可变参数模板
引入:为什么会有可变参数模板?
一:可变参数模板的格式
// Args是一个模板参数包,args是一个函数形参参数包
// 声明一个参数包Args...args,这个参数包中可以包含0到任意个模板参数。
template <class ...Args>
void ShowList(Args... args)
{}//随意更换
template <class ...>
void ShowList(T... t)
{}解释:
①:模板参数Args前面有省略号,代表它是一个可变模板参数,我们把带省略号的参数称为参数包,参数包里面可以包含0到N ( N ≥ 0 ) N(N\geq 0)N(N≥0)个模板参数,而args则是一个函数形参参数包。
②:Args译为参数,我们之前一般用T来表示模板,这里的Args也可以随便更换,但用Args和args是最好的,和官方一致
现在调用ShowList函数时就可以传入任意多个参数了,并且这些参数可以是不同类型的。比如:
int main()
{ShowList();ShowList(1);ShowList(1, 'A');ShowList(1, 'A', string("hello"));return 0;
}![]()
但是,使用不是重点,可变参数模版的重点在于如何获取参数包里面的每一个参数...
二:错误展开参数包
当main中传入参数如下的时候:
ShowList(1, 'A', string("hello"));我们希望能得到传入的参数,并将其打印出来,期望效果如下:
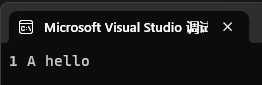
错误方法->期望循环遍历数组打印
template<class ...Args>
void ShowList(Args... args)
{//错误示例:for (int i = 0; i < sizeof...(args); i++){cout << args[i] << " "; //打印参数包中的每个参数}cout << endl;
}
报错如下:
![]()
解释:以上操作是运行时解析,而展开参数包需要编译时解析
换句话说:在C++中,模板参数包的展开必须在编译时完成,而以上代码试图在运行时通过循环访问参数包,这是不允许的。
编译和运行两者的区别:
编译时解析(Compile-Time Expansion)
含义:模板和参数包的展开是在代码编译期间完成的,编译器需要知道所有参数的类型和数量。
运行时解析(Run-Time Access)
含义:在程序运行期间动态访问数据(如数组、循环等),此时模板参数已经编译成具体代码,无法再改变。
-
sizeof...(args)可以获取参数包的大小(编译时计算),但args[i]试图在运行时访问参数包,这是不允许的。 -
原因:
-
参数包
args不是数组或容器,它是一组编译时确定的参数,无法在运行时动态索引。 -
模板在编译时实例化,例如
ShowList(1, "hello", 3.14)会生成一个专门的函数,但args[1]这样的操作在语法上不存在。
-
三:正确展开参数包
①:递归展开参数包
void _ShowList()
{cout << endl;
}//如果想依次拿到每个参数类型和值,编译时递归解析
template <class T, class ...Args>
void _ShowList(const T& val, Args... args)
{cout << val << " ";_ShowList(args...);
}template <class ...Args>
void ShowList(Args... args)
{_ShowList(args...);
}int main()
{ShowList(1, 'A', string("hello"));return 0;
}
代码解释:
a:入口函数->就是我们正常写的可变参数模版
template <class ...Args>
void ShowList(Args... args)
{_ShowList(args...);
}_ShowList(args...);代表展开参数包进行传递给 _ShowList函数, _ShowList现在的参数就是(1,'A',"hello"),而 _ShowList的参数就是能够接受可变模板参数的,所以匹配
解释:只需调用 ShowList(1, "abc", 3.14),无需关心递归逻辑。
b:递归展开
template <class T, class ...Args>
void _ShowList(const T& val, Args... args)
{cout << val << " "; // 处理当前参数_ShowList(args...); // 递归处理剩余参数
}-
作用:每次调用时,分离出参数包的第一个参数(
val),并递归处理剩余参数(args...)。 -
关键点:
-
T:当前参数的类型(如int、string等)。 -
val:参数包的第一个值(如1、"hello"等)。 -
Args... args:剩余的参数包(数量比当前少 1)。 -
递归调用:
_ShowList(args...)会继续匹配这个模板或终止条件。
-
c:递归终止条件
void _ShowList()
{cout << endl;
}-
作用:当参数包
args...被递归展开到空时,调用这个无参版本,结束递归。 -
关键点:
-
这是一个普通函数(非模板),用于终止递归。
-
当
args...为空时,_ShowList()会匹配这个版本,打印换行并结束调用链。
-
运行结果:
递归过程的展开讲解:
//实例化以后,推演生成的过程
void ShowList(int val1, char ch, std::string s)
{_ShowList(val1, ch, s);
}void _ShowList(const int& val, char ch, std::string s)
{cout << val << " ";_ShowList(ch, s);
}void _ShowList(const char& val, std::string s)
{cout << val << " ";_ShowList(s);
}void _ShowList(const std::string& val)
{cout << val << " ";_ShowList();
}
解释:在递归的过程中,参数会越来越少,最后会调用无参的_ShowList终止循环
②:逗号表达式展开参数包
这个方法很抽象,在理解这个方法之前,要先学会一些东西
语法1:在 C++ 中,当在初始化的括号中进行{args...} ,这一步能直接展开参数包!
语法2:逗号表达式的性质
语法1列子:args遇到int数组初始化的{ }
//展开函数
template<class ...Args>
void ShowList(Args... args)
{int arr[] = { args... }; //数组初始化//打印参数包中的各个参数for (auto e : arr){cout << e << " ";}cout << endl;
}int main()
{ShowList(1,2,3,4);return 0;
}运行结果:

解释:在 C++ 中,当在初始化的括号中进行{args...} ,这一步能直接展开参数包;题目中用的是数组的{},所以会展开参数包并逐个填充数组。
类似:
int arr[] = { args... }; 参数包展开后如下:↓int arr[] = { 1,2,3,4};也就是说,当参数包全是整形,或者参数是能够转换为整形的值的时候(double...),展开参数包,直接用一个数组接收然后遍历数组打印就可以了!
但是问题是,参数包一般不会全是整形,有可能如下(int char string都在一起):
(1, 'A', string("sort")这个时候,无法用一个int数组的{}来展开并接受所有的参数了 ,会报错:
![]() (字符转换为整形的ascll码值了)
(字符转换为整形的ascll码值了)
所以现在我们思路是:
a:既然{}中能够进行参数包的打开,那我们能不能运用这个特性在{}中将展开得到的参数逐个的打印?
b:但是只在数组的{}中进行参数包的展开是肯定不行的,人家数组接收的是int,那有什么东西即能在{}中展开参数包,又能返回一个整形值?
c:所以我们用一个逗号表达式操作,逗号表达式的第一个动作先进行参数包的第一个参数的打印,第二个动作给上一个0,根据逗号表达式的特性,会执行完单个参数的打印后,返回这个0给数组,这样我们既白嫖了参数包在{}中能展开的特性,又把逗号表达式返回的0给了数组
语法1+语法2的例子:
template <class T>
void PrintArg(T t)
{cout << t << " ";
}
//展开函数
template <class ...Args>
void ShowList(Args... args)
{int arr[] = { (PrintArg(args...), 0) };cout << endl;
}
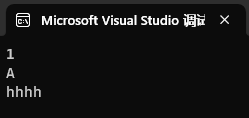
int main()
{ShowList(1);ShowList('A');ShowList(string("hhhh"));return 0;
}运行结果:
但是我们的参数包一般不会只是一个参数,所以要写作下面这样:
//打印参数包的单个参数
template <class T>
void PrintArg(T t)
{cout << t << " ";
}//展开函数
template <class ...Args>
void ShowList(Args... args)
{int arr[] = { (PrintArg(args), 0)... };cout << endl;
}int main()
{ShowList(1, 'A', string("sort"));return 0;
}运行结果:

代码解释:
int arr[] = { (PrintArg(args), 0)... };这里的三个点... 一定要写在逗号表达式的外面,寓意着,参数包中的每个参数都会单独的进入逗号表达式 如下所示:
{ (PrintArg(1), 0), (PrintArg('A'), 0), (PrintArg("sort"), 0) }变成↓
int arr[] ={0,0,0};这样我们既使用{}的特性完成了参数包的展开打印,也利用了逗号表达式的特性返回了0给数组
而数组是什么值,我们根本不关心,我们关心的是展开参数包成功了
总结:数组的{}有着展开参数包的功能,但是呢数组不能白白给你展开参数包,它的{}要的是一个整形值,所以我们就用逗号表达式来即进行了展开参数包,又返回了整形值
四:可变模版参数的运用场景
可变模版参数的运用场景就是在于STL容器中的emplace相关接口函数,因为emplace相关接口函数的参数就是一个可变模版参数,这也是为什么很多人说emplace相关接口函数的效率更高的原因
例子:
如list容器的push_front、push_back和insert函数,都增加了对应的emplace_front、emplace_back和emplace函数。如下:
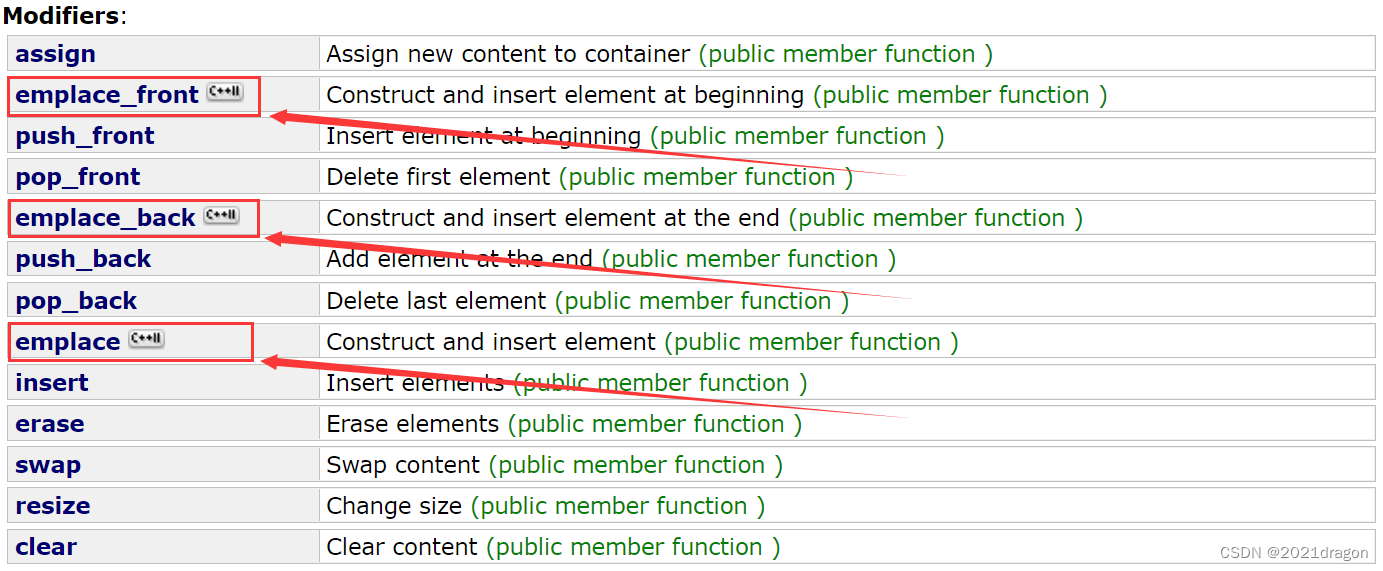
比如list容器的emplace_back函数的声明如下:

注意:

好,下面我们举例验证为什么emplace_back的效率比push_back高~
为什么说emplce接口比普通的函数接口效率更高?以list容器的emplace_back和push_back为例:

解释:emplce的参数传入参数包的时候,效率极高
下面,我们将用库中的链表进行push_back插入和emplace_back插入一个string类型的值,而这个string类呢,我们用自己实现的,因为自己实现的string类当中的构造/拷贝构造/移动构造被调用的时候,会打印相关的信息,这样我们就知道为什么emplace_back的效率高了!
自己实现的string类代码:
namespace bit
{class string{public://构造函数string(const char* str = ""):_size(strlen(str)), _capacity(_size){cout << "构造函数" << endl;_str = new char[_capacity + 1];strcpy(_str, str);}// s1.swap(s2)void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}// 拷贝构造 -- 左值string(const string& s):_str(nullptr){cout << "拷贝构造 -- 深拷贝" << endl;_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}// 移动构造 -- 右值string(string&& s){cout << "移动构造" << endl;swap(s);}// 拷贝赋值 -- 左值// s2 = tmpstring& operator=(const string& s){cout << "拷贝赋值 -- 深拷贝" << endl;string tmp(s);swap(tmp);return *this;}// 移动赋值 -- 右值string& operator=(string&& s){cout << "移动赋值" << endl;swap(s);return *this;}//析构函数~string(){delete[] _str;_str = nullptr;}private:char* _str = nullptr;size_t _size = 0;size_t _capacity = 0; // 不包含最后做标识的\0};
}
①:对push_back和emplace_back插入对象
int main()
{std::list<bit::string> lt1;bit::string s1("xxxx");lt1.push_back(s1);lt1.push_back(move(s1));cout << "=============================================" << endl;bit::string s2("xxxx");lt1.emplace_back(s2);lt1.emplace_back(move(s2));cout << "=============================================" << endl;return 0;
} 运行结果:
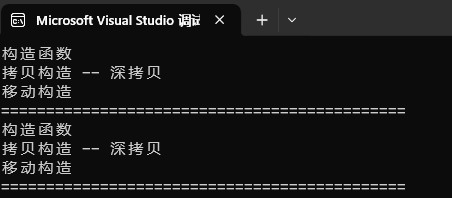
结论:当emplace参数不是参数包的时候,其效率和push_back一致!
解释:push_back:打印效果里面的构造函数是"xxxx"构造出了左值s1,然后此时链表push_back函数会对这个左值s1进行拷贝构造(深拷贝)出一个链表所需的节点;而对于move后的s1是右值,所以push_back函数会对这个右值进行移动构造出一个链表所需的节点,这就是为什么是:构造函数+拷贝构造+移动构造;enplace同理,不再赘述~
如图:
②:对push_back和emplace_back插入构造参数
int main()
{std::list<bit::string> lt1;lt1.push_back("xxxx");lt1.emplace_back("xxxx");cout << "=============================================" << endl;return 0;}运行结果:
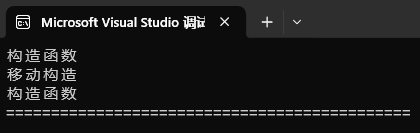
结论:当emplace参数是构造参数(参数包)的时候,其效率高于push_back
解释:push_back:首先会对右值"xxxx"进行构造出一个临时变量,然后push_back函数会对这个临时变量的资源进行移动构造出一个节点,所以是构造函数+移动构造(临时变量也是右值)
emplce_back呢:仅仅只需要构造函数,也就是直接用"xxxx"这个右值构造出了一个节点,所以只有构造函数
如图:
Q:为什么emplace_back()仅需要调用一次string类的构造函数,就能构造出一个链表的节点?
A:emplace_back 是 C++11 引入的高效方法,其核心特点是 直接在容器内构造对象,避免了临时对象的创建和移动/拷贝。
所以到这里,我们证明为什么emplace类的接口函数效率高,因为直接传参数包的时候,会直接构造!
下面看一个复杂场景下,emplace效率会更高:
int main()
{std::list<pair<bit::string, bit::string>> lt2;pair<bit::string, bit::string> kv1("xxxx", "yyyy");lt2.push_back(kv1);lt2.push_back(move(kv1));cout << "=============================================" << endl;pair<bit::string, bit::string> kv2("xxxx", "yyyy");lt2.emplace_back(kv2);lt2.emplace_back(move(kv2));cout << "=============================================" << endl;return 0;}运行结果:
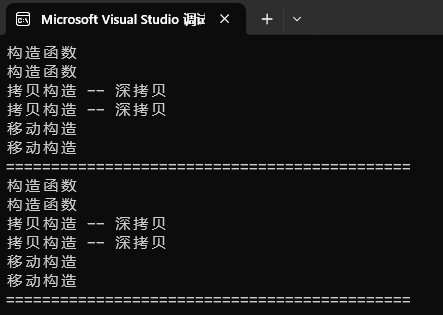
和前面一致,当不是传递参数包的时候,效率和push_bcak一致
当我们emplace传递参数包的时候:
int main()
{std::list<pair<bit::string, bit::string>> lt2;lt2.emplace_back("xxxx", "yyyy");cout << "=============================================" << endl;return 0;
}
运行结果:
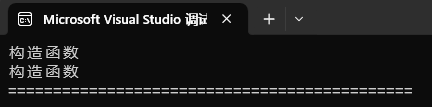
解释:
既然你的链表存储的类型是pair<string,string>,那emplace直接用"xxxx"和"yyyy"去构造节点!
所以两次构造即可,而不传参数包需要两次构造+两次拷贝构造 或 两次构造+两次移动构造
五:emplace_bcak 和 push_back在特定情况下的差异
-
对于浅拷贝的类(比如只包含基本类型成员,拷贝成本低),
emplace_back的优势可能不明显。 -
但对于没有移动构造函数的类,
emplace_back能避免一次拷贝构造,提升效率。 -
如果类有移动构造函数,
push_back和emplace_back的性能差距会缩小(因为临时对象可以通过移动构造转移资源,而非拷贝)。
总结:当类有移动构造的时候,我emplace_back只能省略移动构造的消耗,所以差距不大;
但当类没有移动构造,只有拷贝构造的时候,我emplace_back就及其优秀了,会省略拷贝构造!
例子:
一个没有移动构造的Date类
class Date
{
public:Date(int year, int month, int day):_year(year), _month(month), _day(day){cout << "构造函数" << endl;}Date(const Date& d):_year(d._year), _month(d._month), _day(d._day){cout << "拷贝函数" << endl;}
private:int _year = 1;int _month = 1;int _day = 1;
};int main()
{std::list<Date> lt1;lt1.push_back({ 2024,3,30 });lt1.emplace_back(2024, 3, 30);return 0;
}运行结果:
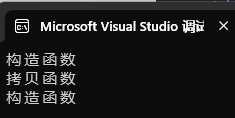
解释:

六:所有源码
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;#include<vector>
#include<list>
#include<map>
#include<set>
#include<string>#include<assert.h>namespace bit
{class string{public://构造函数string(const char* str = ""):_size(strlen(str)), _capacity(_size){cout << "构造函数" << endl;_str = new char[_capacity + 1];strcpy(_str, str);}// 交换函数void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}// 拷贝构造string(const string& s):_str(nullptr){cout << "拷贝构造 -- 深拷贝" << endl;_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}//移动构造string(string&& s):_str(nullptr), _size(0), _capacity(0){cout << "移动构造" << endl;swap(s);}//赋值重载//s1 = s3 string& operator=(const string& s) {if (this != &s) {char* tmp = new char[s._capacity + 1];strcpy(tmp, s._str);delete[] _str;_str = tmp;// 把容量和大小赋过去_size = s._size;_capacity = s._capacity;}cout << "赋值重载----深拷贝" << endl;return *this; // 结果返回*this}// 移动赋值string& operator=(string&& s){cout << "移动赋值" << endl;swap(s);return *this;}//析构~string(){delete[] _str;_str = nullptr;}private:char* _str;size_t _size;size_t _capacity; // 不包含最后做标识的\0};}//体现有名对象 匿名对象 emplace都无区别
//直接给插入对象参数的时候 才有用
//int main()
//{
// /*std::list<bit::string> lt1;*/
//
// //bit::string s1("xxxx");
// //lt1.push_back(s1);
// //lt1.push_back(move(s1));
// //cout << "=============================================" << endl;
//
// //bit::string s2("xxxx");
// //lt1.emplace_back(s2);
// //lt1.emplace_back(move(s2));
// //cout << "=============================================" << endl;
//
// //lt1.push_back("xxxx");
// //lt1.emplace_back("xxxx");
// //cout << "=============================================" << endl;
//
// std::list<pair<bit::string, bit::string>> lt2;
// //pair<bit::string, bit::string> kv1("xxxx", "yyyy");
// //lt2.push_back(kv1);
// //lt2.push_back(move(kv1));
// //cout << "=============================================" << endl;
//
// //pair<bit::string, bit::string> kv2("xxxx", "yyyy");
// //lt2.emplace_back(kv2);
// //lt2.emplace_back(move(kv2));
// //cout << "=============================================" << endl;
//
// lt2.emplace_back("xxxx", "yyyy");
// cout << "=============================================" << endl;
//
//
// return 0;
//}class Date
{
public:Date(int year, int month, int day):_year(year), _month(month), _day(day){cout << "构造函数" << endl;}Date(const Date& d):_year(d._year), _month(d._month), _day(d._day){cout << "拷贝函数" << endl;}
private:int _year = 1;int _month = 1;int _day = 1;
};int main()
{std::list<Date> lt1;lt1.push_back({ 2024,3,30 });lt1.emplace_back(2024, 3, 30);cout << endl;Date d1(2023, 1, 1);lt1.push_back(d1);lt1.emplace_back(d1);cout << endl;lt1.push_back(Date(2023, 1, 1));lt1.emplace_back(Date(2023, 1, 1));return 0;
}