【训练】Datawhale AI春训营 发电功率预测
任务和主题
AI新能源功率预报:根据历史发电功率数据和对应时段多类别气象预测数据,实现次日零时起到未来24小时逐15分钟级新能源场站发电功率预测。
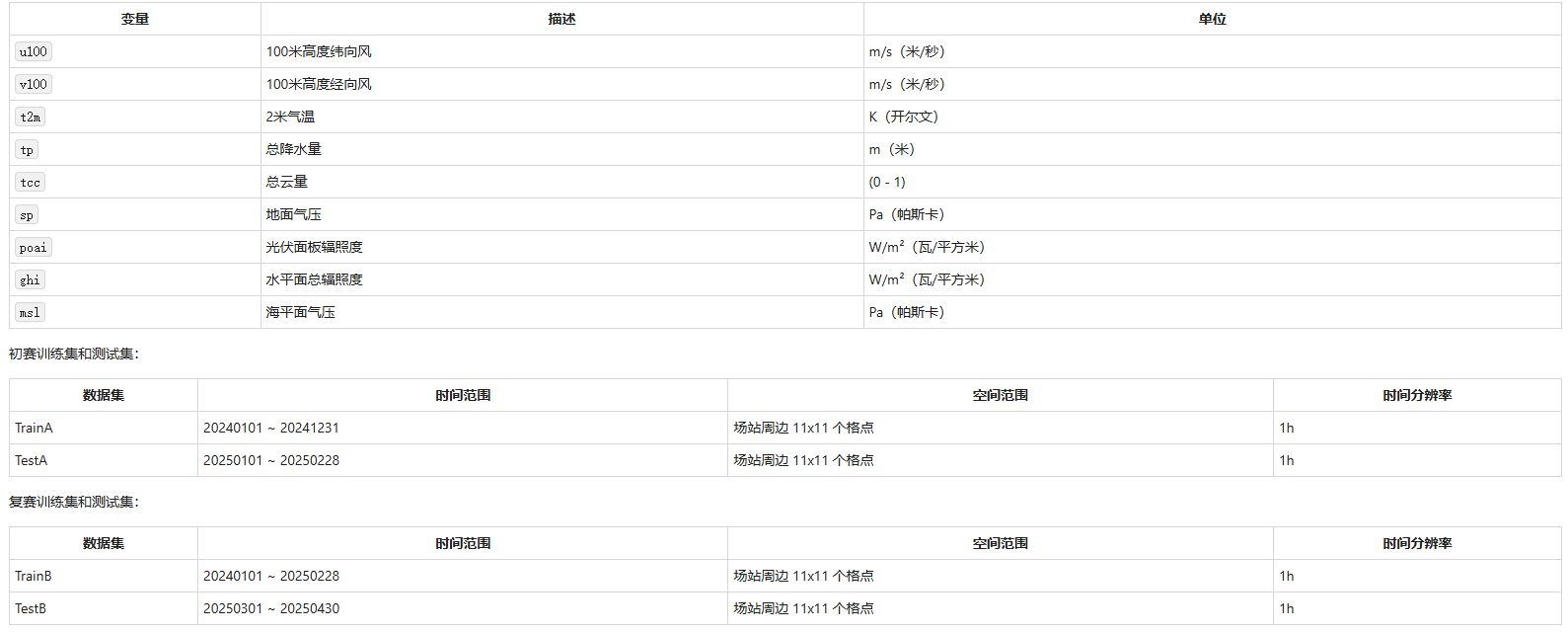
比赛数据
1 .气象数据
比赛输入数据来自三个不同的气象预报数据,数据格式为nc,共8个变量,需要注意气象源NWP_2的变量与另外两个稍有不同。气象变量说明见下文。每个文件是第二天北京时间0点开始的未来24小时气象预报,时间间隔1小时,文件名的日期表示预报发布日期,如20240101.nc是2024年1月1日发布的,对1月2日的预报。每个输入文件有5个维度,time,channel,hour,lat,lon。
time表示数据第一个时刻,为世界时;channel为变量,共8维;hour为从起始时间到预报时间的时间间隔(数据集里没有hour,实际上是lead_time),数值为0~23;lat为纬度,数值从小到大为从北向南排列;lon为经度,数值从小到大为从西向东排列。这里经纬度数值仅代表相对关系,中心点为离场站最近的点。
参赛队伍可以不使用全部气象源的全部变量做为输入。
2.场站实发功率
比赛目标数据来自10个新能源场站的归一化处理后的实发功率,其中包含5个风电场站和5个光伏场站。编号1-5为风电场,6-10为光伏电场。数据时间为北京时间,数据时间间隔为15分钟。需要注意数据中偶有空值、死值等异常值。
3.气象变量说明:
气象源1(NWP_1)、气象源3(NWP_3): [u100, v100, t2m, tp, tcc, sp, poai, ghi],
气象源2(NWP_2): [u100, v100, t2m, tp, tcc,msl,poai,ghi]
具体看官网第三届世界科学智能大赛新能源赛道:新能源发电功率预测
Task2 baseline学习过程与思考
以下代码均为在python语言notebook运行,在IDE下变量需要用print语句
1. 数据探索分析
#读取并查看训练集中气象数据
nc_path = "data/初赛训练集/nwp_data_train/1/NWP_1/20240101.nc"
dataset = Dataset(nc_path, mode='r')
dataset.variables.keys()
#输出:dict_keys(['time', 'channel', 'data', 'lat', 'lon', 'lead_time'])
.nc文件即 NetCDF(Network Common Data Form)文件,是一种用于存储和共享科学数据的文件格式,由美国大学大气研究协会(UCAR)的 Unidata项目开发。它在气象、海洋、地理等众多科学领域被广泛应用。
- 维度(Dimensions):
定义了数据的形状和大小,例如时间、纬度、经度等。通过维度,可以确定数据在各个方向上的长度和范围。 - 变量(Variables):
存储实际的科学数据,每个变量都有自己的数据类型(如整型、浮点型等),并且可以与一个或多个维度相关联。例如,气温数据可能是一个与时间、纬度和经度维度相关联的变量。
这里打印出来的维度可以发现与比赛数据说明中的差不多,hour实际上是lead_time
channel = dataset.variables["channel"][:]
channel
# 输出:array(['ghi', 'poai', 'sp', 't2m', 'tcc', 'tp', 'u100', 'v100'], dtype=object)
打印channel,可以确认与气象源变量数据是对应的
data = dataset.variables["data"][:]
data.shape
# 输出:(1, 24, 8, 11, 11)
最后这个多出来的data官方文件没有说明,打印shape发现跟数据维度对应,lead_time是24小时,channel为8个变量的数据,11X11对应空间范围的格点
2. 数据处理
# 获取2024年日期
date_range = pd.date_range(start='2024-01-01', end='2024-12-30')
# 将%Y-%m-%d格式转为%Y%m%d
date = [date.strftime('%Y%m%d') for date in date_range]
# 定义读取训练/测试集函数
def get_data(path_template, date):# 读取该天数据dataset = Dataset(path_template.format(date), mode='r')# 获取列名channel = dataset.variables["channel"][:]# 获取列名对应的数据data = dataset.variables["data"][:]# for i in range(8) 表示将第三维度进行遍历# data[:, :, i, :, :][0] 的维度为(24, 11, 11)# np.mean(data[:, :, i, :, :][0], axis=(1, 2) 表示对该数组的第二、三个维度(11, 11)计算均值 生成的列表长度为24# 又因为循环了8次 因此形状为8*24# 我们最后使用.T进行转置 将数组的维度转成了24*8mean_values = np.array([np.mean(data[:, :, i, :, :][0], axis=(1, 2)) for i in range(8)]).T# 将数据与列名整合为dataframereturn pd.DataFrame(mean_values, columns=channel)
# 定义路径模版
train_path_template = "/sdc/model/data/初赛训练集/nwp_data_train/1/NWP_1/{}.nc"
# 通过列表推导式获取数据 返回的列表中每个元素都是以天为单位的数据
data = [get_data(train_path_template, i) for i in date]
# 将每天的数据拼接并重设index
train = pd.concat(data, axis=0).reset_index(drop=True)
# 读取目标值
target = pd.read_csv("/sdc/model/data/初赛训练集/fact_data/1_normalization_train.csv")
target = target[96:]
# 功率数据中每四条数据去掉三条
target = target[target['时间'].str.endswith('00:00')]
target = target.reset_index(drop=True)
# 将目标值合并到训练集
train["power"] = target["功率(MW)"]
这个步骤是读取场站1下的NWP_1气象源的所有日期范围数据,实际训练数据没有20241231,在测试集里,测试集数据页没有20250228,并把场站1的功率数据进行拼接,因为气象源数据只有24小时的,功率数据是15分钟的,也就是一个小时4条,所以这里为了对应简单把功率数据每小时去掉三条刚好保留每小时1条数据跟气象源数据进行拼接,优化可以考虑取均值等别的方式,target = target[96:]跳过了前96条,即功率数据对应要后一天数据。可以使用过以下语句查看拼接好的数据信息确认拼接情况。
print(train.shape)
print("完整列信息:", train.columns.values)
(8760, 9)
完整列信息: ['ghi' 'poai' 'sp' 't2m' 'tcc' 'tp' 'u100' 'v100' 'power']
测试集以同样的方式处理,但不需要拼接power列
test_path_template = "data/初赛测试集/nwp_data_test/1/NWP_1/{}.nc"
date_range = pd.date_range(start='2024-12-31', end='2025-02-27')
date = [date.strftime('%Y%m%d') for date in date_range]
data = [get_data(test_path_template, i) for i in date]
test = pd.concat(data, axis=0).reset_index(drop=True)
3.特征工程
这里构建了5个特征,可以理解为向以上拼接后的9列数据的train额外添加了5列,这5列代表的含义在代码注释里有有说明不再赘述,这里的特征构建同时考虑了对风电和光伏不同类型的场站
# 构建特征
def feature_combine(df):df_copy = df.copy()# 经纬度两个方向的风速进行向量计算 获取实际风速df_copy["wind_speed"] = np.sqrt(df_copy['u100']**2 + df_copy['v100']**2)# 添加小时特征 捕捉数据的时间周期性df_copy["h"] = df_copy.index % 24# 特征组合# 计算ghi(水平面总辐照度)与poai(光伏面板辐照度)的比值# 反映光伏组件的效率df_copy["ghi/poai"] = df_copy["ghi"] / (df_copy["poai"] + 0.0000001)# 同上df_copy["ghi_poai"] = df_copy["ghi"] - df_copy["poai"]# 计算总风速与sp(气压)的比值。有助于捕捉风速与气压之间的关系df_copy["wind_speed/sp"] = df_copy["wind_speed"] / (df_copy["sp"] + 0.0000001)return df_copytrain = feature_combine(train)
train = train.dropna().reset_index(drop=True)
可以通过打印查看构建后的train
print(train.shape)
print("完整列信息:", train.columns.values)
(8760, 14)
完整列信息: ['ghi' 'poai' 'sp' 't2m' 'tcc' 'tp' 'u100' 'v100' 'power' 'wind_speed' 'h' 'ghi/poai' 'ghi_poai' 'wind_speed/sp']
对测试集进行同样的操作
test = feature_combine(test)
test = test.dropna().reset_index(drop=True)
print(test.shape)
# 查看所有列名及其类型(包括隐藏列)
print("完整列信息:", test.columns.values)
(1416, 13)
完整列信息: ['ghi' 'poai' 'sp' 't2m' 'tcc' 'tp' 'u100' 'v100' 'wind_speed' 'h' 'ghi/poai' 'ghi_poai' 'wind_speed/sp']
4.模型训练与验证
这里我采用了Task2的融合的代码,直接运行发现报错,原因是train和test维度不匹配,于是添加了cols = [f for f in train.columns if f not in ['power']],去掉了训练数据的power维度
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error
import lightgbm as lgbdef cv_model(clf, train_x, train_y, test_x, clf_name, seed = 2023):'''clf:调用模型train_x:训练数据train_y:训练数据对应标签test_x:测试数据clf_name:选择使用模型名seed:随机种子'''folds = 5kf = KFold(n_splits=folds, shuffle=True, random_state=seed)oof = np.zeros(train_x.shape[0])test_predict = np.zeros(test_x.shape[0])cv_scores = []for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):print('************************************ {} ************************************'.format(str(i+1)))trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]# 定义回调函数callbacks = [early_stopping(stopping_rounds=100), # 早停log_evaluation(period=200) # 替代verbose_eval]if clf_name == "lgb":train_matrix = clf.Dataset(trn_x, label=trn_y)valid_matrix = clf.Dataset(val_x, label=val_y)params = {'boosting_type': 'gbdt','objective': 'regression','metric': 'mae','min_child_weight': 6,'num_leaves': 2 ** 6,'lambda_l2': 10,'feature_fraction': 0.8,'bagging_fraction': 0.8,'bagging_freq': 4,'learning_rate': 0.1,'seed': 2023,'nthread' : 16,'verbose' : -1,}model = clf.train(params, train_matrix, 2000, valid_sets=[train_matrix, valid_matrix],callbacks=callbacks)val_pred = model.predict(val_x, num_iteration=model.best_iteration)test_pred = model.predict(test_x, num_iteration=model.best_iteration)if clf_name == "xgb":xgb_params = {'booster': 'gbtree', 'objective': 'reg:squarederror','eval_metric': 'mae','max_depth': 5,'lambda': 10,'subsample': 0.7,'colsample_bytree': 0.7,'colsample_bylevel': 0.7,'eta': 0.1,'tree_method': 'hist','seed': 520,'nthread': 16}train_matrix = clf.DMatrix(trn_x , label=trn_y)valid_matrix = clf.DMatrix(val_x , label=val_y)test_matrix = clf.DMatrix(test_x)watchlist = [(train_matrix, 'train'),(valid_matrix, 'eval')]model = clf.train(xgb_params, train_matrix, num_boost_round=2000, evals=watchlist, verbose_eval=200, early_stopping_rounds=100)val_pred = model.predict(valid_matrix)test_pred = model.predict(test_matrix)if clf_name == "cat":params = {'learning_rate': 0.1, 'depth': 5, 'bootstrap_type':'Bernoulli','random_seed':2023,'od_type': 'Iter', 'od_wait': 100, 'random_seed': 11, 'allow_writing_files': False}model = clf(iterations=2000, **params)model.fit(trn_x, trn_y, eval_set=(val_x, val_y),metric_period=200,use_best_model=True, cat_features=[],verbose=1)val_pred = model.predict(val_x)test_pred = model.predict(test_x)oof[valid_index] = val_predtest_predict += test_pred / kf.n_splitsscore = mean_absolute_error(val_y, val_pred)cv_scores.append(score)print(cv_scores)return oof, test_predictcols = [f for f in train.columns if f not in ['power']]# 选择lightgbm模型
lgb_oof, lgb_test = cv_model(lgb, train[cols], train["power"], test, 'lgb')
# 选择xgboost模型
xgb_oof, xgb_test = cv_model(xgb, train[cols], train["power"], test, 'xgb')
# 选择catboost模型
cat_oof, cat_test = cv_model(CatBoostRegressor, train[cols], train["power"], test, 'cat')# 进行取平均融合
final_test = (lgb_test + xgb_test + cat_test) / 3
5. 结果输出
output = pd.read_csv("data/output/output1.csv").reset_index(drop=True)final_test = [item for item in final_test for _ in range(4)]
# 添加预测结果
output["power"] = final_test
# 重命名时间列
output.rename(columns={'Unnamed: 0': ''}, inplace=True)
# 将索引设置为时间列
output.set_index(output.iloc[:, 0], inplace=True)
# 删掉数据中名为 0 的列
output = output.drop(columns=["0", ""])
# 存储数据
output.to_csv('output/output1.csv')
结果输出,由于只使用了一个场站的一个源数据,所以输出也只有一个场站的数据,为了获取所有的场站的数据及结果可以外套一个循环,将10个场站的的数据以同样的流程进行处理得到10个CSV输出结果,此外可以考虑对三个气象源的数据进行分析做进一步优化。