深入理解Embedding Models(嵌入模型):从原理到实战(下)

🐇明明跟你说过:个人主页
🏅个人专栏:《深度探秘:AI界的007》 🏅
🔖行路有良友,便是天堂🔖
目录
一、引言
1、什么是 Embedding
2、什么是嵌入模型
二、构建嵌入模型的基本流程
1、数据准备与预处理
2、训练策略(自监督、负采样、目标函数)
2.1、自监督学习(Self-Supervised Learning)
2.2、负采样(Negative Sampling)
2.3、目标函数(Loss Function)
3、嵌入空间的评估指标(相\似度、聚类、可视化)
3.1、向量相似度计算
3.2、聚类效果评估
3.3、可视化分析
三、Embedding 工程应用案例
1、推荐系统中的用户-商品嵌入
2、用 PyTorch 实现用户-商品 Embedding & 点积推荐逻辑
一、引言
1、什么是 Embedding
🌟 什么是 Embedding(嵌入)?
Embedding 就是把“我们能读懂的东西”变成“机器能理解的数字向量”的过程。
📦 通俗讲:
就像给每个词、每个人、每件商品都分配一个“数字身份证” → 一个向量(比如 [0.23, -0.88, 1.15, ...]),这些向量能表示它们之间的语义、关系、距离。
📘 举个例子:词嵌入(Word Embedding)
词语本来是文字,比如:
-
“猫” 🐱
-
“狗” 🐶
-
“香蕉” 🍌
但在计算机眼里,它们本来都是乱码!不能理解“猫”和“狗”是相似的,“香蕉”跟它们不太一样。
➡️ 有了嵌入后就像这样:
"猫" → [0.3, 0.8, -0.5]
"狗" → [0.4, 0.75, -0.45]
"香蕉" → [-0.1, 0.2, 0.9]你会发现:
-
“猫”和“狗”的向量非常接近!👍
-
“香蕉”的向量差很多,它表示的是食物,不是动物!🍌
✨ 这样机器就能“理解”语义上的相似或差异啦!
🎯 Embedding 能嵌入什么?
不仅仅是“词”哦!Embedding 能嵌入各种东西:
| 嵌入对象 | 示例 |
|---|---|
| 词嵌入 | Word2Vec、GloVe |
| 句子嵌入 | Sentence-BERT、USE |
| 文档嵌入 | 文本摘要、相似文档搜索 |
| 用户嵌入 | 推荐系统中你是谁、你的偏好 |
| 商品嵌入 | 商品特性、买过的人相似 |
| 节点嵌入 | 图嵌入中的“社交节点”、“网页”等 |
🧠 为什么要做嵌入?
因为计算机不能直接理解文本、图像、声音、关系网络,但可以处理向量!
💡 嵌入是:
-
让“非结构化数据”变成“结构化特征”
-
让 AI 能“理解”、“比较”、“分类”、“推荐”这些内容!
✅ 一句话总结:
Embedding = 给每个对象配上一个向量,让机器能理解它是谁、它跟别人有多像 🤖📦💡
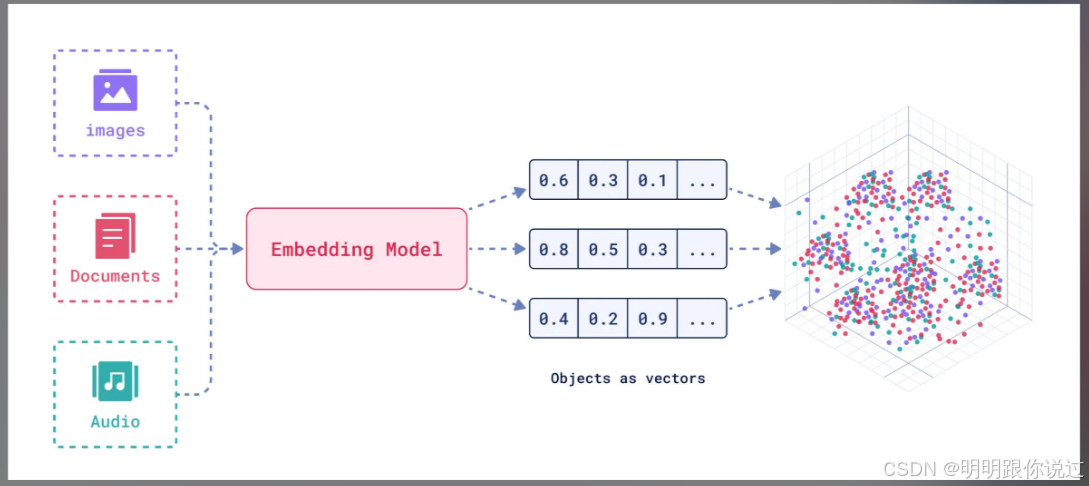
2、什么是嵌入模型
🌟 什么是嵌入模型?
嵌入模型 = 一种把输入(比如词语、句子、用户、物品、节点等)转换成向量的“转换器” 📦🔄
换句话说:Embedding 模型 = 会“理解语义”的压缩机。
它接收你给的内容 ➜ 输出一个有意义的向量!
🎬 举个通俗小剧场:
你给模型一句话:
“我喜欢猫猫。” 🐱
嵌入模型内部:
“让我来压缩这句话的意思,嗯…你大概是在表达喜爱动物的情感!”
然后输出一个向量:
[0.12, -0.85, 0.33, 0.07, ..., 0.91] (比如 768 维)这个向量就可以被搜索引擎、推荐系统、分类器、聚类算法等模型使用!
🔍 常见的嵌入模型类型有哪些?
| 模型类型 | 代表模型 | 用途 | 说明 |
|---|---|---|---|
| 词嵌入模型 | Word2Vec、GloVe | 词语相似度 | 只能处理单词,固定语义 |
| 句子嵌入模型 | Sentence-BERT、E5 | 语义搜索、匹配 | 捕捉上下文语义 🧠 |
| 文档嵌入模型 | Doc2Vec、OpenAI Embedding | 文本检索、摘要 | 可以处理整段文本 📄 |
| 用户/物品嵌入模型 | 推荐系统中的 Embedding Layer | 个性化推荐 | 用户行为 ➜ 向量,捕捉偏好 🎯 |
| 图嵌入模型 | node2vec、GCN、GAT | 社交网络、知识图谱 | 将网络结构 ➜ 向量表示 🕸️ |
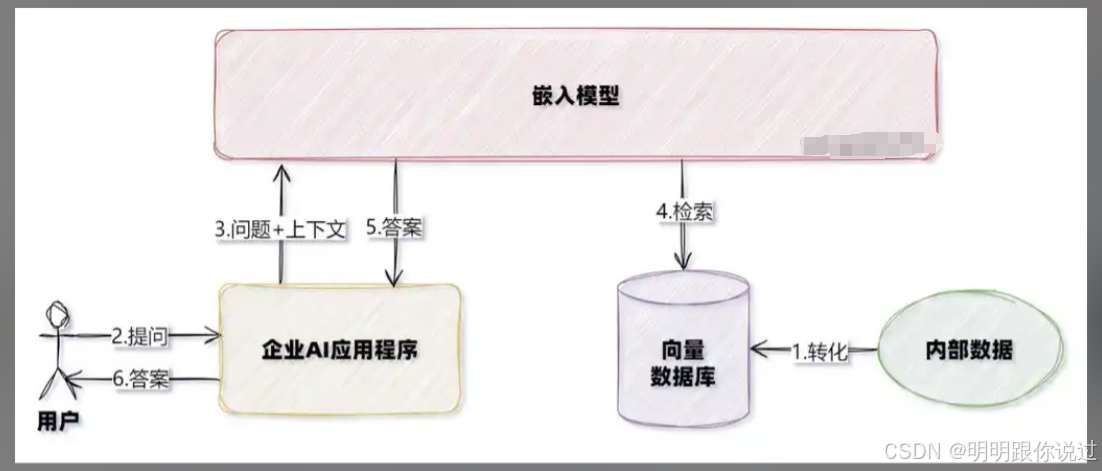
二、构建嵌入模型的基本流程
1、数据准备与预处理
🧱 构建嵌入模型的第一步:数据准备与预处理
📢 无论你是训练词嵌入、句子嵌入还是图嵌入模型,“喂进去的数据质量”决定了“输出向量的质量”!
就像做菜,食材没选好,炒出来也不香!🥬🍳
一步步来:数据准备与预处理流程
1️⃣ 收集原始数据 🧺
🔹 文本嵌入:收集大规模文本语料
🔹 用户/商品嵌入:收集用户行为日志(点击、购买)
🔹 图嵌入:收集图结构数据(节点、边)
🧠 举例:
-
搜集论坛帖子、新闻内容、聊天记录(文本)
-
收集“用户-商品”购买日志(推荐系统)
-
收集社交网络关系(图嵌入)
2️⃣ 数据清洗 🧼
别让“脏数据”影响你模型的判断力!
🔧 清洗包括:
-
去掉 HTML、特殊符号、乱码 🪓
-
去除重复样本、空内容 🔁
-
过滤停用词(如 "的"、"是"、"了")✂️
3️⃣ 分词(适用于文本)✂️
🈶 中文文本 ➜ 分词工具(如 jieba、THULAC)
🅰 英文文本 ➜ 用空格、标点划分 + 词干提取
✅ 示例:
“我爱自然语言处理”
➜ ["我", "爱", "自然", "语言", "处理"]4️⃣ 构建词表 / 编码字典 📚
-
为每个“词”或“实体”分配唯一 ID 👉
{"猫": 1, "狗": 2, "香蕉": 3, ...} -
这样才能输入模型进行 Embedding 操作!
📦 有的模型(如 Word2Vec)自己内部构建词表;你也可以用 tokenizer(如 BERT 的)提前编码好。
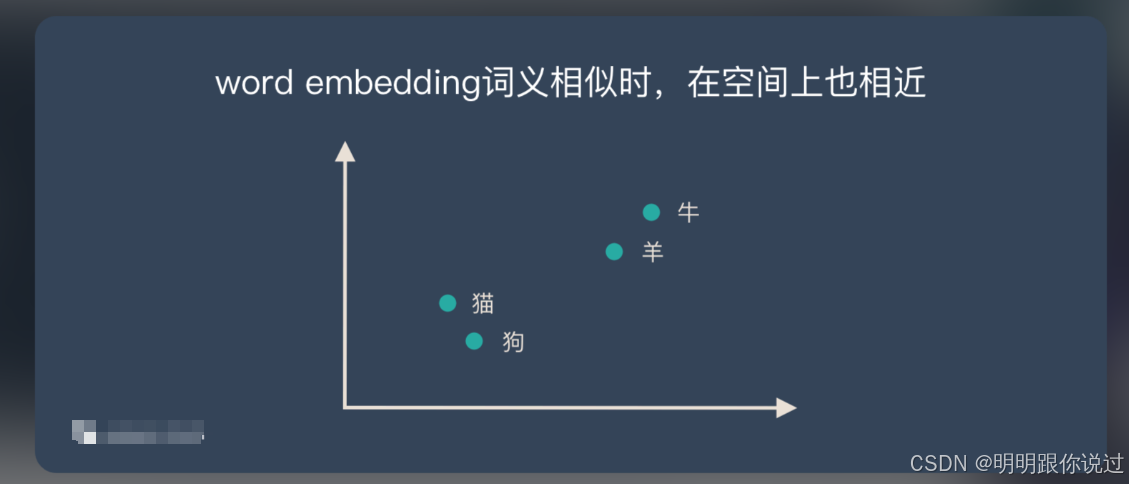
2、训练策略(自监督、负采样、目标函数)
2.1、自监督学习(Self-Supervised Learning)
📢 没有人工标注的标签?没关系!自监督 = 用数据本身构造任务,让模型自己找答案!
🔍 经典示例:
🟢 Word2Vec 的 Skip-gram 任务:
给一个中心词,预测它周围的词。
📘 句子:
“我 喜欢 吃 猫条”
👀 模型输入:
中心词:“喜欢”
🎯 要预测的目标词:
“我”、 “吃”(上下文)
🔍 优点:
✅ 不用人工标注
✅ 可从大规模语料中自动学习
✅ 语义关系自然涌现 ✨

2.2、负采样(Negative Sampling)
📢 嵌入训练中,模型不仅要知道谁“相关”,还要学会谁“不相关”!
🎯 正样本:
中心词“猫” → 上下文词“喵喵”(✅)
🚫 负样本:
中心词“猫” → 胡乱选个词“冰箱” ❄️(❌)
⚒️ 训练目标:
把“猫-喵喵”距离拉近,把“猫-冰箱”距离拉远!
🔧 负采样的作用:
| 问题 | 为什么用负采样? |
|---|---|
| 计算量太大 | 全词表太大,训练会爆炸 💥 |
| 有效率训练 | 只抽几组负样本就能学出方向 📉 |
| 增强判别力 | 学会区分“像” vs “不像” |
2.3、目标函数(Loss Function)
模型训练的最终目标 —— 优化“目标函数”,让结果越来越“贴合预期”。
🔍 常见的目标函数(针对嵌入模型):
| 类型 | 名称 | 功能 |
|---|---|---|
| 对比损失 | Contrastive Loss | 让相似样本靠近、不相似远离 🧲 |
| 交叉熵损失 | Cross-Entropy | 用于词预测、多类分类 📘 |
| 点积目标 | Negative Sampling Loss | 用于 Word2Vec-style 训练(如 Skip-gram)⚙️ |
| Triplet Loss | 三元组损失 | anchor - 正样本 + 负样本:保持合理距离 📐 |
📘 举个例子:
Word2Vec 的目标函数:
maximize log(σ(v_target · v_context)) + Σ log(σ(-v_neg · v_context)) for negative samples🔧 含义是:
-
让真实上下文对的点积更大
-
让假对(负样本)点积更小 ✅

🎬 小结流程图:
原始数据 ➜ 自监督构造训练样本(正+负)
➜ 输入嵌入模型(如 Word2Vec、BERT)
➜ 优化目标函数(如对比损失)
➜ 学到向量表示 🎉
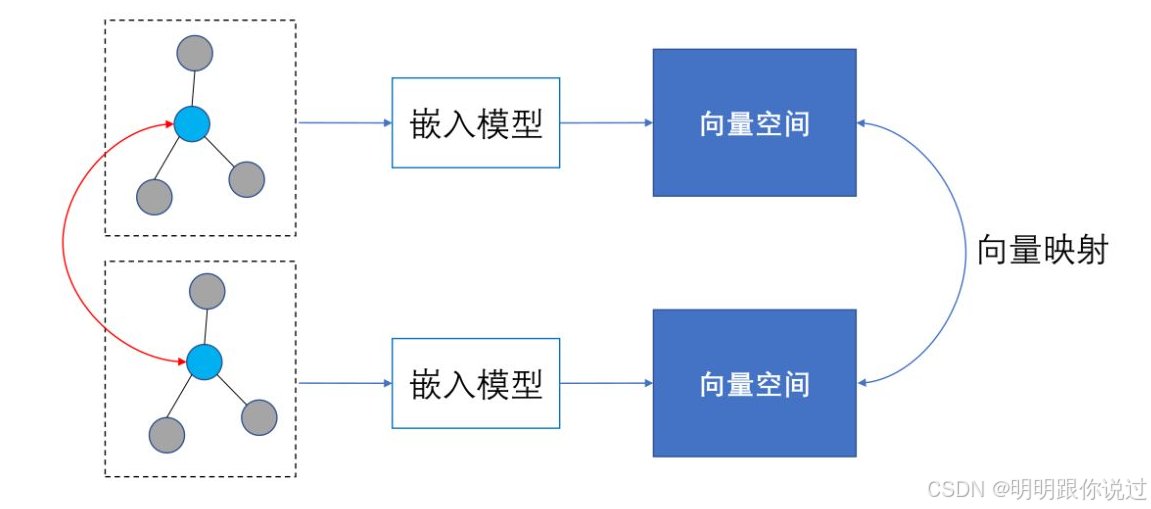
3、嵌入空间的评估指标(相\似度、聚类、可视化)
训练完模型后,如何知道“嵌入学得好不好”?👀🤔
答案就是:用评估方法来“看看”嵌入空间是否有语义结构!
🌐 什么是嵌入空间?
所有词、句子、用户、节点等,被嵌入模型转化为一个个“向量”后,就像被“放进了一个空间里” ——
这个空间就叫 嵌入空间(Embedding Space) ✨
如果模型学得好,意思相近的对象会“靠在一起” 🧲,语义不同的就“隔得远”🚫
🧰 三类常用的嵌入空间评估方式:
3.1、向量相似度计算
衡量两个嵌入向量“像不像”
🔹 常用指标:
| 指标 | 说明 | 适合什么情况 |
|---|---|---|
| 余弦相似度(Cosine Similarity)🌟 | 角度越小,语义越接近 | 常用于文本/词语相似度 |
| 欧几里得距离(L2 距离)📏 | 距离越短,越相似 | 推荐系统中的用户-商品向量 |
| 点积(Dot Product)⚙️ | 向量内积越大,越相关 | 词向量预测、推荐匹配 |
✅ 举例:
向量("猫") 和向量("喵喵")
→ 余弦相似度 ≈ 0.95 ✅(语义相近)
向量("猫") 和向量("冰箱")
→ 余弦相似度 ≈ 0.03 ❌(没啥关系)
3.2、聚类效果评估
看嵌入向量是否能自动分出语义组团
🌀 做法:
-
对向量做 K-Means / DBSCAN 等聚类算法
-
看每个“簇”里是否语义一致(比如全是“动物”、或“电器”等)
🔍 评估指标:
| 指标 | 作用 |
|---|---|
| Silhouette Score | 轮廓系数:衡量聚类紧密 + 分离程度 |
| Davies–Bouldin Index | 聚类“松散度”指标(越小越好) |
| NMI / ARI | 如果你有标签,测聚类是否对得上 ✅ |
3.3、可视化分析
把“高维嵌入向量”降维成 2D/3D,用图看分布!
📉 常用方法:
| 降维算法 | 特点 |
|---|---|
| PCA | 保留最大方差,速度快 ⚡ |
| t-SNE | 适合本地结构,语义簇清晰 🌈 |
| UMAP | 保持全局 + 局部结构 🔍 |
✅ 示例:
-
将词向量降维后画散点图
-
看“国王、王后、男人、女人”是否成语义簇 👑👸
🎨 可视化效果(想象):
👑国王 👸王后
🧍男人 👩女人
🍎苹果 🍌香蕉
→ 嵌入空间“语义分组”明显,说明嵌入学得不错!
三、Embedding 工程应用案例
1、推荐系统中的用户-商品嵌入
用户和商品都变成“向量”,推荐结果靠“向量计算”得出来!⚡🔍
🧠 背景
在推荐系统中,我们的目标是:
给用户推荐他们可能喜欢的商品 🎯
(比如电影、书籍、衣服、视频、课程……)
问题是:
🧍♂️用户、📦商品本身不是数字,怎么输入模型呢?
答案是:用 Embedding 把他们转成向量!
🎲 基本思想
用户 和 商品 ➜ 转换成同一空间的向量表示
然后通过“向量相似度”来判断是否推荐!
📦 举例:
-
用户 A(向量
uA):表示他的兴趣 -
商品 X(向量
vX):表示它的属性
📐 如果 uA · vX(点积)很大 ➜ 推荐!✅
📐 如果两者距离很远 ➜ 不推荐 ❌
🔄 Embedding 如何训练出来?
模型从用户-商品的历史行为数据中学习出“兴趣偏好向量”
| 用户 | 商品 | 行为(标签) |
|---|---|---|
| A | X | 点击(1) |
| B | Y | 未点击(0) |
| A | Z | 购买(1) |
🧩 向量训练的核心流程:
用户-商品历史行为
⬇
用 Embedding 表示用户 & 商品
⬇
计算预测点击/评分的相似度
⬇
通过目标函数(如二分类交叉熵)训练
⬇
得到“语义靠近”的用户商品向量!🎉
2、用 PyTorch 实现用户-商品 Embedding & 点积推荐逻辑
模拟用户和商品都是 ID 类型,Embedding 后做点积预测点击(CTR)
✅ 假设:
-
用户数 = 10000
-
商品数 = 5000
-
每个向量维度 = 32
📦 示例代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass UserItemEmbeddingModel(nn.Module):def __init__(self, num_users, num_items, embedding_dim):super(UserItemEmbeddingModel, self).__init__()self.user_embedding = nn.Embedding(num_users, embedding_dim)self.item_embedding = nn.Embedding(num_items, embedding_dim)def forward(self, user_ids, item_ids):user_vec = self.user_embedding(user_ids) # [batch, dim]item_vec = self.item_embedding(item_ids) # [batch, dim]# 点积作为相似度预测分数dot_product = (user_vec * item_vec).sum(dim=1) # [batch]prob = torch.sigmoid(dot_product) # 映射成点击概率return prob# 示例参数
num_users = 10000
num_items = 5000
embedding_dim = 32# 创建模型
model = UserItemEmbeddingModel(num_users, num_items, embedding_dim)# 模拟一组训练数据
user_ids = torch.tensor([1, 23, 456])
item_ids = torch.tensor([45, 88, 300])
labels = torch.tensor([1.0, 0.0, 1.0]) # 表示是否点击/喜欢# 前向计算
output = model(user_ids, item_ids)
print("预测点击概率:", output)# 定义损失函数(如二分类交叉熵)+ 优化器
loss_fn = nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 计算损失并反向传播
loss = loss_fn(output, labels)
loss.backward()
optimizer.step()🚀 这段代码做了什么?
| 步骤 | 说明 |
|---|---|
nn.Embedding | 将用户 ID 和商品 ID 映射为向量 |
dot_product | 用内积作为相似度预测 |
sigmoid | 映射为点击概率(0~1) |
BCELoss | 与真实标签做二分类损失优化 |
optimizer.step() | 更新嵌入参数 ✨ |
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!