进程间关系与守护进程
上一篇:应用层自定义协议与序列化![]() https://blog.csdn.net/Small_entreprene/article/details/147675344?fromshare=blogdetail&sharetype=blogdetail&sharerId=147675344&sharerefer=PC&sharesource=Small_entreprene&sharefrom=from_link
https://blog.csdn.net/Small_entreprene/article/details/147675344?fromshare=blogdetail&sharetype=blogdetail&sharerId=147675344&sharerefer=PC&sharesource=Small_entreprene&sharefrom=from_link
上一篇的代码补充
我们上一篇只是实现了服务端的代码,我们还有客户端没有实现,客户端也是需要遵循双方间的协议的,也是需要通过数据的序列化向服务端发送请求报文的,然后接收到服务端发送过来的序列化后的应答报文,通过反序列化得到遵循协议的真正可读的应答数据:
所以Protocol类还缺少可以Get到Response应答的接口,所以我们还需要丰富我们的Protocol类:
bool GetResponse(std::shared_ptr<Socket> &client, std::string &resp_buff, Response *resp)
{// 面向字节流,你怎么保证,你的client读到的 一个网络字符串,就一定是一个完整的请求呢??while (true){int n = client->Recv(&resp_buff);if (n > 0){// std::cout << "-----------resp_buffer--------------" << std::endl;// std::cout << resp_buff << std::endl;// std::cout << "------------------------------------" << std::endl;// 成功std::string json_package;// 1. 解析报文,提取完整的json请求,如果不完整,就让服务器继续读取// bool ret = Decode(resp_buff, &json_package);// if (!ret)// continue;while (Decode(resp_buff, &json_package)){// std::cout << "----------response json---------------" << std::endl;// std::cout << json_package << std::endl;// std::cout << "--------------------------------------" << std::endl;// std::cout << "-----------resp_buffer--------------" << std::endl;// std::cout << resp_buff << std::endl;// std::cout << "------------------------------------" << std::endl;// 2. 走到这里,我能保证,我一定拿到了一个完整的应答json报文// 2. 反序列化resp->Deserialize(json_package);}return true;}else if (n == 0){std::cout << "server quit " << std::endl;return false;}else{std::cout << "recv error" << std::endl;return false;}}
}当然了,既然是客户端要发送的数据,这个要发送的数据肯定是需要先构建一个完整的请求,再通过序列化,然后为了保证对端能够对报文进行有效解析,还需要添加长度报头,所以我们也就直接在Protocol类当中添加一个构建请求报文的接口:
std::string BuildRequestString(int x, int y, char oper)
{// 1. 构建一个完整的请求Request req(x, y, oper);// 2. 序列化std::string json_req = req.Serialize();// // 2.1 debug// std::cout << "------------json_req string------------" << std::endl;// std::cout << json_req << std::endl;// std::cout << "---------------------------------------" << std::endl;// 3. 添加长度报头return Encode(json_req);
}自此,我们的Protocol.hpp就完善了:
Protocol.hpp
#pragma once
#include "Socket.hpp"
#include <iostream>
#include <string>
#include <memory>
#include <jsoncpp/json/json.h>
#include <functional>// 实现一个自定义的网络版本的计算器using namespace SocketModule;// 约定好各个字段的含义,本质就是约定好协议!
// client -> server
// 如何要做序列化和反序列化:
// 1. 我们自己写(怎么做) ---> 往往不具备很好的扩展性
// 2. 使用现成的方案(这个是我们要写的) ---> json -> jsoncpp// content_len jsonstring
// 50\r\n协议号\r\n{"x": 10, "y" : 20, "oper" : '+'}\r\n
// 50
// {"x": 10, "y" : 20, "oper" : '+'}
class Request
{
public:Request(){}Request(int x, int y, char oper) : _x(x), _y(y), _oper(oper){}std::string Serialize(){// _x = 10 _y = 20, _oper = '+'// "10" "20" '+' : 用空格作为分隔符Json::Value root;root["x"] = _x;root["y"] = _y;root["oper"] = _oper; // _oper是char,也是整数,阿斯克码值Json::FastWriter writer;std::string s = writer.write(root);return s;}// {"x": 10, "y" : 20, "oper" : '+'}bool Deserialize(std::string &in){// "10" "20" '+' -> 以空格作为分隔符 -> 10 20 '+'Json::Value root;Json::Reader reader;bool ok = reader.parse(in, root);if (ok){_x = root["x"].asInt();_y = root["y"].asInt();_oper = root["oper"].asInt(); //?}return ok;}~Request() {}int X() { return _x; }int Y() { return _y; }char Oper() { return _oper; }private:int _x;int _y;char _oper; // + - * / % -> _x _oper _y -> 10 + 20
};// server -> client
class Response
{
public:Response() {}Response(int result, int code) : _result(result), _code(code){}std::string Serialize(){Json::Value root;root["result"] = _result;root["code"] = _code;Json::FastWriter writer;return writer.write(root);}bool Deserialize(std::string &in){Json::Value root;Json::Reader reader;bool ok = reader.parse(in, root);if (ok){_result = root["result"].asInt();_code = root["code"].asInt();}return ok;}~Response() {}void SetResult(int res){_result = res;}void SetCode(int code){_code = code;}void ShowResult(){std::cout << "计算结果是: " << _result << "[" << _code << "]" << std::endl;}private:int _result; // 运算结果,无法区分清楚应答是计算结果,还是异常值int _code; // 0:sucess, 1,2,3,4->不同的运算异常的情况, 约定!!!!
};const std::string sep = "\r\n";using func_t = std::function<Response(Request &req)>;// 协议(基于TCP的)需要解决两个问题:
// 1. request和response必须得有序列化和反序列化功能
// 2. 你必须保证,读取的时候,读到完整的请求(TCP, UDP不用考虑)
class Protocol
{
public:Protocol(){}Protocol(func_t func) : _func(func){}std::string Encode(const std::string &jsonstr){// 50\r\n{"x": 10, "y" : 20, "oper" : '+'}\r\nstd::string len = std::to_string(jsonstr.size());return len + sep + jsonstr + sep; // 应用层封装报头}// 50\r\n{"x": 10, "y" : 20, "oper" : '+'}\r\n// 5// 50// 50\r// 50\r\n// 50\r\n{"x": 10, "// 50\r\n{"x": 10, "y" : 20, "oper" : '+'}\r\n// 50\r\n{"x": 10, "y" : 20, "oper" : '+'}\r\n50\r\n{"x": 10, "y" : 20, "ope//.....// packge故意是&// 1. 判断报文完整性// 2. 如果包含至少一个完整请求,提取他, 并从移除它,方便处理下一个bool Decode(std::string &buffer, std::string *package){ssize_t pos = buffer.find(sep);if (pos == std::string::npos)return false; // 让调用方继续从内核中读取数据std::string package_len_str = buffer.substr(0, pos);int package_len_int = std::stoi(package_len_str);// buffer 一定有长度,但是一定有完整的报文吗?int target_len = package_len_str.size() + package_len_int + 2 * sep.size();if (buffer.size() < target_len)return false;// buffer一定至少有一个完整的报文!*package = buffer.substr(pos + sep.size(), package_len_int);buffer.erase(0, target_len);return true;}void GetRequest(std::shared_ptr<Socket> &sock, InetAddr &client){// 读取std::string buffer_queue;while (true){int n = sock->Recv(&buffer_queue);if (n > 0){std::cout << "-----------request_buffer--------------" << std::endl;std::cout << buffer_queue << std::endl;std::cout << "------------------------------------" << std::endl;std::string json_package;// 1. 解析报文,提取完整的json请求,如果不完整,就让服务器继续读取while (Decode(buffer_queue, &json_package)){// 我敢100%保证,我一定拿到了一个完整的报文// {"x": 10, "y" : 20, "oper" : '+'} -> 你能处理吗?// 2. 请求json串,反序列化// std::cout << "-----------request_json--------------" << std::endl;// std::cout << json_package << std::endl;// std::cout << "------------------------------------" << std::endl;// std::cout << "-----------request_buffer--------------" << std::endl;// std::cout << buffer_queue << std::endl;// std::cout << "------------------------------------" << std::endl;LOG(LogLevel::DEBUG) << client.StringAddr() << " 请求: " << json_package;Request req;bool ok = req.Deserialize(json_package);if (!ok)continue;// 3. 我一定得到了一个内部属性已经被设置了的req了.// 通过req->resp, 不就是要完成计算功能嘛!!业务Response resp = _func(req);// 4. 序列化std::string json_str = resp.Serialize();// 5. 添加自定义长度std::string send_str = Encode(json_str); // 携带长度的应答报文了"len\r\n{result:XXX, code:XX}\r\n"// 6. 直接发送sock->Send(send_str);}}else if (n == 0){LOG(LogLevel::INFO) << "client:" << client.StringAddr() << "Quit!";break;}else{LOG(LogLevel::WARNING) << "client:" << client.StringAddr() << ", recv error";break;}}}bool GetResponse(std::shared_ptr<Socket> &client, std::string &resp_buff, Response *resp){// 面向字节流,你怎么保证,你的client读到的 一个网络字符串,就一定是一个完整的请求呢??while (true){int n = client->Recv(&resp_buff);if (n > 0){// std::cout << "-----------resp_buffer--------------" << std::endl;// std::cout << resp_buff << std::endl;// std::cout << "------------------------------------" << std::endl;// 成功std::string json_package;// 1. 解析报文,提取完整的json请求,如果不完整,就让服务器继续读取// bool ret = Decode(resp_buff, &json_package);// if (!ret)// continue;while (Decode(resp_buff, &json_package)){// std::cout << "----------response json---------------" << std::endl;// std::cout << json_package << std::endl;// std::cout << "--------------------------------------" << std::endl;// std::cout << "-----------resp_buffer--------------" << std::endl;// std::cout << resp_buff << std::endl;// std::cout << "------------------------------------" << std::endl;// 2. 走到这里,我能保证,我一定拿到了一个完整的应答json报文// 2. 反序列化resp->Deserialize(json_package);}return true;}else if (n == 0){std::cout << "server quit " << std::endl;return false;}else{std::cout << "recv error" << std::endl;return false;}}}std::string BuildRequestString(int x, int y, char oper){// 1. 构建一个完整的请求Request req(x, y, oper);// 2. 序列化std::string json_req = req.Serialize();// // 2.1 debug// std::cout << "------------json_req string------------" << std::endl;// std::cout << json_req << std::endl;// std::cout << "---------------------------------------" << std::endl;// 3. 添加长度报头return Encode(json_req);}~Protocol(){}private:// 因为我们用的是多进程// Request _req;// Response _resp;func_t _func;
};那么接下来,我们就可以实现我们的客户端了:TcpClient.cc
TcpClient.cc
其实客户端代码很好写的,只需要建立网络连接,连接好对应服务器,然后向服务器发送请求,接收应答就可以了:
#include "Socket.hpp"
#include "Common.hpp"
#include "Protocol.hpp"
#include <iostream>
#include <string>
#include <memory>using namespace SocketModule;void Usage(std::string proc)
{std::cerr << "Usage: " << proc << " server_ip server_port" << std::endl;
}void GetDataFromStdin(int *x, int *y, char *oper)
{std::cout << "Please Enter x: ";std::cin >> *x;std::cout << "Please Enter y: ";std::cin >> *y;std::cout << "Please Enter oper: ";std::cin >> *oper;
}// ./tcpclient server_ip server_port
int main(int argc, char *argv[])
{if (argc != 3){Usage(argv[0]);exit(USAGE_ERR);}std::string server_ip = argv[1];uint16_t server_port = std::stoi(argv[2]);std::shared_ptr<Socket> client = std::make_shared<TcpSocket>();client->BuildTcpClientSocketMethod();if (client->Connect(server_ip, server_port) != 0){// 失败std::cerr << "connect error" << std::endl;exit(CONNECT_ERR);}std::unique_ptr<Protocol> protocol = std::make_unique<Protocol>();std::string resp_buffer;// 连接服务器成功while (true){// 1. 从标准输入当中获取数据int x, y;char oper;GetDataFromStdin(&x, &y, &oper);// 2. 构建一个请求-> 可以直接发送的字符串std::string req_str = protocol->BuildRequestString(x, y, oper);// std::cout << "-----------encode req string-------------" << std::endl;// std::cout << req_str << std::endl;// std::cout << "------------------------------------------" << std::endl;// 3. 发送请求client->Send(req_str);// 4. 获取应答Response resp;bool res = protocol->GetResponse(client, resp_buffer, &resp);if (res == false)break;// 5. 显示结果resp.ShowResult();}client->Close();return 0;
}
在 Linux 系统的世界里,进程是程序运行的实例,而进程间的关系错综复杂,守护进程更是其中神秘而关键的角色。今天,就让我们一起深入探索 “进程间关系与守护进程” 的奇妙世界。本文将带你深入了解进程组、会话、控制终端、作业控制以及守护进程等概念😎
进程组:协作单元的底层逻辑
相关概念
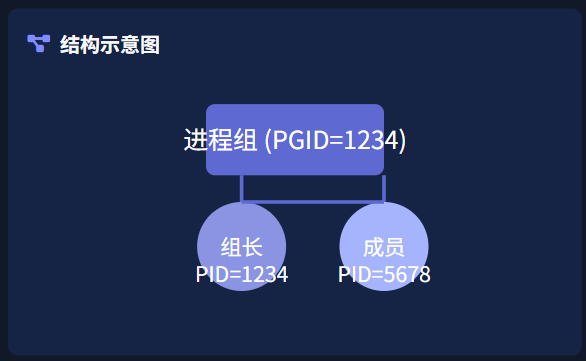
之前我们提到了进程的概念,其实每一个进程除了有一个进程ID(PID)之外,还属于一个进程组。进程组是一个或者多个进程的集合,一个进程组可以包含多个进程。每一个进程组也有一个唯一的进程组ID(PGID),并且这个PGID类似于进程ID,同样是一个正整数,可以存放在`pid_t`数据类型中。
进程组是Linux/Unix系统中最基础的进程协作单元,由多个共享同一进程组ID(PGID)的进程构成。其核心特性包括:
- PGID与组长进程:进程组的ID(PGID)等于组长进程的PID。即使组长进程终止,只要组内仍有其他进程存在,进程组依然存活,这类似于团队中即使队长离职,团队仍可继续运作。
- 信号批量处理:向进程组发送信号(如
kill -9 -PGID)会触发组内所有进程响应,常用于终止或暂停一组关联任务。(到这,我们之前的kill杀掉一进程的观念就需要微调了,是杀掉一个进程组!) - 动态调整机制:通过
setpgid()函数,进程可加入其他进程组或创建新组。例如,父进程通过两次调用setpgid()确保子进程独立成组,避免进程启动顺序导致的问题。

应用场景:
- Shell作业控制:启动多个子进程时,Shell默认将它们置于同一进程组,便于统一管理。
- 批处理任务:批量处理日志分析或数据转换时,通过进程组实现统一启停。
相关接口:getpgid
在操作系统中,进程之间存在关联和管理的需求,setpgid 函数就是用于管理和控制进程组的一个重要工具。
int setpgid(pid_t pid, pid_t pgid);-
pid:表示要设置进程组 ID 的进程的进程 ID。如果pid为 0,则表示设置当前进程的进程组 ID。 -
pgid:表示目标进程组 ID。如果pgid为 0,则新进程组 ID 被设置为pid指定进程的进程 ID。
setpgid函数用于将一个进程加入到指定的进程组中,或者创建一个新的进程组并把进程加入到其中。通过调用该函数,可以改变进程与进程组之间的关联关系。
-
在需要对多个进程进行统一管理和控制时,可以使用
setpgid将这些进程加入到同一个进程组中,然后通过进程组 ID 对它们进行批量操作,如发送信号等。 -
在创建守护进程时,通常会调用
setsid函数创建一个新会话,而setsid函数实际上也会涉及到进程组的创建和管理,与setpgid有相关性。
不过我们要注意:
-
只有具有相同有效用户 ID 的进程之间才能互相设置进程组 ID。如果当前进程没有足够的权限,调用该函数会失败。
-
在调用
fork函数创建子进程后,通常由父进程调用setpgid来设置子进程的进程组 ID,以便对子进程进行管理和控制。 -
setpgid函数通常用于在进程创建后对其进行组织和管理,而setsid函数用于创建新的会话和进程组,这两个函数在进程间通信和控制中具有不同的应用场景和作用。
#include <unistd.h>
#include <sys/types.h>
#include <iostream>int main() {pid_t pid = fork();if (pid == 0) {// 子进程if (setpgid(0, 0) == -1) {perror("setpgid failed");return 1;}std::cout << "Child process, PID: " << getpid() << ", PGID: " << getpgid(getpid()) << std::endl;} else {// 父进程sleep(1); // 确保子进程先执行std::cout << "Parent process, PID: " << getpid() << ", PGID: " << getpgid(getpid()) << std::endl;}return 0;
}我们来见见进程组
我们可以在命令行上使用之前的命令:ps -axj
lfz@HUAWEI:~$ sleep 1000 &
[1] 164498
lfz@HUAWEI:~$ ps -axj | head -1 && ps -axj | grep sleep | grep -v grepPPID PID PGID SID TTY TPGID STAT UID TIME COMMAND164487 164498 164498 164433 pts/0 164517 S 1000 0:00 sleep 1000
当然,也可以:
C++
$ ps -eo pid,pgid,ppid,comm | grep test
#结果如下
PID PGID PPID COMMAND
2830 2830 2259 test-e 选项表示 every 的意思,表示输出每一个进程信息
-o 选项以逗号操作符(,)作为定界符,可以指定要输出的列我们可以通过管道来建立多个兄弟进程,我们来观察:
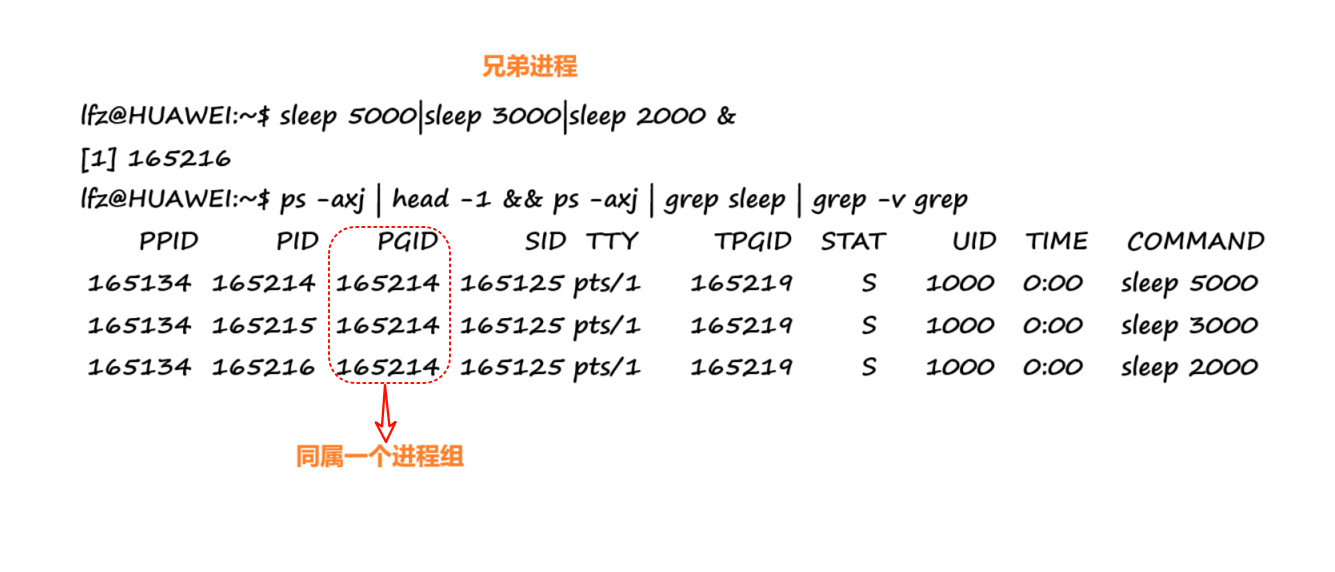
-
进程组组长可以创建一个进程组或者加入(这里更准确地说应是管理,实际创建通常由系统完成)该组中的进程:虽然表述略有出入,但核心意思是进程组组长对进程组内的进程有管理权限,可以创建新进程加入该组(不过通常进程的创建是由系统调用如
fork()完成的,组长进程可以通过这些系统调用来间接创建新进程并加入组)。更准确地说,组长进程有权在该进程组内启动新的进程。 -
进程组组长是进程组的标识:组长进程的ID(PID)与进程组ID(PGID)相同,这使得组长进程在某种程度上代表了整个进程组。(sleep 5000这个进程就是对应PGID进程组的组长进程,因为这个进程的进程PID和进程组的PGID相等!)
-
进程组生命周期的管理:进程组的生命周期从创建开始到其中最后一个进程离开为止,而组长进程的存在与否并不直接影响进程组的存续。
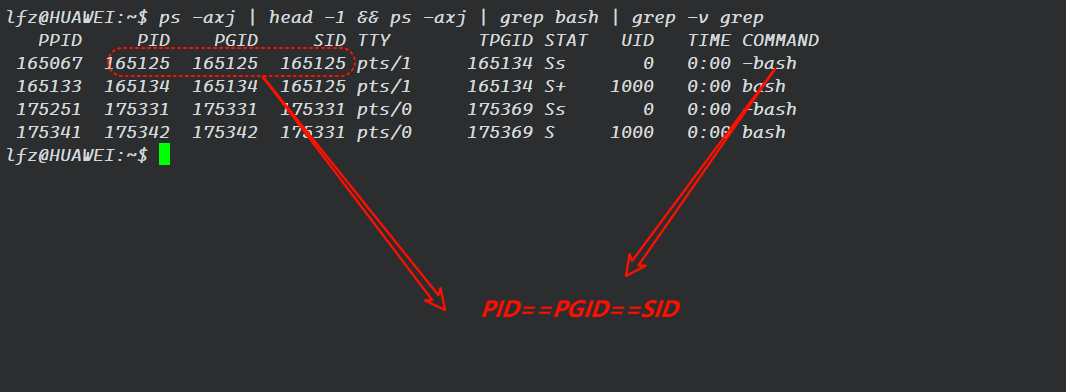
通过之前学习,我们知道了ppid,pid,以及现在的pgid,那么sid又是什么呢?
会话:资源隔离的高级容器
相关概念
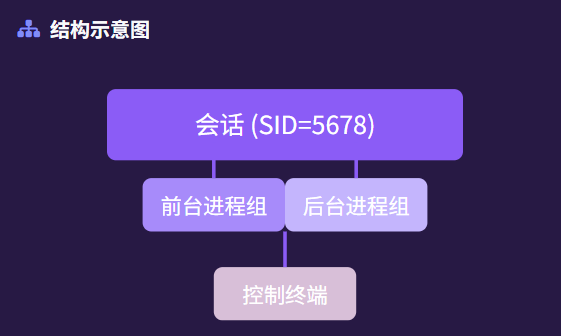
会话是进程组的更高层抽象,一个会话包含多个进程组,并与控制终端(Controlling Terminal)绑定。关键机制如下:
- 会话创建:通过
setsid()创建新会话,调用者必须为非组长进程。常见做法是父进程fork()创建子进程后退出,子进程调用setsid()成为会话首进程。 - 会话生命周期:会话首进程(通常为Shell)负责管理会话。当终端断开时,会话内所有进程会收到SIGHUP信号,默认终止。
- 控制终端关联:会话的输入输出默认绑定到终端设备(如
/dev/tty)。前台进程组可接收终端输入,后台进程组仅能输出日志或运行非交互任务。

将会话比作公司部门,进程组是其中的项目团队。部门经理(会话首进程)协调各团队,部门解散(终端关闭)时所有团队(进程组)随之解散。
相关接口:setsid
setsid() 是一个在 Unix 和类 Unix 系统中用于创建新会话的系统调用。它在进程间通信和守护进程的创建中扮演着重要角色。
#include <unistd.h>
pid_t setsid(void);setsid() 用于创建一个新的会话(session),并使调用进程成为该会话的首进程(session leader)。会话是一个或多个进程组的集合,而会话首进程是会话的管理者。
-
成功时,返回新会话的会话 ID(SID);失败时,返回 -1,并设置
errno为相应的错误码。
调用 setsid() 时,会发生以下几件事情:
-
创建新会话:调用进程成为新会话的首进程。
-
创建新进程组:调用进程成为新进程组的组长,新进程组的 ID 等于调用进程的 PID。
-
脱离控制终端:如果调用进程之前有控制终端,则调用
setsid()后,该进程将脱离控制终端。
我们需要注意的是:
调用条件:调用 setsid() 的进程不能是进程组的组长。如果调用进程已经是进程组的组长,则会报错(EPERM)。
如果调用 setsid() 的进程已经是进程组的组长,那么调用 setsid() 时会出现以下问题:
-
违反会话管理规则:会话首进程不能是其他进程组的组长。如果调用
setsid()的进程已经是进程组的组长,那么它在成为会话首进程时,会违反这一规则。 -
避免冲突:调用
setsid()的目的是创建一个新的会话和新的进程组,如果调用进程已经是进程组的组长,那么它已经管理了一个进程组,再创建新的会话和进程组会导致管理上的冲突和混乱。
常见用法:为了避免调用进程是进程组组长的情况,通常先调用 fork() 创建子进程,父进程退出,子进程继续执行。子进程继承父进程的进程组 ID,但拥有新的进程 ID,因此不会是进程组组长,可以安全地调用 setsid()。
setsid() 常用于创建守护进程。守护进程是一种在后台运行的特殊进程,不与任何终端关联,通常在系统启动时运行,直到系统关闭时才退出。通过调用 setsid(),守护进程可以脱离用户的终端,避免因终端关闭而导致进程退出。(这也是我们最后的目标)
我们来见见会话

其实:
上边我们提到了会话 ID,那么会话 ID 是什么呢?我们可以先说一下会话首进程,会话首进程是具有唯一进程 ID 的单个进程,那么我们可以将该会话首进程的进程 ID 当作是会话 ID。注意:会话 ID 在有些地方也被称为会话首进程的进程组 ID,因为会话首进程总是一个进程组的组长进程,所以两者是等价的。
控制终端:进程与用户交互的桥梁
在 UNIX 系统中,当用户通过终端登录系统后,会获得一个 Shell 进程。此时,该终端便成为 Shell 进程的控制终端。控制终端的信息是存储在进程控制块(PCB)中的。由于 fork 进程会复制 PCB 中的信息,因此由 Shell 进程启动的其他进程也会将该终端作为它们的控制终端。在没有进行重定向的情况下,每个进程的标准输入、标准输出和标准错误都默认指向控制终端,即进程从标准输入读取的是用户的键盘输入,而进程向标准输出或标准错误输出写入的信息则会显示在显示器上。
会话、进程组以及控制终端之间的关系可以详细描述如下:
-
一个会话可以拥有一个控制终端。当会话首进程打开一个终端(无论是终端设备还是伪终端设备)后,该终端即成为该会话的控制终端。
-
与控制终端建立连接的会话首进程被称为控制进程。
-
在一个会话中,可以有多个进程组,这些进程组可以被划分为一个前台进程组和一到多个后台进程组。
-
如果会话拥有一个控制终端,那么它将包含一个前台进程组,而会话中的其他进程组则属于后台进程组。
-
任何时候,当用户在终端按下中断键(Ctrl+C)或退出键(Ctrl+\),中断信号将被发送给前台进程组的所有进程。
-
如果终端接口检测到调制解调器(或网络连接)已经断开,挂断信号将被发送给控制进程,即会话首进程。
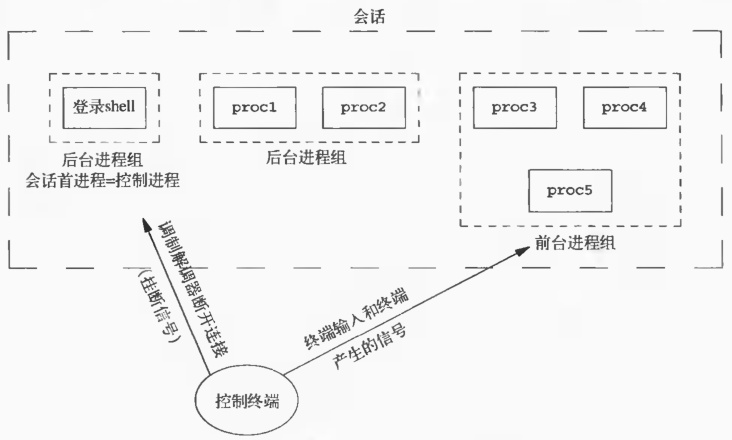
控制终端TTY是用户与系统交互的核心接口,其作用体现在:
- 信号分发中心:用户通过终端快捷键(如Ctrl+C)向前台进程组发送信号。例如,输入
Ctrl+Z时,SIGTSTP信号会暂停前台进程组的所有进程。 - 输入输出重定向:默认情况下,进程的标准输入(stdin)、输出(stdout)和错误(stderr)均指向控制终端。重定向(如
command > log.txt)可改变这一行为。 - 会话与终端的解耦:守护进程通过脱离控制终端(
setsid())实现后台运行,避免因终端关闭而终止。
典型问题:
- 终端孤儿进程:若SSH连接意外断开,会话首进程退出,导致子进程成为孤儿。通过
nohup或tmux工具可避免此问题。
作业控制:多任务并发的调度策略
作业控制是Shell提供的核心功能,允许用户管理前台和后台任务:
| 作业状态 | 含义 |
|---|---|
| 正在运行【Running】 | 后台作业(&),表示正在执行 |
| 完成【Done】 | 作业已完成,返回的状态码为0 |
| 完成并退出【Done(code)】 | 作业已完成并退出,返回的状态码为非0 |
| 已停止【Stopped】 | 前台作业,当前被Ctrl+Z挂起 |
| 已终止【Terminated】 | 作业被终止 |
作业标识:每个作业分配唯一作业号(如[1]),通过jobs命令查看状态(运行中、已停止)。
lfz@HUAWEI:~$ sleep 5000|sleep 3000|sleep 1000 &
[1] 176207
lfz@HUAWEI:~$ jobs
[1]+ Running sleep 5000 | sleep 3000 | sleep 1000 &
这里我们也可以知道,一个任务不能单纯的认为是一个进程来完成的,而是一个进程组!
状态切换:(前后台的概念在之前的文章就已经说过了😭)
&符号启动后台作业/将进程组放在后台中运行(sleep 5000 &)。
Ctrl+Z挂起前台作业,此时bash进程拿回当前会话的前台控制权,就是可以从键盘读取,执行相应的命令了,fg %[作业号]恢复作业到前台。
lfz@HUAWEI:~$ jobs %1
[1]+ Running sleep 5000 | sleep 3000 | sleep 1000 &
lfz@HUAWEI:~$ fg 1
sleep 5000 | sleep 3000 | sleep 1000
^Z
[1]+ Stopped sleep 5000 | sleep 3000 | sleep 1000
信号传递机制:Shell通过进程组管理作业。例如,kill 命令向对应进程组发送信号。
示例流程:
- 用户启动编译任务:
make &(后台运行)。 - 挂起前台编辑器:
Ctrl+Z生成作业号[2]。 - 切换任务:
fg 1将编译任务切回前台,实时查看输出。
守护进程:系统服务的隐形基石
守护进程是脱离终端、长期运行的后台服务,其核心特性包括:
- 生命周期独立:随系统启动而运行,直至系统关闭。例如,
sshd守护进程持续监听SSH连接。 - 环境隔离:
- 终端脱离:通过
setsid()创建新会话,切断与控制终端的关联。 - 目录隔离:调用
chdir("/")避免工作目录被占用。 - 文件描述符关闭:关闭继承的stdin/stdout/stderr,释放资源。
- 终端脱离:通过
- 权限管理:
umask(0)重置文件掩码,确保文件创建权限可控。
前面的铺垫我们讲完了,我们接下来就将我们上一篇实现的网络版本计算器服务端进行守护进程化:
我们需要实现了一个守护进程(Daemon)的创建过程,守护进程是后台运行的进程,通常用于提供服务。
Daemon.hpp
#pragma once#include <iostream>
#include <string>
#include <cstdio>
#include <sys/types.h>
#include <unistd.h>
#include <signal.h>
#include <sys/stat.h>
#include <fcntl.h>
#include "Log.hpp"
#include "Common.hpp"using namespace LogModule;const std::string dev = "/dev/null";// 将服务进行守护进程化的服务
void Daemon(int nochdir, int noclose)
{// 1. 忽略IO,子进程退出等相关的信号signal(SIGPIPE, SIG_IGN);signal(SIGCHLD, SIG_IGN); // SIG_DFL// 2. 父进程直接结束if (fork() > 0)exit(0);// 3. 只能是子进程,孤儿了,父进程就是1setsid(); // 成为一个独立的会话if (nochdir == 0) // 更改进程的工作路径???为什么??chdir("/");// 4. 依旧可能显示器,键盘,stdin,stdout,stderr关联的.// 守护进程,不从键盘输入,也不需要向显示器打印// 方法1:关闭0,1,2 -- 不推荐// 方法2:打开/dev/null, 重定向标准输入,标准输出,标准错误到/dev/nullif (noclose == 0){int fd = ::open(dev.c_str(), O_RDWR);if (fd < 0){LOG(LogLevel::FATAL) << "open " << dev << " errno";exit(OPEN_ERR);}else{dup2(fd, 0);dup2(fd, 1);dup2(fd, 2);close(fd);}}
}
在代码的实现期间,我们有几个需要注意的点:
忽略信号
signal(SIGPIPE, SIG_IGN):为什么这么做:当进程通过管道与另一个进程通信时,如果管道另一端的进程已经退出,继续向管道中写数据会产生 SIGPIPE 信号,默认会终止进程。忽略这个信号可以防止进程因管道断裂而意外退出。(这是我们之前进程间通信时将管道的时候说明的:读端关闭,写端还一直在写,这就会导致系统向该进程发送信号,导致终止进程)
signal(SIGCHLD, SIG_IGN):为什么这么做:当子进程退出时,会向父进程发送 SIGCHLD 信号。默认情况下,父进程会接收这个信号并可能受到影响。忽略这个信号可以让操作系统自动回收子进程的资源,避免父进程被子进程的退出信号打扰。
创建子进程
fork():为什么这么做:通过 fork() 创建一个子进程,父进程在创建子进程后立即退出。这样做的目的是让子进程成为孤儿进程,从而被系统的 init 进程(PID 为 1)收养。init 进程是一个特殊的进程,能够更好地管理守护进程,确保它不会因为父进程的退出而受到影响。(其实主要还是说创建会话的进程不能是组长进程!)
创建新会话
setsid():为什么这么做:调用 setsid() 使进程成为新的会话领导者,并脱离原来的终端。这一步是为了让进程完全独立于终端,即使终端关闭或注销,进程仍然能够在后台运行。会话领导者不会接收到终端产生的挂断信号(如 SIGHUP),从而增强了进程的独立性和稳定性。
更改工作目录
chdir("/"):为什么这么做:如果进程不更改工作目录,它可能会依赖于启动时所在的目录。如果该目录被卸载或有其他操作限制,可能会影响进程的运行。将工作目录更改为根目录(/)可以避免这些问题,确保进程在任何情况下都能正常运行。
重定向标准输入输出
open()、dup2()、close():为什么这么做:守护进程不应该与终端进行交互,因此需要重定向标准输入、输出和错误到 /dev/null。这样可以避免进程从终端读取输入或向终端输出信息,从而完全脱离终端的控制。/dev/null 是一个特殊的设备文件,写入它的数据会被丢弃,读取它时会立即返回文件末尾,非常适合用于守护进程的标准输入输出重定向。
注意事项
错误处理:在关键操作(如打开文件)后添加错误检查,确保程序健壮性。例如,在调用 open() 打开 /dev/null 时,检查返回值是否有效,避免后续操作失败。
资源管理:及时关闭不必要的文件描述符,避免资源泄漏。例如,在使用 dup2() 重定向标准输入输出后,关闭原始的文件描述符。(需要知道重定向的原理到底是什么,这个问题其实在之前的文章就已经详细的说明过了)
日志记录:在关键步骤添加日志,便于调试和问题定位。例如,在忽略信号、创建子进程等步骤后记录日志,帮助开发者了解程序的执行流程。
权限控制:确保进程有权限执行相关操作,如更改目录和重定向文件描述符。例如,在更改工作目录时,确保进程对根目录有访问权限。
因此,接下来,我们就可以实现对上一篇服务端代码的守护进程化了!!!
守护进程化
使用我们上面实现的Daemon.hpp,我们可以将我们上一篇服务端代码的守护进程化:
我们就直接在main.cc代码当中,在合理位置调用就可以了,就是调用后父进程就终止了,子进程就成为新的会话了,这样进程就守护化了:main.cc
然后我们肯定是需要观察日志信息的,我们将日志的另一个模式打开,使其向特定文件上写入日志信息,方便我们以后的查看!
#include "NetCal.hpp"
#include "Protocol.hpp"
#include "TcpServer.hpp"
#include "Daemon.hpp"
#include <memory>void Usage(std::string proc)
{std::cerr << "Usage: " << proc << " port" << std::endl;
}// 我的代码为什么要这样写???
// ./tcpserver 8080
int main(int argc, char *argv[])
{if (argc != 2){Usage(argv[0]);exit(USAGE_ERR);}std::cout << "服务器已经启动,已经是一个守护进程了" << std::endl;Daemon(0, 0);// Enable_Console_Log_Strategy();Enable_File_Log_Strategy();// 1. 顶层std::unique_ptr<Cal> cal = std::make_unique<Cal>();// 2. 协议层std::unique_ptr<Protocol> protocol = std::make_unique<Protocol>([&cal](Request &req) -> Response{ return cal->Execute(req); });// 3. 服务器层std::unique_ptr<TcpServer> tsvr = std::make_unique<TcpServer>(std::stoi(argv[1]),[&protocol](std::shared_ptr<Socket> &sock, InetAddr &client){protocol->GetRequest(sock, client);});tsvr->Start();// sleep(5);return 0;
}
其实Daemon根本就不需要我们自己设计!系统有为我们用户提供的(其实就是我们上面自己写的了,不过还是介绍一下,能快点用干嘛不快点用😘)
daemon
在 Unix-like 系统中,daemon 函数用于将进程转变为守护进程。
#include <unistd.h>
#include <stdlib.h>
int daemon(int nochdir, int noclose);-
nochdir :如果该参数为 0,
daemon函数会将进程的根目录更改到文件系统的根目录(/),这可以防止守护进程所在的文件系统无法卸载。如果为非 0 值,则不更改根目录。 -
noclose :若该参数为 0,函数会关闭所有打开的文件描述符,这是为了防止守护进程持有不必要的文件资源。若为非 0,文件描述符保持打开状态。
-
成功时返回 0。失败时返回 -1,并设置相应的错误码(
errno),如ECHILD表示 fork 失败,ENOMEM表示内存不足等。
调用 daemon 函数后,会进行一系列操作将当前进程转变为守护进程。主要包括:调用 fork 使父进程退出,子进程继续执行,脱离终端会话;子进程成为新的会话 leader 并脱离控制终端;设置进程的根目录、工作目录等;关闭不必要的文件描述符;重定向标准输入、输出、错误文件描述符等。
lfz@HUAWEI:~/lesson/lesson41/NetCal$ ./ServerNetCald 8080
服务器已经启动,已经是一个守护进程了
lfz@HUAWEI:~/lesson/lesson41/NetCal$ ps -axj | head -1 && ps -axj | grep ServerNetCald | grep -v grepPPID PID PGID SID TTY TPGID STAT UID TIME COMMAND1 210139 210139 210139 ? -1 Ss 1000 0:00 ./ServerNetCald 8080
lfz@HUAWEI:~/lesson/lesson41/NetCal$ ./client_netcal 113.45.250.155 8080
[2025-05-11 18:20:35] [INFO] [210458] [Socket.hpp] [72] - socket success
Please Enter x: 30
Please Enter y: 12
Please Enter oper: *
计算结果是: 360[0]
Please Enter x: 13
Please Enter y: 0
Please Enter oper: %
计算结果是: 0[2]
Please Enter x: 13
Please Enter y: 0
Please Enter oper: /
计算结果是: 0[1]
Please Enter x: 简单发布
在开发过程中,我们不仅需要编写代码,还需要考虑如何将应用程序发布给用户。今天,我将分享如何将一个简单的C++应用程序打包并发布。
项目结构
我们的项目包含以下文件:
-
main.cc:服务器端主程序。 -
TcpClient.cc:客户端主程序。 -
Makefile:用于编译项目。 -
install.sh和uninstall.sh:用于安装和卸载应用程序的脚本。 -
test.conf:配置文件。
Makefile
Makefile用于自动化编译过程。我们定义了几个主要目标:
.PHONY:all
all:ServerNetCald client_netcal ServerNetCald:main.ccg++ -o $@ $^ -std=c++17 -ljsoncpp -static -lpthread
client_netcal:TcpClient.ccg++ -o $@ $^ -std=c++17 -ljsoncpp -static -lpthread.PHONY:output
output:@mkdir output@mkdir -p output/bin@mkdir -p output/conf@mkdir -p output/log@cp ServerNetCald output/bin@cp client_netcal output/bin@cp test.conf output/conf@cp install.sh output/@cp uninstall.sh output/@tar czf output.tgz output.PHONY:clean
clean:rm -rf ServerNetCald client_netcal output output.tgz-
all:编译生成服务器端和客户端程序。 -
output:创建输出目录结构,并将编译后的程序、配置文件和脚本打包成output.tgz。 -
clean:清理生成的文件。
shell脚本
我们编写了两个shell脚本用于安装和卸载应用程序。
install.sh
#!/usr/bin/bashcp -f ./bin/ServerNetCald /usr/bin
cp -f ./bin/client_netcal /usr/bin该脚本将编译后的程序复制到系统的 /usr/bin 目录下。
uninstall.sh
#!/usr/bin/bashrm -rf /usr/bin/ServerNetCald
rm -f /usr/bin/client_netcal该脚本用于删除安装的程序。
发布步骤
-
确保所有源代码文件和必要的依赖项都在项目目录中。
-
在项目根目录下运行
make命令编译项目。 -
运行
make output生成包含应用程序的output.tgz包。 -
将
output.tgz分发给用户。 -
用户解压
output.tgz后,可以运行install.sh安装应用程序,运行uninstall.sh卸载应用程序。
通过以上步骤,我们可以轻松地将C++应用程序打包并发布给用户。
使用xshell的实际情况
在Linux系统中,用户通过xshell这样的远程终端连接工具登录到服务器时,会经历一个复杂但有序的进程创建和管理过程。这个过程涉及到会话(Session)、进程组(Process Group)、控制终端(Controlling Terminal)等概念,它们共同协作以确保用户能够顺利地与系统进行交互。
首先,当用户通过xshell发起登录请求时,Linux系统会进行身份验证。如果认证成功,系统将为该用户创建一个新的会话。会话是用户与系统交互的上下文环境,它包含了用户登录过程中创建的所有进程。在Linux中,每个会话都有一个唯一的会话ID(Session ID),这个ID通常被设置为该会话中bash进程的进程ID(PID)。
创建会话后,系统会默认创建一个进程组,这个进程组通常被称为bash进程组。进程组是一组进程的集合,它们可以共享某些资源,如信号。在这个进程组中,bash进程作为首进程(session leader),负责管理该组内的所有进程。
为了使进程能够与用户进行交互,系统还需要创建一个控制终端。控制终端是一个特殊的文件,它代表了用户的终端设备,使得进程可以接收用户的输入并将输出发送给用户。在图中,这个控制终端被表示为/dev/pts/XXX,其中XXX是一个特定的标识符。
接下来,bash进程会打开三个标准文件描述符:标准输入(0)、标准输出(1)和标准错误(2)。这些文件描述符最初是指向控制终端的,允许用户通过终端与bash进程进行交互。
在bash进程内部,可能会调用fork()系统调用来创建一个新的子进程。fork()会创建当前进程的一个副本,新创建的子进程最初与父进程完全相同,但随后它们可以独立执行不同的任务。在图中,这个过程被表示为fork() -> exec(bash),意味着子进程通过exec()系列函数加载并执行bash程序,从而启动一个新的bash会话。
此外,图中还展示了多个进程组的存在。除了bash进程组外,还有其他进程组,如运行server_netcat的进程组2,以及其他独立的进程组3。这些进程组中的进程可以独立运行,也可以通过进程间通信(IPC)机制进行数据交换和同步。
总的来说,这个过程展示了Linux系统如何通过创建和管理会话、进程组和控制终端来支持用户的登录和交互。这些机制确保了用户可以启动和管理多个进程,同时保持系统的稳定性和安全性。通过这种方式,用户可以在Linux系统中执行各种命令和操作,进行文件编辑、程序编译、网络通信等任务。