常微分方程(OTD)和偏微分方程(PDE),以及混合精度
常微分方程(ODE)与偏微分方程(PDE)的区别
1. 常微分方程(Ordinary Differential Equation, ODE)
-
定义:仅涉及一个自变量(如时间 t)的函数及其导数。
-
形式:例如)dt/dy=f(t,y),描述单一变量变化的动态系统。

2. 偏微分方程(Partial Differential Equation, PDE)
-
定义:涉及多个自变量(如空间 x,y,z 和时间 t)的函数及其偏导数。
-
形式:例如热传导方程 ∂t∂u=α∇2u。

为什么使用混合精度训练?
1. 显存效率提升
-
FP16(16位浮点)相比FP32(32位)显存占用减半,允许更大的批次大小(Batch Size)。
-
例如:RTX 3090的24GB显存,FP32下训练ResNet-50的Batch Size为256,FP16可增至512。
-
2. 计算速度加快
-
NVIDIA Tensor Core对FP16矩阵运算有4-8倍加速(如A100的312 TFLOPS for FP16 vs 19.5 TFLOPS for FP32)。
3. 通信带宽优化
-
分布式训练中,梯度通信量减少50%(如Horovod的FP16 AllReduce)。
4. 数值稳定性保障
-
关键操作(如梯度累加、Softmax)保留FP32,避免下溢(Underflow)和舍入误差
-
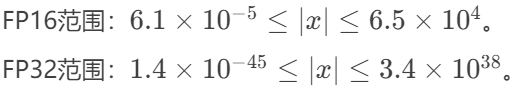
如何实现混合精度训练?
步骤1:启用自动混合精度(AMP)
-
PyTorch示例:
from torch.cuda.amp import autocast, GradScalerscaler = GradScaler() # 梯度缩放器for data, target in dataloader:optimizer.zero_grad()with autocast(): # 自动转换FP16output = model(data)loss = criterion(output, target)scaler.scale(loss).backward() # 缩放梯度scaler.step(optimizer) # 更新参数(自动转FP32)scaler.update() # 调整缩放系数
步骤2:关键配置
-
梯度缩放(Gradient Scaling):
-
防止FP16下梯度值过小被舍入为0。
-
动态调整缩放因子(通常初始值=65536),根据梯度溢出情况自动调整。
-
-
白名单(FP32)操作:
-
包括Softmax、LogSoftmax、LayerNorm等对数值敏感的操作。
-
步骤3:监控与调试
-
检测溢出:PyTorch的
scaler._scale若频繁变化(如减半),表明梯度溢出。 -
典型调整:
-
增大
batch_size或降低scaler.init_scale。 -
对特定层强制FP32:
module.to(torch.float32)。
-
框架支持
| 框架 | 工具 | 关键特性 |
|---|---|---|
| PyTorch | torch.cuda.amp | 动态损失缩放,自动类型转换 |
| TensorFlow | tf.keras.mixed_precision | 策略式配置,全局控制 |
| JAX | jax.experimental.mixed_precision | 与pmap/pjit无缝集成 |
混合精度训练的注意事项
-
硬件要求:
-
需GPU支持FP16加速(如NVIDIA Pascal架构及以上)。
-
避免在非Tensor Core GPU(如GTX 10系列)上强制启用。
-
-
模型适应性:
-
某些模型(如低维嵌入层)可能需手动转为FP32。
-
损失函数需对FP16鲁棒(如交叉熵中使用
LogSoftmax而非手动实现)。
-
-
性能调优:
-
使用
NVIDIA Nsight Systems分析FP16利用率。 -
确保数据管道不成为瓶颈(预处理使用CPU或GPU加速)。
-
实例:训练ResNet-50的混合精度优化
-
显存对比:
-
FP32:每张V100 16GB,Batch Size=128。
-
FP16:Batch Size=256,训练速度提升2.1倍。
-