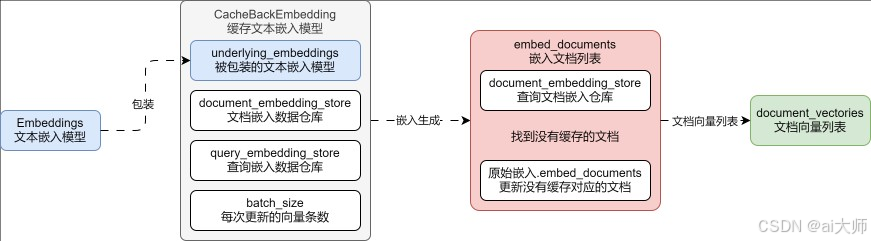
CacheBackEmbedding 组件的运行流程和使用注意事项
1. CacheBackEmbedding 的使用与应用场景
背景介绍
使用嵌入模型计算数据向量需要消耗大量算力。对于重复内容,Embeddings 的计算结果是固定的,重复计算不仅效率低下,还会造成资源浪费。
解决方案
LangChain 提供了 CacheBackEmbedding 包装类来解决这个问题。通常通过 from_bytes_store 类方法进行实例化。
资料推荐
- 💡大模型中转API推荐
- ✨中转使用教程
主要参数说明
-
underlying_embedder
- 作用:指定用于嵌入的基础模型
- 类型:嵌入模型对象
-
document_embedding_cache
- 作用:用于缓存文档嵌入的存储库
- 类型:ByteStore
-
batch_size
- 作用:控制存储更新间的文档嵌入数量
- 默认值:None
- 可选参数
-
namespace
- 作用:文档缓存的命名空间,用于避免缓存冲突
- 默认值:“”
- 建议设置为所使用的嵌入模型名称
-
query_embedding_cache
- 作用:用于缓存查询/文本嵌入的存储库
- 默认值:None(不缓存)
- 可设置为 True 以使用与 document_embedding_cache 相同的存储
注意事项
CacheBackEmbedding默认不会缓存embed_query生成的向量- 如需缓存查询向量,需要明确设置
query_embedding_cache参数 - 强烈建议设置
namespace参数,避免不同嵌入模型间的缓存冲突
示例代码
import dotenv
import numpy as np
from langchain.embeddings import CacheBackedEmbeddings
from langchain.storage import LocalFileStore
from langchain_openai import OpenAIEmbeddings
from numpy.linalg import normdotenv.load_dotenv()def cosine_similarity(vector1: list, vector2: list) -> float:"""计算传入两个向量的余弦相似度"""# 1.计算内积/点积dot_product = np.dot(vector1, vector2)# 2.计算向量的范数/长度norm_vec1 = norm(vector1)norm_vec2 = norm(vector2)# 3.计算余弦相似度return dot_product / (norm_vec1 * norm_vec2)embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
embeddings_with_cache = CacheBackedEmbeddings.from_bytes_store(embeddings,LocalFileStore("./cache/"),namespace=embeddings.model,query_embedding_cache=True,
)query_vector = embeddings_with_cache.embed_query("你好,我是xxx,我喜欢打篮球")
documents_vector = embeddings_with_cache.embed_documents(["你好,我是xxx,我喜欢打篮球","这个喜欢打篮球的人叫xxx","求知若渴,虚心若愚"
])print(query_vector)
print(len(query_vector))print("============")print(len(documents_vector))
print("vector1与vector2的余弦相似度:", cosine_similarity(documents_vector[0], documents_vector[1]))
print("vector2与vector3的余弦相似度:", cosine_similarity(documents_vector[0], documents_vector[2]))
2. CacheBackEmbedding 底层运行流程
核心原理
CacheBackEmbedding 本质是一个封装了持久化存储功能的数据仓库系统。
详细流程
-
数据检索
- 从数据存储仓库中检索对应向量
- 对输入文本进行匹配查找
-
缓存比对
- 逐个匹配数据是否存在
- 筛选出缓存中不存在的文本
-
向量生成
- 对未缓存的文本调用嵌入模型
- 生成新的向量表示
-
数据存储
- 将新生成的向量存入数据仓库
- 完成向量的持久化存储
工作机制
通过以上流程,CacheBackEmbedding 实现了对重复数据的高效处理,避免了重复计算,提高了系统效率。
资料推荐
- 💡大模型中转API推荐
- ✨中转使用教程
图示