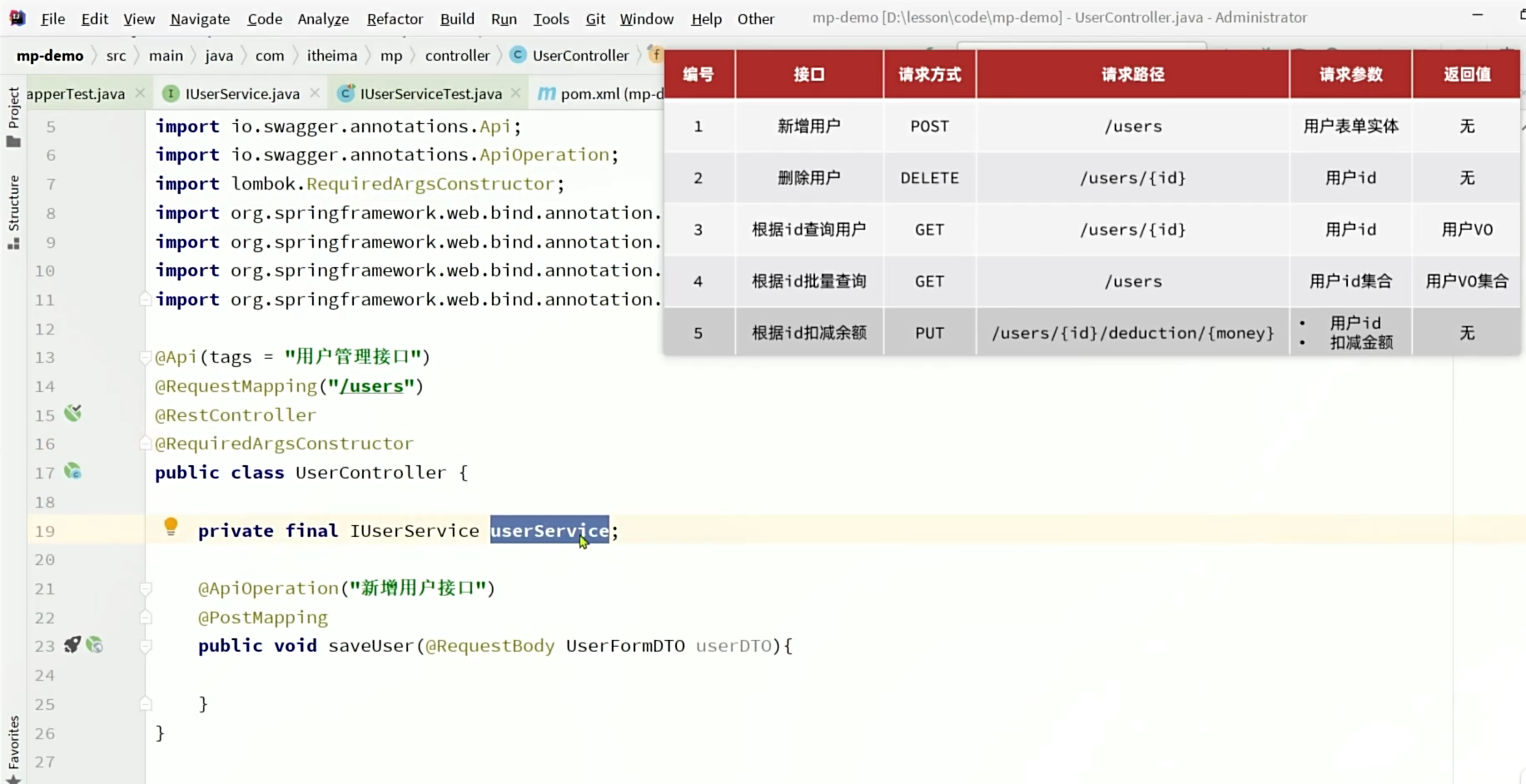
Mybatis-plus
目录
1、MybatisPlus入门
1、MP入门案例
2、MP常见注解
3、MP常用配置
2、MP核心功能
1、条件构造器(如果不是按id来处理呢?)编辑
QueryWrapper相关(构建select、delete、update的where条件部分时使用)
UpdateWrapper相关(在set语句比较特殊时使用)
2、自定义SQL
3、Iservice接口基本用法
4、Iservice开发基础业务接口
5、Iservice开发复杂业务接口(具有业务逻辑时)
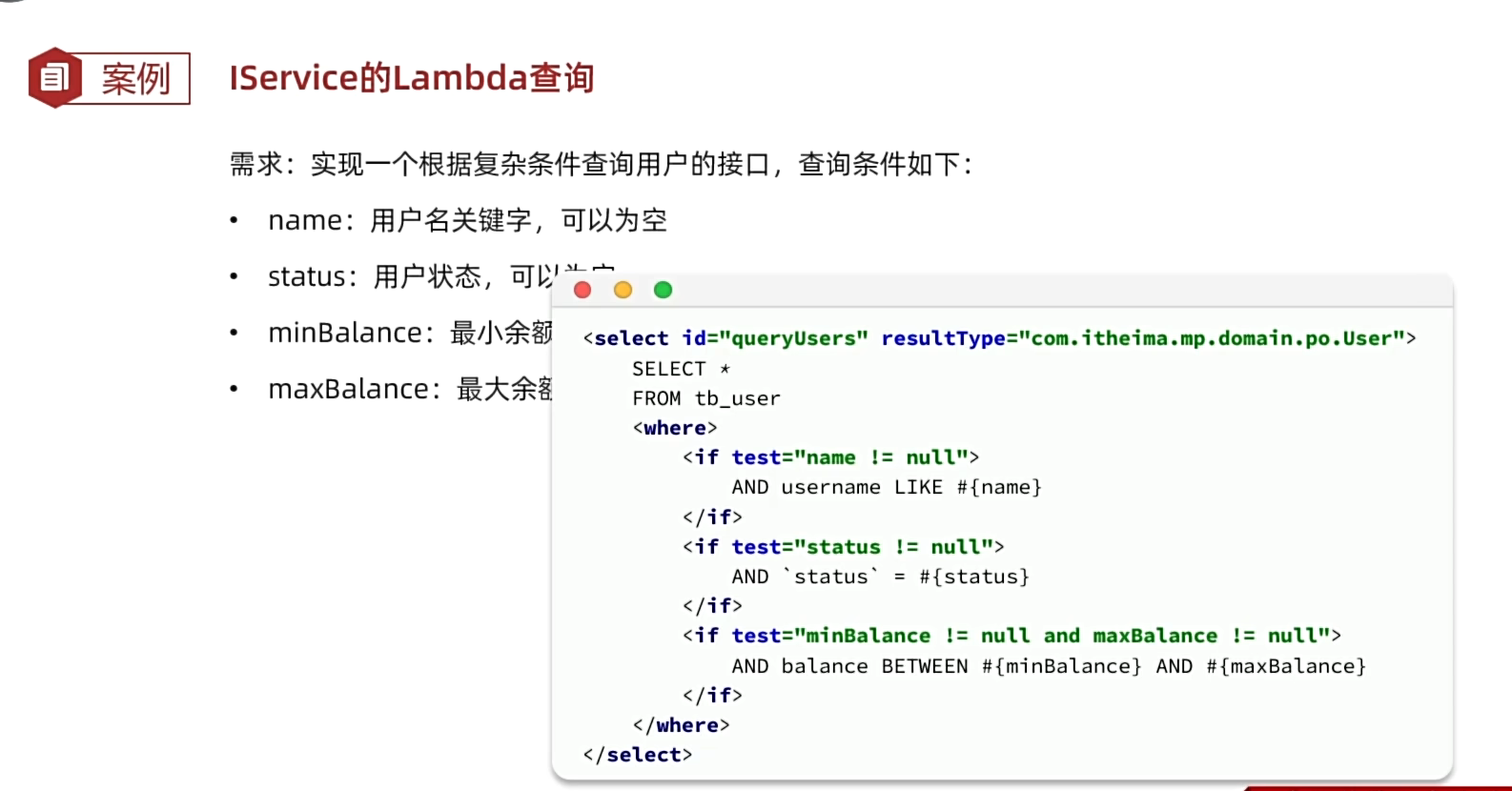
6、Iservice的Lambda查询(当业务逻辑很复杂时用Lambda,复杂查询LambdaQuery和复杂更新LambdaUpdate)
使用Iservice的Lambda查询完成以下SQL语句。(复杂查询)
新问题(复杂更新)
7、Iservice的批量新增
普通for循环对大量数据插入
使用MP自带的批处理
3、MP的拓展功能
1、代码生成(一个插件)
2、静态工具(避免循环依赖用的)
3、逻辑删除(不推荐,会导致内容堆积)
4、枚举处理器
5、JSON处理器
6、分页插件
通用分页查询
通用分页实体与MP转换(优雅)
一些疑惑:
1、ID自增有什么问题?UUID为啥不行?雪花算法的优点、缺点?如何避免缺点?
2、为什么没有 @Mapper 注解的接口会被注入到 IOC 容器
3、通过构造函数注入Bean对象
4、为什么 IService 的 lambdaQuery 能直接返回结果而不用调用 Mapper
1. 内部封装了 Mapper 调用
2. 链式调用最终会触发 Mapper 查询
3. 查询执行流程
4. 与直接使用 Mapper 的区别
5. 设计优势
5、mybatis怎么处理枚举字段的?
1. 默认枚举映射(无需配置)
2、使用注解简化配置(MyBatis 3.4.5+)
3、枚举与动态 SQL
6、 那为什么需要在返回值前写泛型呢?
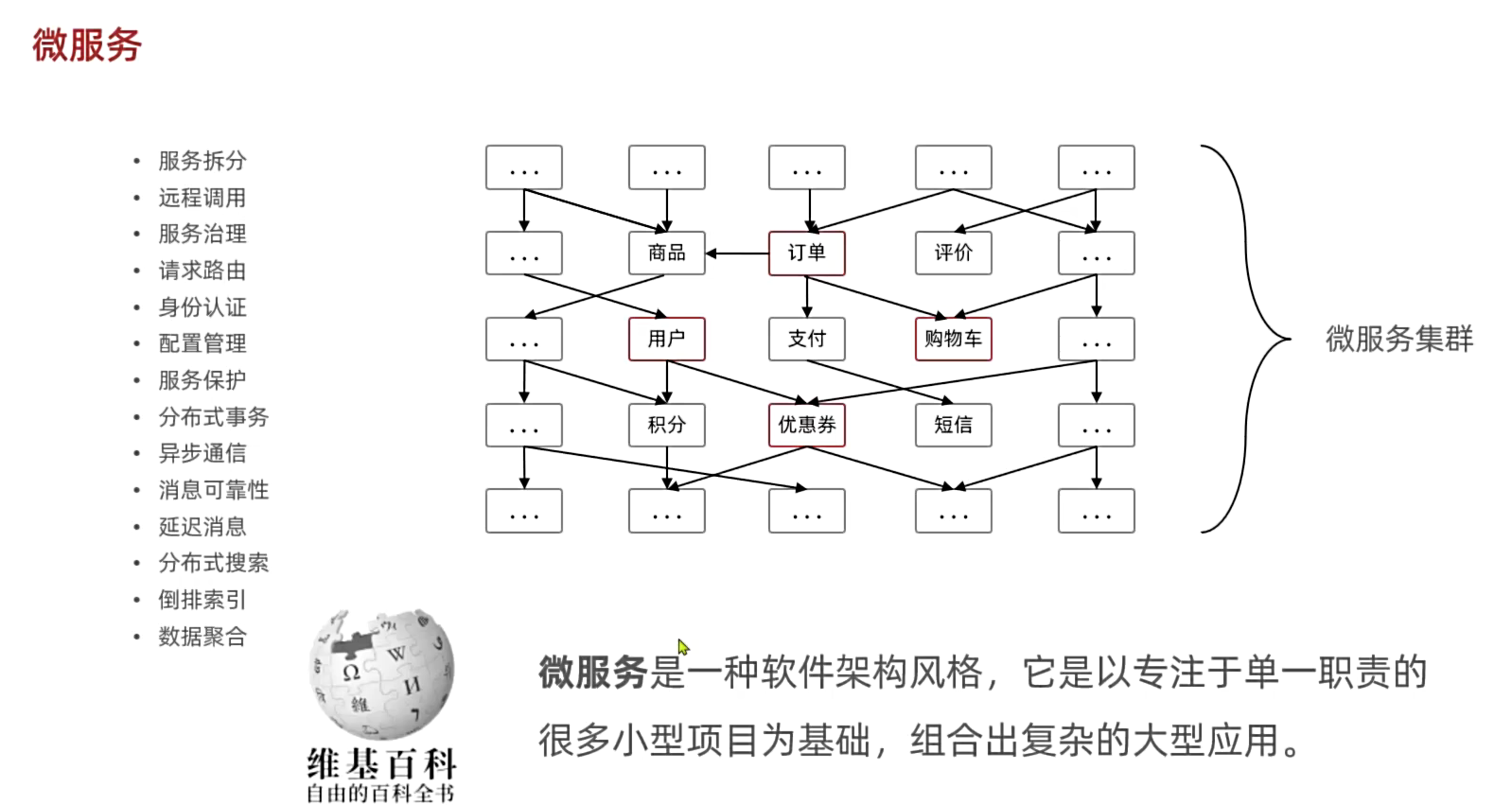
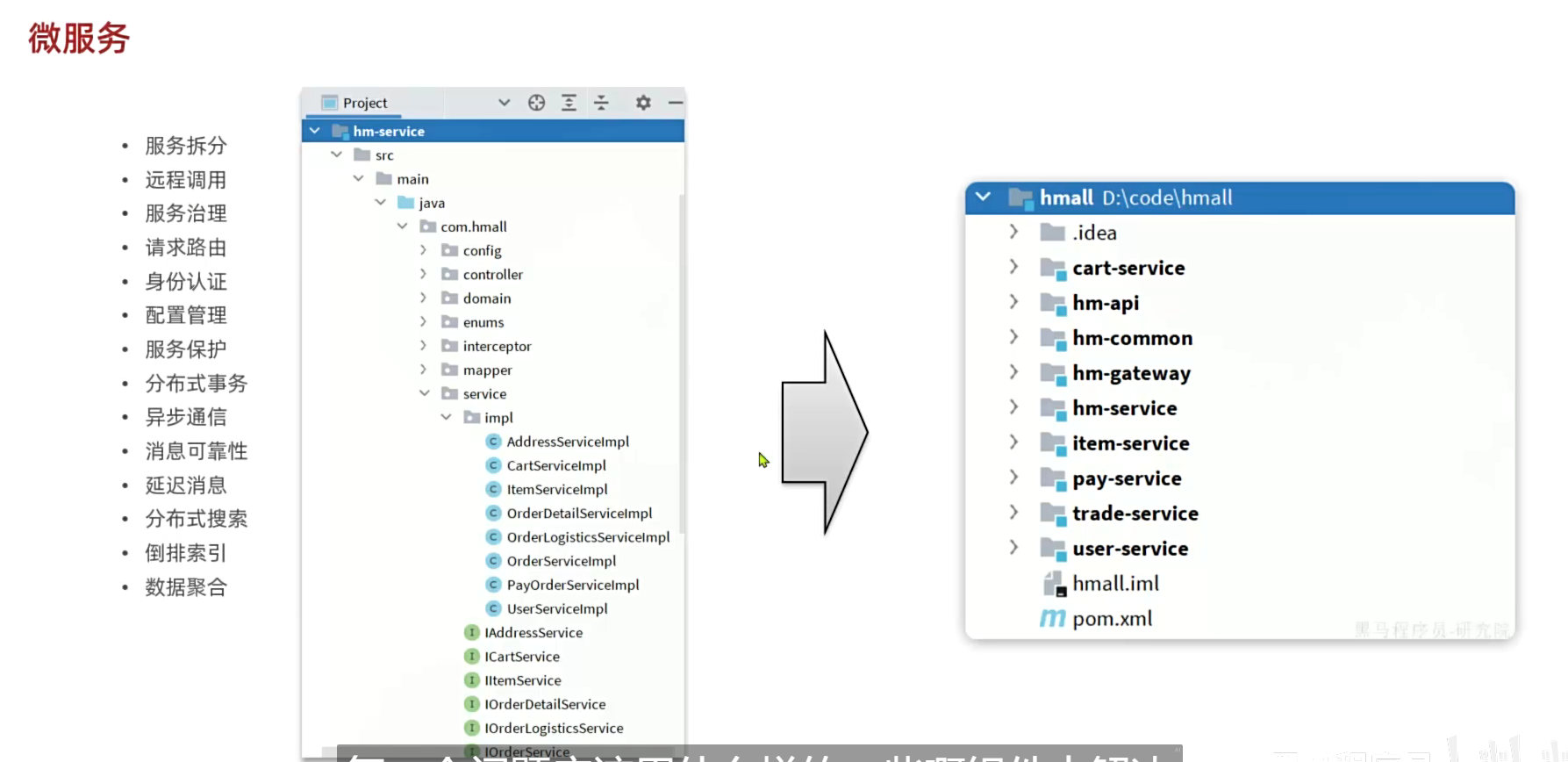
学习将一个单体项目逐步拆分成微服务。
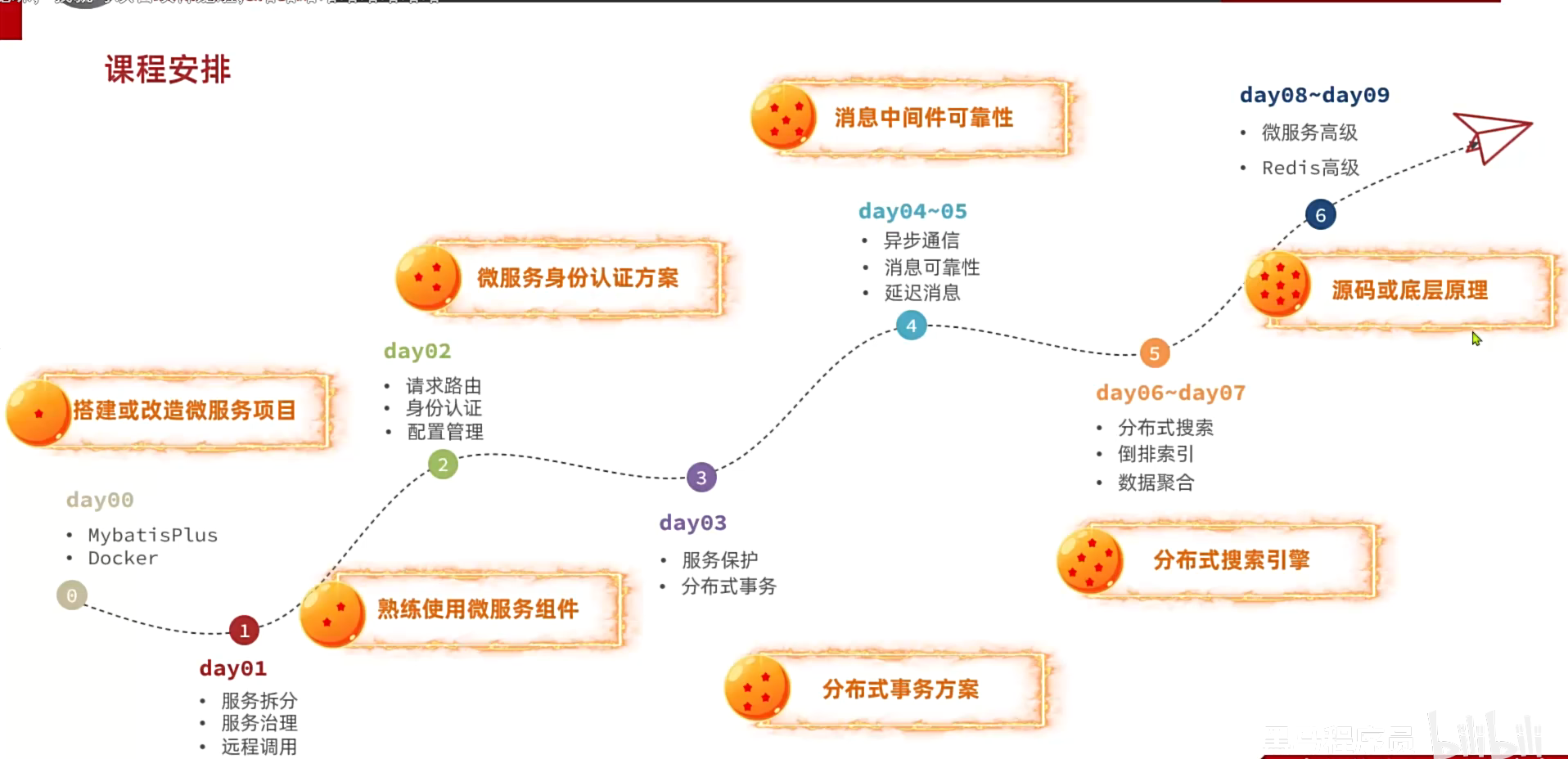
学习路径:
1、MybatisPlus入门
mp对Mybatis是无侵入的,并且MP可以简化Mybatis。很显而易见,如果我们要写update语句,那么Mybatis的if test判断语句会很多,但是如果使用mp可以智能的判断。
1、MP入门案例

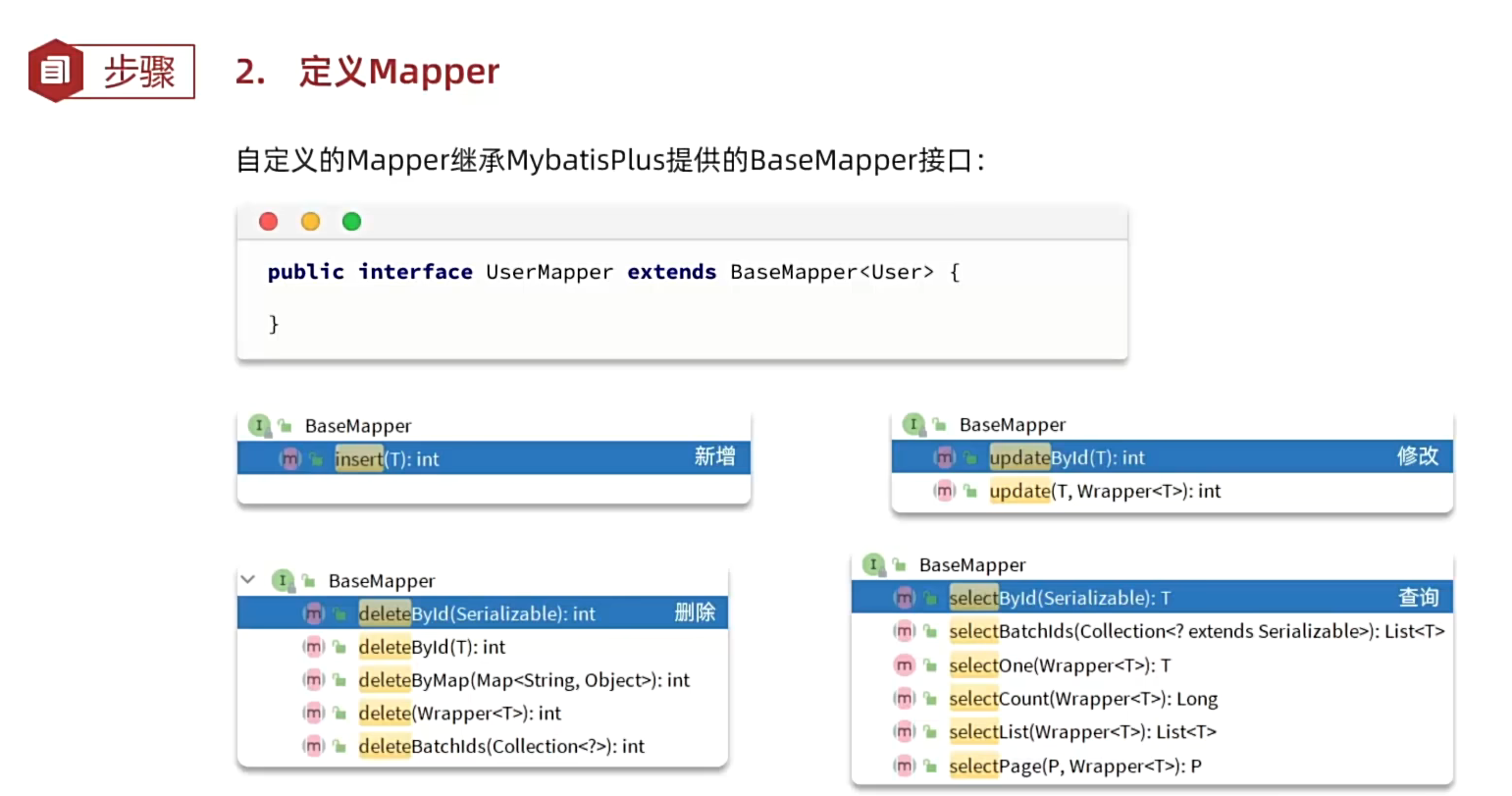
具体实现:
注意在继承BaseMapper<T>时要指定泛型,T为要操作的实体类。

注入Bean对象:

使用:

2、MP常见注解
MP是怎么知道该去操作哪个表?怎么操作表的呢?答:根据匹配规则,约定大于配置!只要你能遵守约定,那么mp就能通过反射得到实体类的信息,从而得知表的信息。
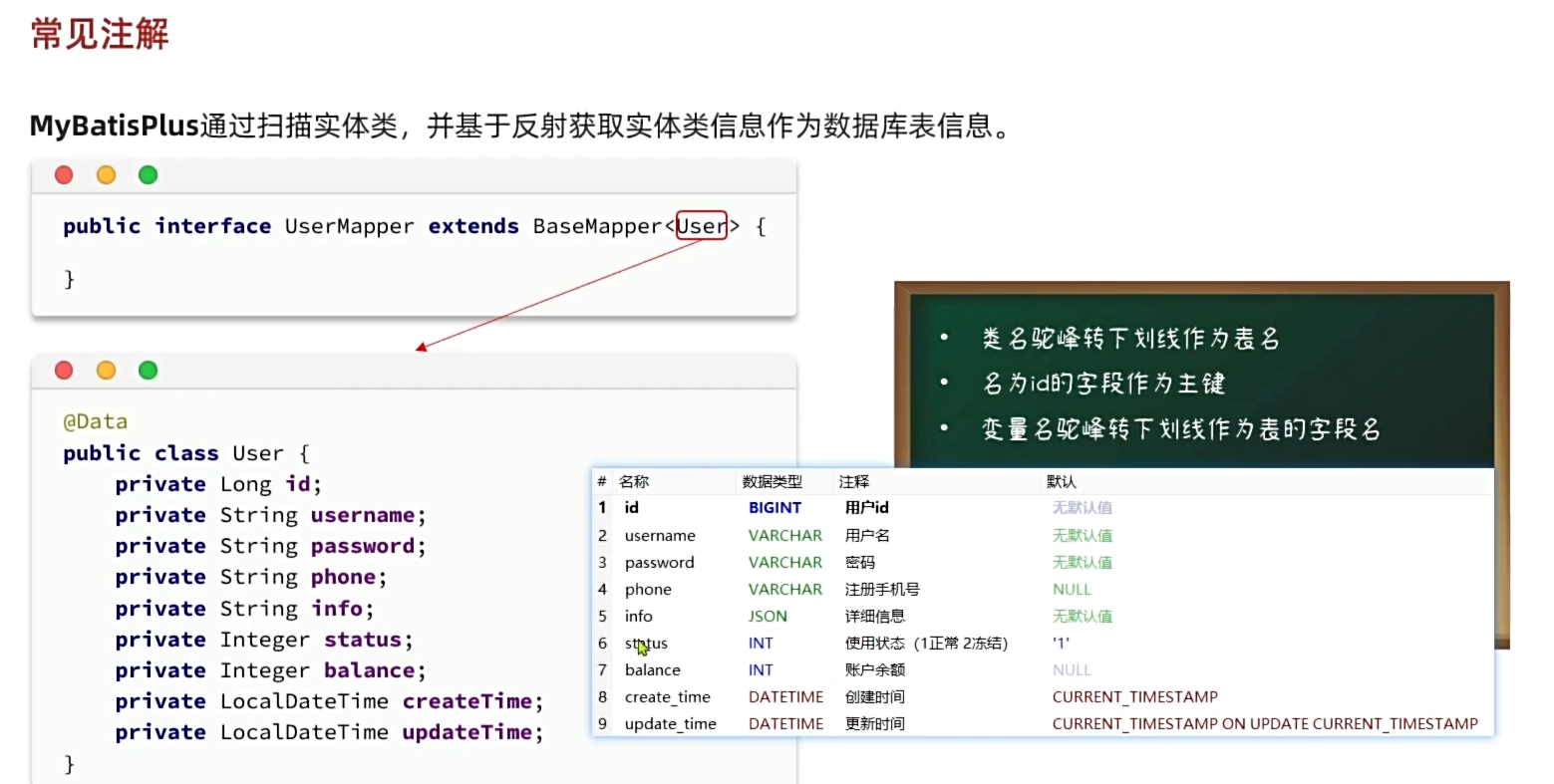
如果实体类和数据库数据约定不一致呢?那我们就需要通过注解去指明对应表的信息。
TableId
可以指明为雪花算法,让mp帮我们填id,这样分库分表时就有优势(默认就是雪花算法)。也可以选择set方法自己填,或者选Auto让数据库填。
TableField
驼峰转化后名称不一致要用TableField重新命名。
可以指定名称,注意要是成员变量是is开头且是布偶值时一定要加,因为MP会把is去掉。
与关键字冲突时加''转义字符来指定名称。
非数据库字段时通过exist指明非必须。


3、MP常用配置
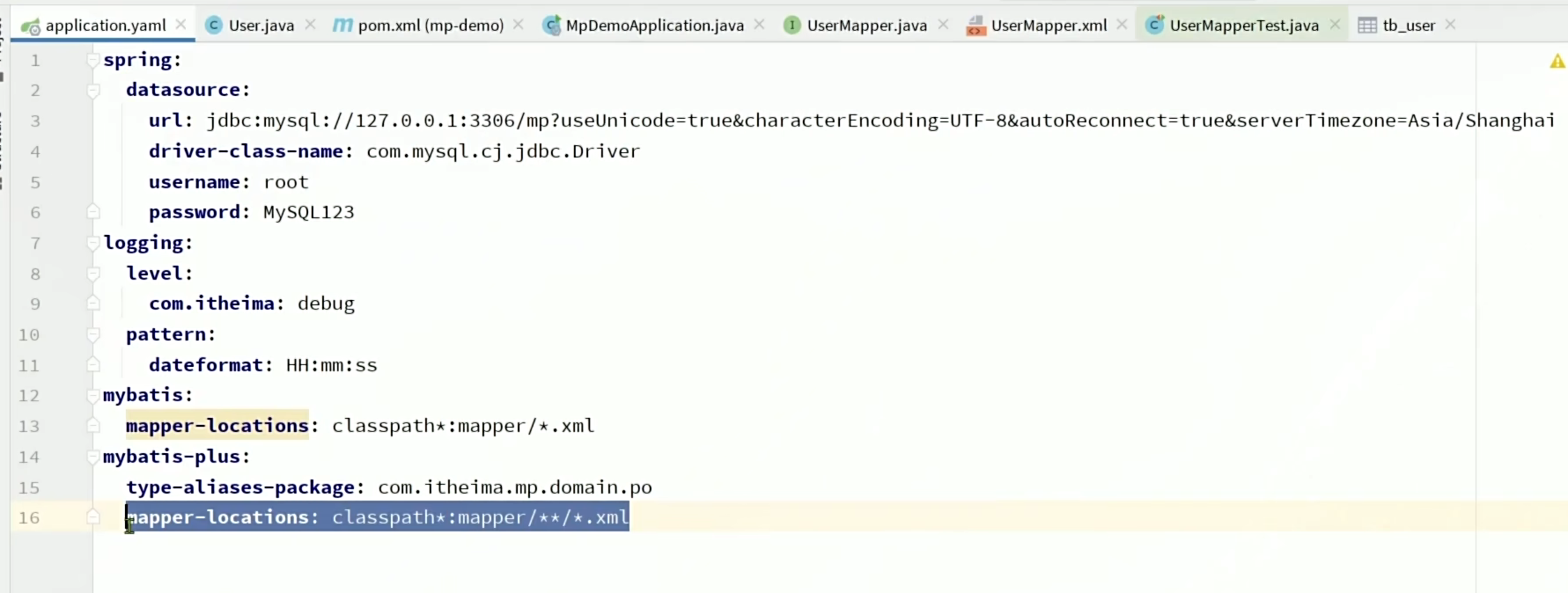
MP同样是支持xml文件的,MP适用的场景是单表操作,如果是复杂的操作还是要写在xml文件中。通过mapper-location指明xml文件位置。

MP的mapper-locations更强大,它写的mapper/**/*.xml可以扫描mapper下除xml文件外的子文件。
2、MP核心功能
1、条件构造器(如果不是按id来处理呢?)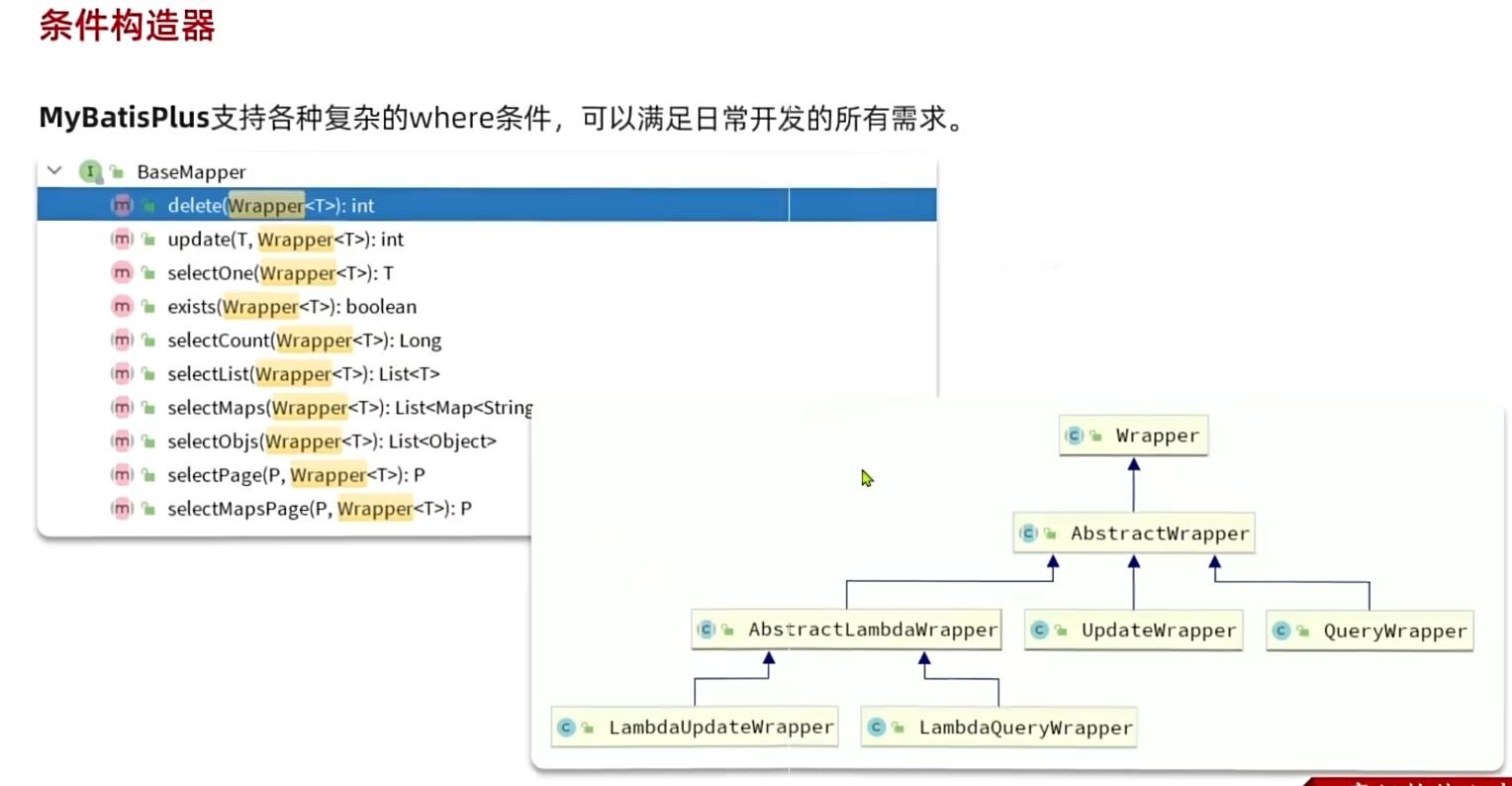
QueryWrapper相关(构建select、delete、update的where条件部分时使用)
原SQL语句: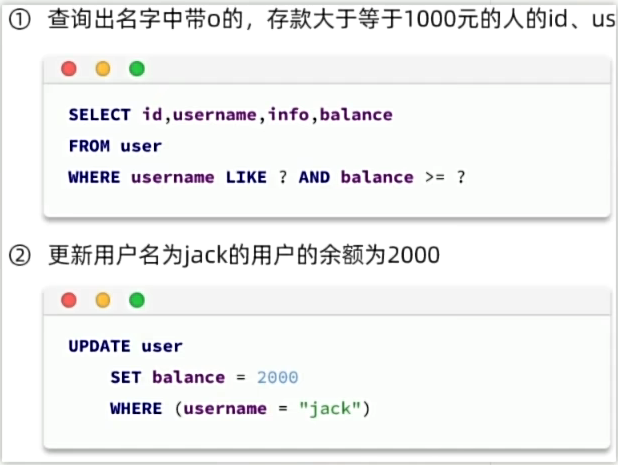
通过MP简化后的SQL语句:
注意由于update更新的是查询出来的语句,所以使用Querywrapper先实现查询。


UpdateWrapper相关(在set语句比较特殊时使用)
原SQL语句:
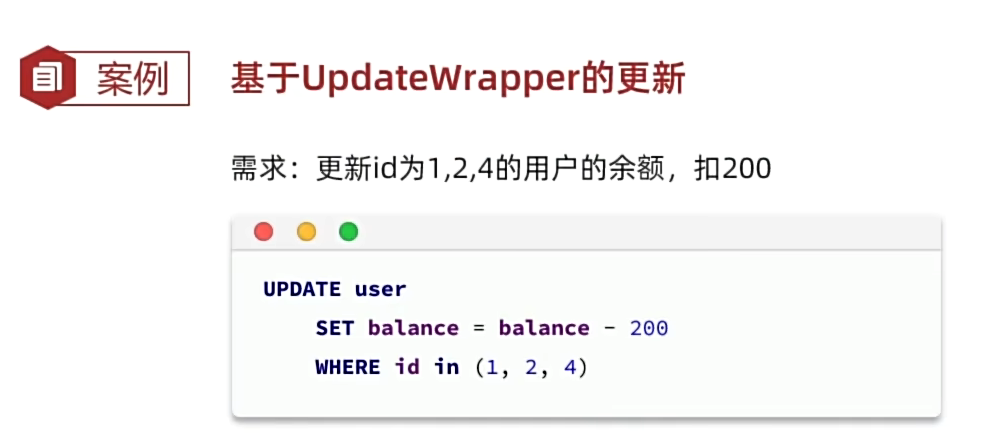
MP精简后的:

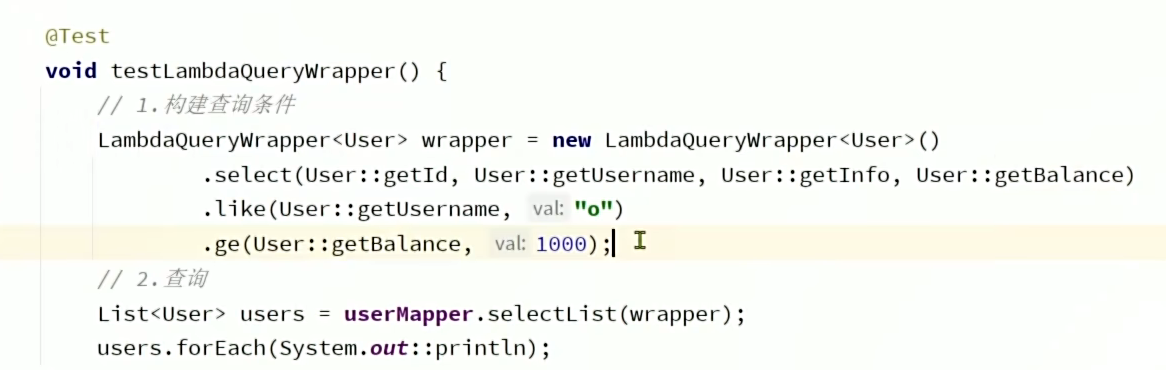
以上两种属于硬编码,它把字段部分写死了。避免这种情况可以使用属lambda的条件构造器。这样当实体类发生字段修改时,它不会因为定死的字段而报错。具体实现就是将字段改成User::getId这种。

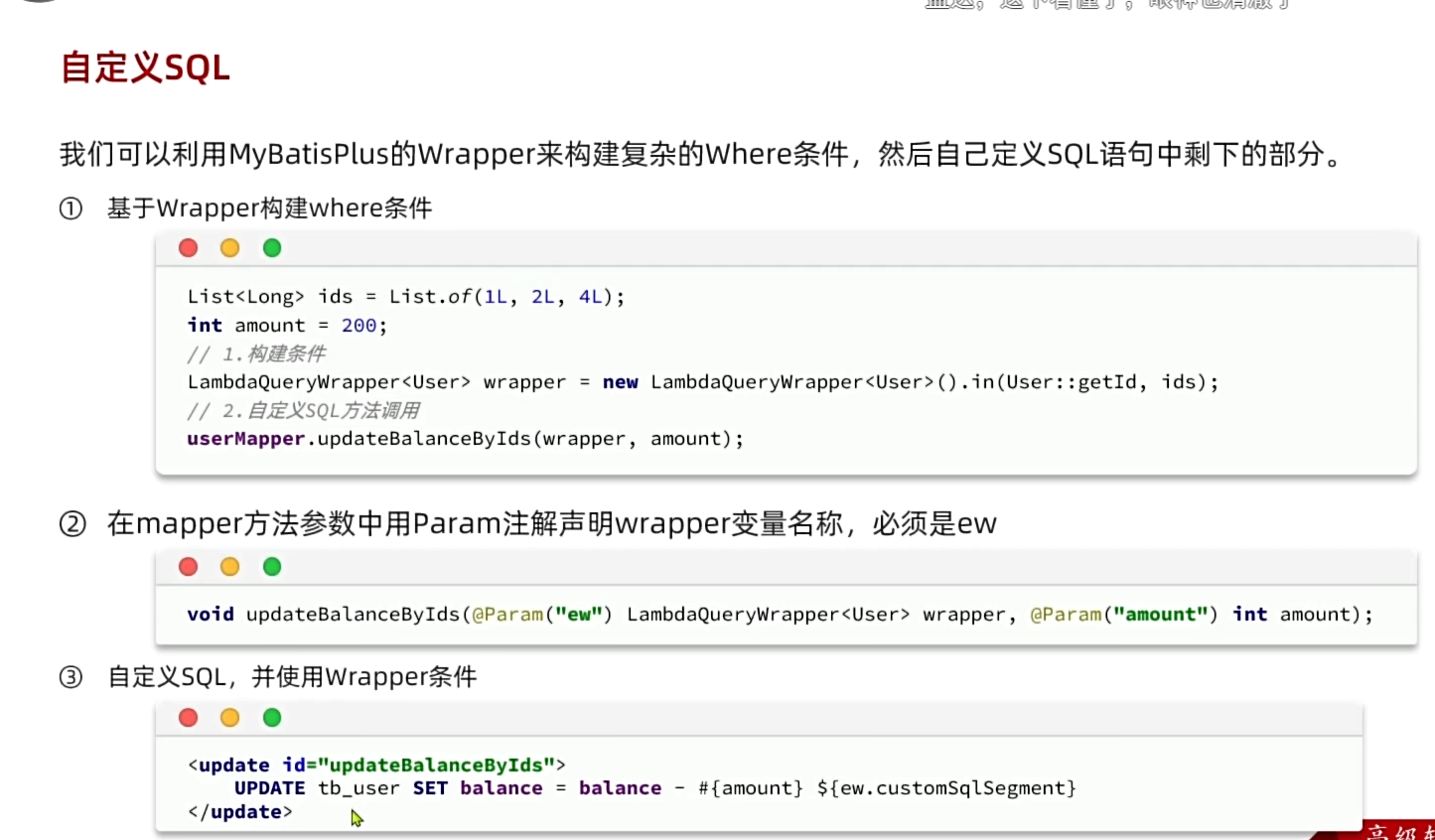
2、自定义SQL

案例:
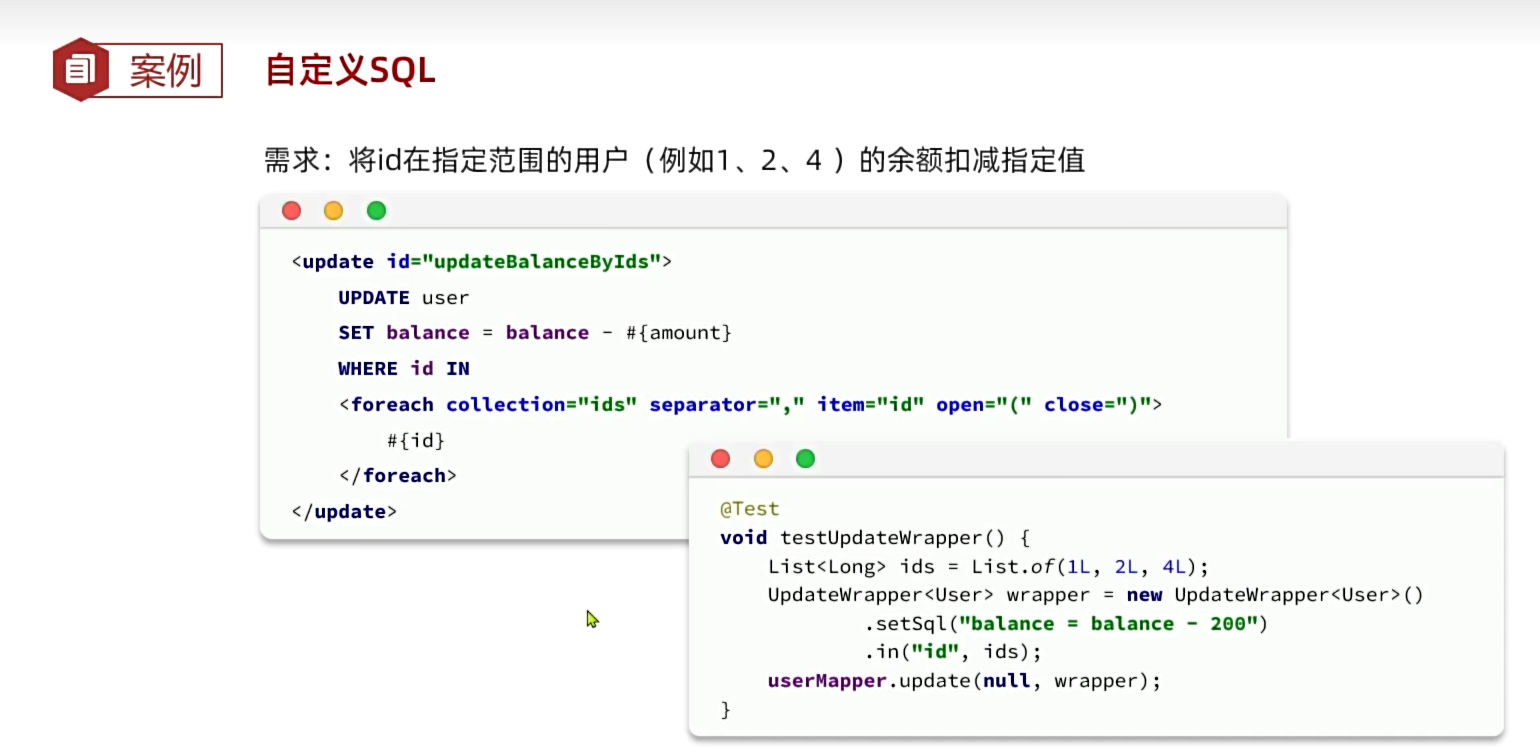
我们之前写的.setSql是在业务层写的SQL语句,这在很多公司的规范中是不被允许的。用MP方便了,但有的时候要去拼接SQL,违反企业开发规范。比如我们这里的setSql(...)语句。

自定义SQL就是我们在service和mapper层只构建条件然后逐步向下传递,然后在xml文件里对SQL语句进行拼接。
3、Iservice接口基本用法
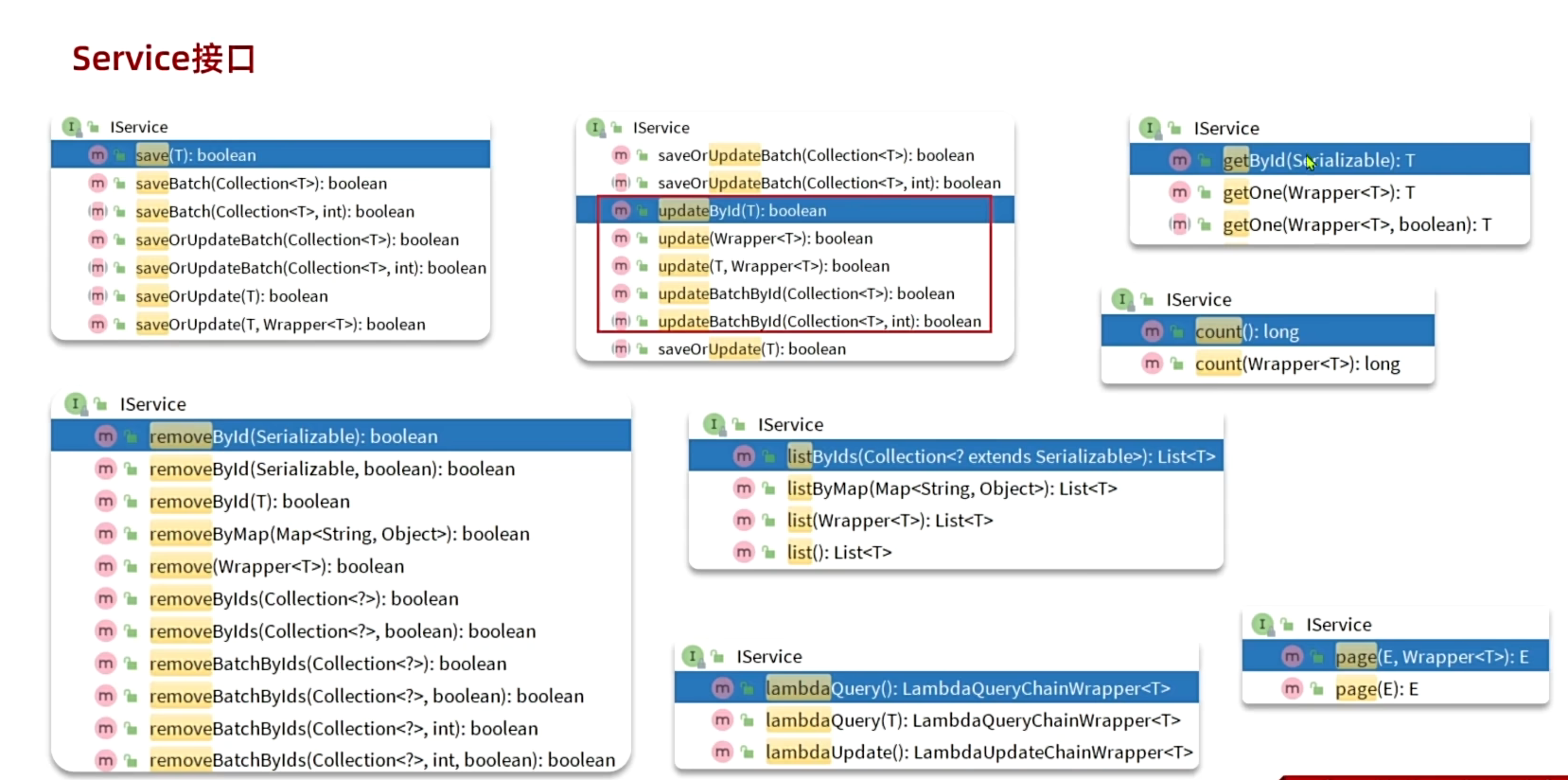
对于增删改而言,MP在service接口的主要优势是可以实现批量的增删改,saveBatch和removeBatchByIds和updateBatchById这种批量的增删改。而查询包含单个(getById)、数量(count)、多个(listByIds)、分页(page)、复杂条件(lambdaQuery)
service接口要继承IService接口,service实现类也要继承ServiceImpl类。
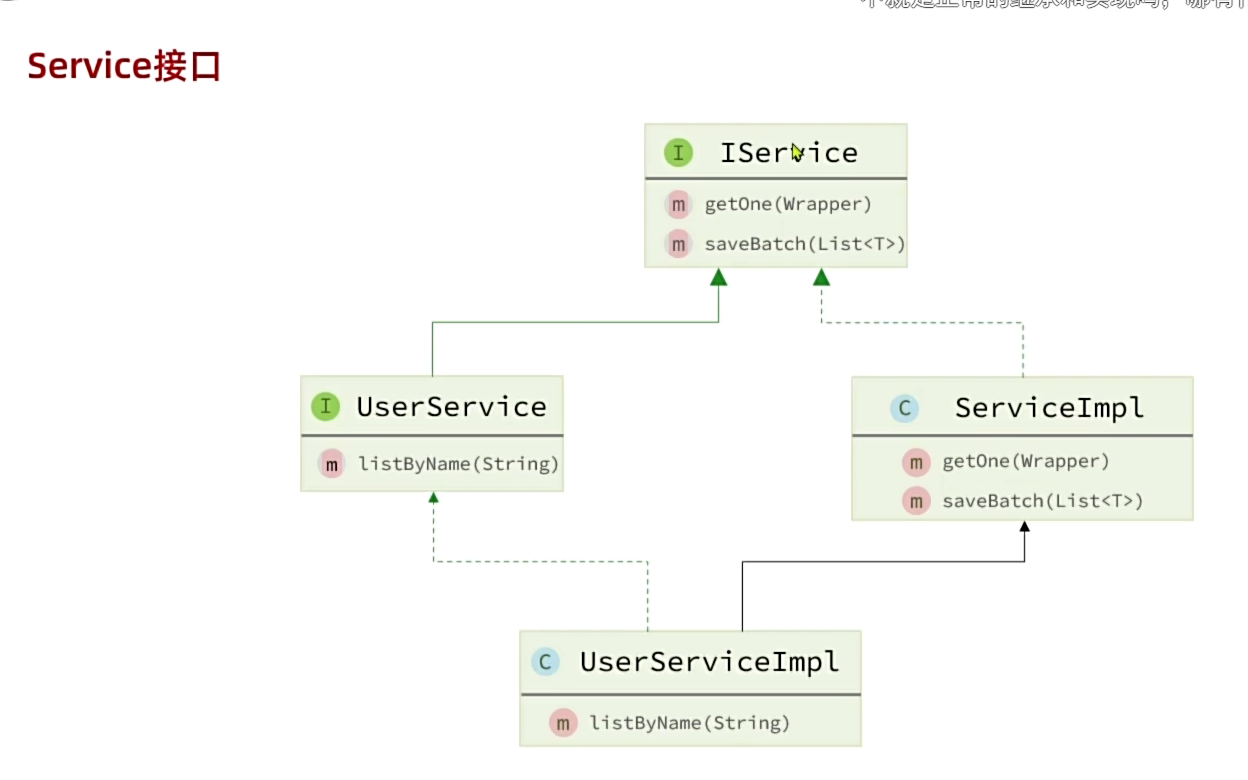

其实service最终还是基于mapper层来实现的,所以在extend ServiceImpl<UserMapper,User>需要指明对应的mapper类和操作的实体类。
具体实现:
4、Iservice开发基础业务接口
注意有关@Api的东西是swager依赖的东西,编写它是用于测试。

BeanUtil.copyProperties是hutool依赖项中的方法,它可以将差不多的实体类进行转换,比如vo和po几乎一模一样,可能少了一些属性,它就能通过拷贝进行转化。(这是一个很常见的场景)


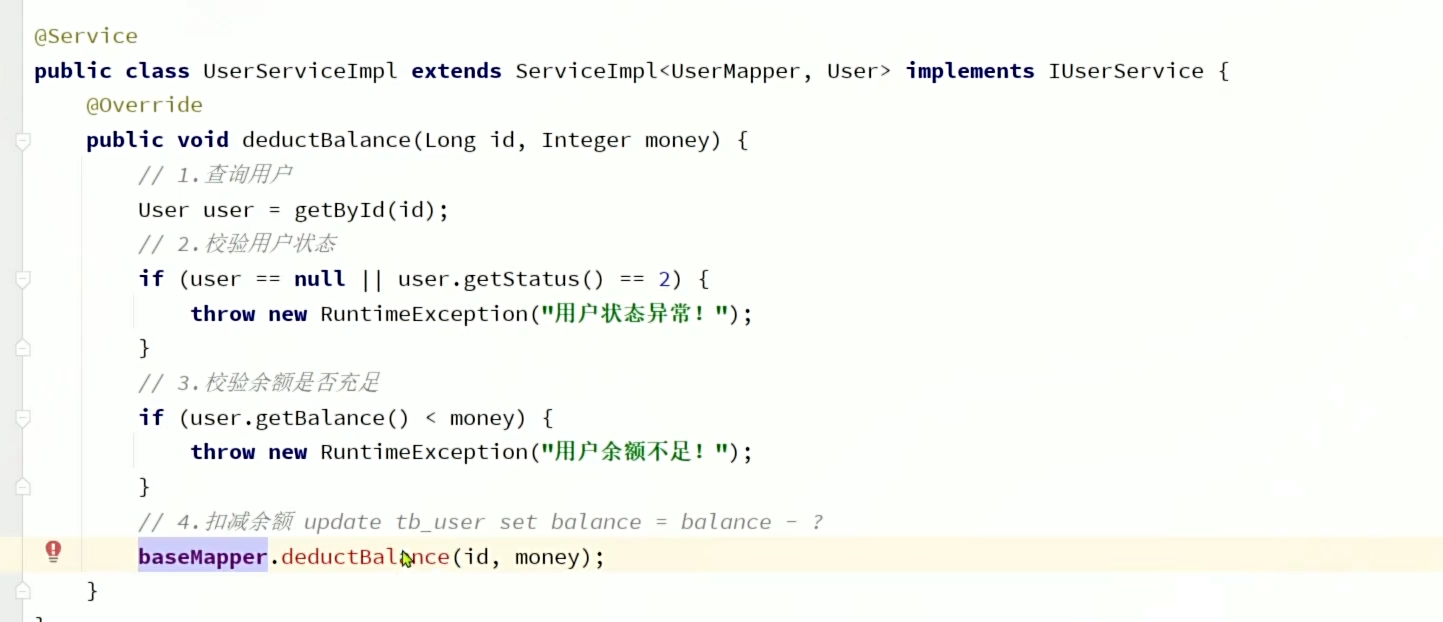
5、Iservice开发复杂业务接口(具有业务逻辑时)

Controller:
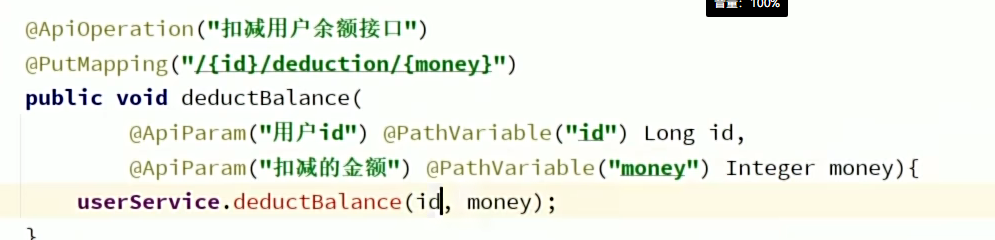
service:

6、Iservice的Lambda查询(当业务逻辑很复杂时用Lambda,复杂查询LambdaQuery和复杂更新LambdaUpdate)
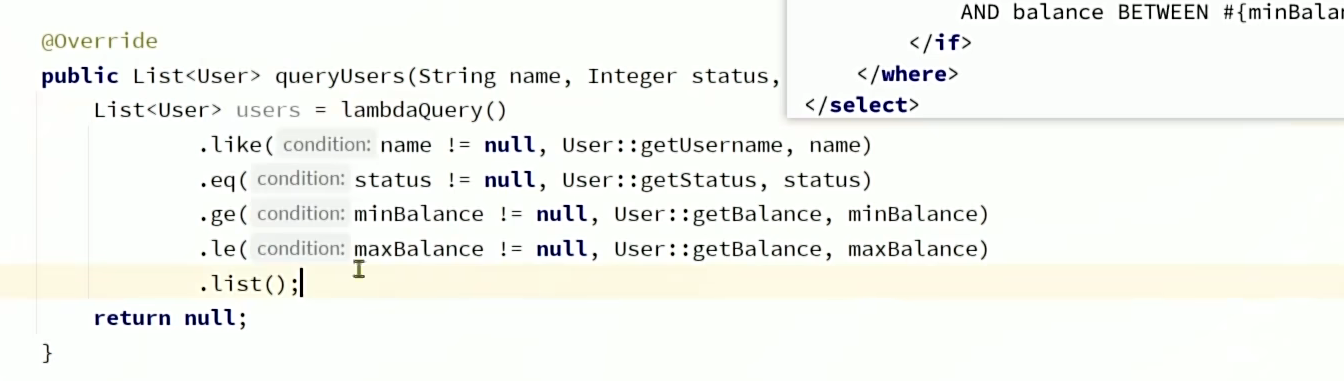
使用Iservice的Lambda查询完成以下SQL语句。(复杂查询)
注意Controller层的queryUsers方法是一个get请求,它不包含请求体所以没办法使用@RequestBody,直接用UserQuery这个实体类去接收就好。

问:为什么 IService 的 lambdaQuery 能直接返回结果而不用调用 Mapper
因为已经隐式调用,详情看一些疑惑中的回答四。
新问题(复杂更新)


由于可能出现线程安全的问题,要加锁。或者我们通过逻辑加一个乐观锁。即只有当数据库中对应id的值和我刚刚查到的值相同时才修改,否则不修改。

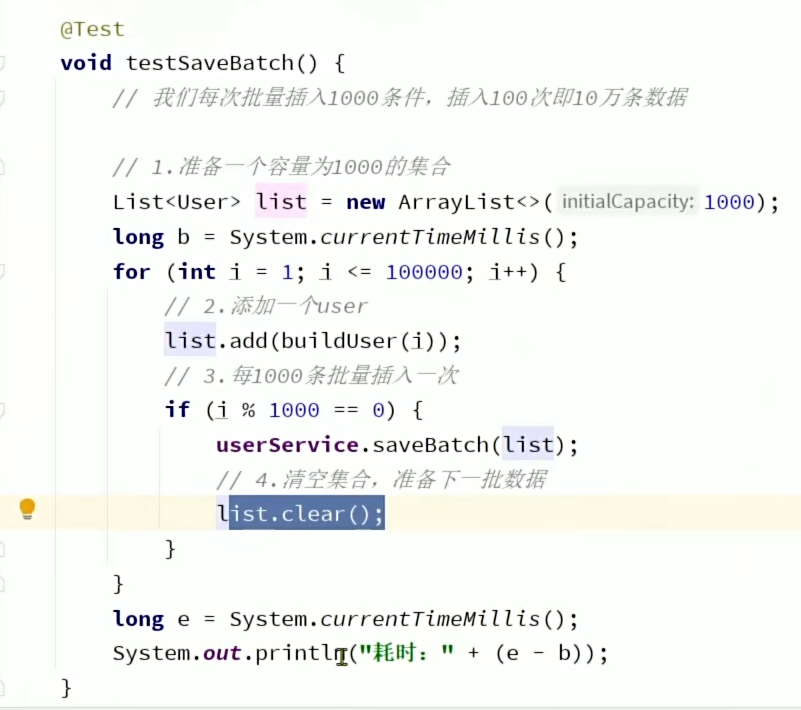
7、Iservice的批量新增

普通for循环对大量数据插入


使用MP自带的批处理
它的实现主要是通过每次批量插入1000条数据,插100次即可插10w条数据。每次只插1000条是因为List对象如果为10w的长度的话可能会内存溢出。
为什么它仍然可以优化呢?因为MP自带的批量新增是对添加语句进行预编译,它会预编译1000条新增SQL语句。所以我们可以设置MySQL的jdbc驱动的rewriteBatchedStatements属性为true,它会重写1000插入语句,让其变成一条插入语句,实现真正的批量插入。
为什么JDBC 默认关闭 rewriteBatchedStatements?因为兼容性问题,一些古早的服务器或者其他版本服务器对执行重写后的语句有歧义。并且重写SQL语句有安全分险,可能SQL注入。再就是少量的数据在插入时如果也重写的话会浪费时间,甚至可能性能还会下降。重写SQL语句也会导致日志审查困难。
在配置文件中让这个属性为true

3、MP的拓展功能
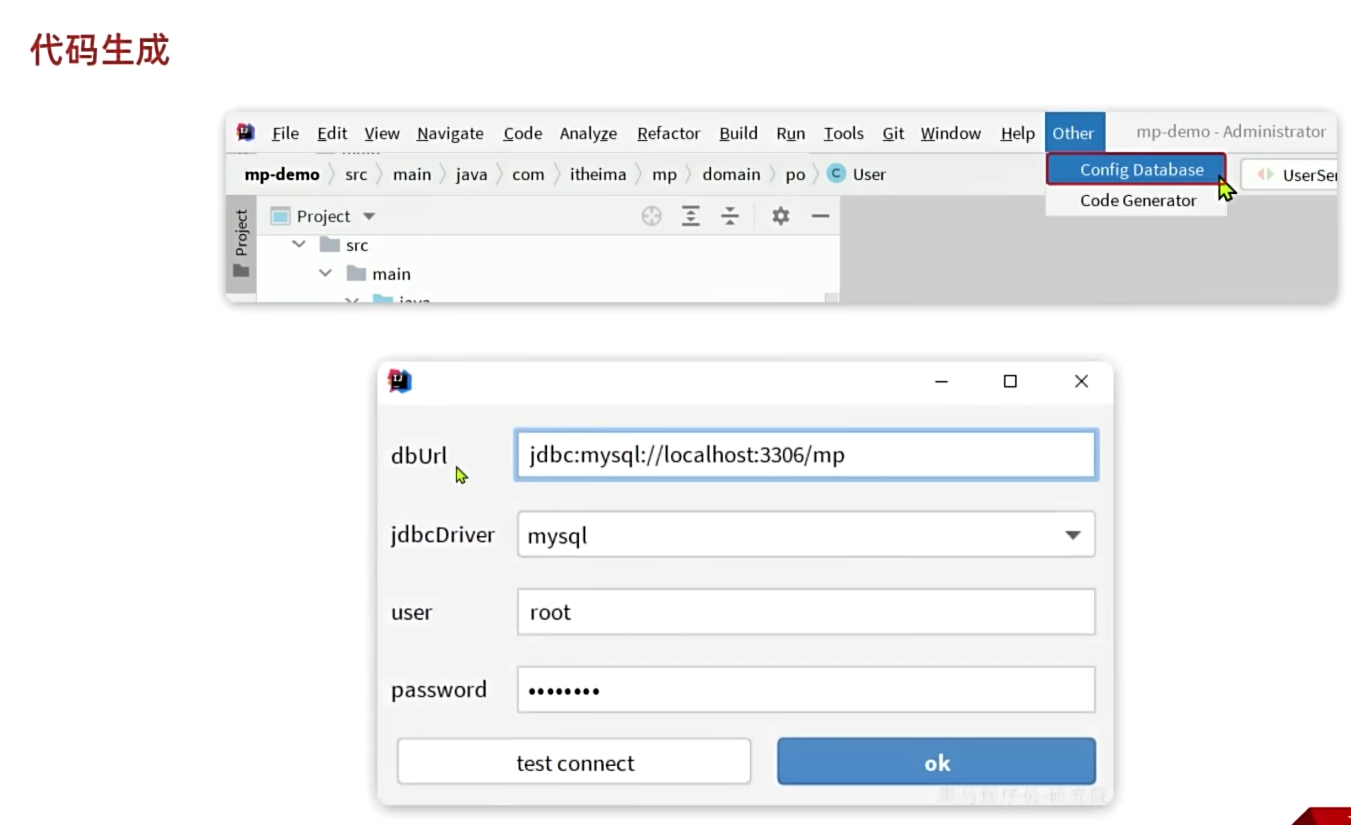
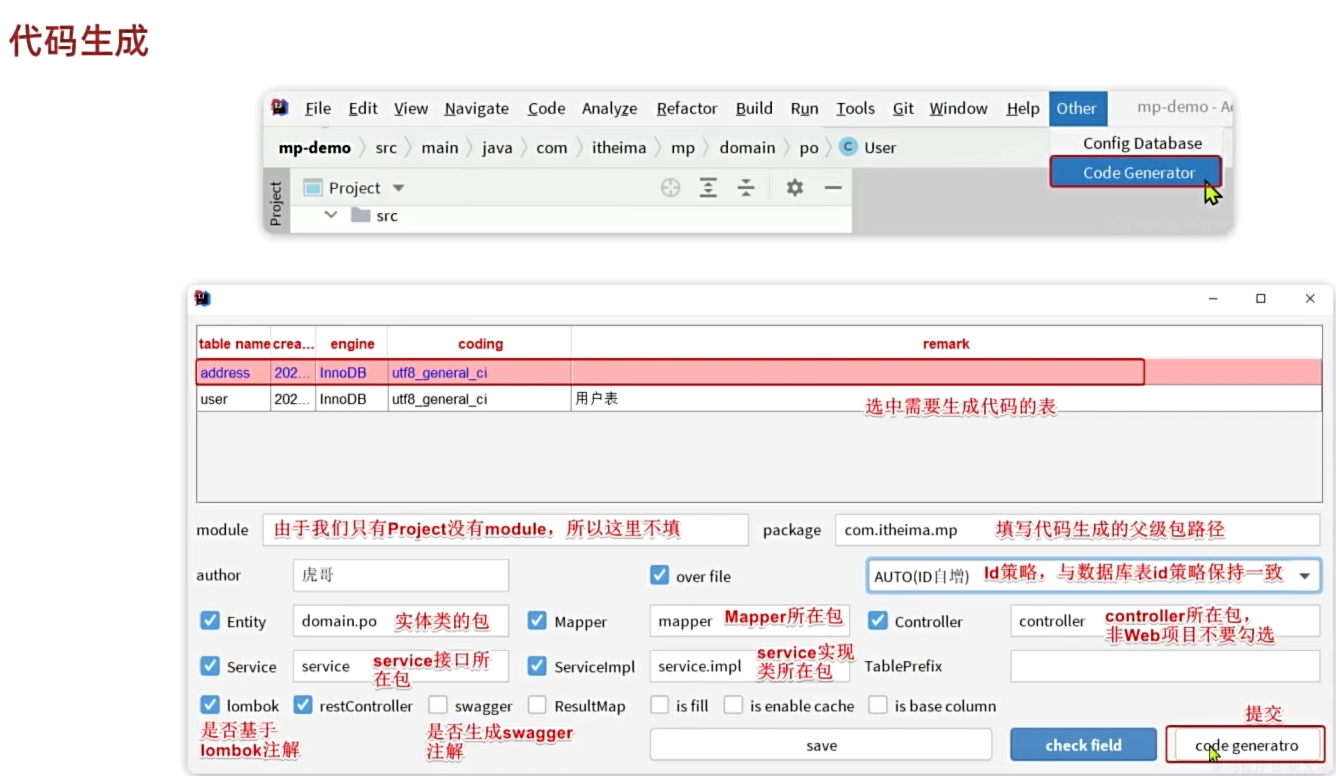
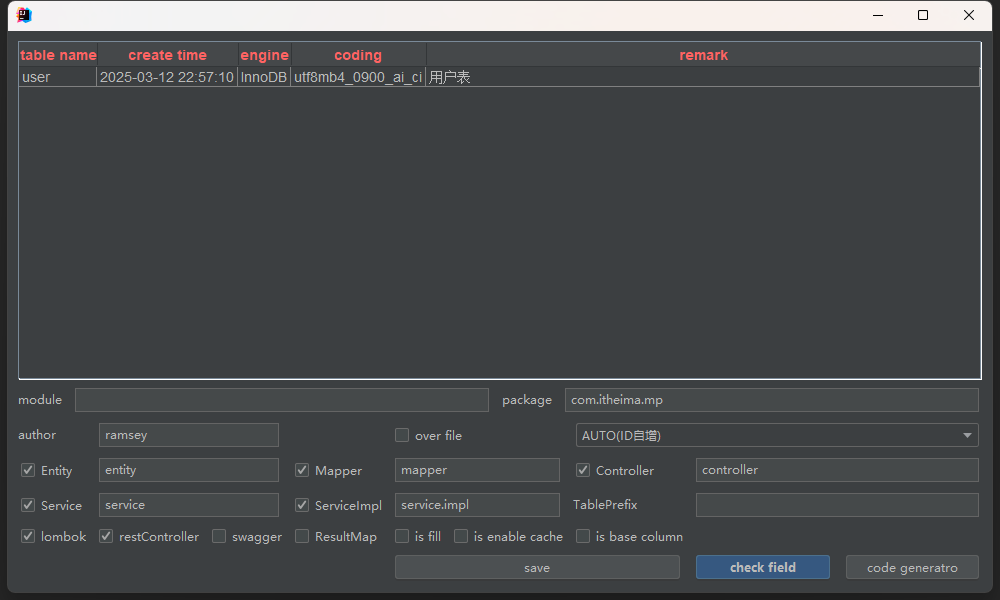
1、代码生成(一个插件)
通过插件生成基础的代码
具体位置在工具栏
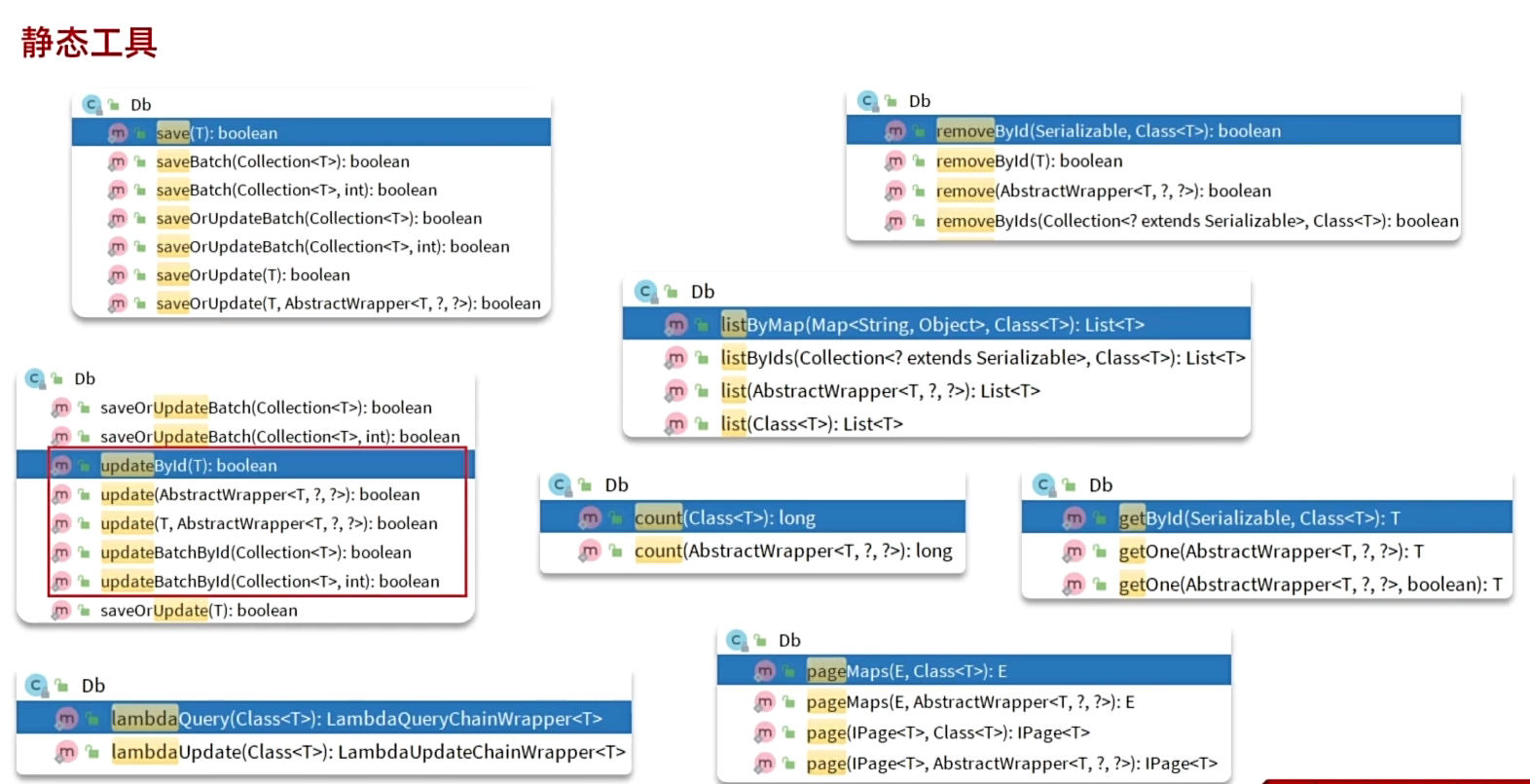
2、静态工具(避免循环依赖用的)
Iservice是非静态的,所以需要指明实体类和mapper文件,通过反射操作。而Db是静态的,所以它的方法需要传一个Class字节码参数(似乎更麻烦)
静态工具Db,主要是当出现两个Service比如user和address的Service,出现互相依赖也就是循环依赖时使用,这样当我们user需要去查询address时,不需要注入address的Bean对象来调用方法,直接用Db传入address的字节码Class文件就好。

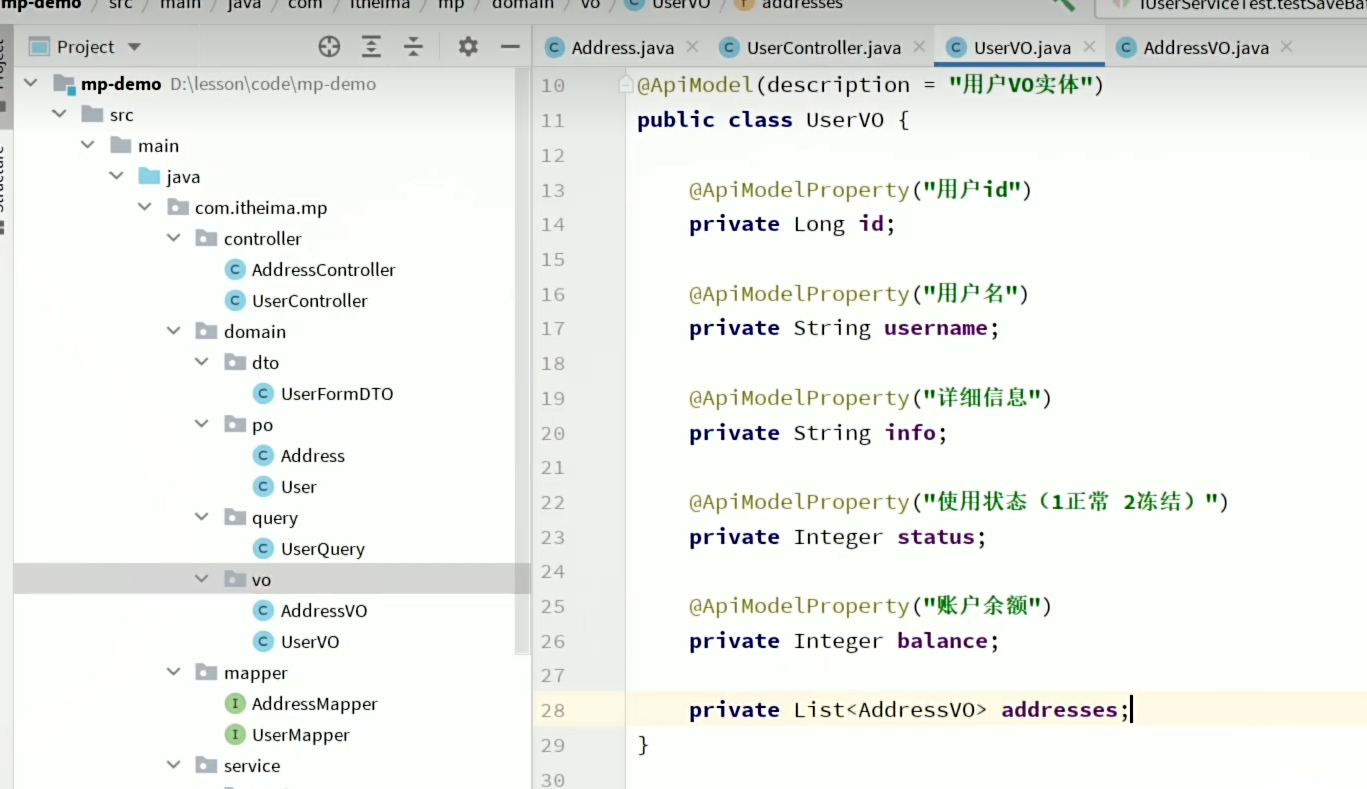
实现
首先给userVO实体类添加addresses字段
Controller

Service
通过Db.lambdaQuery(Address.class),我们不用注入Address的Iservice也可以使用它的LambdaQuery,这样避免了循环依赖。
还有就是hutool工具包的BeanUtil.copyProperties可以互相转实体类,BeanUtil.copyToList可以将List对象转为实体类对象。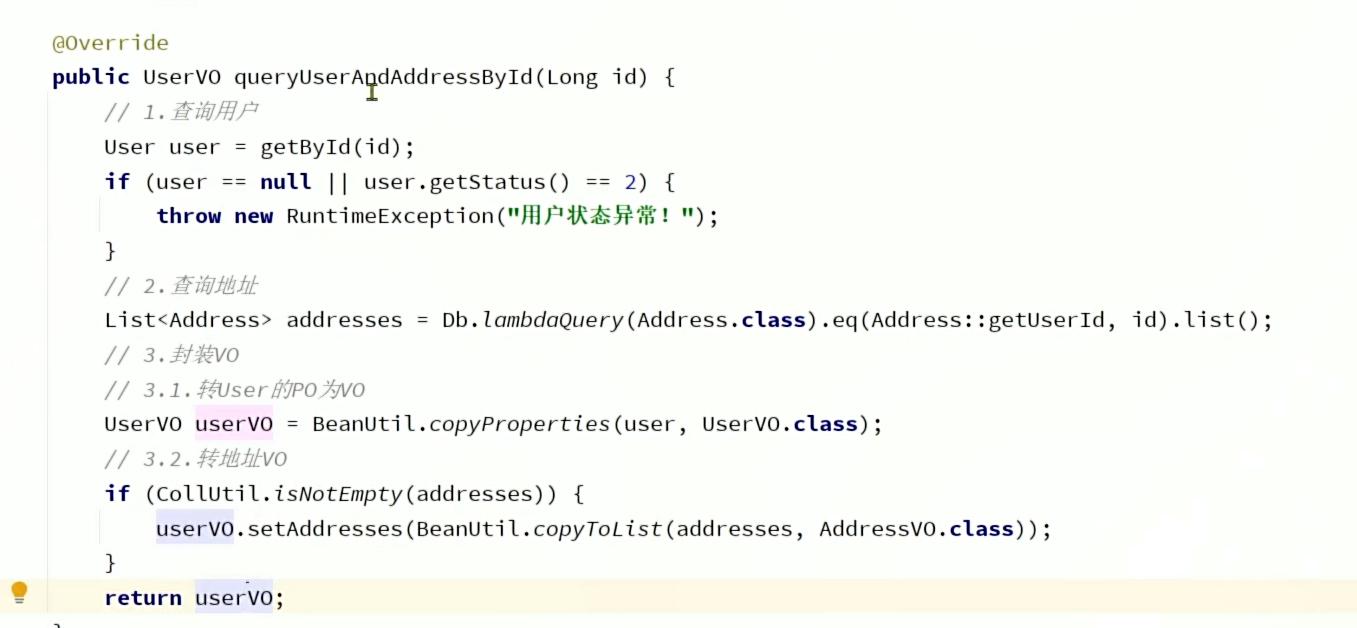
更复杂的实现

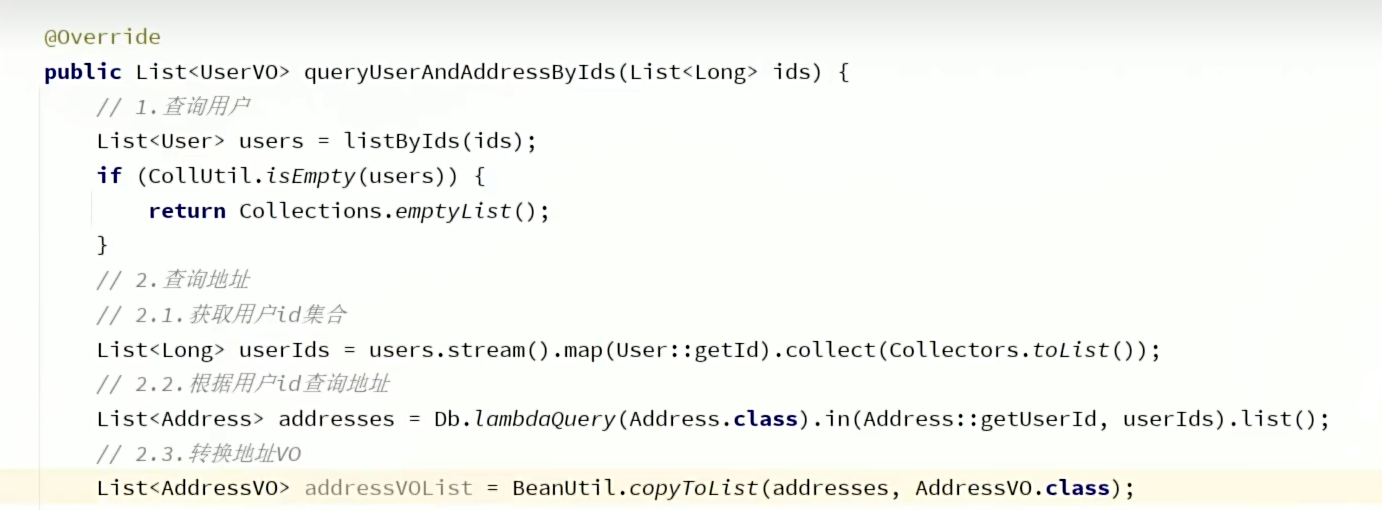
1、为什么要查询完用户再来获取用户id呢?因为查询的ids可能为空。
2、流处理主要包含中间操作和终止操作两部分,中间操作有filter(Predicate) 过滤符合条件的元素、map(Function) 将元素转换为其他形式、distinct() 去重、sorted() 自然排序还有limit限制个数、skip跳过前几个元素。终止操作一般为collect和foreach两个。
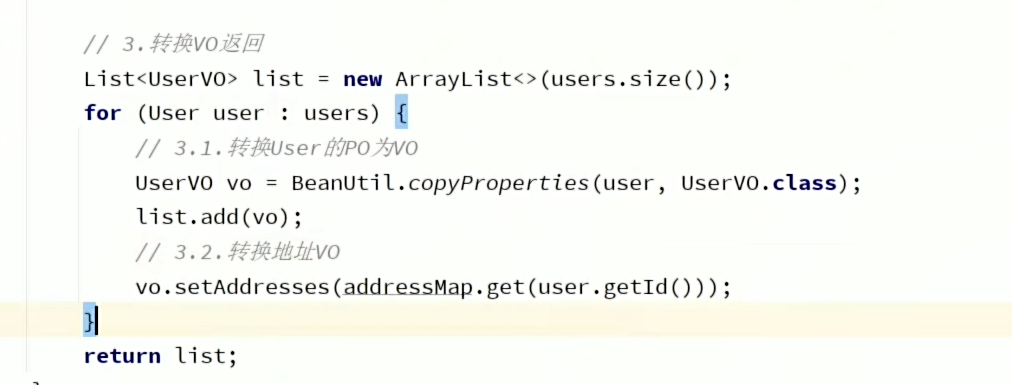
3、获取userId后通过静态工具Db调用Address服务获取地址List<Addressov>。注意这个集合包含查询的所有地址,再通过流处理collectors.groupingBy()对List进行分类。

1、为什么不是先set在list.add呢?因为指向的是引用,顺序影响不大。
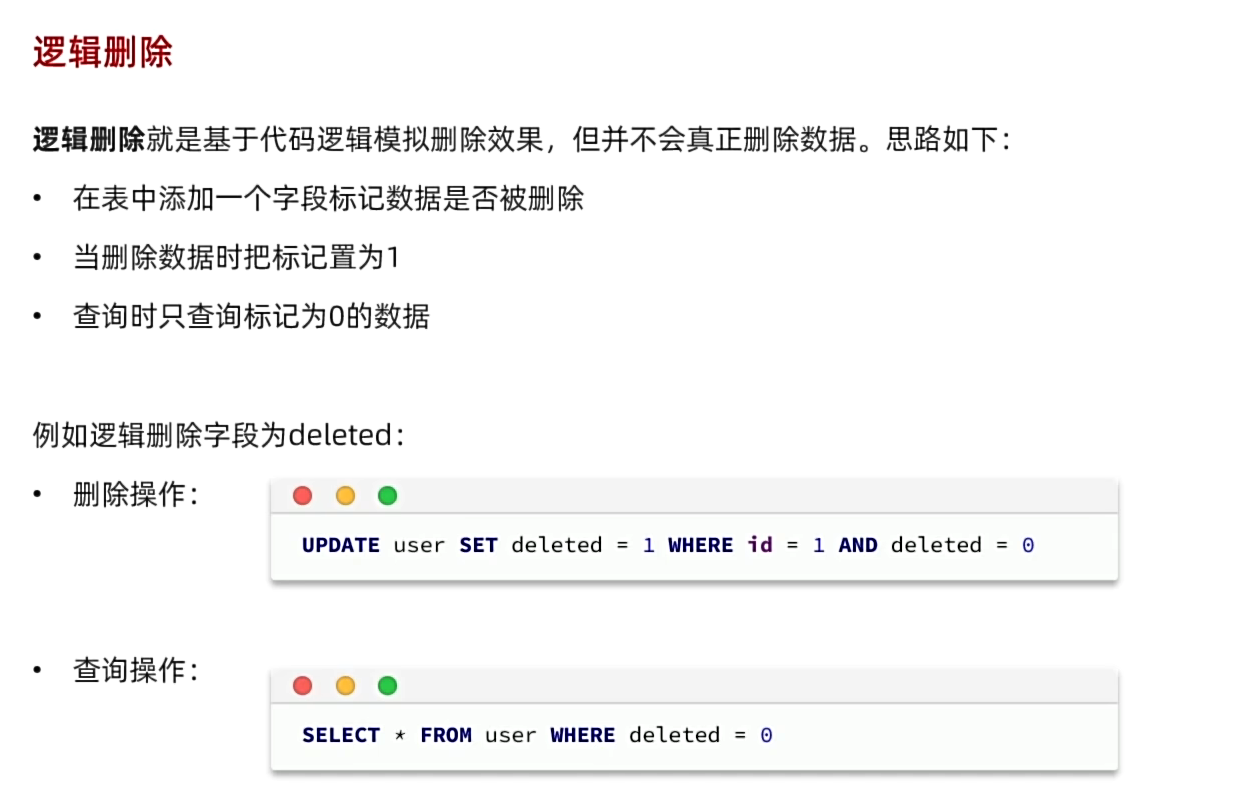
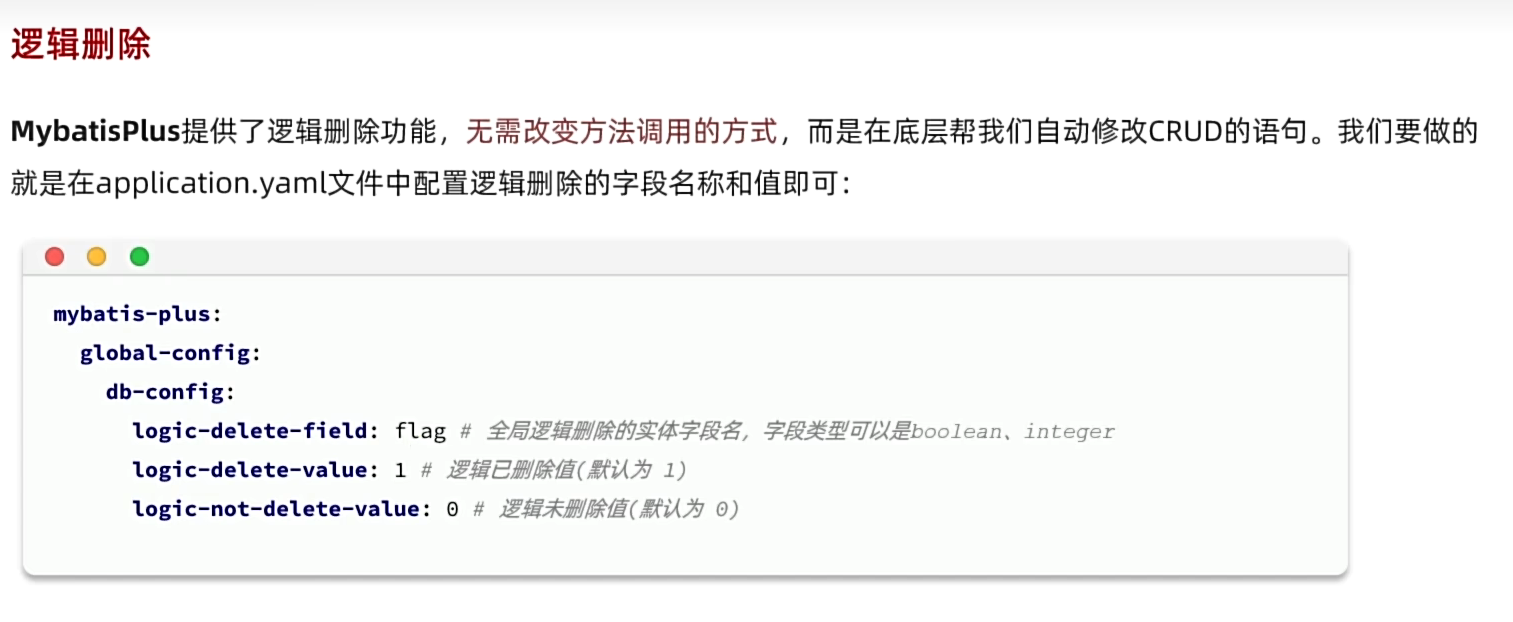
3、逻辑删除(不推荐,会导致内容堆积)

4、枚举处理器
我们创建枚举类后,就可以在实体类中创建枚举类对象,这样我们在代码中就可以给他赋NORMAL和FREEZE这样的属性,而java字段的枚举类型和数据库的枚举类型的相互转化是由Mybatis的Typehandler。
这是Mybatis的Typehandler
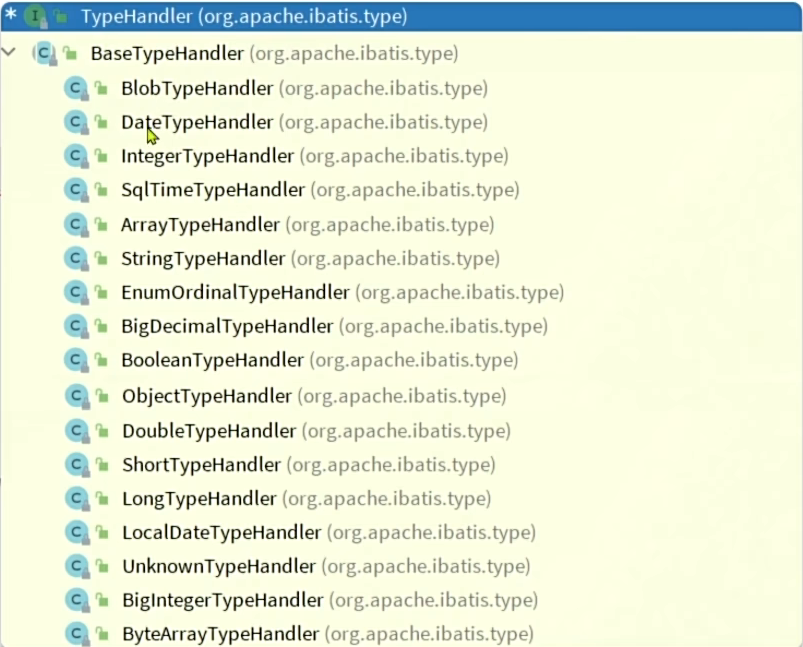
MP多了两个类,这两个类主要是实现和Mybatis的自定义枚举处理器一样的效果,也就是枚举某个属性(如 NORMAL、FREEZE)而非名称或序号存储时,需自定义 TypeHandler。
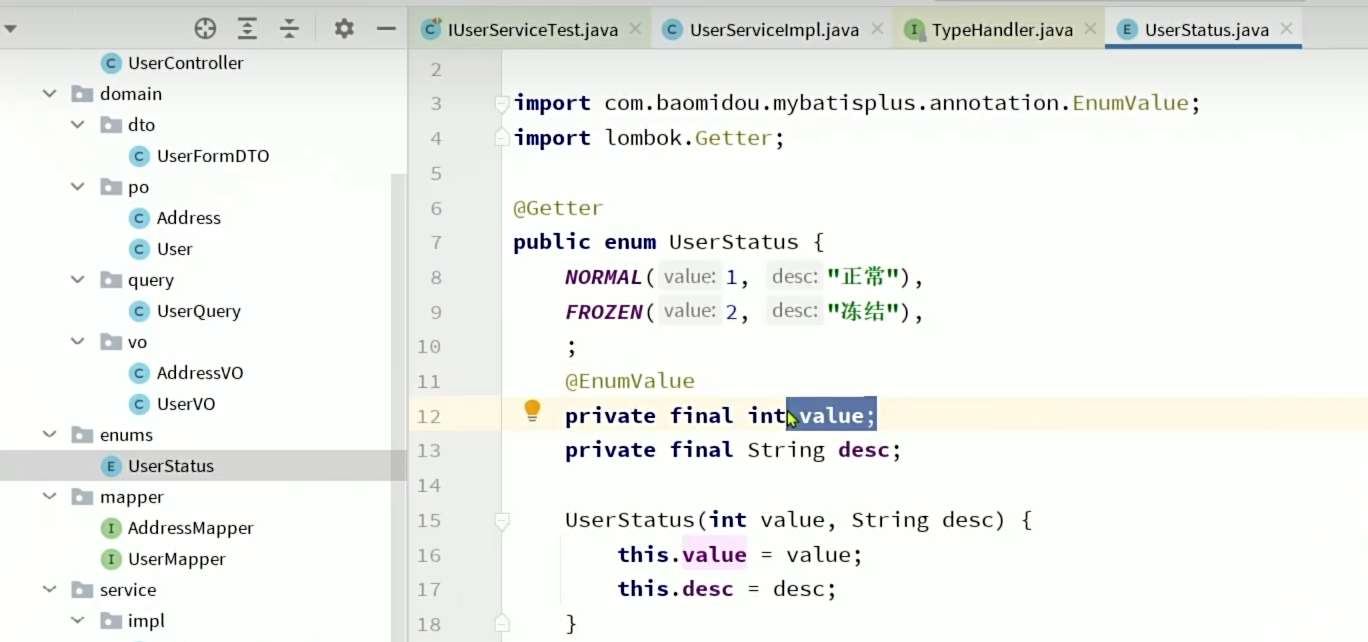
 使用@EnumValue注解
使用@EnumValue注解
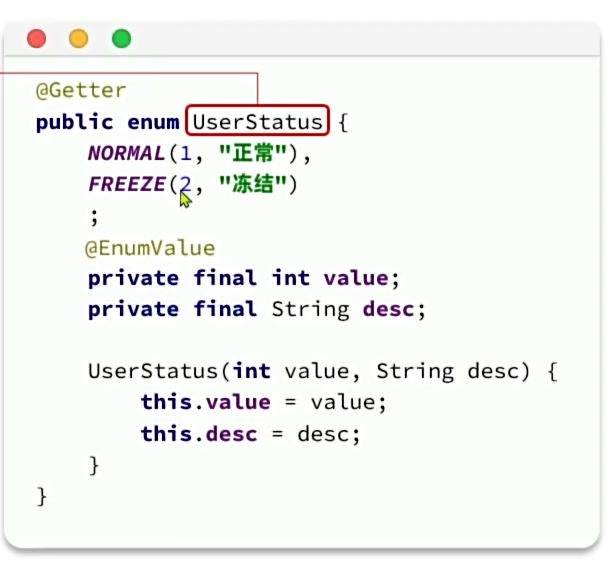
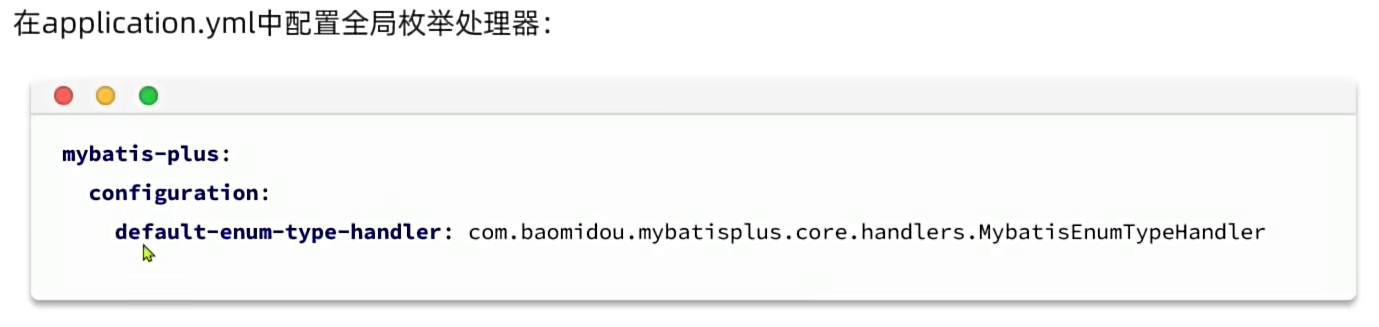
选定默认的枚举处理器(这里我们选的自然是枚举类型而非json类型)
 实现:
实现:
1、写枚举类
2、配置枚举处理器

3、修改字段类型

4、枚举字段可以直接用==比较,我们在业务代码也要修改,可读性变得非常好
5、默认给前端返回的是NORMAL、FREEZE字段,要想返回的是其他字段用@JsonValue注解


5、JSON处理器
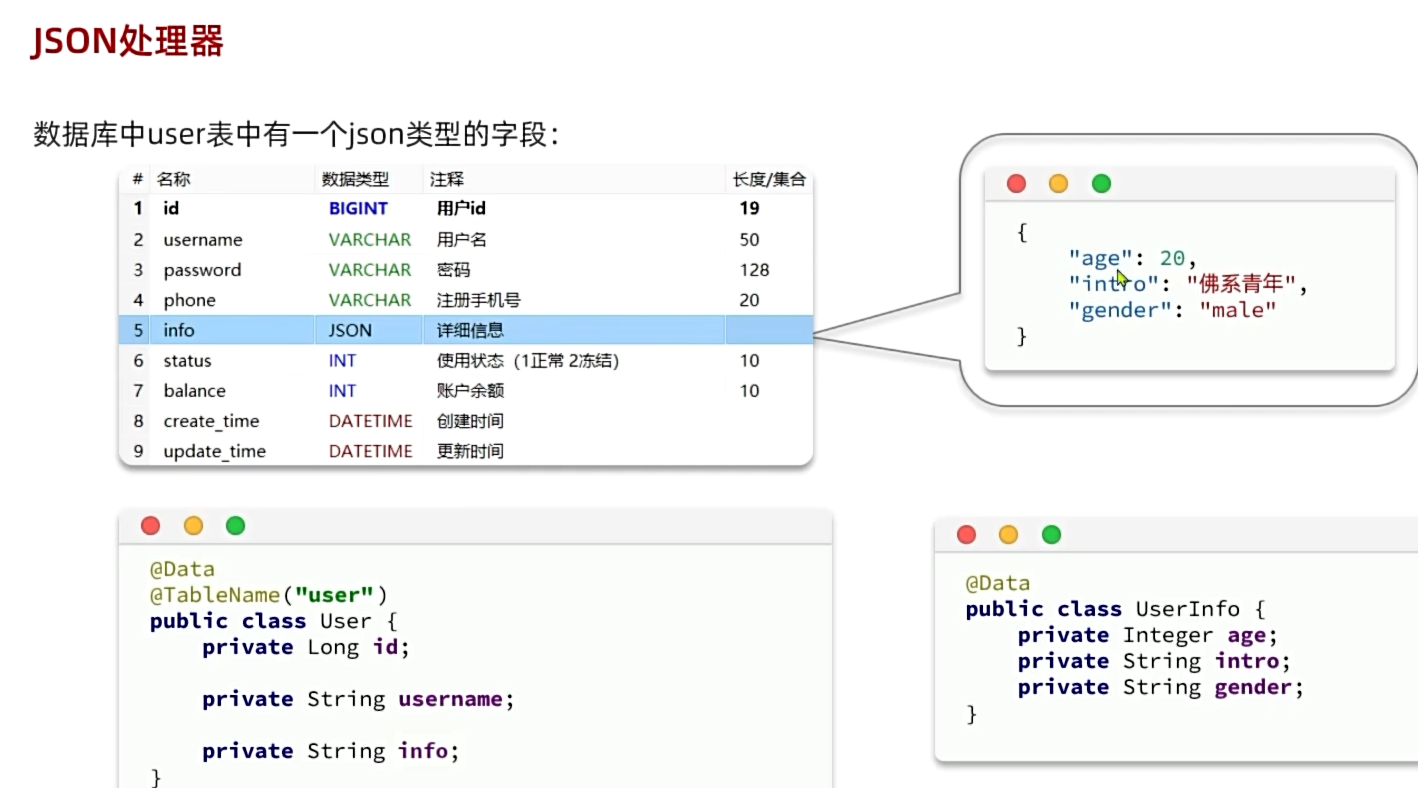
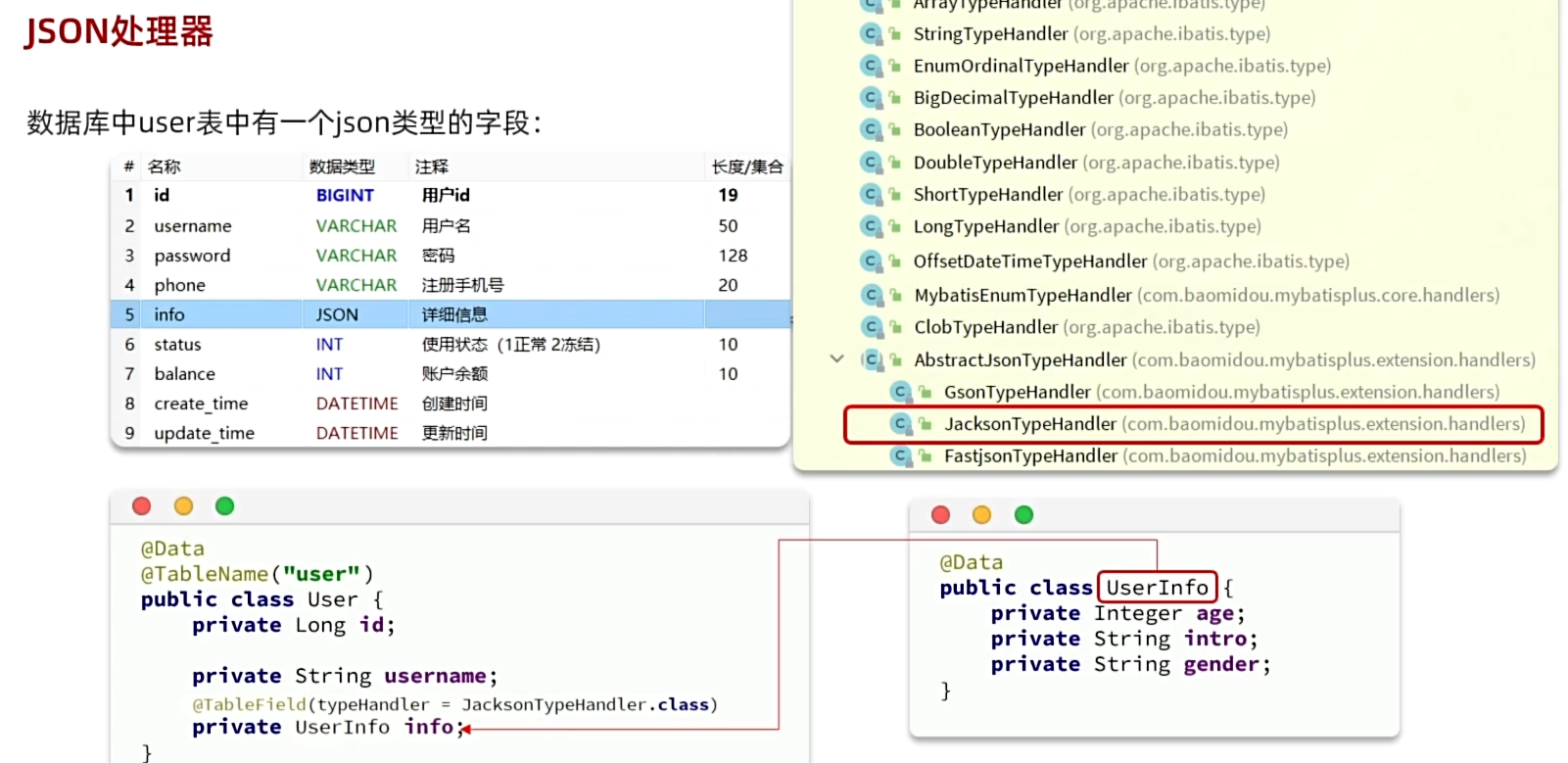
枚举通常被视为简单值类型,不需要复杂的嵌套映射。JSON处理器需要明确知道如何处理这些嵌套关系,autoResultMap=true会触发MP使用配置的类型处理器。
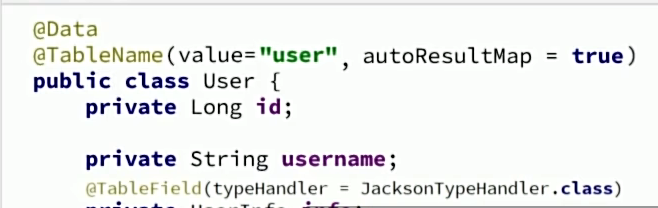
1、添加JSON字段的实体类,在这个对象上面@TableField注解里选择TypeHandler="JacksonTypeHandler.class"
2、TableName设置autoResultMap=true,处理嵌套映射。
6、分页插件
1、分页插件需要在MP的拦截器中配置了才可以使用。

2、这个主要关注一下page的两个参数,一个page包含分页的参数(页码、每页大小、排序字段等),一个querywrapper包含查询条件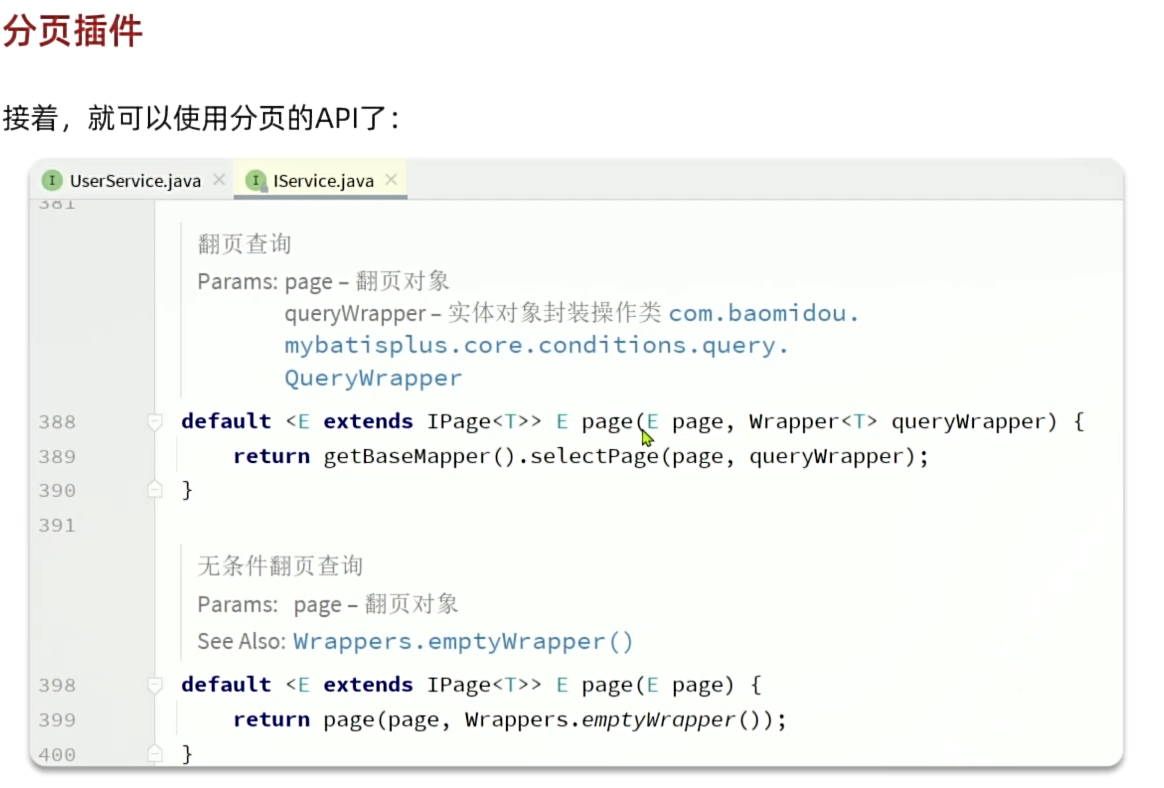
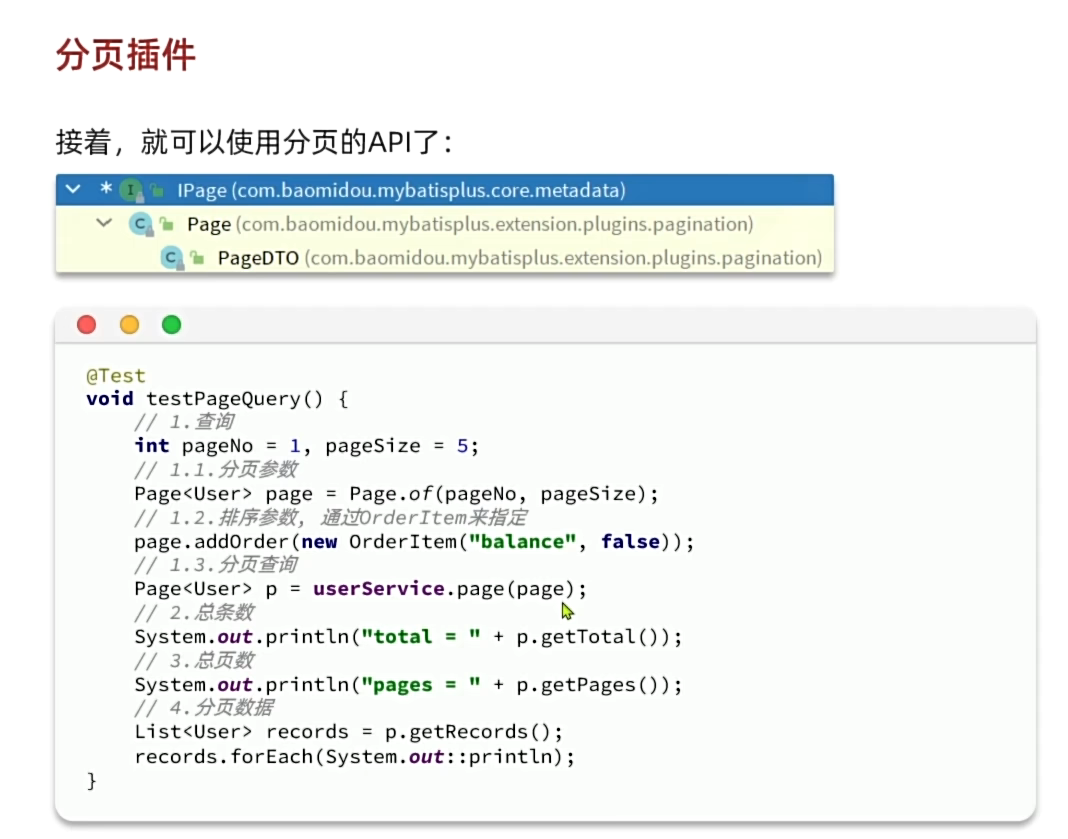
3、准备分页条件时用Page.of方法创建page分页条件对象。注意新版在使用OrderItem()指定排序方式时,需要用静态方法asc(String)来创建对象。true代表升序。
通用分页查询

1、写一个统一的分页查询文件
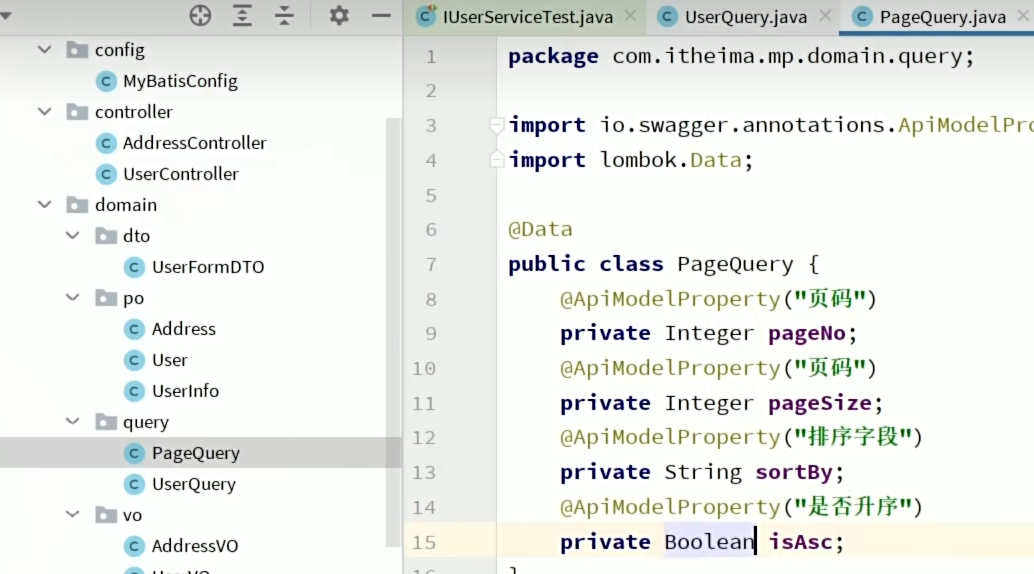
2、其他业务继承和拓展即可。@EqualsAndHashCode(...)注解就是说,当判断相等时先考虑父类属性再考虑子类属性,就是分页的时候把分页条件作为数据请求的的前提,然后再考虑查到了哪些匹配的数据

3、分页查询结果返回的实体类
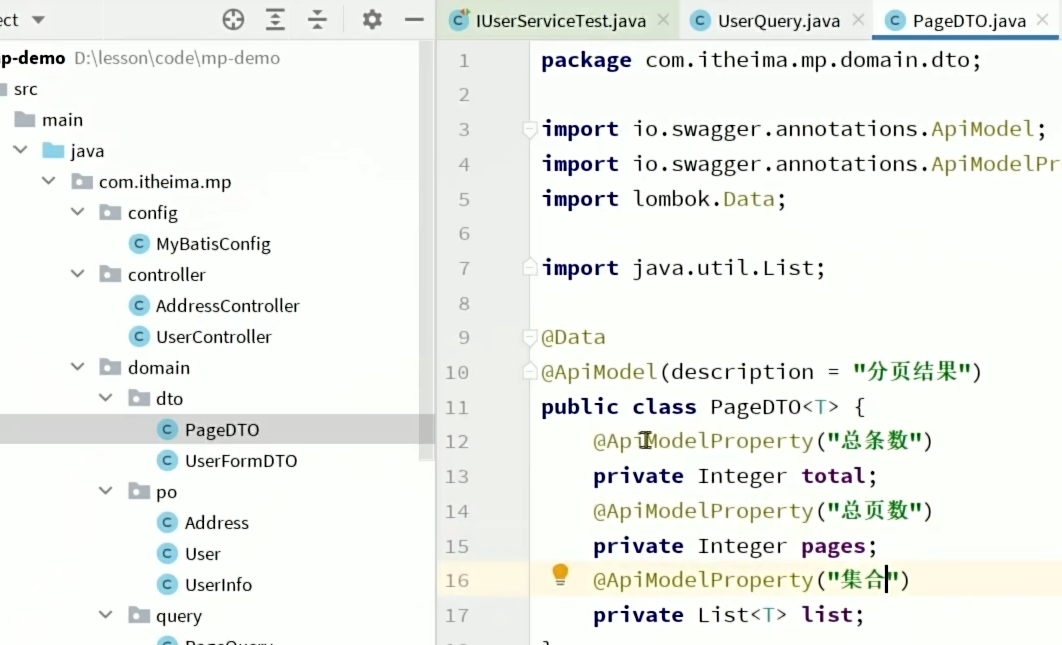
4、Controller

5、service
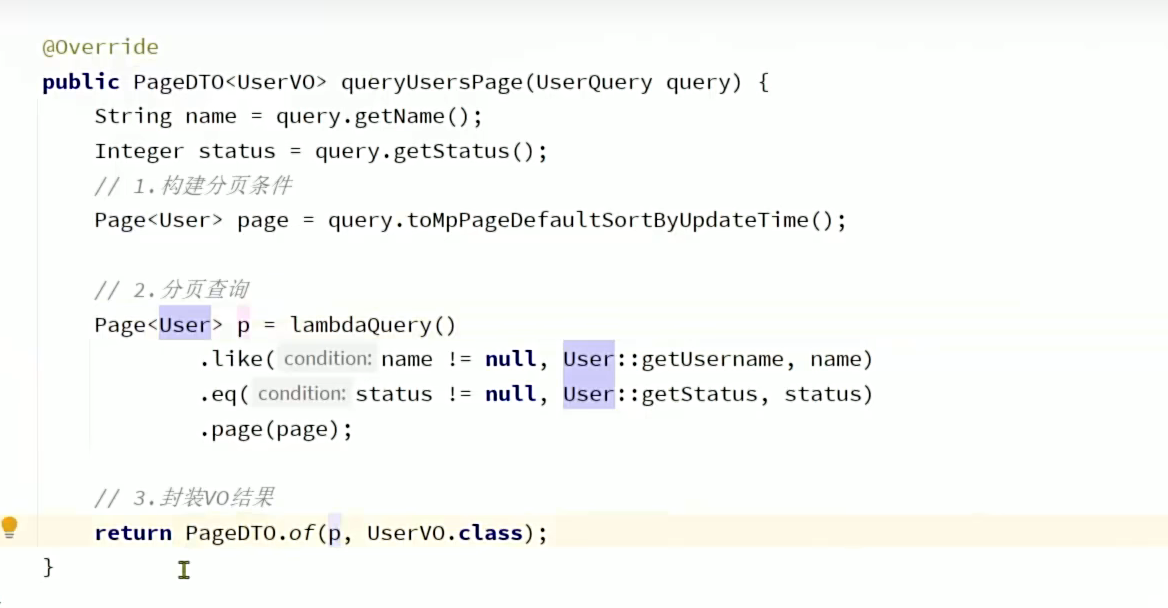
5.1 这个地方和上面直接用page查询又不同,因为它有条件查询(要求status是1),所以我们使用Lambdaquery复杂查询实现。还要去判断它是否传了排序字段,没有的话我们用更新时间字段排序


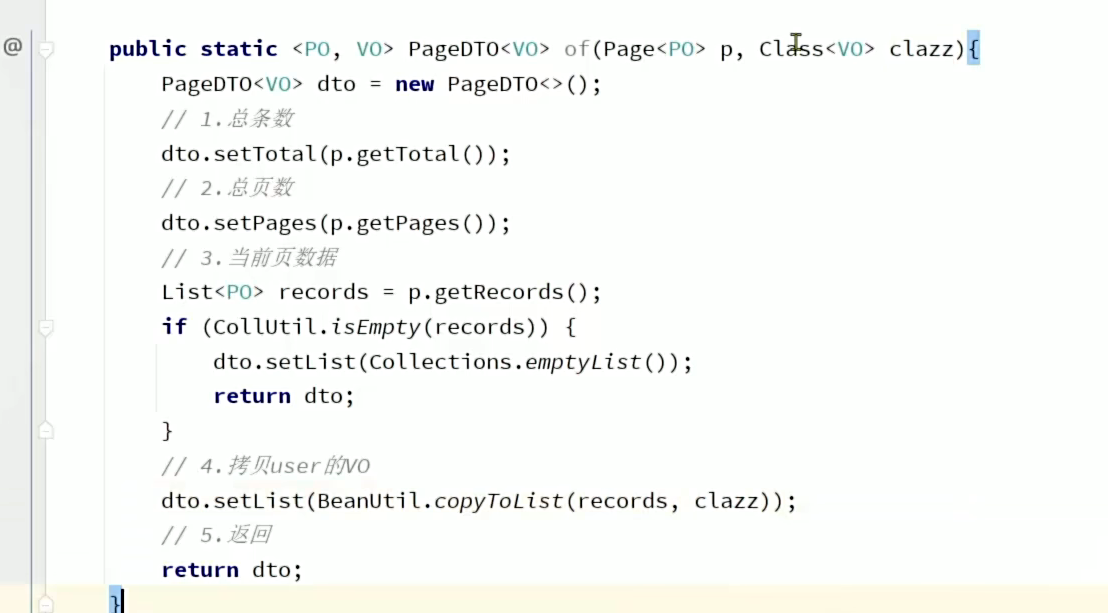
5.2 对返回的结果进行处理,这里我们可以学到如果我们要返回的是一个空集合,我们可以用collection.emptyList()创建一个空集合。 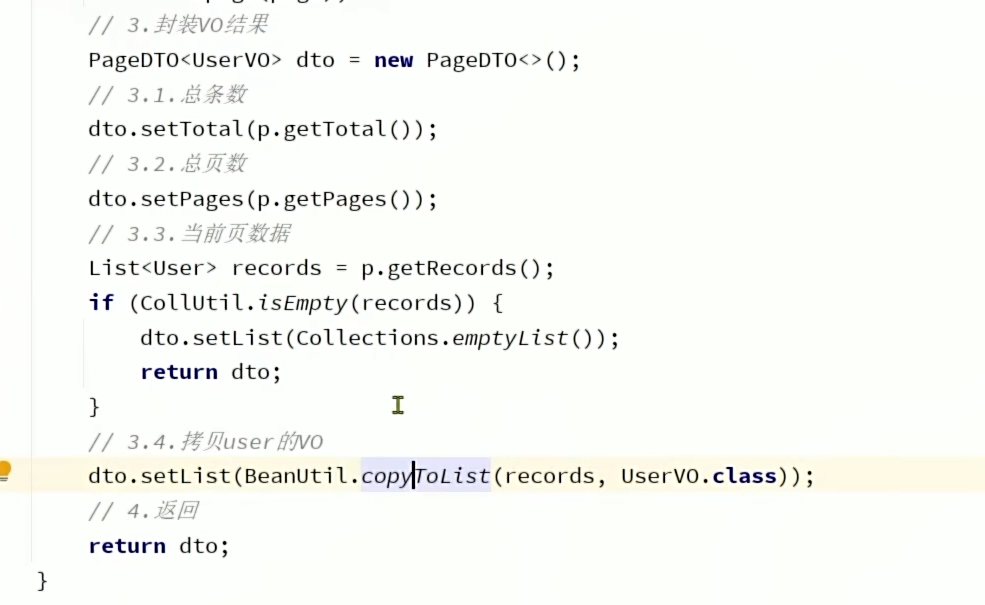
通用分页实体与MP转换(优雅)

直接将page对象在pagequery实体类中就用方法生成
由于我们默认排序的字段不知道,我们使用可变参数OrderItem ... items,可变参数支持从零到多个参数,这样它排序的字段就可以为多个。
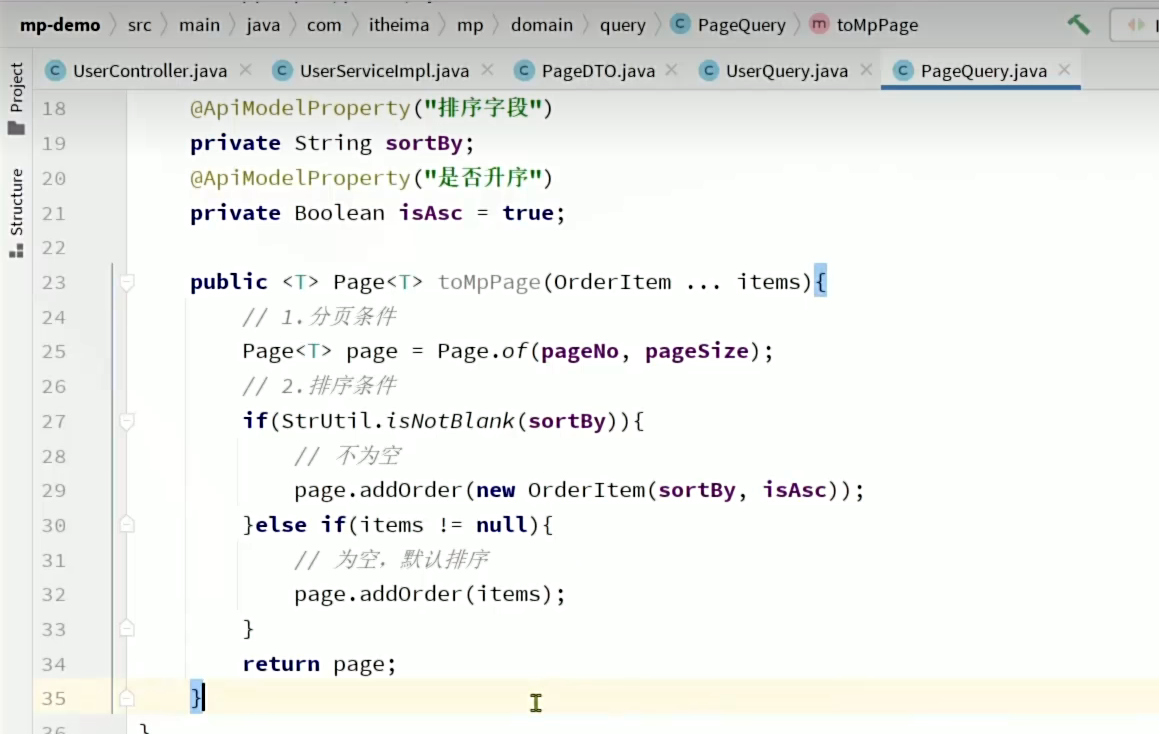
方法重载一下,考虑其他参数情况。
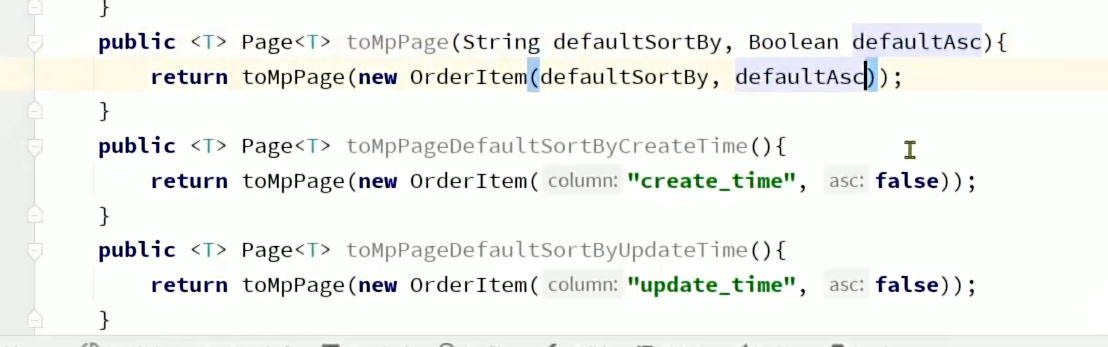
pageDto中呢由于要通用的让vo转成po,所以我们使用泛型作为参数,在实例化的时候才指明类型
由此,我们业务代码可以简化为:
我们在最后想让代码更优雅一点,我们不用hutool工具包的copy方法去将po转vo,我们自定义一个方法,通过流处理的方式将他转为vo
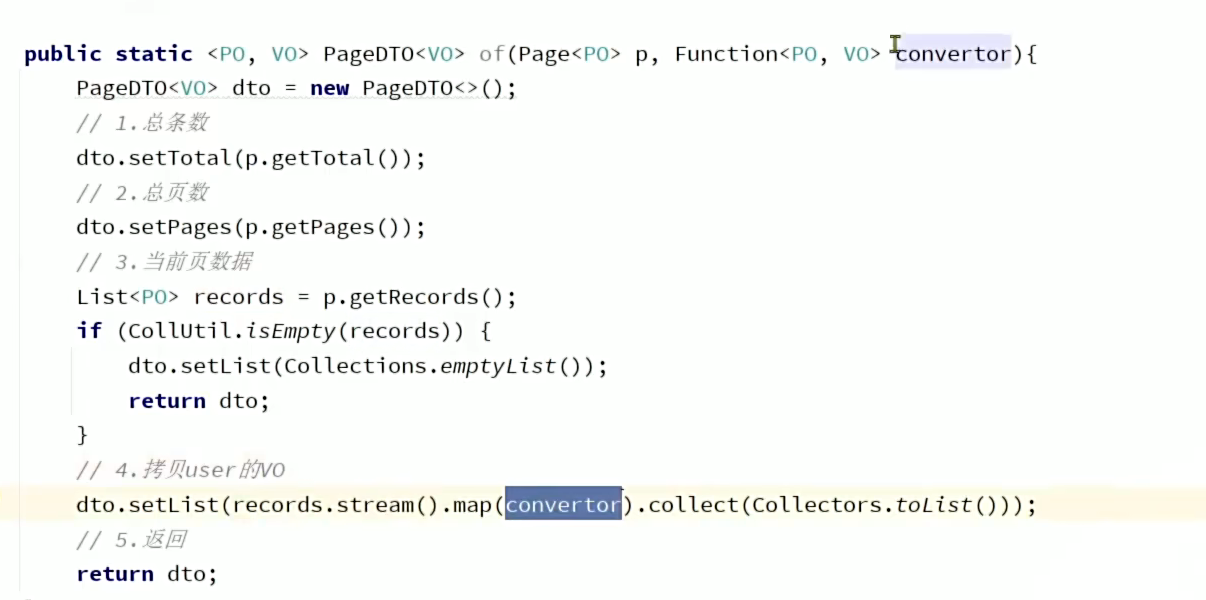
那我们在使用的时候就要给他传一个方法,一个Lambda表达式,相当于在map()里的执行的方法

一些疑惑:
1、ID自增有什么问题?UUID为啥不行?雪花算法的优点、缺点?如何避免缺点?
2、为什么没有 @Mapper 注解的接口会被注入到 IOC 容器
即使你没有在接口上显式添加 @Mapper 注解,这个 MyBatis Mapper 接口仍然可能被注入到 Spring IOC 容器中,主要有以下几种可能原因:
1. 使用了 @MapperScan 注解
最常见的情况是你在配置类或启动类上使用了 @MapperScan 注解:
@SpringBootApplication
@MapperScan("com.example.mapper") // 扫描指定包下的所有接口
public class Application {public static void main(String[] args) {SpringApplication.run(Application.class, args);}
}@MapperScan 会扫描指定包路径下的所有接口,并将它们注册为 MyBatis Mapper,无需在每个接口上单独添加 @Mapper 注解。
2. MyBatis-Spring-Boot-Starter 自动配置
如果你使用的是 Spring Boot 并添加了 mybatis-spring-boot-starter 依赖,它会自动配置 MyBatis 相关组件:
<dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>版本号</version>
</dependency>这个 starter 会自动扫描标注了 @Mapper 的接口,或者 在配置文件中通过 mybatis.mapper-locations 指定了 XML 文件位置时,也会自动关联对应的接口。
3. XML 文件与接口的对应关系
MyBatis 通过以下方式将接口与 XML 映射文件关联:
命名空间匹配:XML 中的 <mapper namespace> 必须与接口的全限定名一致
方法名匹配:XML 中的 SQL 语句 id 必须与接口方法名一致
当这些条件满足时,即使没有 @Mapper 注解,MyBatis 也能正确识别并创建接口的代理实现。
4. Spring 的组件扫描
虽然不太常见,但如果你在接口上添加了 @Repository 或其他 Spring 的组件注解,Spring 也会将其注册为 Bean,但这通常不是推荐的做法。
总结
没有 @Mapper 注解但接口仍被注入 IOC 容器的原因通常是:
使用了 @MapperScan 进行批量扫描
MyBatis-Spring-Boot-Starter 的自动配置
正确的 XML 文件与接口的对应关系
这种设计提供了灵活性,你可以选择在单个接口上使用 @Mapper,或者使用 @MapperScan 进行批量注册。
3、通过构造函数注入Bean对象
在IuserService对象前添加final,由于@RequiredArgsConstructor它会构造那些必要的参数,如添加了final的IuserService,这样就不用@Autowired注入了。
4、为什么 IService 的 lambdaQuery 能直接返回结果而不用调用 Mapper
MyBatis-Plus 的 IService 接口及其实现类 ServiceImpl 在使用 lambdaQuery() 方法时能够直接返回结果而不需要显式调用 Mapper 方法,这是因为 MyBatis-Plus 在内部已经完成了整个查询流程的封装。以下是具体原因:
1. 内部封装了 Mapper 调用
ServiceImpl 内部已经持有了对应的 Mapper 实例(通过泛型注入),当调用 lambdaQuery() 时:
// 简化的实现逻辑
public class ServiceImpl<M extends BaseMapper<T>, T> implements IService<T> {@Autowiredprotected M baseMapper; // 已经注入了对应的Mapperpublic LambdaQueryChainWrapper<T> lambdaQuery() {return new LambdaQueryChainWrapper<>(baseMapper, entityClass);}
}
2. 链式调用最终会触发 Mapper 查询
LambdaQueryChainWrapper 采用链式编程设计,最终的方法调用(如 .list()、.one())会触发真正的查询:
// 示例用法 List<User> users = userService.lambdaQuery().eq(User::getName, "张三").gt(User::getAge, 18).list(); // 这里最终会调用baseMapper.selectList(wrapper)
3. 查询执行流程
-
构建条件:
.eq()、.gt()等方法构建查询条件 -
转换为 Wrapper:条件被转换为
LambdaQueryWrapper -
自动调用 Mapper:当调用终止方法(如
.list())时:-
自动调用
baseMapper.selectList(wrapper) -
或
baseMapper.selectOne(wrapper)等对应方法
-
-
返回结果:直接返回查询结果
4. 与直接使用 Mapper 的区别
| 方式 | 使用 Mapper | 使用 IService.lambdaQuery() |
|---|---|---|
| 代码示例 | mapper.selectList(wrapper) | service.lambdaQuery().eq().list() |
| 条件构造 | 需要先创建 Wrapper | 链式直接构造 |
| Mapper 调用 | 显式调用 | 隐式自动调用 |
| 返回结果 | 直接返回 | 通过终止方法返回 |
| 适用场景 | 复杂SQL/自定义SQL | 简单条件查询 |
5. 设计优势
-
简化代码:避免手动创建 Wrapper 和调用 Mapper
-
链式编程:更流畅的API体验
-
保持一致性:与其他 MyBatis-Plus 特性(如
LambdaUpdateWrapper)风格统一 -
降低学习成本:对新手更友好
这种设计让 Service 层能够更自然地表达查询意图,而不需要关心底层的 Mapper 调用细节,是 MyBatis-Plus 对经典三层架构的一种优雅改进。
5、mybatis怎么处理枚举字段的?
MyBatis 提供了多种灵活的方式来处理枚举字段的映射,以下是主要的处理方式及实现方法:
1. 默认枚举映射(无需配置)
MyBatis 内置了 EnumTypeHandler,默认将枚举的 名称(name()) 与数据库字段(字符串类型)直接映射。例如:
public enum Gender { MALE, FEMALE }数据库字段为 VARCHAR 时,MALE 会存储为 "MALE",查询时自动转换回枚举
2、使用注解简化配置(MyBatis 3.4.5+)
通过 @EnumValue 注解指定枚举的存储属性,无需自定义 TypeHandler:
public enum UserStatus { @EnumValue(1) ACTIVE, @EnumValue(0) INACTIVE; }MyBatis 会自动识别注解并处理映射
3、枚举与动态 SQL
在动态 SQL 中直接使用枚举实例,MyBatis 会自动调用对应的 TypeHandler:
<select id="selectUsers" resultType="User"> SELECT * FROM user WHERE
status = #{status}
</select>6、 那为什么需要在返回值前写<T>呢?
1、区分泛型方法与泛型类
泛型类的类型参数(如 class Box<T>)作用于整个类,但泛型方法的类型参数(如 <T> void print(T t))仅作用于当前方法。
若方法需要独立的泛型类型(与类泛型无关),必须在返回值前声明 <T>,否则编译器会认为 T 是类定义的泛型参数
public class Box<T> { // 类泛型public <U> void inspect(U u) { // 方法泛型,U 独立于 TSystem.out.println("U: " + u.getClass());}
}2、静态方法必须声明泛型
静态方法无法访问类的泛型参数(因为类泛型在实例化时确定),若需使用泛型,必须单独声明 <T>
public static <T> T getFirst(List<T> list) { // 必须声明 <T> return list.get(0); }