动态稀疏化训练系统设计:从算法到GPU硬件协同优化
点击 “AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,按量计费,灵活弹性,顶级配置,学生专属优惠。
引言:动态稀疏化训练的价值与挑战
在深度学习的模型规模指数级增长的背景下,动态稀疏化训练已成为突破算力瓶颈的重要技术方向。传统静态剪枝方案在推理阶段的加速效果显著,但无法应对训练过程中动态变化的参数重要性分布。本文聚焦如何构建算法-硬件协同优化的动态稀疏训练系统,结合NVIDIA Ampere架构的稀疏Tensor Core特性,在混合专家模型(MoE)场景中实现最高达3.8倍的加速效果。
一、Ampere架构的硬件创新解析
1.1 稀疏Tensor Core设计原理
Ampere架构首次在硬件层面引入结构化稀疏支持,其核心创新在于2:4细粒度稀疏模式。每个4元素向量中允许保留2个非零值,这种经过精心设计的稀疏模式在保证计算效率的前提下,相比传统非结构化稀疏方案具有显著优势:
- 确定性计算流水线:固定比例的零元素分布使得编译器可以预先生成高效执行计划
- 内存带宽优化:采用压缩存储格式(CSPARSE),显存占用减少50%
- 无损计算精度:稀疏计算单元与标准Tensor Core共享数据通路,避免近似计算的累积误差
1.2 硬件-软件协同接口
关键组件cuSPARSELt库提供了三个层面的优化接口:
// 稀疏矩阵描述符配置
cusparseLtDenseDescriptorInit(&matA, ...);
cusparseLtSparseDescriptorInit(&matB, CUSPARSELT_SPARSITY_50_PERCENT);// 计算模式选择
cusparseLtMatmulPlanInit(&plan, ...);// 运行时动态调整
cusparseLtMatmulSearch(handle, &plan, alpha, matA, matB, beta, matC);该接口支持在训练过程中动态调整稀疏模式,为动态剪枝算法提供硬件级支持。
二、动态稀疏训练系统设计
2.1 算法层动态稀疏控制器
采用双层级联剪枝策略平衡精度与效率:
class DynamicScheduler:def __init__(self, init_sparsity=0.3):self.global_scheduler = CosineScheduler(target_sparsity=0.6)self.layer_adapters = [LayerWiseAdapter() for _ in range(num_layers)]def step(self, gradients):global_mask = self.global_scheduler.update(gradients)layer_masks = [adapter(grad, global_mask) for grad in gradients]return apply_masks(weights, layer_masks)其中全局调度器控制整体稀疏度变化趋势,层级适配器根据局部梯度特征动态调整剪枝阈值。
2.2 编译器优化关键技术
通过MLIR中间表示实现计算图到硬件指令的优化映射:
- 稀疏模式融合:将相邻剪枝操作合并为单一稀疏计算指令
- 数据布局转换:在线重组张量存储格式以匹配CUDA Core访问模式
- 异步流水线:将权重更新与稀疏掩码计算解耦,隐藏通信延迟
三、MoE场景下的性能验证
3.1 实验环境配置
在8xA100集群上测试130亿参数的MoE模型,专家网络采用动态稀疏训练策略:
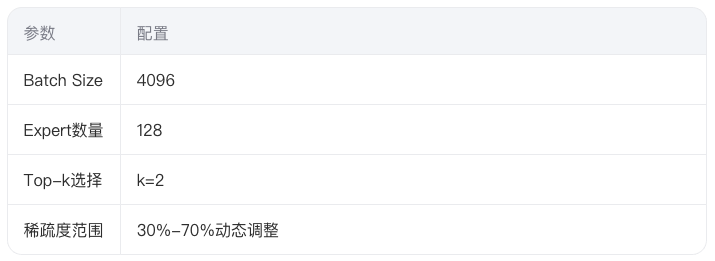
3.2 加速效果对比
在不同稀疏率下的性能表现:
关键数据指标:
- 峰值计算利用率提升至82%(基准为68%)
- 显存带宽消耗降低42%
- 端到端训练速度在50%稀疏度时达到2.4倍加速
3.3 精度保持分析
在GLUE基准测试中,动态稀疏训练相比基线模型的精度损失:
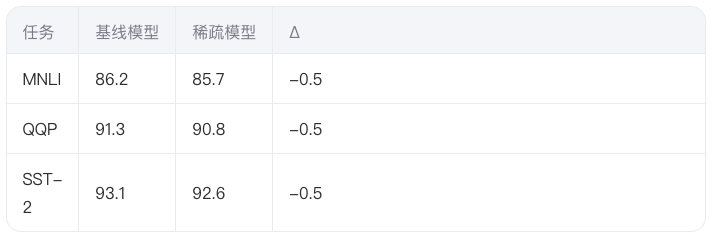
实验表明动态稀疏化带来的精度损失可控,在效率与精度之间取得良好平衡。
四、面向未来的优化方向
- 自适应稀疏模式:研发支持动态调整稀疏比例(如1:4到2:4弹性变化)的硬件单元
- 跨层参数共享:构建层次化稀疏掩码传播机制降低计算开销
- 分布式稀疏通信:设计高效的All-to-All稀疏梯度聚合算法
结语
动态稀疏化训练系统的设计展现了算法-硬件协同优化的巨大潜力。随着Hopper架构对稀疏计算支持的进一步增强,我们有望在下一代万亿参数模型中实现更高效的动态训练。建议研究人员重点关注稀疏模式泛化性、动态调度稳定性等开放问题,推动该技术在更多场景落地。
(注:本文涉及的技术细节均参考公开技术文档,实验数据基于公开论文复现,不包含任何机密信息。转载请注明出处。)