关于输入法重码率的计算
本人在电脑上一直使用的86版五笔输入法。在手机上之前使用的是9宫全拼,后来使用了基于Rime框架的同文输入法,没有九宫全拼了;然后就自己配置了一个四角号码输入法。
如果有兴趣的可以移步:四角号码输入法介绍、四角号码配置仓库
四角号码输入法用下来感觉还是不错的,使用九宫格键盘,按键大,不易误触。
在调查四角号码输入法可行性的时候,也考虑和计算了重码率这个概念。统计的思路是统计码表内的总字数作为基准,计算存在同码字的字数,与之相除得到的比例值作为重码率。所使用的码表文件见: 四角号码码表 四码+五码+六码 收录汉字及部件约 7w5 个
统计脚本
统计码表的重码率 python 脚本如下:
# -*- coding:UTF-8 -*-
"""
@author: dyy
@contact: douyaoyuan@126.com
@time: 2025/4/18 12:01
@file: 字典组词方案验证.py
@desc: xxxxxx
"""# region 引入必要的依赖
import os模块名 = 'DebugInfo'
try:from DebugInfo.DebugInfo import *
except ImportError as impErr:print(f"尝试导入 {模块名} 依赖时检测到异常:{impErr}")print(f"尝试安装 {模块名} 模块:")try:os.system(f"pip install {模块名}")except OSError as osErr:print(f"尝试安装模块 {模块名} 时检测到异常:{osErr}")exit(0)else:try:from DebugInfo.DebugInfo import *except ImportError as impErr:print(f"再次尝试导入 {模块名} 依赖时检测到异常:{impErr}")exit(0)# endregionclass CharCls:word: str = ''code: str = ''def 加载码表(charCodeFile_: str,colIdxOfCode: int = 0,限制码长: int = 0,画板: 打印模板 = None)-> dict[str, CharCls]:"""加载指定的码表文档,默认第一列为字,不同列以 tab 分隔:param colIdxOfCode: 编码所在的列,如果小于1,则默认最后一列为编码:param charCodeFile_: 指定的码表文档,文本文档:param 限制码长: 限制码的长度,如果为0,则不限制:param 画板: 打印模板:return: 返回码表字典,以字为key,以 CharCls对象为值"""画板 = 画板 if isinstance(画板, 打印模板) else 打印模板()画板.执行位置(加载码表)if not charCodeFile_:画板.提示错误('未指定字码文件')return {}if not os.path.isfile(charCodeFile_):画板.提示错误(f'指定的字码文件不存在: {黄字(charCodeFile_)}')return {}charsDic: [str, CharCls] = {}with open(charCodeFile_, 'r', encoding='utf-8') as f:开始: bool = Falsefor 行 in f:行 = 行.strip()if 开始:if not 行.startswith('#'):行分列: list[str] = 行.split('\t')if len(行分列) < 2: # 如果行的列数小于2,则这不是有效的字码行continue字 = 行分列[0]if 0 < colIdxOfCode < len(行分列):码 = 行分列[colIdxOfCode]else:码 = 行分列[-1]if 限制码长 > 0:码 = 码[:限制码长]if len(码) > 1:okFlg: bool = Trueif charsDic.__contains__(字):if len(charsDic[字].code) > len(码):okFlg = Falseif okFlg:cc: CharCls = CharCls()cc.word = 字cc.code = 码charsDic[字] = ccif 行 == '...':开始 = Truereturn charsDicdef 加载词表(wordFile_: str, 画板: 打印模板 = None) -> dict[str, CharCls]:"""加载指定的词语表,词语位于第一列,不同列以 Tab 分隔;可限制词语的字数,加载词语表时,不加载里面的码:param wordFile_: 指定的词语表文档:param 画板: 打印模板:return: 返回词码字典"""画板 = 画板 if isinstance(画板, 打印模板) else 打印模板()画板.执行位置(加载词表)if not wordFile_:画板.提示错误('未指定词语文件')return {}if not os.path.isfile(wordFile_):画板.提示错误(f'指定的词语文件不存在: {黄字(wordFile_)}')return {}worldsDict: [str, CharCls] = {}with open(wordFile_, 'r', encoding='utf-8') as f:开始: bool = Falsefor 行 in f:行 = 行.strip()if 开始:if not 行.startswith('#'):词, *_ = 行.split('\t')if len(词) == 2 and not worldsDict.__contains__(词):wc: CharCls = CharCls()wc.world = 词worldsDict[词] = wcif 行 == '...':开始 = Truereturn worldsDictif __name__ == "__main__":画板 = 打印模板(True)画板.执行位置(__file__)# 直接统计码表的重码率if True:码表: dict[str, CharCls] = 加载码表(charCodeFile_=r'f:\Users\TmpFolder\sjhm_base.dict.yaml',colIdxOfCode=1,画板=画板.副本.缩进())汉字数量: int = len(码表)画板.消息(f'共加载码表条目 {绿字(汉字数量)} 条')码字表: dict[str, list[str]] = {} # 以 码 为键,统计每个码应对的汉字for k, v in 码表.items():if v.code in 码字表.keys():码字表[v.code].append(k)else:码字表[v.code] = [k]重码字数量:int = len([len(码字表[code]) for code in 码字表 if len(码字表[code]) > 1])画板.消息(f'存在重码的字共有 {红字(重码字数量)} 个')画板.消息(f'计算码码率为 {重码字数量 * 100 / 汉字数量}%')
重码率统计
四角号码最大码表可以是六码,但也兼容四码和五码,以及存在一简、二简、三简字,日常使用一般是一简、二简、三简字和标准四码。
对于一、二、三简字,同时存在其对应的标准四、五、六码编码,在以下的统计中,我们将去除一、二、三简码,只统计四、五、六码的编码条目。
如果一个字的编码存在不同的码长编码,则以较长的码为统计依据。
下面分别统计不限码长和限码长的重码率情况。
不限制码长统计重码率
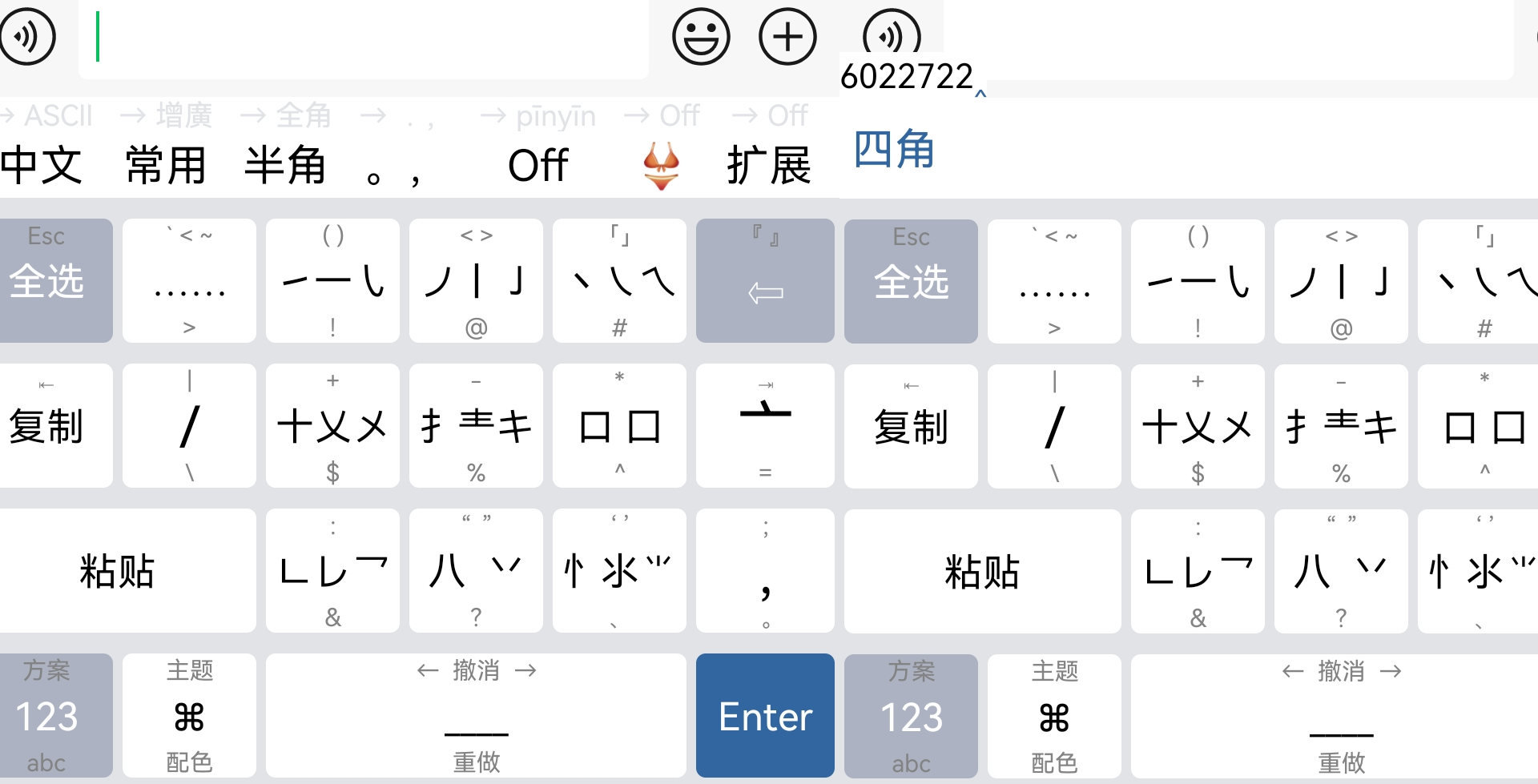
码表汉字条目为 74162 条,其中存在重码的字为 49313 条,重码率为 66.49%
限制码长为五码,统计重码率
这里,我们不统计六码编码,只统计四码、五码的条目,对于六码的条目,我们将其码长截短为五码。
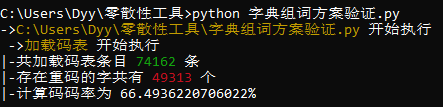
码表汉字条目为 74162 条,其中存在重码的字为 65303 条,重码率为 88.05%
限制码长为四码,统计重码率
这里,我们将码长大于四码的条目,其码长截短为四码。统计其重码率如下。
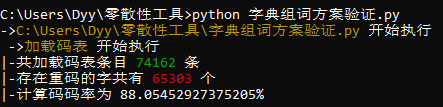
码表汉字条目为 74162 条,其中存在重码的字为 72862 条,重码率为 98.25%
不翻页重码率
在实际的输入法使用中,一般我们在第一页中可以提供最多10个候选项目,在不翻面的情况下,选字是十分快捷和便利的。如果以不翻页选字为标准,即只将重码字数在10以上的字计算为重码字,则以此口径统计重码率如下:
| 码长类型 | 汉字数量 | 重码字数量 | 重码率 |
|---|---|---|---|
| 不限码长 | 74162 | 10079 | 13.59% |
| 限定5码 | 74162 | 29521 | 39.81% |
| 限定4码 | 74162 | 59507 | 80.24% |
全拼重码率参考(不限码长)
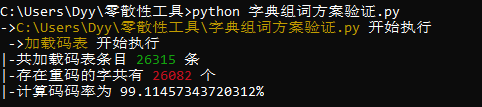
作为对比,统计全拼的单字重码率数据如下(以四叶草拼音的码表为统计基准)。
码表汉字条目为 26315 条,其中存在重码的字为 26082 条,重码率为 99.11%
86五笔重码率参考(定长四码)
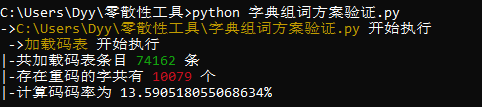
作为对比,统计86版五笔码表的单字重码率数据如下。
码表汉字条目为 74162 条,其中存在重码的字为 10079 条,重码率为 13.59%
小结
从以上可以看出,从重码率的角度,四角号码输入法在手机使用场景下,优于全拼,但差于五笔(但五笔需要使用全26键键盘,手机上只有两个大拇指操作,误触率和操作便利性上要比电脑键盘差的多)。