10 = r.zrevrange("sales_rank", 0, 9, withscores=True) for rank, (prod, score) in enumerate(top10, 1):print(rank, prod.decode(), int(score))上面示例中,
sales_rank是一个 ZSet 键,每个成员是商品ID,分值是累计销量。执行zincrby后,zrevrange能迅速返回前十。
3. Elasticsearch 实时聚合:搜索专家
场景与原理:Elasticsearch (ES) 作为分布式实时搜索引擎,也可用于排行查询。思路有两种:一是将商品信息及其实时销量作为文档存入 ES,并按销量字段排序;二是将每笔订单记录入 ES,然后用聚合(terms + sum)查询各商品销量。例如,使用聚合查询求前10销量商品:
GET /orders/_search
{"size": 0,"aggs": {"top_products": {"terms": {"field": "product_id","order": { "total_sales": "desc" },"size": 10},"aggs": {"total_sales": { "sum": { "field": "quantity" } }}}}
}
-
适用场景:适合需要复杂实时查询和分析的场景。Elasticsearch 是分布式、实时的搜索和分析引擎,可以水平扩展到集群,支持全文检索、过滤、聚合等多种能力。用于热销榜时,如果数据量较大,ES 可以并行聚合分片数据,返回结果。它的实时性比传统数据库要好一些。
-
优势:内置强大的聚合功能,可用来统计和排序;水平扩展容易加节点;结合 Kibana 等工具,可做可视化分析。对于数据量大、并发查询高的场景,分布式 ES 比单机 MySQL 更具吞吐。
-
劣势:ES 资源消耗大,需要更多内存和 CPU。“处理大量数据时可能会出现性能问题”,配置和调优复杂;数据一致性为近实时,写入到可查询需要一个小延迟;针对排行榜这种频繁更新分值的场景,每次写入文档后都需要刷新索引,消耗较大。此外,ES 专为搜索设计,用于高频率更新排名时并不是最优选择。StackOverflow 上就有人提到“对 ES 来说,每次更新都要重新计算排名,没办法做到排行”。
-
技术建议:若已有 ES 平台,可方便地扩展出排行榜功能。可将订单日志同步到 ES,并周期性运行聚合查询(近实时)。或者在商品索引中增加销量字段,每次订单后更新文档,但要注意批量刷新策略来减少开销。适合需要全文搜索与排行融合的场景,否则纯排行需求下,可以优先考虑 Redis 或缓存方案。
-
示例代码:下面示例用 ES 的 JSON 查询语言,统计各商品总销量并按降序取前10(相当于前面示例中的聚合查询):
GET /orders/_search {"size": 0,"aggs": {"top_products": {"terms": {"field": "product_id","order": { "total_sales": "desc" },"size": 10},"aggs": {"total_sales": { "sum": { "field": "quantity" } }}}} }上述查询返回了按销量排序的前 10 个
product_id。在实际代码中,可以使用官方客户端发起此查询。例如使用 Python 的elasticsearch库:from elasticsearch import Elasticsearches = Elasticsearch(["http://localhost:9200"]) res = es.search(index="orders", body={"size": 0,"aggs": {"top_products": {"terms": {"field": "product_id", "order": {"total_sales": "desc"}, "size": 10},"aggs": {"total_sales": {"sum": {"field": "quantity"}}}}} }) top = res['aggregations']['top_products']['buckets'] for bucket in top:print(bucket['key'], bucket['total_sales']['value'])需要注意的是,如果订单数量极大,上述聚合也会很耗时。一般可将 ES 用作对 MySQL 的补充分析,而非单纯排行榜的主要存储。
4. 缓存+异步更新:榜单的幕后推手
场景与原理:实时性需求高,但数据库写入慢时,可采用「写一遍缓存、后台慢慢同步」的方式。具体做法是:用户下单时,先更新缓存中的排行榜(如 Redis ZSet),并异步将增量消息发到消息队列;后台消费者接收消息后再更新关系型数据库或持久化存储。这样,排行榜可立即反馈给用户(低延迟),而数据库更新则异步执行,削峰填谷。
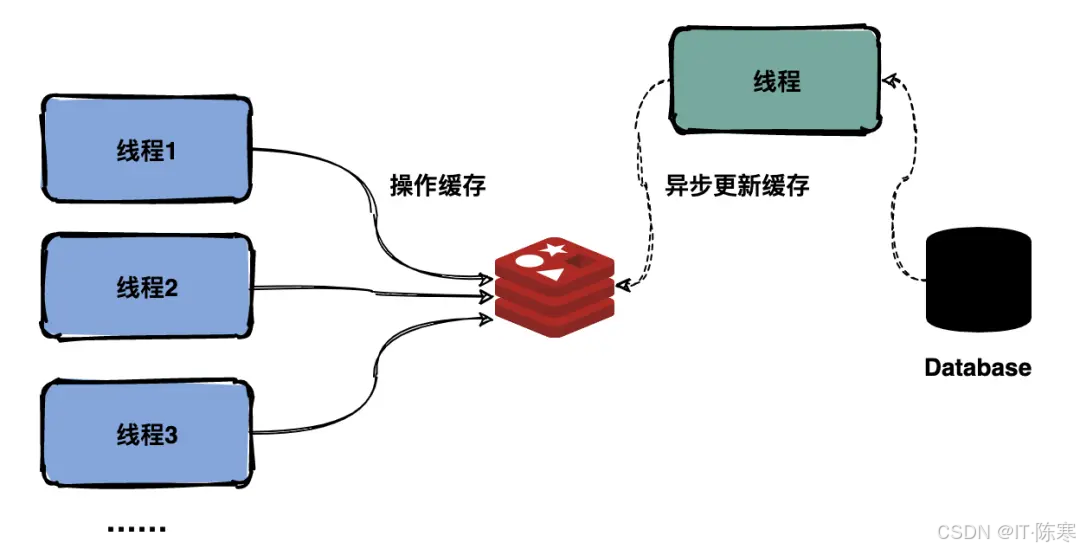
-
适用场景:适合对读高峰性能要求严格,而对最终一致性要求稍松的场景(例如排行榜不是严格金融账本)。当订单并发猛增时(秒杀场景),通过消息队列缓冲可平滑流量,避免 DB 瞬时写爆表。
-
优势:读操作(排行榜查询)都落在缓存层,速度飞快;写操作先写缓存,不阻塞用户流程;消息队列可应对突发流量,将写压力抛给后台,有一定的降峰功能;系统整体更解耦、灵活。
-
劣势:弱一致性:缓存与数据库之间可能存在短暂数据不一致,需要考虑延时刷新和缓存失效策略;系统复杂度提高,需要额外维护消息队列和后台服务;需要保证消息投递与消费的可靠性。
-
技术建议:常见做法是使用 Redis 作为排行榜缓存,RabbitMQ/Kafka 等消息中间件接收“销售事件”消息,后台服务消费后更新 MySQL 或 Elasticsearch。建议给“热Key”操作加分使用异步方式,防止缓存击穿或数据库死锁。
-
示例代码:下面用 Python 演示一个简化的异步更新流程(伪代码)。假设我们有一个消费订单的函数,当订单到来时我们更新 Redis 并发送消息到队列:
import redis, json import pika # RabbitMQ 客户端示例# 初始化 Redis 和消息队列(RabbitMQ) r = redis.Redis(host='localhost', port=6379, db=0) conn = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = conn.channel() channel.queue_declare(queue='sales_updates')def on_order_created(order):# 订单生成时更新缓存排行榜pid = order['product_id']qty = order['quantity']r.zincrby("sales_rank", qty, pid) # Redis 内存排行加分# 异步发消息给后台处理持久化msg = json.dumps({"product_id": pid, "increment": qty})channel.basic_publish(exchange='', routing_key='sales_updates', body=msg)# 后台消费者示例(可运行在另一个进程或服务) def process_sales_update(ch, method, properties, body):data = json.loads(body)pid = data['product_id']inc = data['increment']# 这里调用数据库接口,更新订单表或商品销量表update_database_sales(pid, inc)ch.basic_ack(delivery_tag=method.delivery_tag)在这个例子里,
on_order_created表示一个订单生产事件:它将销量更新到 Redis 排行榜,同时将消息放入sales_updates队列。后台有一个监听该队列的服务,异步处理并更新数据库。这样用户侧不会被数据库的锁或延迟拖慢。
5. 大数据离线批处理:夜间魔法师
场景与原理:当订单数据量极大(数亿、数十亿条)且对实时性要求不高时,可以使用大数据技术(如 Apache Spark、Flink 等)离线批处理生成热销榜。思路是把所有订单数据(日志、HDFS、数据湖或数据库快照)作为输入,通过分布式计算,按商品汇总销量,然后排序输出 TopN。因为是离线统计,往往在业务低峰期(如半夜)跑批任务,第二天再展示榜单。
-
适用场景:适合数据规模特别大或计算非常复杂的情况。例如电商全站级别的统计分析、定期报表、整站销量排行等。利用 Spark 或 Flink 的强大并行能力,可以在处理数十亿条记录后,快速生成榜单。
-
优势:可处理海量数据,横向扩容能力强;开发模型相对灵活,可合并多种数据源(订单库、点击流日志等),实现更复杂的统计。结果离线生成,数据库和应用不受高峰压力。
-
劣势:非实时,通常需要几分钟到几小时的延迟,不适合需要分钟级更新的榜单;需要运维大数据平台,学习成本和资源成本都较高;调度和监控复杂。
-
技术建议:可使用 Spark SQL、Flink 批处理等。将订单数据按时间分区存储(如 Parquet),定时触发批作业。注意采用适当的分区和聚合策略(如使用
groupBy+sum操作然后orderBy+limit)来获取 TopN。处理完后将榜单写入缓存或数据库,供服务端读取展示。 -
示例代码:以下是用 PySpark 简单演示的示例,假设有一张订单数据表,列有
product_id和quantity:from pyspark.sql import SparkSession from pyspark.sql.functions import desc, sum as _sumspark = SparkSession.builder.appName("HotProducts").getOrCreate() # 读取订单数据(例如已缓存为 Parquet 或从数据库导入) orders = spark.read.parquet("hdfs://.../data/orders.parquet") # 计算各商品总销量,取前10 top10 = (orders.groupBy("product_id").agg(_sum("quantity").alias("total_sales")).orderBy(desc("total_sales")).limit(10)) top10.show()这段代码将在整个集群上并行运行,对巨量订单数据分区聚合后输出前10名热销商品。生产环境中,可以把结果保存到 Hive 表或 NoSQL 存储,定时更新排行榜。
综上所述,不同的技术方案各有千秋:MySQL 聚合法简单但对海量场景“骨感”;Redis ZSet实时快速但占内存、易失效;Elasticsearch搜索力强、分布式友好,但更新开销大、配置复杂;缓存+异步方案读写分离、降峰有奇效;大数据离线能扛海量,但要等批作业完成。根据业务需求(实时性、数据量、成本等)权衡取舍,才能设计出既酷炫又靠谱的电商热销榜。
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻