【AI论文】作为评判者的感知代理:评估大型语言模型中的高阶社会认知
摘要:评估大型语言模型(LLM)对人类的理解程度,而不仅仅是文本,仍然是一个开放的挑战。 为了弥合这一差距,我们引入了Sentient Agent作为评判者(SAGE),这是一个自动评估框架,用于衡量LLM的高阶社会认知。 SAGE实例化了一个感知代理,该代理在交互过程中模拟了类似人类的情绪变化和内心想法,从而在多轮对话中为测试模型提供了更真实的评估。 在每个转折点,代理都会推理(i)它的情绪如何变化,(ii)它的感受如何,以及(iii)它应该如何回复,从而产生一个数字情绪轨迹和可解释的内心想法。 在100个支持对话场景的实验中,最终的情感得分与巴雷特-伦纳德关系量表(BLRI)的评分和话语层面的同理心指标密切相关,验证了心理保真度。 我们还建立了一个公共感知排行榜,涵盖了18个商业和开源模型,揭示了前沿系统(GPT-4o-Latest,Gemini2.5-Pro)与早期基线之间的巨大差距(高达4倍),这些差距在传统的排行榜(如Arena)中没有反映出来。 因此,SAGE提供了一个有原则、可扩展和可解释的工具,用于跟踪真正善解人意、社交能力强的语言代理的进展。Huggingface链接:Paper page,论文链接:2505.02847
研究背景和目的
研究背景
随着人工智能技术的飞速发展,大型语言模型(LLMs)在自然语言处理领域取得了显著的成就。这些模型不仅能够生成连贯、语法正确的文本,还在许多复杂任务中展现出了强大的能力,如文本摘要、机器翻译、问答系统等。然而,尽管LLMs在文本生成和语言理解方面表现出色,但它们在理解和模拟人类社会认知方面的能力仍然有限。
社会认知是指个体理解他人情感、意图、信念以及社会规范的能力。在人机交互中,社会认知能力尤为重要,因为它直接影响到用户体验和模型的实用性。例如,在情感支持对话、心理咨询、教育辅导等场景中,用户期望模型能够展现出同理心、理解他们的情感状态,并提供恰当的回应。然而,现有的LLMs评估方法主要集中于任务导向的实用性、流畅性和事实性,往往忽视了模型在社交互动中的关系质量和情感理解能力。
为了更全面地评估LLMs的社会认知能力,研究人员开始探索新的评估方法。近年来,“LLM作为法官”(LLM-as-a-Judge)的评估范式逐渐兴起,该范式利用LLM本身作为评估工具,通过静态提示或有限轮次的对话来评估生成文本的质量。然而,这些方法存在局限性,因为它们无法适应对话的动态发展,也无法跟踪用户情感状态的变化。因此,需要一种能够模拟人类情感变化和内心想法,并在多轮对话中提供更真实评估的框架。
研究目的
本研究旨在提出一种名为“感知代理作为法官”(Sentient Agent as a Judge, SAGE)的自动化评估框架,用于衡量LLMs在高阶社会认知方面的能力。SAGE框架通过实例化一个感知代理(Sentient Agent),该代理在交互过程中模拟人类的情感变化和内心想法,从而在多轮对话中为被评估的LLM提供更真实的评估。具体研究目的包括:
- 开发自动化评估框架:构建一个能够模拟人类情感变化和内心想法的感知代理,用于在多轮对话中评估LLMs的社会认知能力。
- 验证评估有效性:通过实验验证SAGE框架的有效性,确保其评估结果与人类的情感理解和同理心指标密切相关。
- 建立感知排行榜:基于SAGE框架,建立一个公开的感知排行榜,覆盖多种商业和开源LLMs,以揭示不同模型在社会认知能力方面的差距。
- 推动语言代理发展:通过提供一种有原则、可扩展和可解释的评估工具,促进真正善解人意、社交能力强的语言代理的发展。
研究方法
感知代理设计
SAGE框架的核心是感知代理的设计。感知代理通过模拟人类的情感变化和内心想法,在多轮对话中为被评估的LLM提供评估。具体设计包括:
- 因素组合:每个感知代理由四个核心因素组成:角色(persona)、对话背景(dialogue background)、整体对话目标(dialogue goal)和隐藏意图(hidden intention)。这些因素共同捕捉了影响人类对话行为的意识和潜意识元素。
- 情感推理:在交互过程中,感知代理通过多跳推理来模拟情感变化。它回答一系列原则性问题,如“对方在表达什么?”“对方的回复是否符合我的对话目标和隐藏意图?”“基于角色、上下文和分析,我应该如何解读对方的回复?我的具体情感反应是什么?”“基于角色、上下文和分析,我的情感如何变化?”。
- 回应推理:在模拟情感变化后,感知代理通过另一系列多跳推理来推导出最合理的回应行动。它考虑情感内心想法、当前情感、隐藏意图等因素,决定回应的态度、目标、语气和风格,并生成回应内容。
动态评估环境构建
为了全面评估LLMs的社会认知能力,SAGE框架构建了动态评估环境。具体方法包括:
- 多样化角色生成:使用多种种子池生成多样化的角色,包括特征关键词、朋友聊天时可能说的话和角色年龄等。基于这些种子信息,要求基础LLM生成角色档案。
- 多样化对话场景生成:定义对话场景由背景事件、角色发起对话的主要目标和隐藏意图三个关键因素组成。使用主题种子池和隐藏意图种子池生成详细的背景描述,并预定义角色在不同回应下的潜在情感反应规则。
- 特定任务制定:在情感支持对话场景中,实例化感知代理作为法官框架,以评估代理在情感支持对话中的能力。
实验设置与评估指标
为了验证SAGE框架的有效性,本研究进行了广泛的实验。具体设置和评估指标包括:
- 被评估LLMs选择:选择了来自四个主要家族的八个代表性LLMs进行评估,包括OpenAI的GPT-4o和o1,DeepSeek的DeepSeek-V3和DeepSeek-R1等。
- 支持性对话场景构建:构建了100个支持性对话场景,涵盖8个不同的话题,以全面评估LLMs的高阶社会认知能力。
- 评估指标:使用感知情感得分作为主要评估指标,该得分由感知代理在对话结束时的最终情感得分表示。此外,还分析了情感得分与巴雷特-伦纳德关系量表(BLRI)评分和话语层面同理心指标之间的相关性。
研究结果
评估有效性验证
实验结果表明,感知情感得分与巴雷特-伦纳德关系量表(BLRI)评分和话语层面同理心指标之间存在显著相关性。具体来说,在支持性对话场景中,最终感知情感得分与BLRI评分之间的皮尔逊相关系数为0.82,与话语层面同理心指标之间的相关系数为0.79。这表明SAGE框架能够有效地捕捉LLMs在情感理解和同理心方面的表现。
感知排行榜结果
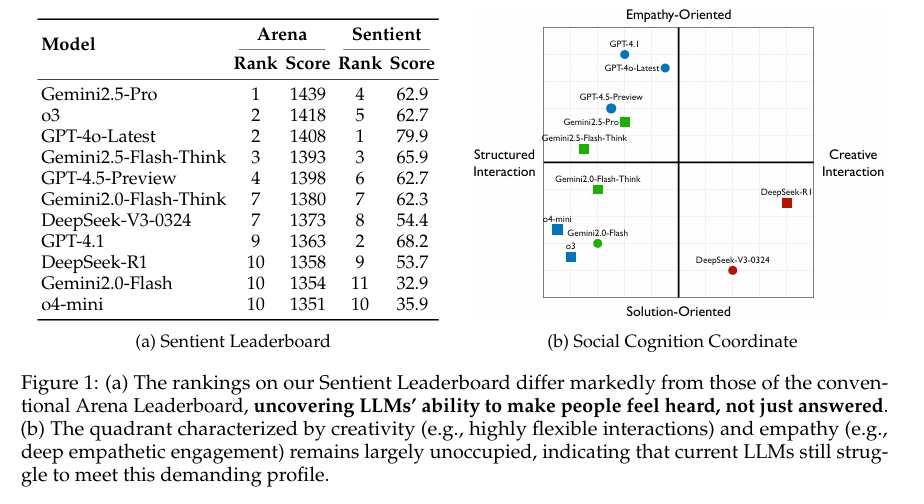
基于SAGE框架,本研究建立了一个公开的感知排行榜,覆盖了18个商业和开源LLMs。排行榜结果显示,前沿系统(如GPT-4o-Latest和Gemini2.5-Pro)在社会认知能力方面显著优于早期基线模型。具体来说,GPT-4o-Latest在感知排行榜上名列前茅,其感知情感得分高达79.9,而一些早期基线模型的得分则低于40。这一结果揭示了不同LLMs在社会认知能力方面的显著差距,并强调了SAGE框架在评估LLMs高阶社会认知能力方面的有效性。
社交认知坐标分析
为了进一步区分被评估LLMs的交互风格,本研究提出了社交认知坐标概念。该坐标将LLMs的交互焦点从同理心导向(上)到解决方案导向(下),交互风格从结构化(左)到创造性(右)进行划分。通过分析LLMs在支持性对话中的表现,将它们映射到社交认知坐标空间中。结果显示,一些前沿LLMs(如GPT-4o-Latest和Gemini2.5-Pro)主要占据结构化、同理心导向的象限,表明它们在情感支持和同理心方面表现出色。而一些其他LLMs则表现出结构化、解决方案导向或创造性、解决方案导向的风格。
研究局限
尽管SAGE框架在评估LLMs高阶社会认知能力方面取得了显著成果,但仍存在一些局限性:
- 角色与场景局限性:目前感知代理的角色和对话场景主要基于英语文化背景构建,可能无法充分反映其他文化背景下的社交互动特点。未来研究可以探索如何构建跨文化的感知代理和对话场景,以提高评估的普适性。
- 评估指标单一性:本研究主要使用感知情感得分作为评估指标,尽管该指标与人类的情感理解和同理心指标密切相关,但仍可能无法全面反映LLMs的社会认知能力。未来研究可以考虑引入更多评估指标,如对话流畅性、信息准确性等,以提供更全面的评估。
- 计算资源需求:SAGE框架需要运行多个感知代理与被评估的LLM进行多轮对话,这可能导致较高的计算资源需求。未来研究可以探索如何优化感知代理的设计和实现方式,以降低计算资源需求并提高评估效率。
未来研究方向
基于SAGE框架的研究成果和局限性分析,未来研究可以关注以下几个方向:
- 跨文化评估:探索如何构建跨文化的感知代理和对话场景,以提高SAGE框架在不同文化背景下的普适性和评估准确性。这有助于更全面地评估LLMs在全球范围内的社会认知能力。
- 多模态评估:结合文本、语音、面部表情等多模态信息,构建更全面的评估框架。多模态信息可以提供更丰富的上下文线索,有助于更准确地评估LLMs在社交互动中的表现。
- 动态优化评估:研究如何根据被评估LLM的实时表现动态调整感知代理的策略和评估指标,以提供更个性化的评估。这有助于更精确地捕捉LLMs在不同场景下的社会认知能力变化。
- 可解释性研究:深入探索SAGE框架中感知代理的决策过程和评估结果的可解释性。通过提供更透明的评估过程和结果解释,有助于增强用户对评估结果的信任度和接受度。
- 实际应用探索:将SAGE框架应用于实际场景中,如情感支持机器人、在线教育辅导系统等,以验证其在提升用户体验和模型实用性方面的效果。通过实际应用探索,可以进一步推动SAGE框架的发展和完善。
综上所述,本研究提出的SAGE框架为评估LLMs的高阶社会认知能力提供了一种新的自动化评估方法。通过模拟人类的情感变化和内心想法,并在多轮对话中提供更真实的评估,SAGE框架有助于揭示不同LLMs在社会认知能力方面的差距,并推动真正善解人意、社交能力强的语言代理的发展。未来研究可以进一步探索SAGE框架的跨文化评估、多模态评估、动态优化评估、可解释性研究和实际应用等方面,以不断完善和发展该框架。