HTTP协议解析:Session/Cookie机制与HTTPS加密体系的技术演进(一)
一.HTTP协议
我们上篇文章已经提到了对于自定义协议的序列化与反序列化。那么有没有什么比较成熟的,大佬们写的应用层协议,供我们参考使用呢?HTTP(超文本传输协议)就是其中之一。
在互联网世界中, HTTP(HyperText Transfer Protocol, 超文本传输协议) 是一个至关重要的协议。 它定义了客户端(如浏览器) 与服务器之间如何通信, 以交换或传输超文本(如 HTML 文档) 。
HTTP 协议是客户端与服务器之间通信的基础。 客户端通过 HTTP 协议向服务器发送请求, 服务器收到请求后处理并返回响应。 HTTP 协议是一个无连接、 无状态的协议, 即每次请求都需要建立新的连接, 且服务器不会保存客户端的状态信息。
TIPS:超文本传输通俗的来说就是指传输的文件类型不仅限于文本,还可以是图片,视频等等。
1.1什么是URL
 通俗点来说URL就是我们平常所说的网址, 但图中部分的消息我们现在一般很少或根本不可能从URL上看到:
通俗点来说URL就是我们平常所说的网址, 但图中部分的消息我们现在一般很少或根本不可能从URL上看到:
- 登录信息(user:pass@)。这个其实不可能看到的原因很简单,因为没有人会把自家钥匙直接挂在门上。这部分现在都以登录页面输入密码或手机验证码等更安全的形式替代了。
- 显示端口号(:80)。以前在HTTP(:80)或HTTPS(:443)不常用的时候,为了让用户辨清那个是我网站的"门",一般会带上。但现在对于HTTP/HTTPS已经很成熟了,浏览器会默认加上80或443,所以一般是不带上的现在。但如果说是我们自己在服务器创建的服务,比如他的服务端口号8080,这个时候就需要带上了。
- 带扩展名的路径(/dir/index.htm)。以前的时候网址直接对应服务器上的文件路径,也就是说/dir/index.htm这个文件是在服务器中真实存在的。但现在一般都使用的动态生成内容比如dy的/video/123不是真实文件,将文件扩展名隐藏了起来,更加简介与安全。
- 查询字符串(?uid=1)和片段(#ch1)。以前
?uid=1传参数、#ch1跳转到章节,像在网址里手写操作说明。现在参数可能藏在路由里(比如/user/1代替?uid=1)。#ch1更多用于网页内跳转(比如点目录跳章节),而单页应用(如抖音)用它控制页面切换。
1.2urlencode 和 urldecode
像 / ? : 等这样的字符, 已经被 url 当做特殊意义理解了。因此这些字符不能随意出现.比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义。
转义的规则如下:
将需要转码的字符转为 16 进制, 然后从右到左, 取 4 位(不足 4 位直接处理), 每 2 位做一位, 前面加上%, 编码成%XY 格式。
比如:
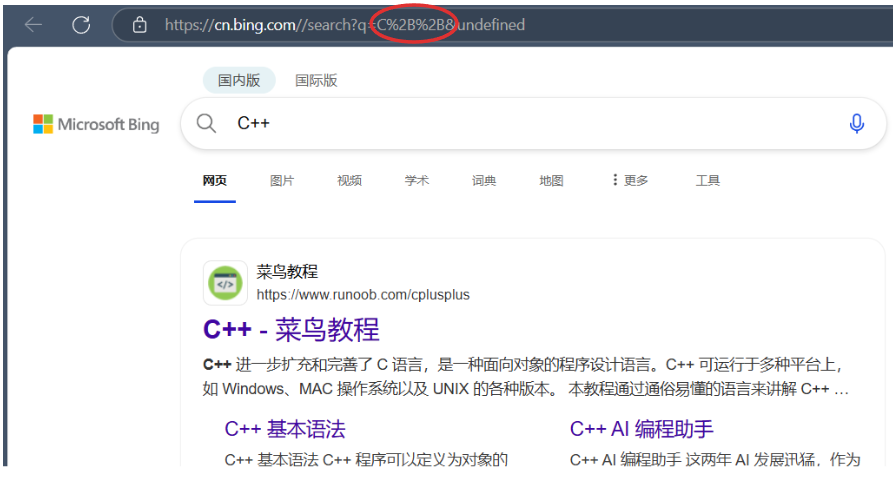
可以看到+被转义为了%2B。urldecode 就是 urlencode 的逆过程;
UrlEncode编码/UrlDecode解码 - 站长工具
1.3HTTP协议请求与响应格式
一个请求报文示例如下:
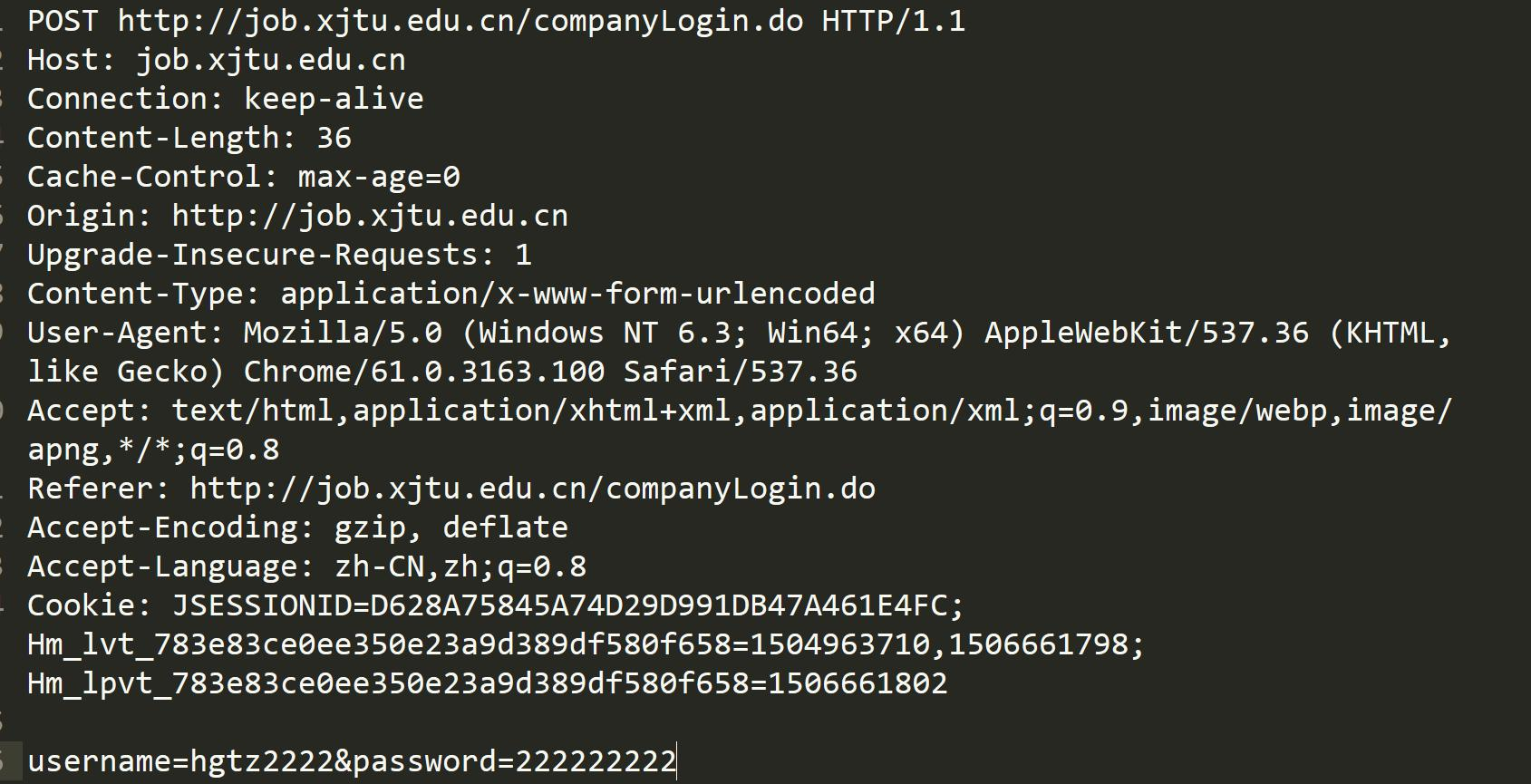
而对于HTTP的请求与应答报文结构通常如下:
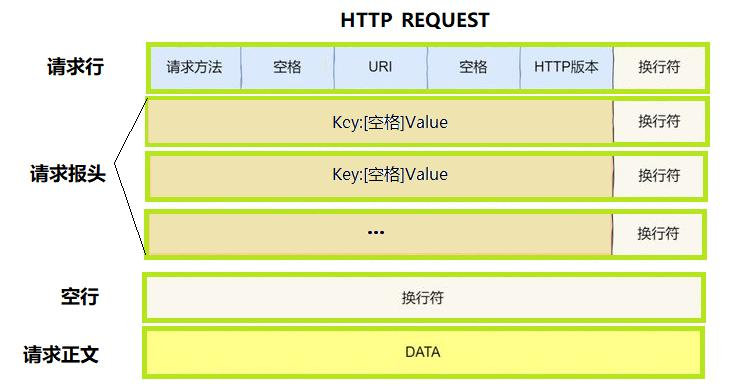

对于请求报文REQUSET第一行为空行,接下来为请求报头,请求报头以空行与正文内容分离。 应答报文也是类似。
基本的应答格式:
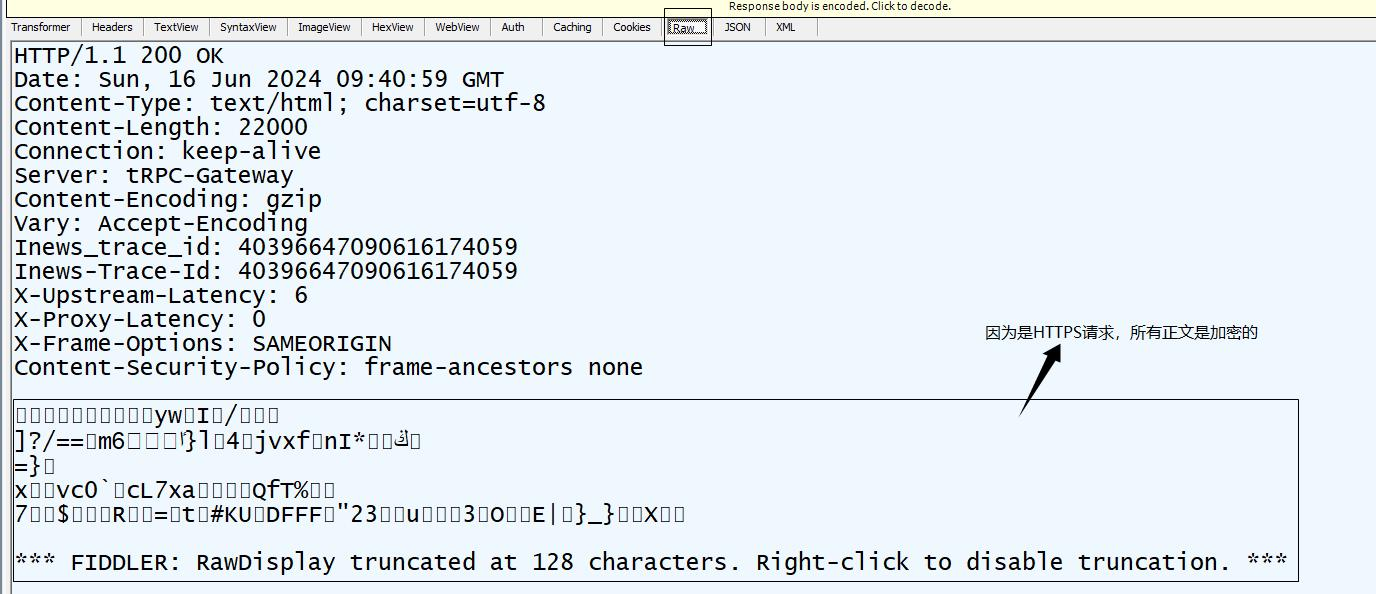
应答的正文内容一般是html,css,图片,音频,视频等文件。 这个图片中的Content-Type:text/html说明应答文件类型是html的,Content-Lenth说明正文长度为22000。Conection等我们后面部分重要的会提到。
1.4HTTP方法
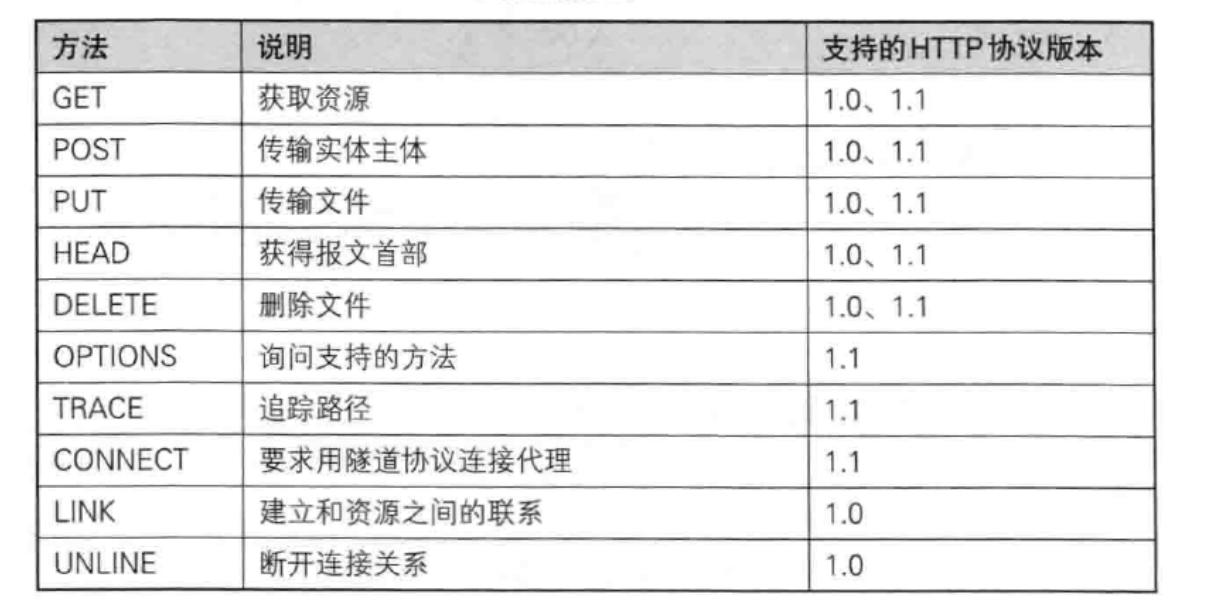 一般最经常使用的为GET与POST方法。如果说所有方法的使用机率和为100%,那么他俩一共就占到90%甚至更高。
一般最经常使用的为GET与POST方法。如果说所有方法的使用机率和为100%,那么他俩一共就占到90%甚至更高。
1.4.1GET方法与POST方法(重点)
简单的理解,GET就是获取资源,POST就是上传资源。我们一般的上网行为通常无非就两种,上传和获取。又因为我们网络通信其实本质上是进程间通信,也就是说我们上网本质就是IO。
GET一般从服务器获取图片,音频,html网页等静态资源。虽说POST一般用于上传资源,但我们也可以使用GET上传资源。不过后者上传的资源大小一般是有限的。
1. GET 的限制:URL 长度问题
GET 的数据是放在 URL 里的,比如:
https://example.com/login?username=admin&password=123456
浏览器和服务器对 URL 长度有限制(通常 2048~8192 字符),太长的 URL 会被截断或报错。就像写信时地址栏写不下太多字,信封(URL)塞太多内容会被邮局拒收。
2. POST 的优势:数据放在“信封内部”POST 的数据是放在 HTTP 请求的“正文”(body)里的,比如:
<form method="POST" action="/login"><input type="text" name="username" value="admin"><input type="password" name="password" value="123456"> </form>
服务器不会限制 POST 数据大小(但实际仍受服务器配置影响,比如 PHP 默认限制 8MB)。就像把内容写在信纸(body)里,信封(URL)只写收件地址,能塞更多内容。

HTML 表单 | 菜鸟教程
1.4.2PUT方法(不常用)
PUT 方法的核心作用:将数据(如文件、JSON)上传到服务器的指定位置,并让服务器按你给的 URL 路径完整保存。类比:就像你往网盘(服务器)上传文件,并明确告诉它:“把这个文件 精确 存到 /docs/report.pdf 这个路径下”。
所以我们说PUT方法上传的方式过于暴力。我要把这个文件 精确 放到 /path/xxx,不管原来有什么,直接覆盖!一般人家自己的服务器怎么可能不由分说就让你覆盖人家原有的文件,所以一般是被服务器禁止使用的。
1.4.3Head方法
与 GET 方法类似, 但不返回报文主体部分, 仅返回响应头。比如:HEAD /index.html HTTP/1.1用于确认 URL 的有效性及资源更新的日期时间等。
// curl -i 显示
$ curl -i www.baidu.com
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: private, no-cache, no-store, proxy-revalidate, notransform
Connection: keep-alive
Content-Length: 2381
Content-Type: text/html
Date: Sun, 16 Jun 2024 08:38:04 GMT
Etag: "588604dc-94d"
Last-Modified: Mon, 23 Jan 2017 13:27:56 GMT
Pragma: no-cache
Server: bfe/1.0.8.18
Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/
<!DOCTYPE html>
...
// 使用 head 方法, 只会返回响应头
$ curl --head www.baidu.com
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: private, no-cache, no-store, proxy-revalidate, notransform
Connection: keep-alive
Content-Length: 277
Content-Type: text/html
Date: Sun, 16 Jun 2024 08:43:38 GMT
Etag: "575e1f71-115"
Last-Modified: Mon, 13 Jun 2016 02:50:25 GMT
Pragma: no-cache
Server: bfe/1.0.8.181.4.4DELETE方法(不常用)
用于删除文件, 是 PUT 的相反方法。比如: DELETE /example.html HTTP/1.1。按请求 URL 删除指定的资源。所以不用多说为什么不常用,和PUT一样一般都是被禁止的。
1.4.5OPTIONS方法
用于查询针对请求 URL 指定的资源支持的方法。示例:OPTIONS * HTTP/1.1。返回允许的方法, 如 GET、 POST 等。
不支持的效果
// 搭建一个 nginx 用来测试
// sudo apt install nginx
// sudo nginx -- 开启
// ps ajx | grep nginx -- 查看
// sudo nginx -s stop -- 停止服务
$ sudo nginx -s stop
$ ps ajx | grep nginx
2944845 2945390 2945389 2944845 pts/1 2945389 S+ 1002 0:00
grep --color=auto nginx
$ sudo nginx
$ ps axj | grep nginx
1 2945393 2945393 2945393 ? -1 Ss 0 0:00
nginx: master process nginx
2945393 2945394 2945393 2945393 ? -1 S 33 0:00
nginx: worker process
2945393 2945395 2945393 2945393 ? -1 S 33 0:00
nginx: worker process
2944845 2945397 2945396 2944845 pts/1 2945396 S+ 1002 0:00
grep --color=auto nginx
// -X(大 x) 指明方法
$ curl -X OPTIONS -i http://127.0.0.1/
HTTP/1.1 405 Not Allowed
Server: nginx/1.18.0 (Ubuntu)
Date: Sun, 16 Jun 2024 08:48:22 GMT
Content-Type: text/html
Content-Length: 166
Connection: keep-alive
<html>
<head><title>405 Not Allowed</title></head>
<body>
<center><h1>405 Not Allowed</h1></center>
<hr><center>nginx/1.18.0 (Ubuntu)</center>
</body>
</html>405Not ALLowed就表示服务器不想告诉客户端我支持什么HTTP请求方法。
支持的效果
HTTP/1.1 200 OK
Allow: GET, HEAD, POST, OPTIONS
Content-Type: text/plain
Content-Length: 0
Server: nginx/1.18.0 (Ubuntu)
Date: Sun, 16 Jun 2024 09:04:44 GMT
Access-Control-Allow-Origin: *
Access-Control-Allow-Methods: GET, POST, OPTIONS
Access-Control-Allow-Headers: Content-Type, Authorization
// 注意: 这里没有响应体, 因为 Content-Length 为 0说明当前该服务端口支持GET,HEAD,POST,OPTIONS这四种方法。
1.5HTTP状态码
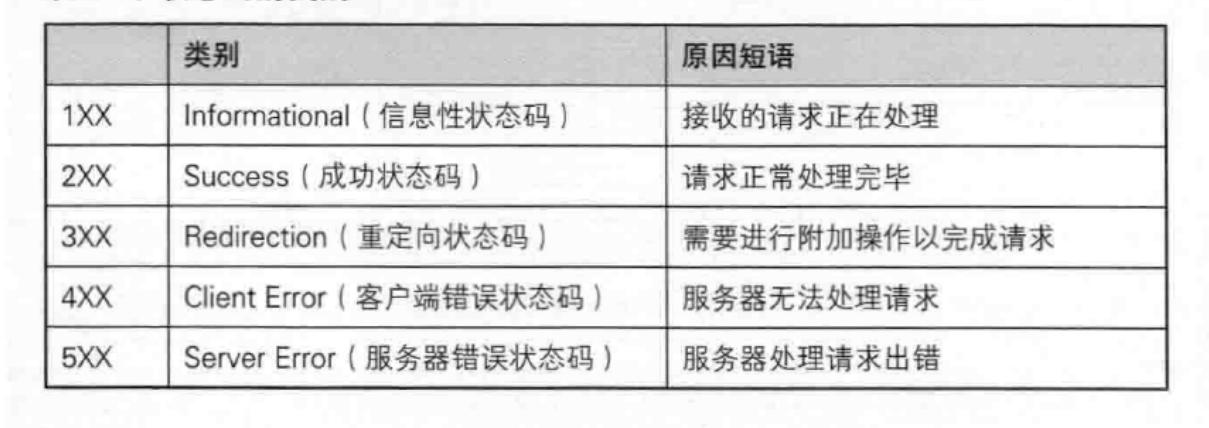
最常见的状态码, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)。
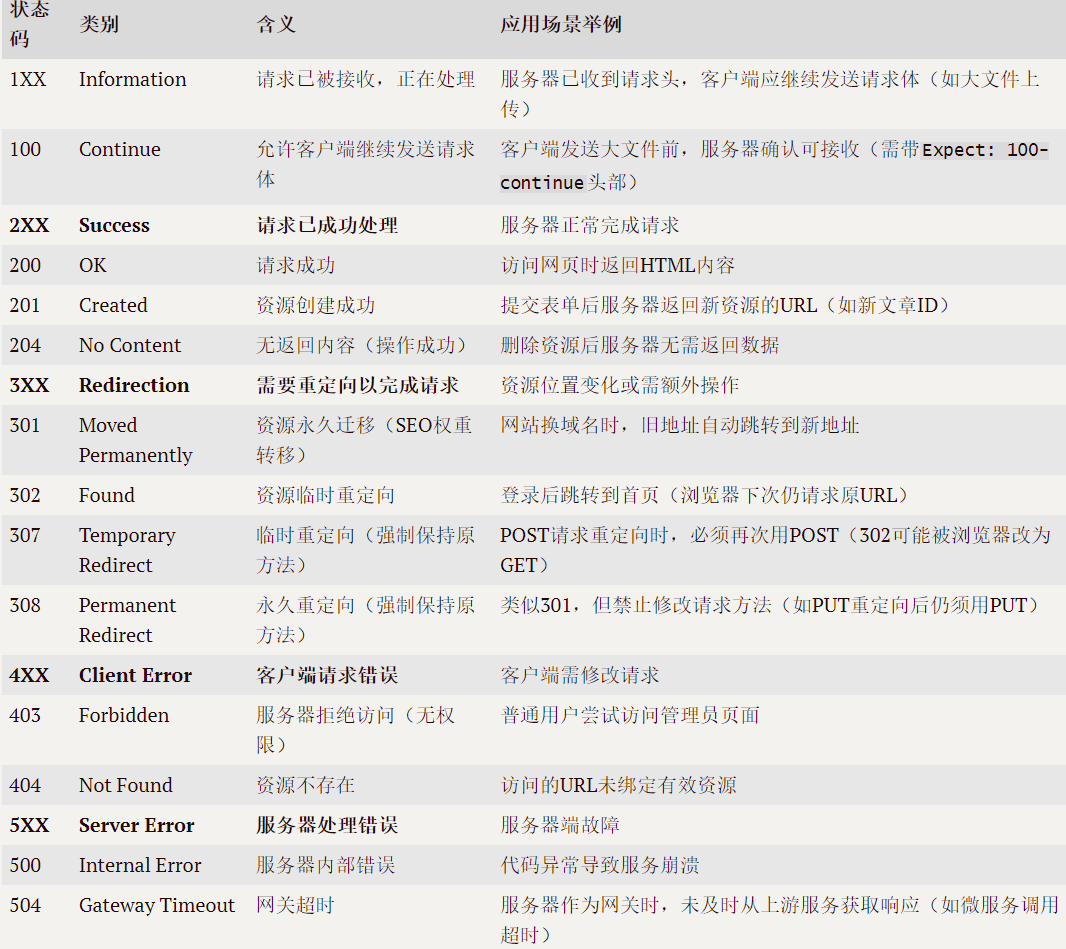
需要注意的是,网站返回的状态码因为没有严格要求程序员一般都不认真写的原因,其实可信度不大。还有安全方面的问题。比如服务器崩了的时候,为了防止一些人趁病要命,一般不会给你返回5XX的状态码,要么直接返回OK,要么返回404。
关于重定向的验证, 以 301 为代表
HTTP 状态码 301(永久重定向) 和 302(临时重定向) 都依赖 Location 选项。 以下是关于两者依赖 Location 选项的详细说明:
HTTP 状态码 301(永久重定向) :
当服务器返回 HTTP 301 状态码时, 表示请求的资源已经被永久移动到新的位置。在这种情况下, 服务器会在响应中添加一个 Location 头部, 用于指定资源的新位置。 这个 Location 头部包含了新的 URL 地址, 浏览器会自动重定向到该地址。例如, 在 HTTP 响应中, 可能会看到类似于以下的头部信息:
HTTP/1.1 301 Moved Permanently\r\n
Location: https://www.new-url.com\r\nHTTP 状态码 302(临时重定向) :
当服务器返回 HTTP 302 状态码时, 表示请求的资源临时被移动到新的位置。同样地, 服务器也会在响应中添加一个 Location 头部来指定资源的新位置。 浏览器会暂时使用新的 URL 进行后续的请求, 但不会缓存这个重定向。例如, 在 HTTP 响应中, 可能会看到类似于以下的头部信息:
HTTP/1.1 302 Found\r\n
Location: https://www.new-url.com\r\n总结: 无论是 HTTP 301 还是 HTTP 302 重定向, 都需要依赖 Location 选项来指定资源的新位置。 这个 Location 选项是一个标准的 HTTP 响应头部, 用于告诉浏览器应该将请求重定向到哪个新的 URL 地址。
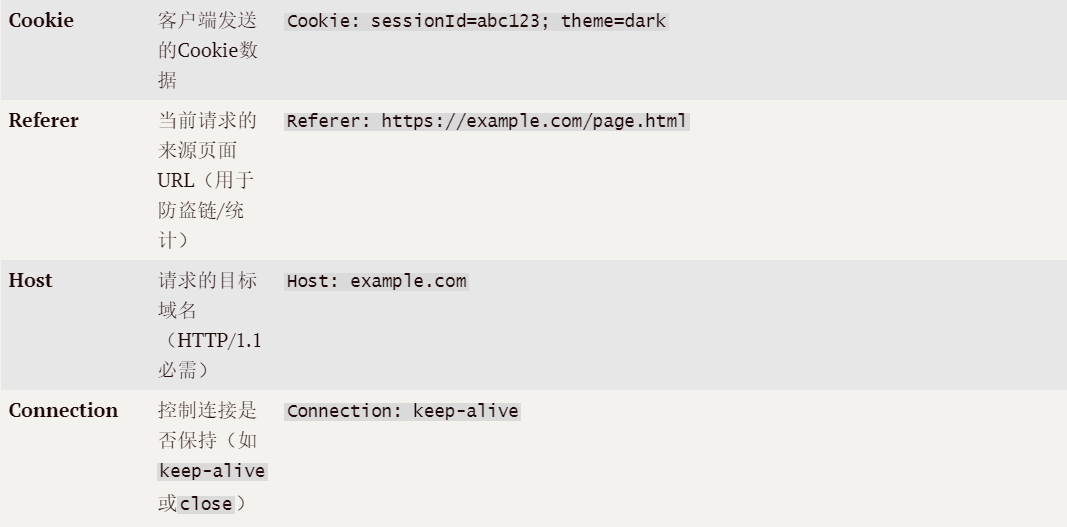
1.6HTTP常见Header
- Content-Type: 数据类型(text/html 等)
- Content-Length: Body 的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- Location: 搭配 3xx 状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;(后面会细讲)
关于 connection 报头
HTTP 中的 Connection 字段是 HTTP 报文头的一部分, 它主要用于控制和管理客户端与服务器之间的连接状态。
核心作用
管理持久连接: Connection 字段还用于管理持久连接(也称为长连接) 。 持久连接允许客户端和服务器在请求/响应完成后不立即关闭 TCP 连接, 以便在同一个连接上发送多个请求和接收多个响应。
持久连接(长连接)
HTTP/1.1: 在 HTTP/1.1 协议中, 默认使用持久连接。 当客户端和服务器都不明确指定关闭连接时, 连接将保持打开状态, 以便后续的请求和响应可以复用同一个连接。
HTTP/1.0: 在 HTTP/1.0 协议中, 默认连接是非持久的。 如果希望在 HTTP/1.0上实现持久连接, 需要在请求头中显式设置 Connection: keep-alive。
语法格式
Connection: keep-alive: 表示希望保持连接以复用 TCP 连接。
Connection: close: 表示请求/响应完成后, 应该关闭 TCP 连接。HTTP常见Header的表格

1.7模拟实现一个最简单的HTTP服务器
实现一个最简单的 HTTP 服务器, 只在网页上输出 "hello world"; 只要我们按照 HTTP协议的要求构造数据, 就很容易能做到,就是把下面的功能模块在前文的代码上换个功能函数即可。
Http.hpp
#pragma once#include "Socket.hpp"
#include "TcpServer.hpp"
#include <iostream>
#include <string>
#include <memory>
#include <unordered_map>
#include "Util.hpp"using namespace socket_module;const std::string gspace = " ";
const std::string glinespace = "\r\n";//http换行符const std::string webroot = "./wwwroot";//web根目录
const std::string homepage = "/home.html";//web首页
const std::string glinesep = ": ";//http报头分隔符class HttpRequest
{
public:HttpRequest(){}//请求序列化std::string Serialize(){return std::string();}//请求反序列化bool Deserialize(std::string &reqstr){return true;}~HttpRequest(){}private:std::string _method;//请求方法std::string _uri;//统一资源定位符,通俗点来说就是网址std::string _version;//Http版本std::unordered_map<std::string, std::string> _headers;//请求行std::string _blankline;//空行分隔符std::string _text;//请求正文内容
};class HttpResponse
{
public:HttpResponse() : _blankline(glinespace){}//应答序列化std::string Serialize(){std::string status_line = _version + gspace + std::to_string(_code) + gspace + _desc + glinespace;std::string resp_header;_headers["Set-Cookie"] = "zhangsan=Xiu123hehe@";for (auto &header : _headers){std::string line = header.first + glinesep + header.second + glinespace;resp_header += line;}return status_line + resp_header + _blankline + _text;}//应答反序列化bool Deserialize(std::string &reqstr){return true;}~HttpResponse() {}// private:
public:std::string _version;//http版本int _code;//状态码std::string _desc;//状态码描述 std::unordered_map<std::string, std::string> _headers;//应答报头std::string _blankline;//空行分割符std::string _text;//应答正文内容
};class Http
{
public:Http(uint16_t port):tsvrp(std::make_unique<TcpServer>(port)){}void HandlerHttpRquest(std::shared_ptr<Socket> &sock, InetAddr &client){#ifndef DEBUG#define DEBUGstd::string httpreqstr;// 假设:直接读到了完整的请求sock->Recv(&httpreqstr); std::cout << httpreqstr;// 直接构建最简单的http应答HttpResponse resp;resp._version = "HTTP/1.1";resp._code = 200; // successresp._desc = "OK";std::string filename = webroot + homepage;bool res = Util::ReadFileContent(filename, &(resp._text));(void)res;std::string response_str = resp.Serialize();sock->Send(response_str);#endif}void Start(){tsvrp->Start([this](std::shared_ptr<Socket> &sock, InetAddr client){ this->HandlerHttpRquest(sock, client); });}~Http(){}private:std::unique_ptr<TcpServer> tsvrp;
};Util.hpp
#pragma once #include <iostream>
#include <fstream>
#include <string>// 工具类class Util
{
public://读取html文件内容到out中static bool ReadFileContent(const std::string &filename, std::string *out){// version1 字节流读取,但文件传输时默认是二进制传输,所以该版本无法传输图片// std::ifstream in(filename);// if (!in.is_open())// {// return false;// }// std::string line;// while(std::getline(in, line))// {// *out += line;// }// in.close();// return true;int filesize = FileSize(filename);if(filesize > 0){std::ifstream in(filename);if(!in.is_open())return false;out->resize(filesize);in.read((char*)(out->c_str()), filesize);in.close();}else{return false;}return true;}//读取请求或应答的一行将其提取出来并从源请求或应答中删除static bool ReadOneLine(std::string &bigstr, std::string *out, const std::string &sep/*\r\n*/){auto pos = bigstr.find(sep);if(pos == std::string::npos)return false;*out = bigstr.substr(0, pos);bigstr.erase(0, pos + sep.size());return true;}//读取文件的大小static int FileSize(const std::string &filename){std::ifstream in(filename, std::ios::binary);if(!in.is_open())return -1;in.seekg(0, in.end);int filesize = in.tellg();in.seekg(0, in.beg);in.close();return filesize;}
};注意,需要在当前目录下创建一个目录wwwroot,并在当前目录下放一个能够打印hello world的html文件home.html。这个html文件直接询问ai生成即可。我们这里不再介绍html。
1.8HTTP版本
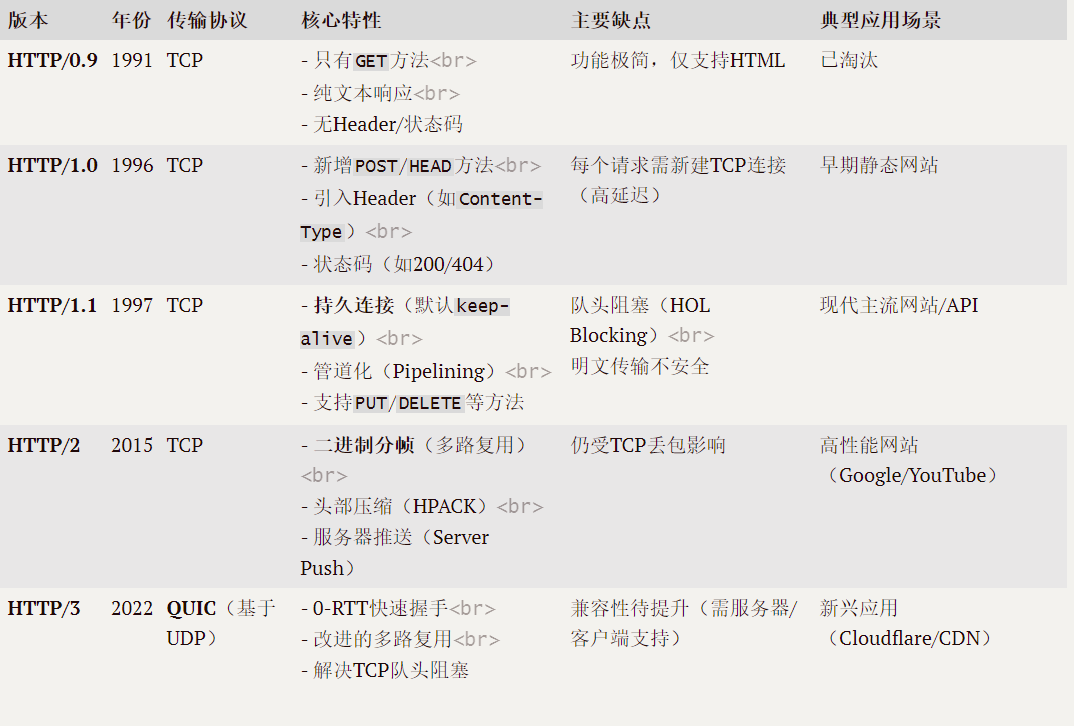
对于HTTP的Cookie与Session和Https,主要是http安全方面的问题。由于篇幅问题,我们放到下篇文章进行拆解介绍。