Datawhale PyPOTS时间序列5月第1次笔记
课程原地址:
https://github.com/WenjieDu/PyPOTS(Package地址)
https://github.com/WenjieDu/BrewPOTS/tree/datawhale/202505_datawhale(Tutorial地址)
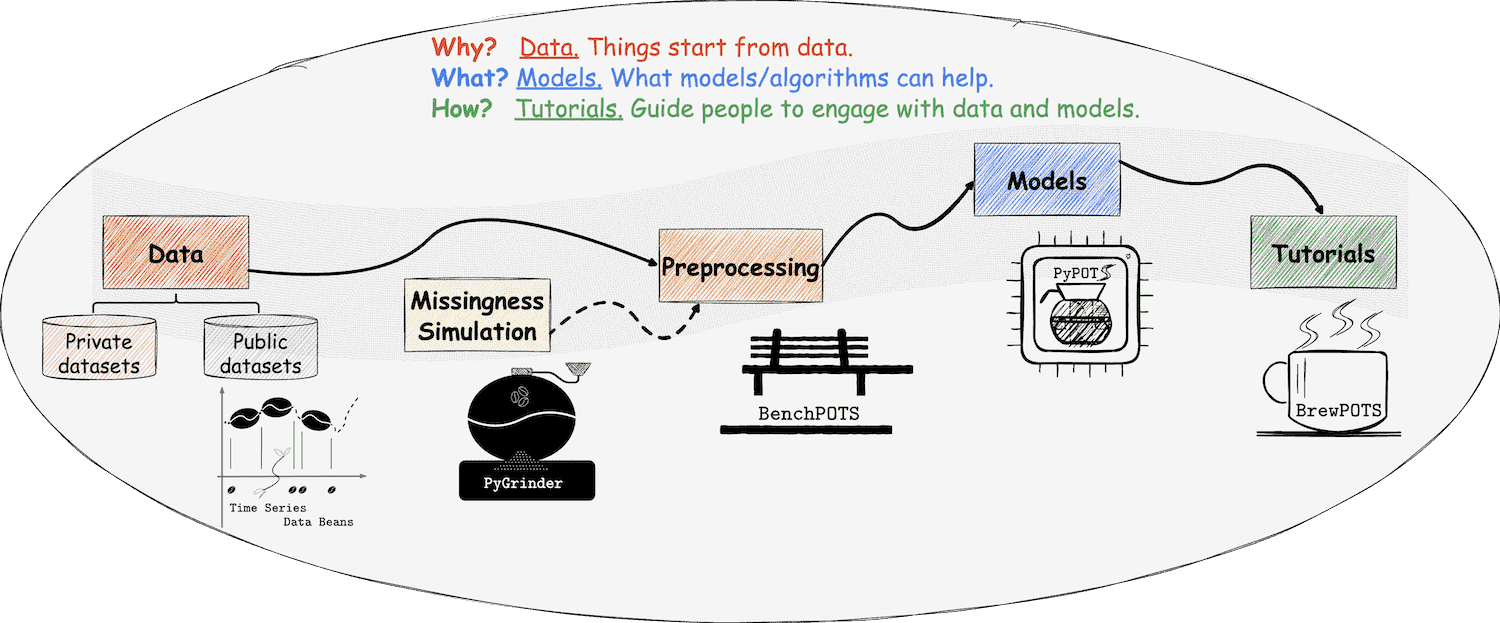
2.1 PyPOTS简介
PyPOTS 是一个专为处理部分观测时间序列(Partially-Observed Time Series, 简称 POTS)而设计的开源 Python 工具箱。在现实世界中,由于传感器故障、通信错误或其他不可预见的原因,时间序列数据中常常存在缺失值。这些缺失值会影响数据分析和建模的准确性。PyPOTS 的目标是为工程师和研究人员提供一个便捷的工具,使他们能够专注于核心问题,而无需过多担心数据中的缺失部分。工程师和研究人员可以通过PyPOTS轻松地处理POTS数据建模问题, 此外PyPOTS会持续不断的更新关于部分观测多变量时间序列的经典算法和先进算法. 除此之外, PyPOTS还提供了统一的应用程序接口,详细的算法学习指南和应用示例。
2.2 PyPOTS 支持的核心任务
PyPOTS 针对带有缺失值的多变量时间序列数据,提供了五大类核心任务支持,几乎覆盖了时间序列数据挖掘的各类典型应用场景。这些任务背后都配备了经过验证的高质量算法,涵盖传统方法、深度学习模型以及概率图模型等。
1. 🧩 缺失值填补(Imputation)
这是 PyPOTS 最重要的功能之一,主要目标是在数据中存在缺失的情况下,最大程度恢复原始信号。PyPOTS 实现了超过 12 种填补算法,既有传统方法,也有现代深度学习模型:
-
传统方法:
- 前向填充(Forward Filling)
- 后向填充(Backward Filling)
- 线性插值(Linear Interpolation)
-
深度学习方法:
- SAITS(Self-Attention based Imputation for Time Series):PyPOTS 自主实现的 Transformer 风格模型;
- BRITS:基于双向 RNN 的填补方法,兼顾因果一致性;
- GRU-D:引入时间衰减机制,特别适合处理医疗场景;
- MRNN、CSDI、Transformer-Denoising Autoencoder 等
-
概率模型:
- BTTF(Bayesian Temporal Tensor Factorization):使用贝叶斯推断的张量分解方法,适合建模数据不确定性。
这些方法可根据数据特性灵活选择,并通过统一接口进行调用和评估。
2. 🔮 预测(Forecasting)
PyPOTS 支持基于不完整观测值的序列预测任务。在训练时可以同时学习时间依赖性和缺失机制。支持的模型主要有:
- Impute-then-Forecast 方法链:先填补再进行预测(支持组合 SAITS+LSTM 等);
- 端到端预测模型:如 Transformer 与 GRU 基模型;
- 与 Benchmark 模块结合,支持将任何模型进行标准化评估。
目前框架内已集成了多种典型预测结构,并可与填补模块无缝连接。
3. 🏷️ 分类(Classification)
对于需要将时间序列分为不同类别的任务(如疾病分类、用户行为识别等),PyPOTS 提供了适配部分观测数据的时间序列分类器:
- 基于 RNN、Transformer 的深度分类模型;
- 可结合填补模块预处理后的数据进行分类;
- 支持多任务学习,将分类与预测或填补结合。
目前至少支持 5 种深度分类结构,同时提供高扩展性,便于接入外部分类器。
4. 🧭 聚类(Clustering)
聚类任务在探索性分析中非常重要,PyPOTS 提供了处理缺失值时间序列聚类的支持:
- 填补 + 聚类:先使用 SAITS 等模型填补缺失,再进行 K-Means、DBSCAN 等聚类;
- 特征提取 + 聚类:通过 Transformer 等模型提取潜在特征后进行聚类;
- 支持对比学习风格的时间序列表示学习,用于后续聚类。
该模块提供标准化聚类评估指标,如 Silhouette Score、NMI 等。
5. ⚠️ 异常检测(Anomaly Detection)
异常检测主要用于识别时间序列中不符合正常模式的行为,PyPOTS 可处理带缺失的异常检测任务:
- 填补 + Reconstruction-Based 方法:如使用自动编码器重构序列,比较原始与预测误差;
- 基于统计的方法:结合滑动窗口与动态阈值;
- Transformer-based 模型:学习时间依赖与异常模式,例如结合 CSDI 等模型进行异常点估计;
- 可与 BenchPOTS 一起评估各类异常检测算法的性能。