leetcode-hot-100 (滑动窗口)
1. 无重复字符的最长子串
题目链接:无重复字符的最长子串
题目描述:给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串 的长度。
解答
如果题目中的字符串 s 仅由字母组成,那么我们可以创建一个大小为 char[26] 的数组,用来记录每个字母的出现次数。接着,使用双指针的方法:左指针(慢指针)和右指针(快指针)。每次右指针向右移动一位时,就将对应位置的字符加入到计数数组中。若此时该字符的计数值大于 1,说明出现了重复字符,于是我们需要不断向右移动左指针,直到所有字符的计数都恢复为 1 为止。这样可以动态维护一个不包含重复字符的子串。
通过上述方法,左指针和右指针所覆盖的区域实际上形成了一个“窗口”。每次右指针的移动相当于将窗口向前扩展一个位置,而左指针的移动则使窗口的范围缩小。这正是滑动窗口技术的核心思想。
然而,当前的问题在于字符串 s 不仅包含英文字母,还可能包括数字、符号和空格。为了处理这种情况,我们需要一种更通用的方法来记录每个字符的出现次数。不同于只使用大小为26的数组来存储字母的计数,我们可以考虑使用哈希表(或字典)来动态地记录所有可能出现的字符及其对应的计数值。
这个时候通过查找,可以发现 C++ 中的 unordered_set<char> chars; 是 C++ 中用于创建一个存储字符的无序集合(哈希集合)的方法。这种数据结构非常适合用于快速查找、插入和删除操作,因为它的平均时间复杂度为 O(1)。
具体有如下操作:
- 插入元素
chars.insert('a');
- 查找元素
使用 find() 方法来检查某个元素是否存在于集合中。如果存在,find() 返回一个指向该元素的迭代器;如果不存在,则返回 chars.end() - 删除元素
chars.erase('b');
- 遍历集合
for(char c : chars) {std::cout << c << " ";
}
- 检查集合大小
std::cout << "Set size: " << chars.size() << std::endl;
- 清空集合
chars.clear();
有了上面的相关基础,我们下面就可以来编写这道题目的代码了。
完整的代码如下(带注释):
class Solution {
public:int lengthOfLongestSubstring(string s) {// 使用 unordered_set 来记录当前窗口内已经包含的字符unordered_set<char> chars;// 双指针:左指针 left 和右指针 right,用于定义滑动窗口int left = 0, right = 0;// 用于记录最长无重复字符子串的长度int max_len = 0;// 获取字符串的长度,避免在循环中反复调用 size() 提高性能int len = s.size();// 开始滑动窗口遍历字符串while (right < len) {// 如果当前右指针指向的字符不在集合中,说明没有重复if (chars.find(s[right]) == chars.end()) {// 将该字符加入集合中chars.insert(s[right]);// 更新最大长度:当前窗口大小为 right - left + 1max_len = max(max_len, right - left + 1);// 右指针向右移动一位right++;} else {// 如果当前字符已经存在,则说明有重复字符// 此时需要将左指针右移,直到窗口中不再包含重复字符// 从集合中删除左指针对应的字符chars.erase(s[left]);// 左指针向右移动一位left++;}}// 返回最长无重复字符子串的长度return max_len;}
};
当然,C++ 中还可以使用 unordered_map<char, int> 来解决寻找最长不含重复字符的子字符串问题,相比于 unordered_set,unordered_map 不仅能记录某个字符是否出现在当前窗口中,还能记录该字符出现的次数。
具体的实现代码如下:
class Solution {
public:int lengthOfLongestSubstring(string s) {unordered_map<char, int> charCount;int left = 0, right = 0, max_len = 0, len = s.size();while (right < len) {if (charCount[s[right]] > 0) {charCount[s[left]]--;left++;} else {charCount[s[right]]++;max_len = max(max_len, right - left + 1);right++;}}return max_len;}
};
2. 找到字符串中所有字母异位词
题目链接:找到字符串中所有字母异位词
题目描述:给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
解答
我其实一开始的想法就是使用 unordered_set<char> chars 进行求解的,但是我在编码过程中,发现不对,因为可能这个 p 有重复的字符,这样的话,上述这个只能记录是否出现这个字符,但是不能统计该字符的频率。因此上述方法就不行了。编写到下面我就编不下去了。
// 这是错误代码
class Solution {
public:vector<int> findAnagrams(string s, string p) {unordered_set<char> chars;for (int i = 0; i < p.size(); i++) {chars.insert(p[i]);}int left=0,right=0,len=s.size();vector<int> result;while(right<len){if()}}
};
但是 C++ 中还可以使用 unordered_map<char, int> 来解决寻找最长不含重复字符的子字符串问题,相比于 unordered_set,unordered_map 不仅能记录某个字符是否出现在当前窗口中,还能记录该字符出现的次数。而这是解题的关键。
于是我基于上述思想编写下面的代码:
class Solution {
public:vector<int> findAnagrams(string s, string p) {unordered_map<char, int> charCount_p; // 存储p中字符及其频率unordered_map<char, int> charCount_win; // 存储当前窗口中字符及其频率int len_s = s.size();int len_p = p.size();// 如果p比s长,直接返回空结果if (len_p > len_s) return {};// 初始化p的字符频率表for (int i = 0; i < len_p; ++i) {charCount_p[p[i]]++;}int left = 0, right = 0;vector<int> result;while (right < len_s) {char currentChar = s[right];// 如果currentChar不在p中,整个窗口无效,重置窗口if (charCount_p.find(currentChar) == charCount_p.end()) {charCount_win.clear(); // 清空窗口统计left = right + 1; // 左指针跳过该无效字符} else {charCount_win[currentChar]++;// 如果当前字符频次超过了p中的频次,移动左指针缩小窗口while (charCount_win[currentChar] > charCount_p[currentChar]) {char leftChar = s[left];charCount_win[leftChar]--;if (charCount_win[leftChar] == 0) {charCount_win.erase(leftChar); // 移除计数为0的键值对}left++;}// 如果窗口大小正好等于p的长度,说明 OKif (right - left + 1 == len_p) {result.push_back(left);}}right++;}return result;}
};
上述代码的思路大致如下:
- 使用两个
unordered_map分别记录:charCount_p: 字符串p中每个字符的出现次数。charCount_win: 当前窗口中每个字符的出现次数。
- 遇到非法字符(不在
p中):清空窗口并让左指针跳过它。 - 遇到频次超标:不断移动左指针缩小窗口直到合法。
- 窗口大小等于
p.length():说明是异位词,将其起始索引加入结果集。
那上述代码有可以优化的地方吗,当然:
上述代码细致地处理了不同情况,例如遇到不在 p 中的非法字符和字符频次超标的情况,这使得逻辑相对复杂。然而,实际上我们可以简化这些处理过程。不论遇到何种情况,只要没有满足 charCount_win == charCount_p 的条件,则匹配肯定不会成功。因此,我们只需要区分两种情况编写代码:匹配成功 和 不成功。
具体来说,无需特别处理非法字符或频次超标的情况。每次调整窗口后,只需检查当前窗口的字符频率是否与 p 的字符频率完全一致。如果一致,则记录匹配成功的起始索引;如果不一致,则继续移动窗口,直到找到下一个可能的匹配或遍历结束。
于是代码可以修改如下:
class Solution {
public:vector<int> findAnagrams(string s, string p) {vector<int> result;if (p.size() > s.size()) return result; // 如果p比s长,直接返回空结果unordered_map<char, int> charCount_p; // 统计p中字符及其频率unordered_map<char, int> charCount_win; // 统计当前窗口中的字符频率// 初始化p的字符频率表for (char c : p) charCount_p[c]++;int left = 0, right = 0;int len_s = s.size();int len_p = p.size();while (right < len_s) {// 将右指针对应字符加入窗口频率表char rightChar = s[right];charCount_win[rightChar]++;// 当窗口大小超过p的长度时,左指针右移,缩小窗口if (right - left + 1 > len_p) {char leftChar = s[left];charCount_win[leftChar]--;if (charCount_win[leftChar] == 0) {charCount_win.erase(leftChar); // 如果减为0,从map中删除}left++;}// 检查当前窗口是否和p的字符频率一致if (charCount_win == charCount_p) {result.push_back(left);}right++;}return result;}
};
这样就大大简化了判断。
| 特性/步骤 | 第二段代码实现 | 第一段代码实现 |
|---|---|---|
| 数据结构 | 使用两个 unordered_map<char, int> 分别记录 p 中字符及其频率 (charCount_p) 和当前窗口中的字符频率 (charCount_win)。 | 同样使用两个 unordered_map<char, int> 来分别记录 p 和当前窗口的字符频率。 |
| 处理非法字符 | 直接将右指针指向的字符加入到窗口中,没有特别处理不在 p 中的字符。 | 遇到不在 p 中的字符时,清空当前窗口并让左指针跳过该字符,重新开始计数。 |
| 频次超标处理 | 当窗口大小超过 p 的长度时,简单地从窗口中移除左边界的字符,并调整窗口大小。 | 当某个字符的频次超过 p 中的频次时,通过移动左指针缩小窗口直到窗口内该字符的频次与 p 中相等。 |
| 匹配检查时机 | 每次调整完窗口后立即检查 charCount_win 是否等于 charCount_p。 | 只有当窗口大小恰好等于 p 的长度时,才进行匹配检查。 |
| 窗口调整逻辑 | 主要依赖于窗口大小是否超过了 p 的长度来进行调整。 | 主要依赖于字符频次是否超标来进行调整,同时考虑了非法字符的情况。 |
| 效率与准确性 | 这种方式虽然可以工作,但在每次循环中都进行完整的哈希表比较,可能会影响性能。 | 更加精细地控制窗口调整,减少了不必要的哈希表比较次数,理论上提高了效率。 |
| 代码复杂度 | 代码相对简洁,但缺少对特定情况(如非法字符)的处理。 | 代码稍微复杂一些,但是覆盖了所有边界情况,包括非法字符和频次超标的情况。 |
实际上,上述的编写还是比较复杂的,我们再看题目,注意到下面的话:
既然题目限定了字符都是小写字母,也可以用两个 int count_p[26] 和 count_win[26] 替代哈希表,效率更高。
官方代码也是这样实现的。

class Solution {
public:vector<int> findAnagrams(string s, string p) {int sLen = s.size(); // 主字符串长度int pLen = p.size(); // 模式字符串长度// 如果主字符串比模式字符串短,直接返回空结果if (sLen < pLen) {return vector<int>();}vector<int> ans; // 存储所有匹配的起始索引// 使用两个大小为26的数组来记录字符频率(只考虑小写字母)vector<int> sCount(26);vector<int> pCount(26);// 初始化:统计第一个窗口(前 pLen 个字符)中的字符频率for (int i = 0; i < pLen; ++i) {++sCount[s[i] - 'a']; // 将 s 的前 pLen 个字符频率统计进 sCount++pCount[p[i] - 'a']; // 统计 p 的字符频率}// 判断初始窗口是否匹配if (sCount == pCount) {ans.emplace_back(0); // 匹配则将起始索引 0 加入结果集}// 开始滑动窗口:从第 1 个位置开始,直到不能再形成一个完整窗口为止for (int i = 0; i < sLen - pLen; ++i) {// 窗口左边界右移一位:移除窗口最左边的字符--sCount[s[i] - 'a'];// 窗口右边界右移一位:加入新的右边界的字符++sCount[s[i + pLen] - 'a'];// 检查当前窗口是否与 p 的字符频率一致if (sCount == pCount) {// 若一致,则当前窗口的起始位置是 i + 1ans.emplace_back(i + 1);}}return ans;}
};
其实和我前面的差不多,判断初始位置,然后每次移进一个右字符,弹出一个左字符,然后再进行判断。

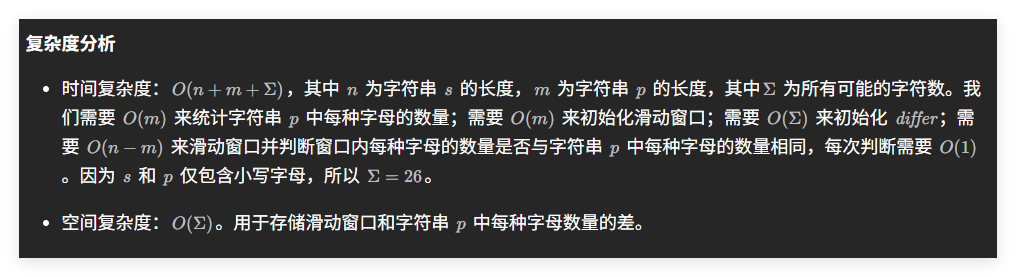
官方还给出了一种优化的方式:

class Solution {
public:vector<int> findAnagrams(string s, string p) {int sLen = s.size(), pLen = p.size();// 如果主串长度小于模式串,直接返回空结果if (sLen < pLen) {return vector<int>();}vector<int> ans; // 存储所有匹配的起始索引vector<int> count(26); // 用于记录每个字符在窗口和 p 中的差值for (int i = 0; i < pLen; ++i) {++count[s[i] - 'a']; // 当前窗口中的字符增加--count[p[i] - 'a']; // 模式串中的字符减少}// 统计当前窗口中有多少字符与 p 中的数量不同int differ = 0;for (int j = 0; j < 26; ++j) {if (count[j] != 0) {++differ;}}// 如果初始窗口中没有差异,说明是异位词if (differ == 0) {ans.emplace_back(0);}// 开始滑动窗口:从第1个位置开始,直到不能再形成完整窗口为止for (int i = 0; i < sLen - pLen; ++i) {char leftChar = s[i]; // 即将移出窗口的字符(左边界)char rightChar = s[i + pLen]; // 即将加入窗口的字符(右边界)// 处理即将移出窗口的字符if (count[leftChar - 'a'] == 1) {// 之前这个字符比 p 多一个,现在要减掉,会导致差异减少--differ;} else if (count[leftChar - 'a'] == 0) {// 之前相同,现在会变不同,所以差异增加++differ;}--count[leftChar - 'a']; // 实际减去该字符// 处理即将加入窗口的字符if (count[rightChar - 'a'] == -1) {// 之前这个字符比 p 少一个,现在补上,差异减少--differ;} else if (count[rightChar - 'a'] == 0) {// 之前相同,现在变不同,差异增加++differ;}++count[rightChar - 'a']; // 实际加上该字符// 如果当前窗口中所有字符都匹配,即差异为0,则找到一个异位词if (differ == 0) {ans.emplace_back(i + 1); // 加入当前窗口的起始索引}}return ans;}
};
| 步骤 | 功能描述 |
|---|---|
| 初始化窗口 | 先统计第一个窗口(前 p.length() 个字符)与 p 的字符频率差 |
| 计算差异数 | 统计当前窗口中有多少字符与 p 不一致 |
| 滑动窗口 | 每次只处理窗口首尾两个字符的变化,更新 count 和 differ |
| 判断匹配 | 若 differ == 0,则当前窗口是一个异位词 |
官方给的第二段优化滑动窗口的代码,有下面的问题需要解释一下:
问题
在这段代码中:
- 处理
leftChar(即将移出窗口的字符)时,为什么只判断count[leftChar - 'a'] == 1或== 0? - 为什么不处理
count[leftChar - 'a'] == -1的情况? - 同理,处理
rightChar时,为什么不处理count[rightChar - 'a'] == 1?
一、关于 leftChar 的判断为何不考虑 count[leftChar - 'a'] == -1
代码片段
if (count[leftChar - 'a'] == 1) {--differ;
} else if (count[leftChar - 'a'] == 0) {++differ;
}
--count[leftChar - 'a'];
解析
当我们将一个字符 leftChar 移出窗口时:
- 如果它在当前窗口中比
p多了 1 个(即count[leftChar - 'a'] == 1),那么减去这个字符后,就变成一样多了 → 差异数减少。 - 如果它在当前窗口中与
p相等(即count[leftChar - 'a'] == 0),那么减去之后就不相等了 → 差异数增加。
为什么没有处理 count[leftChar - 'a'] == -1?
因为 count[leftChar - 'a'] == -1 表示:当前窗口中该字符比 p 少了一个,也就是它已经在“差异”中了。
而我们现在只是从窗口中 再减去一个字符,只会让这个差距更大(变成 -2)。所以:
- 它本来就在差异里(count != 0)
- 减完以后还在差异里(count != 0)
➡️ 所以differ不会变化,不需要做任何调整。
二、关于 rightChar 的判断为何不考虑 count[rightChar - 'a'] == 1
代码片段
if (count[rightChar - 'a'] == -1) {--differ;
} else if (count[rightChar - 'a'] == 0) {++differ;
}
++count[rightChar - 'a'];
解析
当我们将一个字符 rightChar 加入窗口时:
- 如果它在当前窗口中比
p少了 1 个(即count[rightChar - 'a'] == -1),加上这个字符后,就变成一样多了 → 差异数减少。 - 如果它在当前窗口中与
p相等(即count[rightChar - 'a'] == 0),那么加上之后就不相等了 → 差异数增加。
为什么没有处理 count[rightChar - 'a'] == 1?
如果 count[rightChar - 'a'] == 1,表示当前窗口中该字符已经比 p 多了一个。
现在再加上一个,就会变成多两个,仍然处于“差异”状态(count != 0)。
➡️ 所以 differ 不变,不需要处理。
总结
我们只关心字符是否从“差异状态”进入“相同状态”,或者从“相同状态”进入“差异状态”。其他情况下,字符仍处于“差异状态”,不影响 differ 的值。
| 条件 | 是否影响 differ | 原因 |
|---|---|---|
count[x] == 1(移出) | 是 | 从“多一个”变成“一样”,差异数减少 |
count[x] == 0(移出) | 是 | 从“一样”变成“少一个”,差异数增加 |
count[x] == -1(移出) | 否 | 从“少一个”变成“少两个”,仍在差异中 |
count[x] == -1(加入) | 是 | 从“少一个”变成“一样”,差异数减少 |
count[x] == 0(加入) | 是 | 从“一样”变成“多一个”,差异数增加 |
count[x] == 1(加入) | 否 | 从“多一个”变成“多两个”,仍在差异中 |