一般的析因设计
本文是实验设计与分析(第6版,Montgomery著傅珏生译)第5章析因设计第5.4节的python解决方案。本文尽量避免重复书中的理论,着于提供python解决方案,并与原书的运算结果进行对比。您可以从Detail 下载实验设计与分析(第6版,Montgomery著傅珏生译)电子版。本文假定您已具备python基础,如果您还没有python的基础,可以从Detail 下载相关资料进行学习。
二因子析因设计的结果可以推广至一般情况,其中因子A有a个水平,因子B有b个水平,因子C有c个水平,等等,这些因子安排在一个析因实验中。一般说来,当有完全实验的n次重复时,将有abc···n个总的观测值。当所有可能的交互作用包括在模型之内时,为了确定误差平方和,必须至少进行两次重复(n≥2)。
如果实验的所有因子都是固定的,则容易给出计算公式并检验关于主效应和交互作用的假设。对固定效应模型说来,主效应和交互作用的检验统计量都可以将相应的主效应或交互作用的均方除以误差均方而得。所有这些F检验都是上尾部的、单边的检验,任一主效应的自由度是因子的水平数减1,交互作用的自由度是和交互作用有关的各个成分的自由度的乘积。
例如,考虑三因子方差分析模型,设A,B,C是固定的,方差分析表如表5.12所示,关于主效应和交互作用的F检验可直接由期望均方得出。

通常,利用统计软件包计算方差分析,然而,偶尔手工计算平方和的公式也是有用的。总平方和由通常的办法得出:
![]()
主效应的平方和由因子A,B,C的总和yi…,y,j..,y..k,求得如下。
![]()
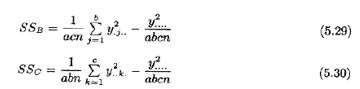
计算二因子交互作用的平方和,要用到A×B,A×C,B×C单元的总和。要计算这些量,通常借助于把原始数据表压缩为三个双向表。由下式得出这些平方和:
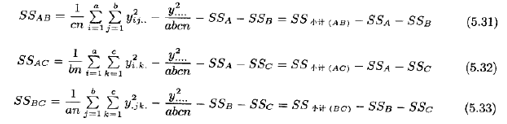
二因子小计的平方和从每个双向表的总和中得出。三因子交互作用的平方和由三项单元总和{yijk}算得为
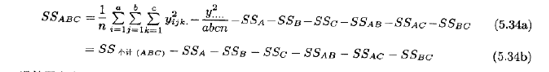
误差平方和可以从总平方和减去每个主效应以及交互作用的平方和而得到,或者用
![]()
例5.3软饮料的灌装问题
一位软饮料灌装员成兴趣的问题是,在他的生产线上生产的瓶装饮料有更为一致的灌装高度。灌注机械从理论上说能以正确的标准高度来灌注每只饮料瓶,但实际上,围绕这一目标是有偏差的,灌装员希望更好地了解这种变异性的来源进而减小这种偏差。
在进行灌注时,生产线上的工程师能够控制3个变量:碳酸百分率(A),灌注器的操作压强(B),每分钟生产的瓶数或流水线速度(C)。压强和速度易于控制,但是在实际生产时,碳酸百分率却较难于控制,因为它随产品温度的变化而变化。不过,为了实验,工程师可以在3个水平上控制碳酸:10%,12%以及14%。他选取两种压强水平(20psi与30psi)和两种流水线速度水平(200bpm与250bpm)。他决定在这三因子的析因设计中做两次重复,所有24个试验的顺序是随机选取的。观测到的响应变量是相对于目标灌注高度的平均偏差,它是在每一组条件下生产瓶装饮料时观测到的。从这一实验中所得的数据如表5.13所示。正偏差表示灌注高度在目标之上,负篇差表示灌注高度在目标之下,表5.13中圆圈内的数是三向单元总和ijk。
由(5.27)式得出总校正平方和为
![]()
由(5.28)式、(5.20)式与(5.30)式算得主效应的平方和是
![]()
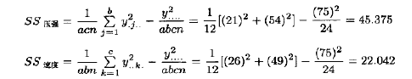
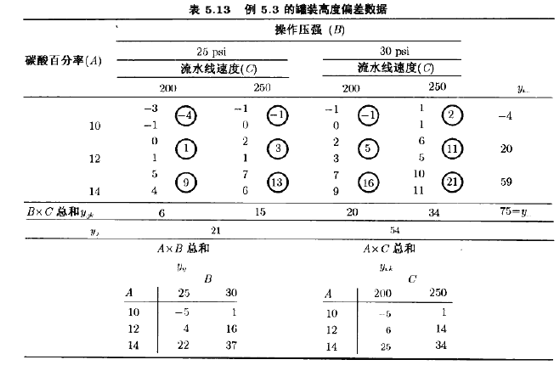
要计算二因子交互作用的平方和,必须求出双向单元的总和。例如,为了求碳酸-压强即AB的交互作用,需要表5.13中A×B的单元总和{yij..}。用(5.31)式,求得平方和为
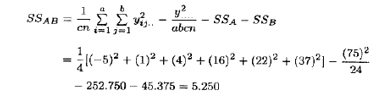
碳酸-速度即AC的交互作用由表5.13所示的A×C的单元总和{yi.k.}以及(5.32)式求得
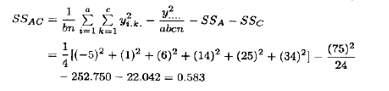
碳酸-速度即AC的交互作用由表5.13所示的A×C的单元总和{y.jk.}以及(5.32)式求得
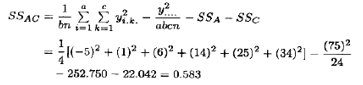
压强-速度即BC的交互作用由表5.13的B×C的单元总和{yijk.}以及(5.33)式求得:
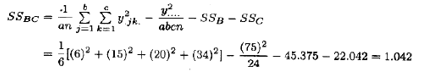
三因子交互作用的平方和由A×B×C的单元总和{yijk.}求得,那是表5.13中用圆圈圈起来的数。由(5.34a)式,得

最后,注意到
![]()
我们有
![]()
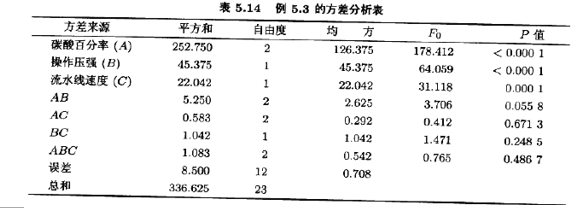
方差分析概括在表5.14中。碳酸百分率、操作压强、流水线速度都显著影响灌注量。碳酸-压强交互作用的F比的p值为0.0558,这表明这两个因子之间有弱的交互作用。
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.formula.api as smf
import pandas as pd
import statsmodels.api as sm
from sklearn import linear_model
import seaborn as sns
import matplotlib.pyplot as plt
import mistat
x1 = [25,25,30,30,25,25,30,30,25,25,30,30,25,25,30,30,25,25,30,30,25,25,30,30]
x2 = [200,250,200,250,200,250,200,250,200,250,200,250,200,250,200,250,200,250,200,250,200,250,200,250]
x3 = [10,10,10,10,10,10,10,10,12,12,12,12,12,12,12,12,14,14,14,14,14,14,14,14]
y = [-3,-1,-1,1,-1,0,0,1,0,2,2,6,1,1,3,5,5,7,7,10,4,6,9,11]
data = {"y":y,"x1":x1,"x2":x2,"x3":x3}
data=pd.DataFrame(data)
#d = pd.read_csv("G:/WORK/5-1.txt", sep="\t")
model =smf. ols('data.y ~ C(data.x1)*C(data.x2)*C(data.x3) ', data=data).fit()
anova_table = sm.stats.anova_lm(model, typ=2)
anova_table
>>> anova_table
sum_sq df F PR(>F)
C(data.x1) 45.375000 1.0 64.058824 3.742257e-06
C(data.x2) 22.041667 1.0 31.117647 1.202174e-04
C(data.x3) 252.750000 2.0 178.411765 1.186249e-09
C(data.x1):C(data.x2) 1.041667 1.0 1.470588 2.485867e-01
C(data.x1):C(data.x3) 5.250000 2.0 3.705882 5.580812e-02
C(data.x2):C(data.x3) 0.583333 2.0 0.411765 6.714939e-01
C(data.x1):C(data.x2):C(data.x3) 1.083333 2.0 0.764706 4.868711e-01
Residual 8.500000 12.0 NaN NaN
model =smf. ols('data.y ~ data.x1*data.x2*data.x3 ', data=data).fit()
anova_table = sm.stats.anova_lm(model, typ=2)
anova_table