数据结构(2)线性表-顺序表
知道一个算法的好坏怎么去判断以后,就该正式的去学习一些常见的数据结构,当然,这里的数据结构仅仅是初阶,不会挨个一个一个学完,后期慢慢来。
一、数据结构总论
一般按照逻辑结构和存储结构来分类,在初阶的学习时,虽不能全部学完,但基本每个类别都能见到例子。
1.按逻辑结构分类
按照逻辑结构分类,可以分为集合结构(数据元素同属于一个集合,但是并没有任何的关系)、线性结构(数据元素一对一,好像一条线一样连在了一起)、树形结构(数据元素一对多的关系,就好像一个树的主干的根只有一个,但是他身上每一个节点都可能有好几个树枝)、图状/网状结构(这种结构就类似于在天上俯瞰一个城市的公路一样,每条路的十字看做一个数据元素的话,那就是多对多的关系)
2.按存储结构分类
按照存储结构有顺序存储(如数组,数组元素就是在内存中连续的存储)、链式存储(其实在C语言学习结构体的时候我们就已经见过怎样建立一个链表节点,即一个数据域,一个地址,这个地址是指向链式存储的下一个数据元素)、索引存储、哈希存储(根据散列函数的计算而定位数据元素)。
二、线性表
线性表是一类数据结构的总称,这一类数据结构最明显的特点就是逻辑上是线性的,但是物理上不一定是线性的。
也就是说,线性表在使用的时候,在我们的大脑中思考就是连续的、线性的,但实际上在内存中的存储可不一定是顺序存储。
三、顺序表
1.概述
这次学习的顺序表就是属于线性表,符合线性表的特征,即逻辑结构是线性结构,且数据顺序存储(底层实现类似于数组,或者说借助于数组)。
2.顺序表和数组的区别
这个时候就有人要问了,既然你跟我说顺序表借助于数组实现,那为啥不就当成数组呢。它们两个的关系就类似于什么呢:
我相信基本上能跟编程打交道的,你说你自己一点也不玩游戏,我是不信的,甭管玩手机游戏还是电脑游戏,你要玩游戏最基本得有个设备吧,就说手机游戏,你弄个平板玩,正常就搂着玩就行了呗,但是有的人嫌举着累,买个支架,又嫌自己打游戏的时候发热会导致掉帧,卡的不行,又买了一个散热器,手老出汗买个指套,更有甚者玩个手机游戏开加速器。
顺序表和数组基本就是这样的,数组只能存一系列数据,你存着只能取出来用,对里面的数据进行增删改是很麻烦的,顺序表在创建好以后,相当于数组+增加/删除/修改/查找……一系列的辅助工具,帮助你对数据进行维护,数组就没有这个条件。
3.顺序表的声明
①静态顺序表
静态数据表就是用定长数组来存储数据的,当然,并不等同于数组,一般都是这样定义的:
#define定义是为了方便修改静态顺序表的大小,即底层的数组的大小,为什么要将数组的类型由typedef定义一下呢,直接写个int不行吗?
给顺序表的数据的类型取别名也是为了方便修改顺序表所存储的数据类型。
这样看来顺序表也没比数组好到哪去,只不过可以确定有效数据个数而已。
这么看当然看不出来顺序表相对于数组的优点,因为正常情况下,比如用顺序表来存储双11某用户的订单个数,这种玩意肯定是动态的,不能说你就给他7个大小的内存,假如就说成7个订单,那万一双十一买的多了咋办,难道还能让用户少买一点吗?肯定是用户创建的订单决定数据存储的大小,也就是经常用的就是动态顺序表。
②动态顺序表
动态和静态的区别在哪里那,其实举的小例子已经给出了,静态的顺序表存储的数据个数是固定的,你给少了吧就不够用,给多了吧,又给内存浪费了(不要小看内存浪费,一个人浪费1000个字节,人多起来再多的内存都不够用)。
千万不要说,那你说要多大,比如存7个int,我就给你#define N 7,你要几我就定义几,这真就是对程序的内存申请不了解啊,在C语言学习的时候不说别的,编译的时候就给这个顺序表的内存大小固定死了,你把N定义的值改了有什么用,你程序已经写好了,软件里就是这么大,你说改成9,那么软件就不能用了,就得重新把你改好的应用到软件里,你敢想象双十一,特别是双十一的晚上购物平台提交不了订单会造成多大的损失吗,等你改好再上架,黄花菜都凉了。
因此,来看我们动态顺序表的声明(动态就是可以根据你给的数据,去调整申请的内存大小)。

因为要动态申请,所以提前准备一个指针,去接收不管是malloc还是calloc等去申请的那块内存空间的地址,有效数据个数不用多说,而静态顺序表的大小是确定的,动态顺序表只能动态计算去确定,因此多加一个capacity变量。
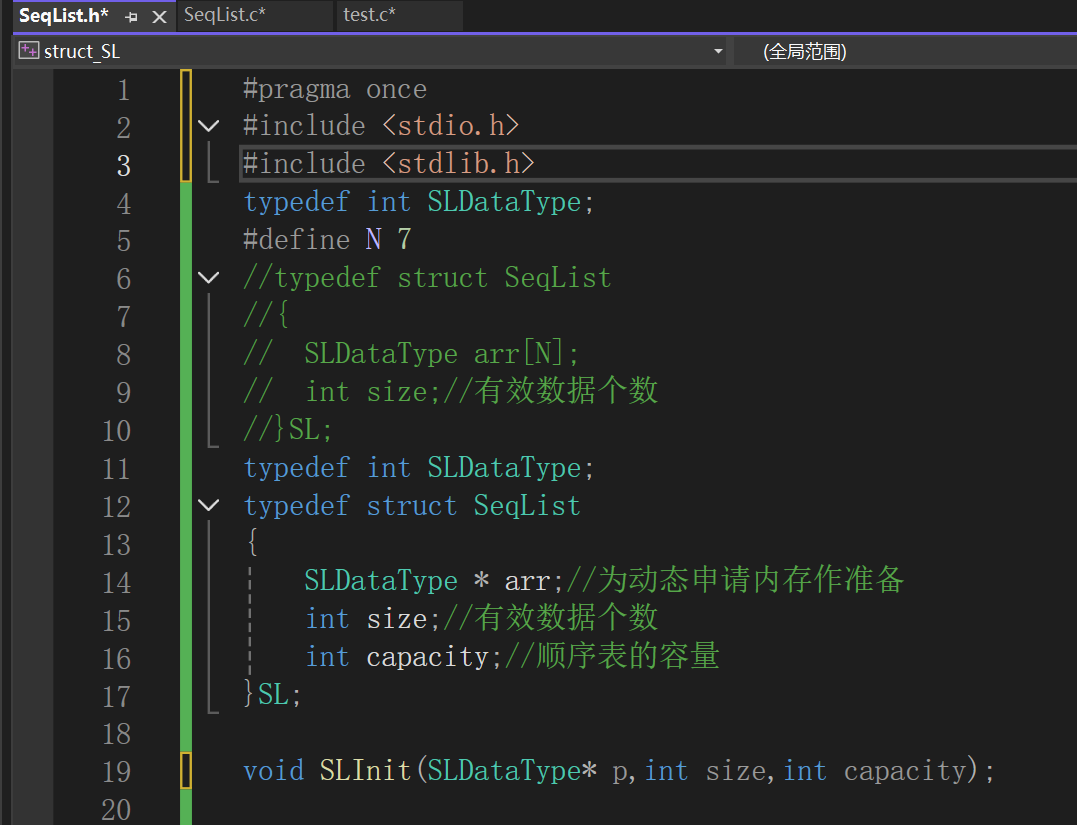
4.动态顺序表的初始化
声明好一个变量做的第一件事就是初始化,创建一个顺序表也是如此:
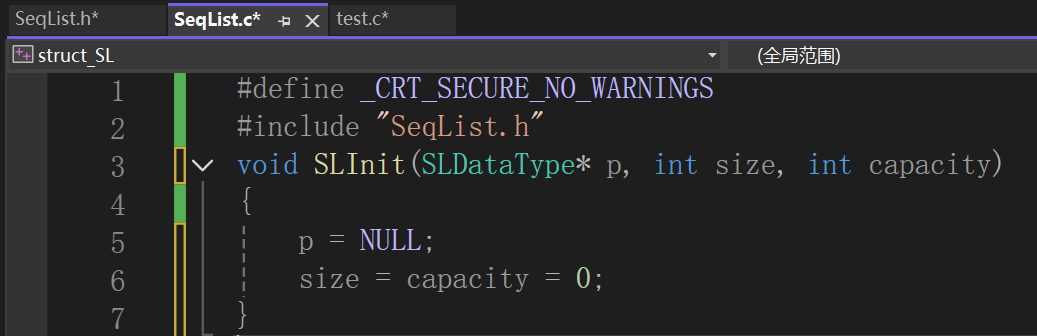
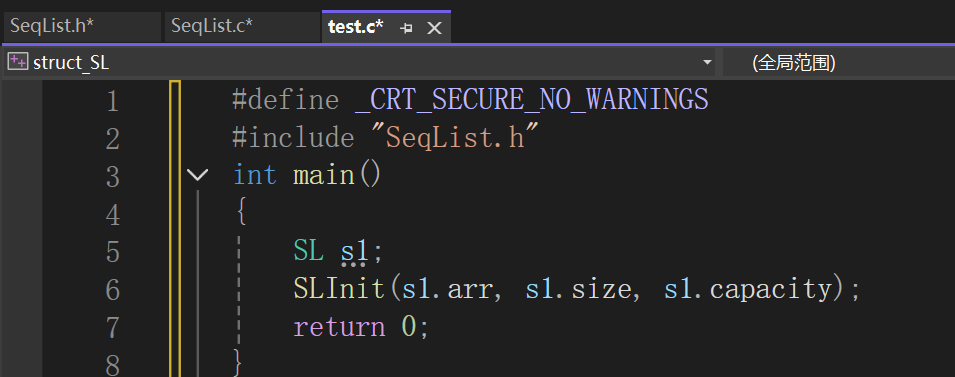
信心满满的写完了,然后:
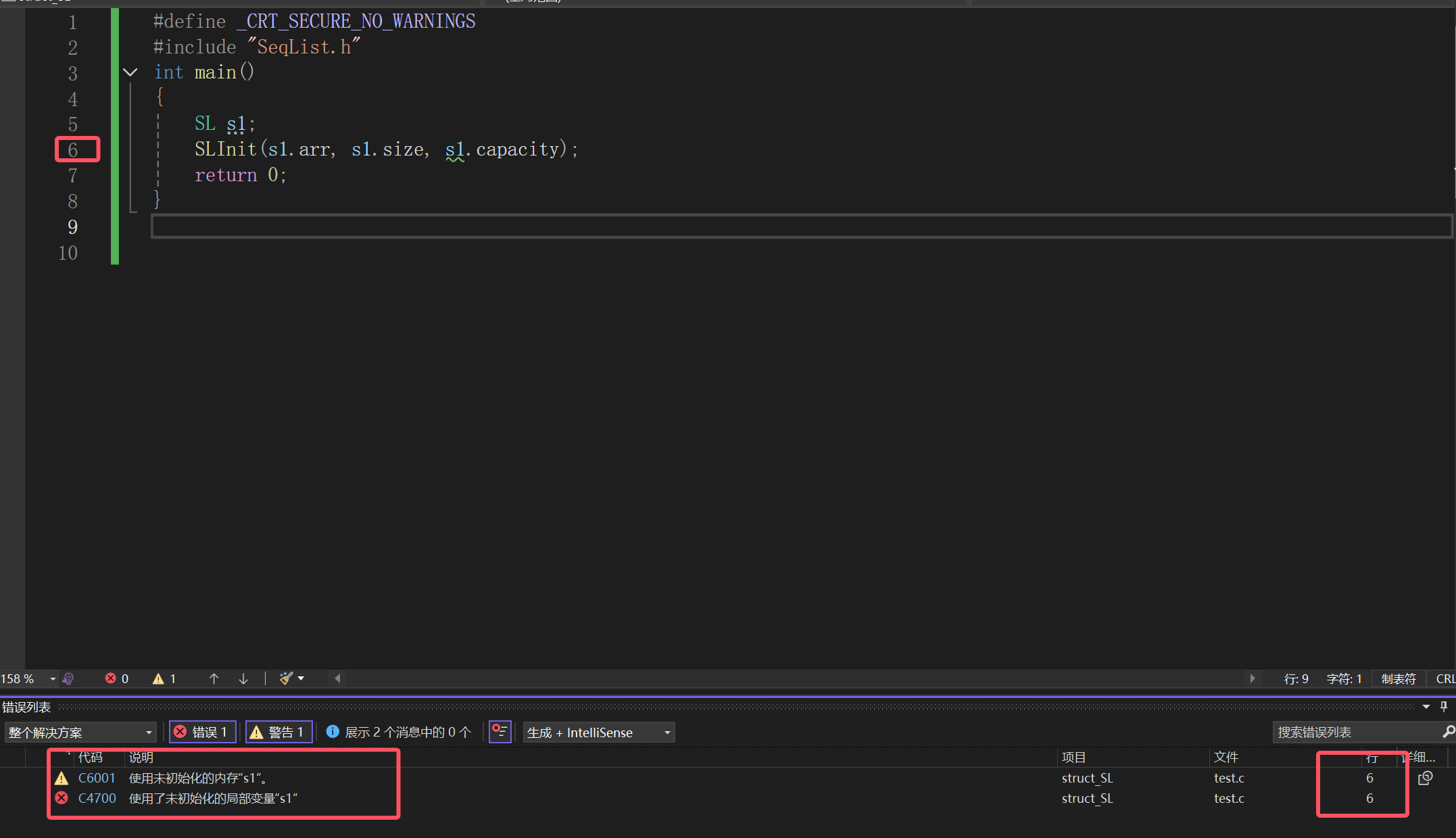
???
你这破计算机犯什么毛病,我已经第六行就是给你初始化去的,你告诉我未初始化干嘛。
其实还是我们之前提过的一个问题,传值调用和传址调用。
传值调用只是对实参的一个临时拷贝,如果仅仅用于计算,无可厚非,但是如果想传值用形参来实现修改实参的话,那还是想想算了。
形参的值不影响实参的值,出了函数还直接没了。
如果相对实参进行修改,那还是传地址过来吧,让我顺着地址给你修改:
又再次复习了一下,这次可就是传值传址调用的实例了,不再是空泛的硬憋出来的例子。
5.顺序表的插入
尾插
比如这样的数据:
想在尾部插入的话得有size吧,知道了size才能知道该插入的位置(即我们想象出来的下标),这块内存空间的起始地址也得有吧,因此,干脆直接像初始化一样,传过来这个顺序表的地址,你想去用这个顺序表哪个成员就用哪个成员,最后另外写出来一个参数,这个参数接收需要插入的元素:

当然,这么写就是错的,顺序表只初始化是没有对应的内存空间的,并没有给这个顺序表申请空间,是不能去赋值的,所以在此之前先怼一个内存开辟,由于考虑到内存可能溢出的问题,所以malloc calloc realloc用realloc,这样如果第一次开辟的内存不够用,可以自主开辟:

realloc第一个参数如果是NULL的话,效果和malloc是一样的,因为需要修改的位置为空,那么就不需要修改,直接开辟即可,返回值仍需检查。
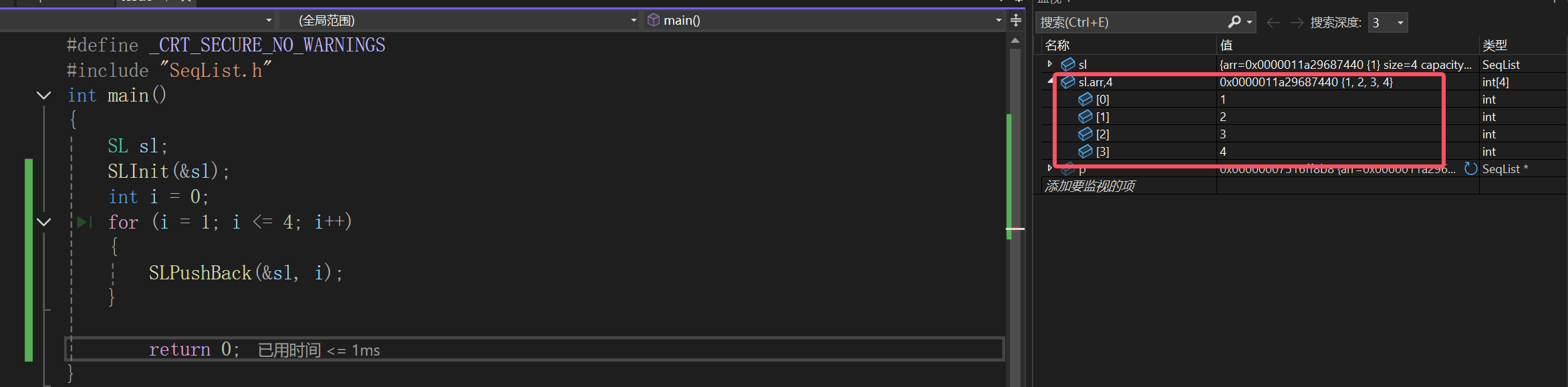
调试结果就是这样的,其实挺简单的。
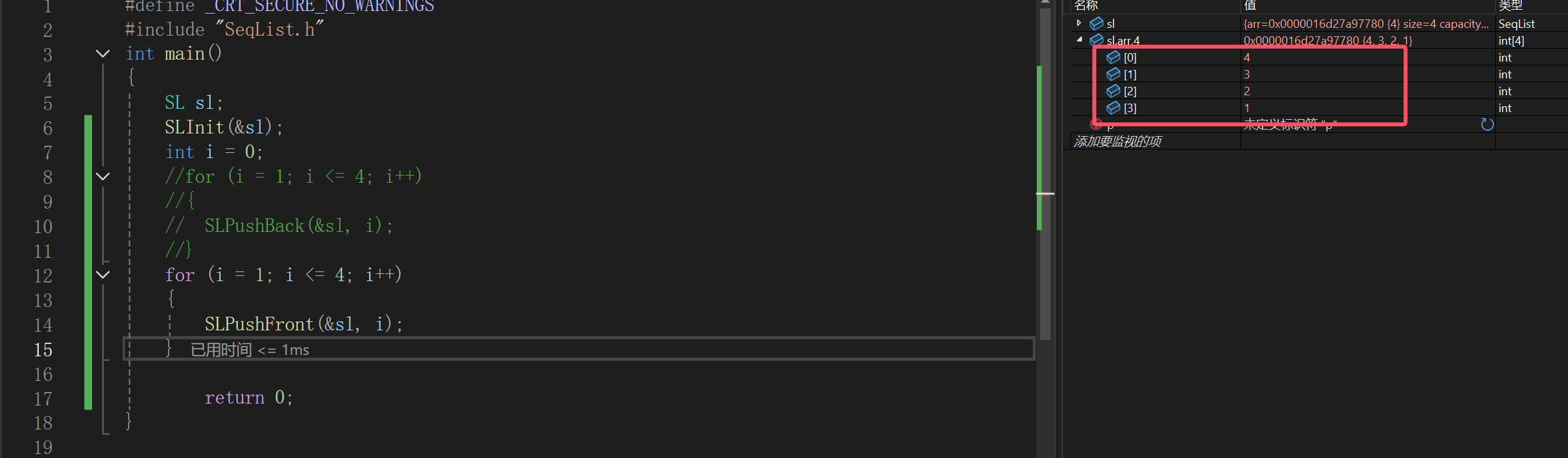
头插
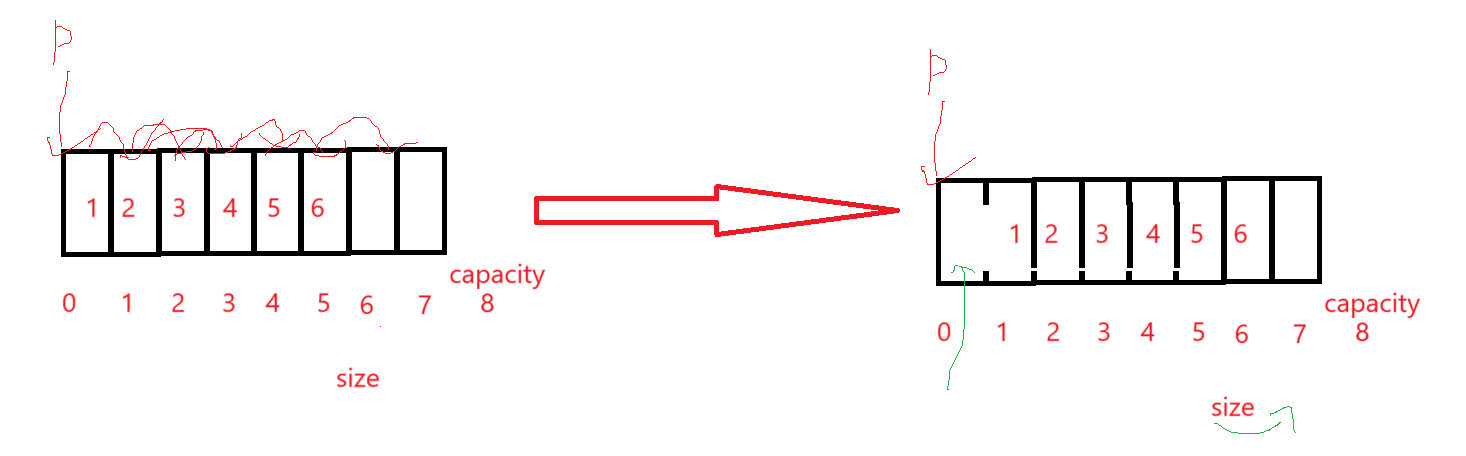
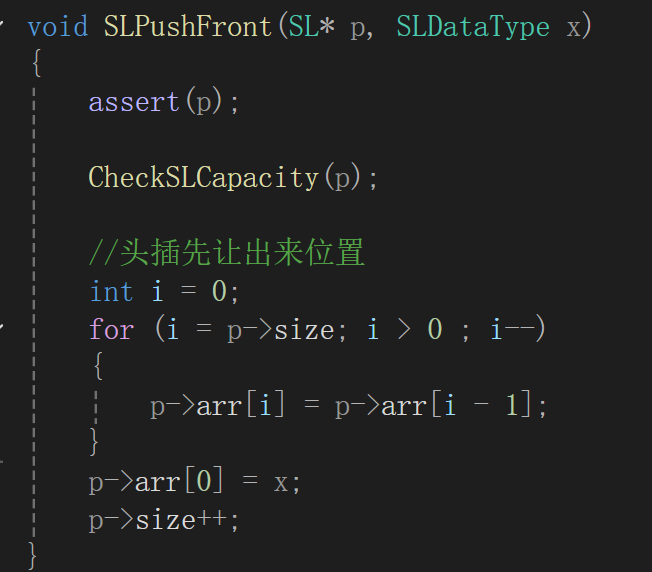
这个有两个要注意的点,一个是头插必须把已有的数据后移,空出来顺序表最前面的位置;后移必后面的先移,不然就会导致数据的覆盖:
最后空出来的赋值就简单了,下面是代码表达:
调试没问题:
指定位置插入
其实如果空想的话,你给我的下标是几,那我就把这个下标开始加上后面的全部都后移,最后在这个位置插入你想插的元素:
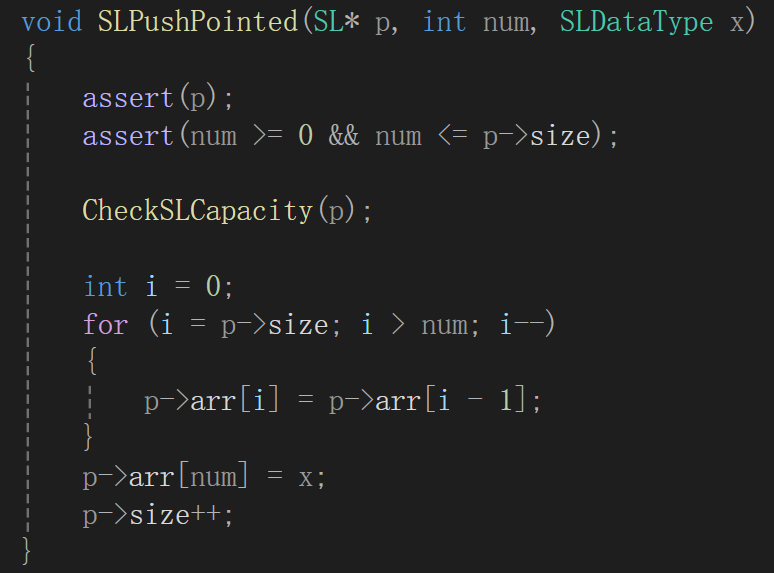
真是服了,写出来一大堆乱码,检查了半天是因为自己在扩容的时候写错了:

我算出来的newcapacity是元素个数,人家realloc要的是字节数,还得乘一下,调试半天。
其它没什么疑问:
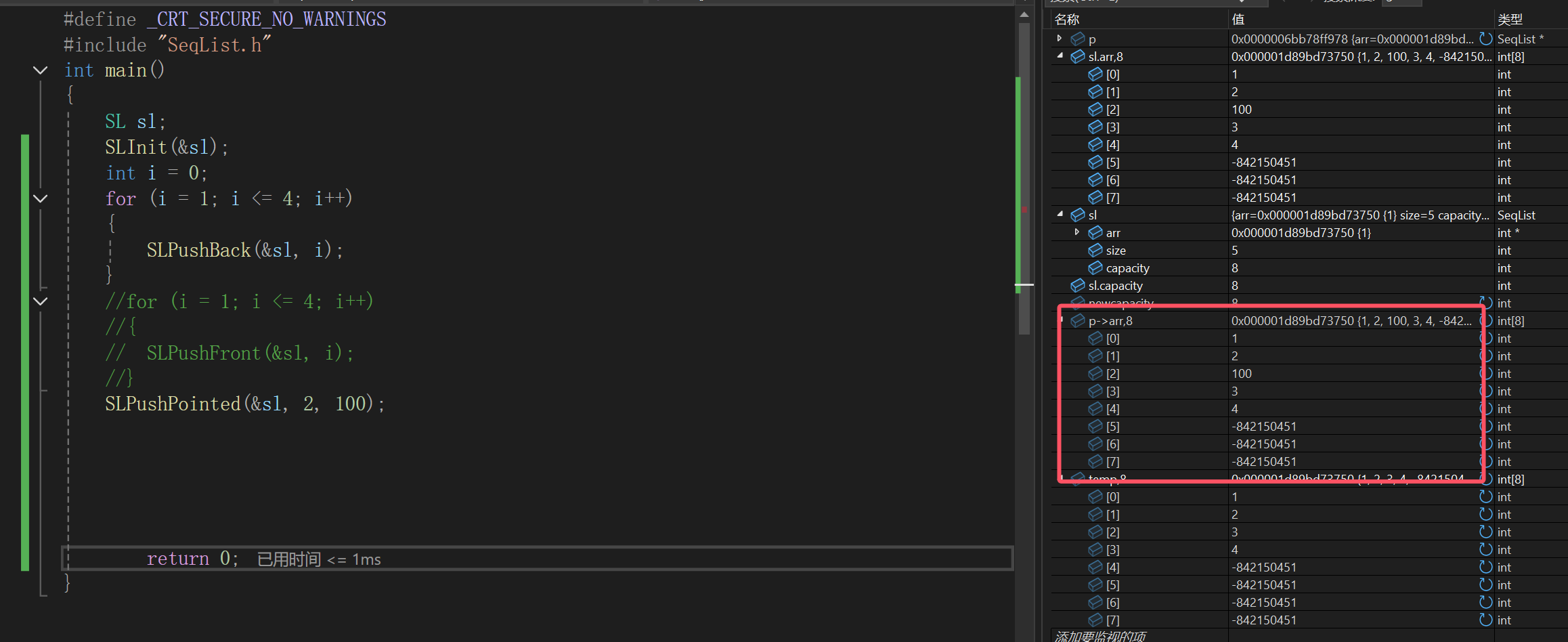
6.顺序表的删除
尾删
直接给出

删除操作,下意识的我们就可能想到,必须把尾部的数据给删除了,但是实际上删除以后难道计算机对于这块位置就不再管了吗?显然不是的,只是变成乱码了而已,假设给上乱码,你不还是得size--嘛,反正也就是为了不再访问顺序表尾部的值,直接size--即可
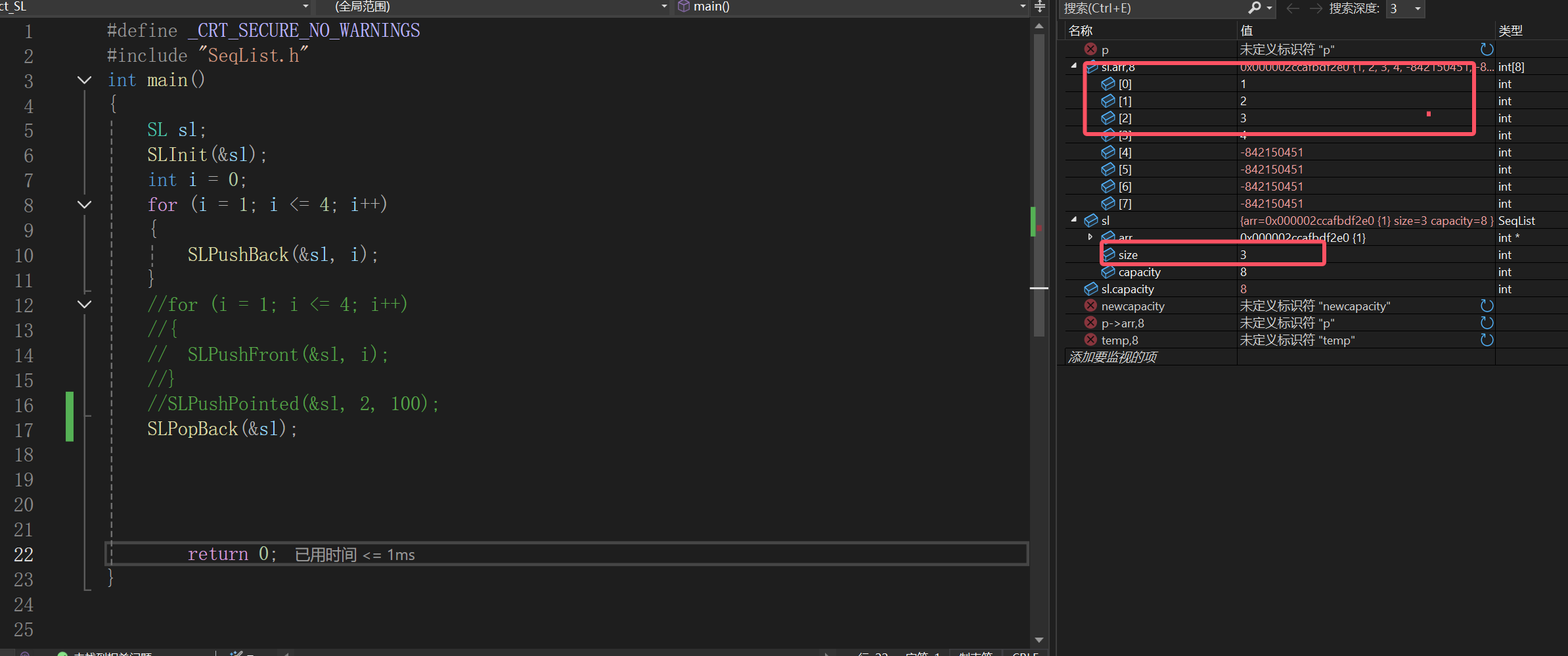
头删
从前往后覆盖即可:
比如这个,就是从2->1,3->2等等即可。
代码表达:

测试:
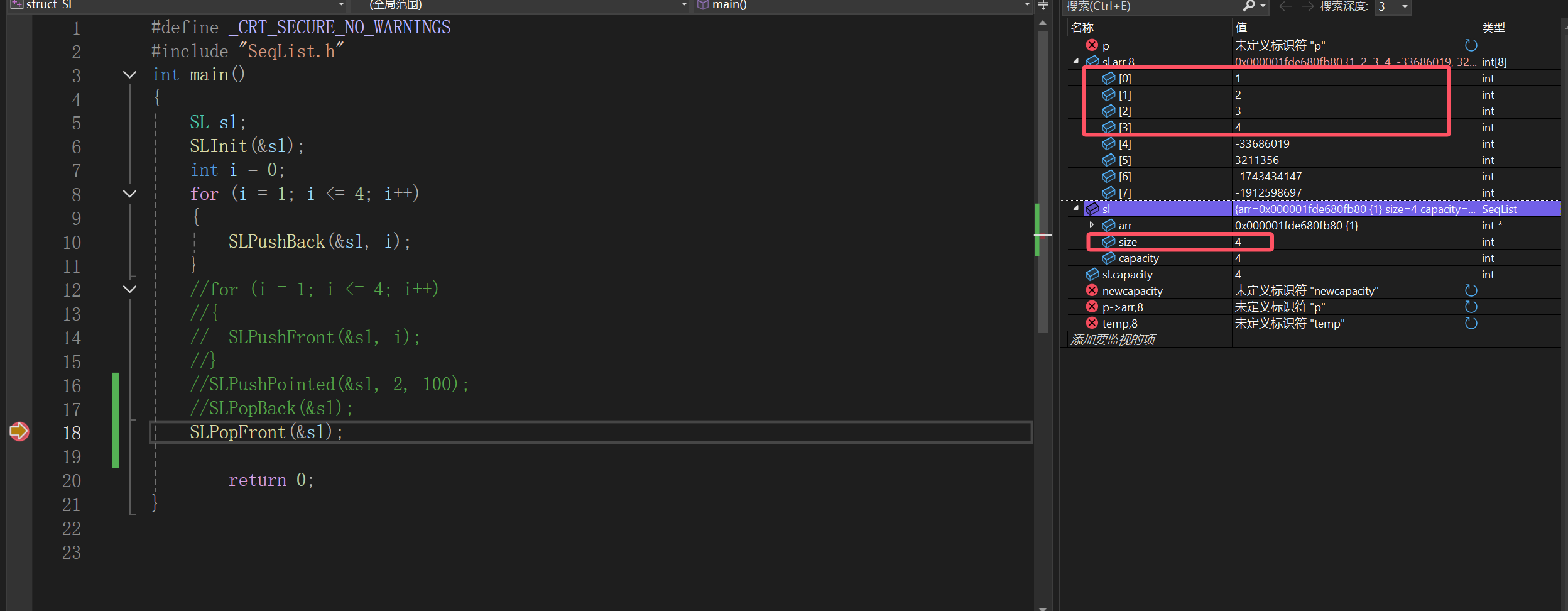
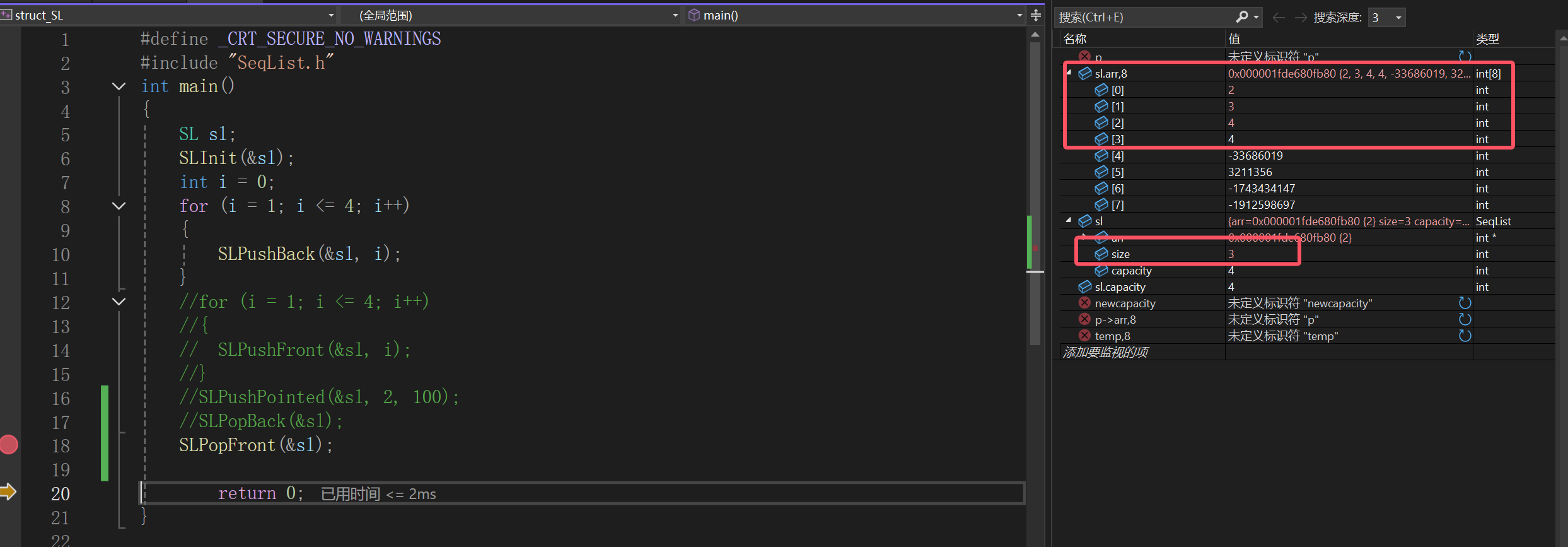
一样道理,即使最后的不删,size为3,不管你做遍历还是插入等一系列操作,都不会被这个值影响。
指定位置删除
类似于头插的前移,只不过与所给位置有关而已:

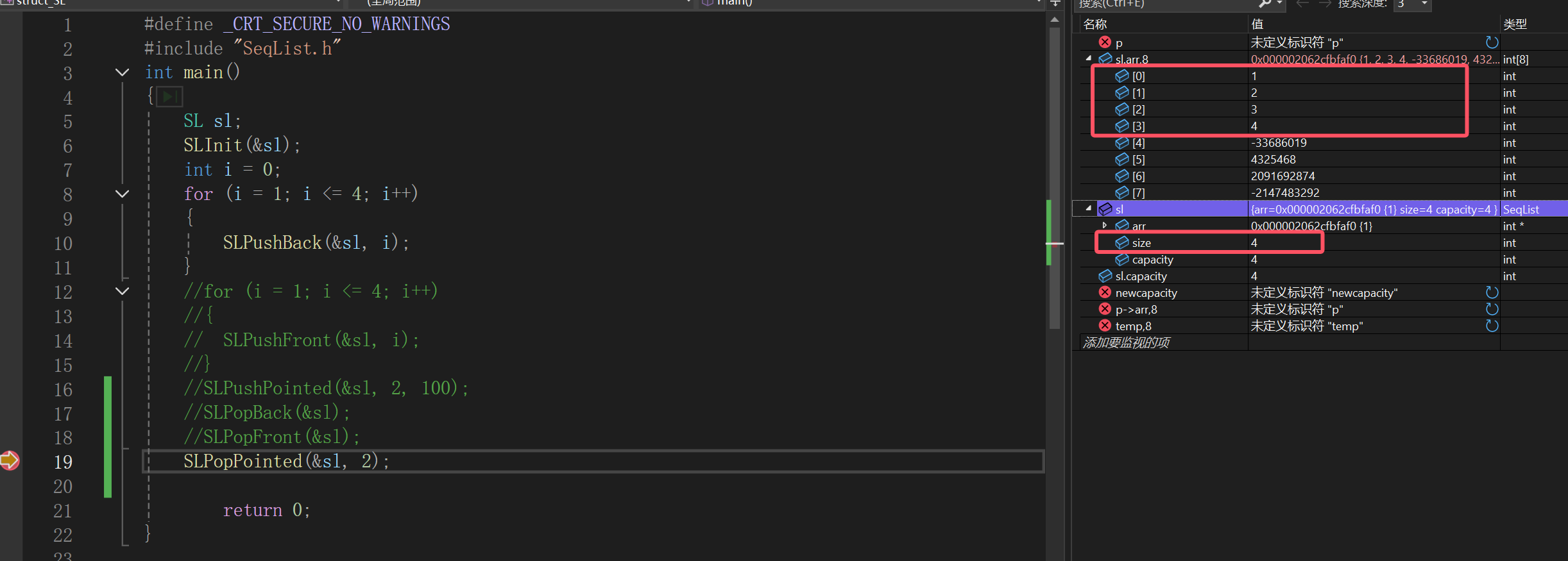
调试:
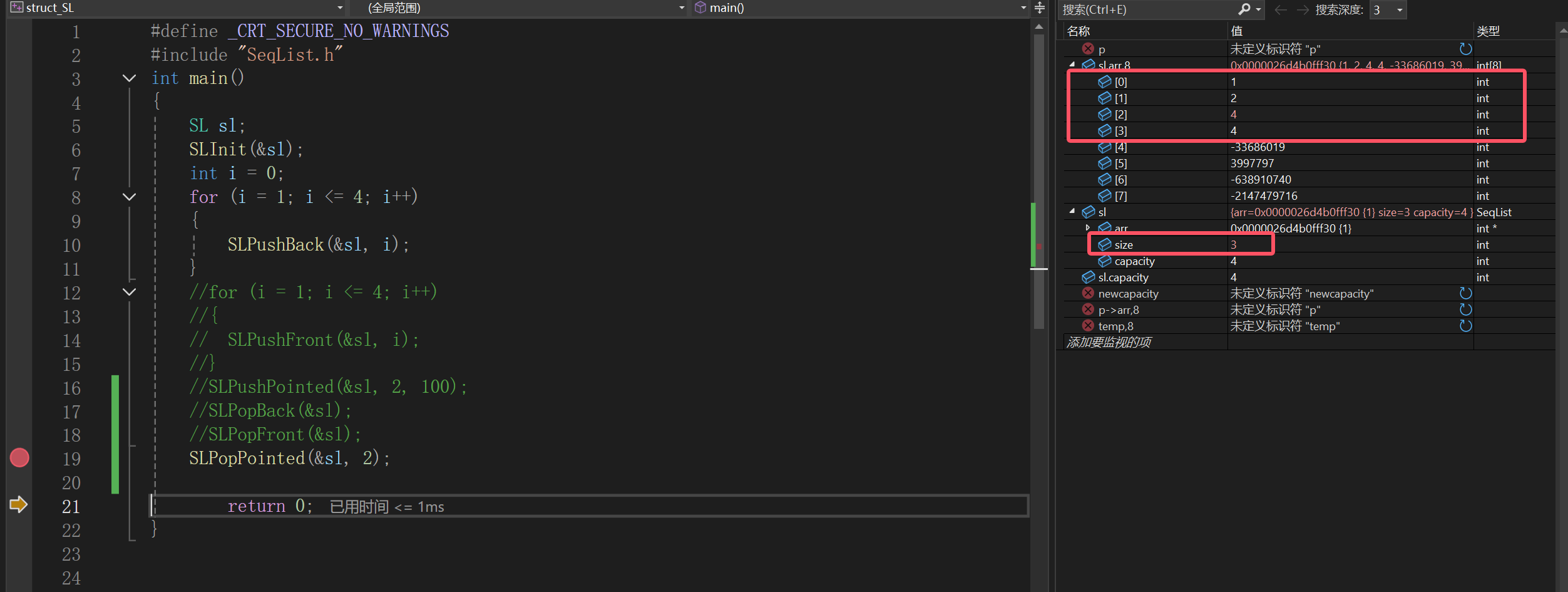
7.顺序表的查找
参数肯定是一个顺序表,一个需要查找的元素,不过这次仅仅是查找,可以传值调用了,毕竟不要求对数据源进行修改,仅仅是对比。

调试: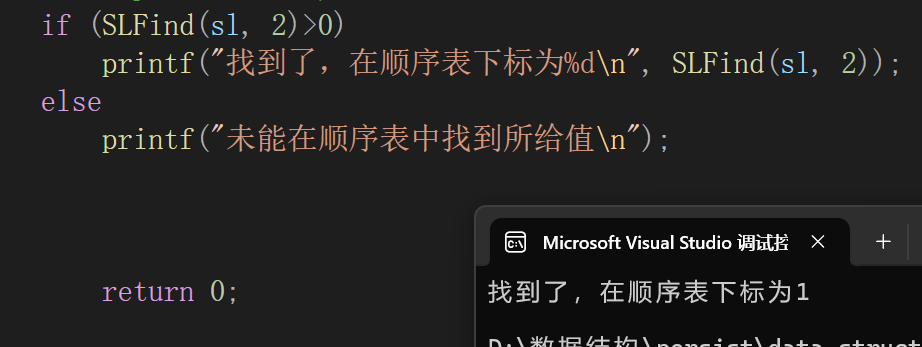

8.顺序表遍历打印
当然,这里只写int类型的遍历:

调试:
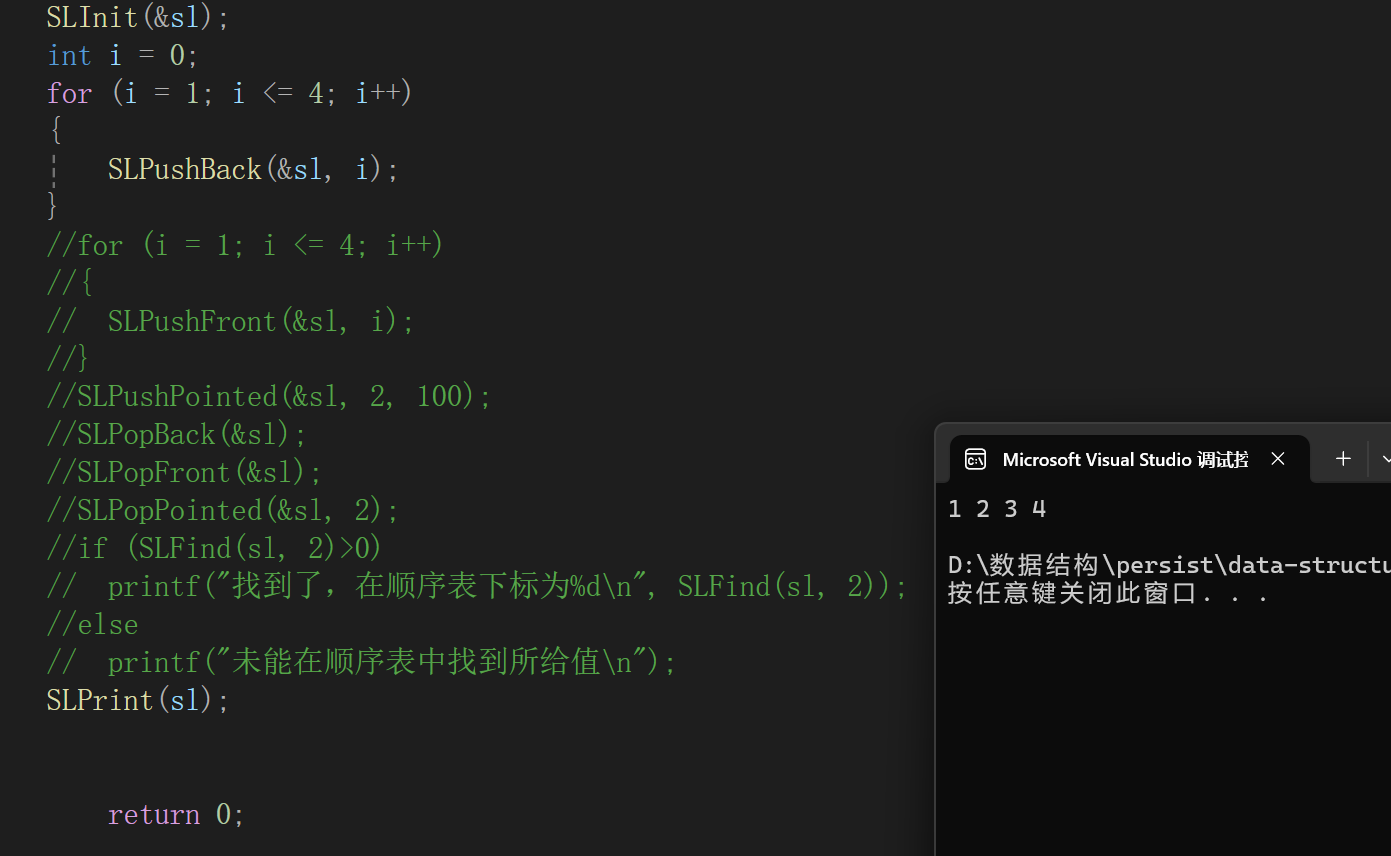
毋庸置疑。
9.顺序表的销毁
如果你写的是局部变量,那就等出了函数系统自动回收空间就算了,但是我们用的最多的是动态顺序表,也就意味着有一块动态开辟的内存空间,碰见这样的事的话,用完了手动给它回收吧,不过我们要给它封装成一个函数:

不用多解释,其实就是调用了个free,最后置指针为空。