大数据应用开发——大数据平台集群部署(三)
前言
大数据应用开发——大数据平台集群部署
安装虚拟机
集群基础设置
在集群上安装jdk和hadoop
大数据应用开发——实时数据采集
大数据应用开发——实时数据处理
Flink完成Kafka中的数据消费,将数据分发至Kafka的dwd层中
并在HBase中进行备份
大数据应用开发——数据可视化
目录
在集群上安装jdk和hadoop
在三个节点创建/opt/module目录
在master节点安装jdk
配置jdk的环境变量
将jdk安装到slave1和slave2
在slave1和slave2上source /etc/profile和java -version,检查是否安装jdk成功
安装Hadoop分布式
解压Hadoop的压缩包
配置Hadoop的环境变量并生效
进入到hadoop的配置文件路径,配置Hadoop的配置文件
配置hadoop-env.sh
配置core-site.xml
配置hdfs-site.xml
配置mapred-site.xml
配置yarn-site.xml
配置workers文件
将hadoop从master节点拷贝到save1和slave2,记得source
格式化NAMENODE,启动Hadoop集群
启动Hadoop集群
测试HDFS和YARN是否能正常运行
在集群上安装jdk和hadoop
| master | slave1 | slave2 | |
|---|---|---|---|
| HDFS | namenode | secondarynamenode | |
| datanode | datanode | datanode | |
| YARN | resourcemannager | ||
| nodemanager | nodemanager | nodemanager |
在三个节点创建/opt/module目录
[root@master ~]# mkdir /opt/module/
[root@master ~]# scp -r /opt/module slave1:/opt/
[root@master ~]# scp -r /opt/module slave2:/opt/在master节点安装jdk
[root@master ~]# tar -zxvf /opt/software/jdk-8u212-linux-x64.tar.gz -C /opt/module/配置jdk的环境变量
[root@master jdk1.8.0_212]# vi /etc/profile.d/my-env.sh# 配置内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/binsource使配置文件生效,并且查看jdk版本是否正确
[root@master jdk1.8.0_212]# source /etc/profile
[root@master jdk1.8.0_212]# java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
[root@master jdk1.8.0_212]#将jdk安装到slave1和slave2
# 拷⻉/etc/profile.d/my-env.sh
[root@master ~]# scp /etc/profile.d/my-env.sh slave1:/etc/profile.d
[root@master ~]# scp /etc/profile.d/my-env.sh slave2:/etc/profile.d
# 拷⻉jdk
[root@master ~]# scp -r /opt/module/jdk1.8.0_212/ slave1:/opt/module/
[root@master ~]# scp -r /opt/module/jdk1.8.0_212/ slave2:/opt/module/在slave1和slave2上source /etc/profile和java -version,检查是否安装jdk成功
slave1
[root@slave1 ~]# source /etc/profile
[root@slave1 ~]# java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
[root@slave1 ~]#slave2
[root@slave2 ~]# source /etc/profile
[root@slave2 ~]# java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
[root@slave2 ~]#安装Hadoop分布式
解压Hadoop的压缩包
[root@master softwares]# tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/配置Hadoop的环境变量并生效
[root@master hadoop-3.1.3]# vi /etc/profile.d/my-env.sh# 添加内容
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin# 使环境变量⽣效
[root@master hadoop-3.1.3]# source /etc/profile验证hadoop
[root@master hadoop-3.1.3]# hadoop version进入到hadoop的配置文件路径,配置Hadoop的配置文件
[root@master hadoop]# cd $HADOOP_HOME/etc/hadoop/配置hadoop-env.sh
[root@master hadoop]# vi hadoop-env.sh# 添加内容
export JAVA_HOME=/opt/module/jdk1.8.0_212
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root配置core-site.xml
[root@master hadoop]# vi core-site.xml<configuration>
<!-- 指定NameNode的地址 -->
<property><name>fs.defaultFS</name><value>hdfs://master:8020</value>
</property>
<!-- 指定hadoop数据的存储⽬录 -->
<property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS⽹⻚登录使⽤的静态⽤⼾ root -->
<property><name>hadoop.http.staticuser.user</name><value>root</value>
</property>
<!-- 配置root(superUser)允许通过代理访问主机节点 -->
<property><name>hadoop.proxyuser.root.hosts</name><value>*</value>
</property>
<!-- 配置root(superUser)允许代理⽤⼾所属组 -->
<property><name>hadoop.proxyuser.root.groups</name><value>*</value>
</property>
<!-- 配置root(superUser)允许通过代理的⽤⼾ -->
<property><name>hadoop.proxyuser.root.users</name><value>*</value>
</property>
</configuration>配置hdfs-site.xml
[root@master hadoop]# vi hdfs-site.xml<configuration>
<!-- nn web端访问地址 -->
<property><name>dfs.namenode.http-address</name><value>master:9870</value>
</property>
<!-- 2nn web端访问地址 -->
<property><name>dfs.namenode.secondary.http-address</name><value>slave2:9868</value>
</property>
<!-- 指定集群环境HDFS副本的数量 -->
<property><name>dfs.replication</name><value>1</value>
</property>
</configuration>配置mapred-site.xml
[root@master hadoop]# vi mapred-site.xml<configuration>
<!-- 指定MapReduce程序在Yarn上运⾏ -->
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
<!-- 配置历史服务器端地址 -->
<property><name>mapreduce.jobhistory.address</name><value>master:10020</value>
</property>
<!-- 配置历史服务器Web端地址 -->
<property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value>
</property>
</configuration>配置yarn-site.xml
[root@master hadoop]# vi yarn-site.xml<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定MR⾛shuffle -->
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址 -->
<property><name>yarn.resourcemanager.hostname</name><value>slave1</value>
</property>
<!-- 环境变量的继承 -->
<property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOMEHADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn单个容器允许分配的最⼤内存⼤⼩ -->
<property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value>
</property>
<property><name>yarn.scheduler.maximum-allocation-mb</name><value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value>
</property>
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property>
</configuration>配置workers文件
[root@master hadoop]# vi workersmaster
slave1
slave2将hadoop从master节点拷贝到save1和slave2,记得source
[root@master hadoop]# scp -r /opt/module/hadoop-3.1.3/ slave1:/opt/module/
[root@master hadoop]# scp -r /opt/module/hadoop-3.1.3/ slave2:/opt/module/
[root@master hadoop]# scp /etc/profile.d/my-env.sh slave1:/etc/profile.d
[root@master hadoop]# scp /etc/profile.d/my-env.sh slave2:/etc/profile.d格式化NAMENODE,启动Hadoop集群
[root@master hadoop]# hdfs namenode -format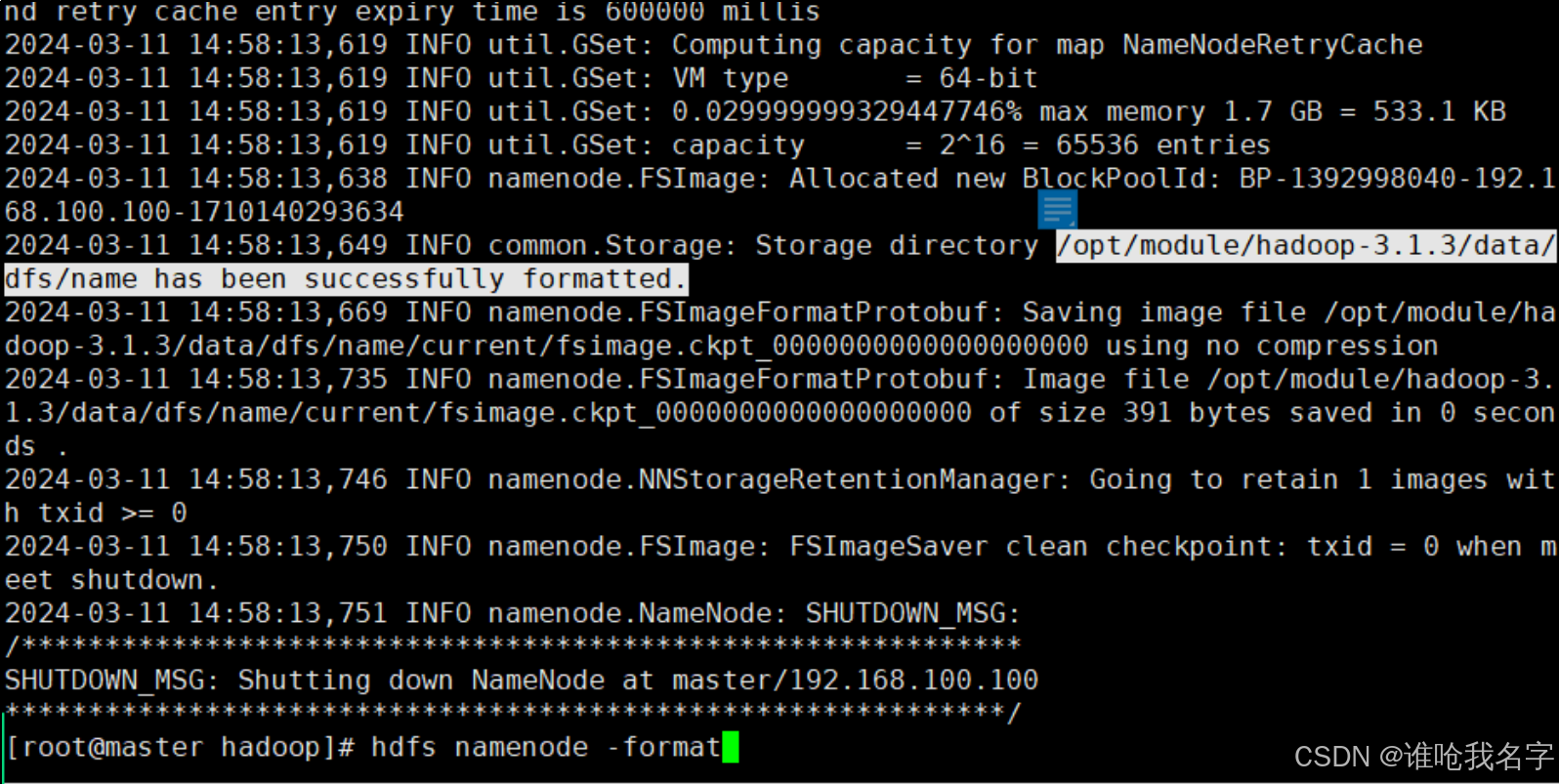
启动Hadoop集群
master
[root@master hadoop-3.1.3]# start-dfs.shslave1
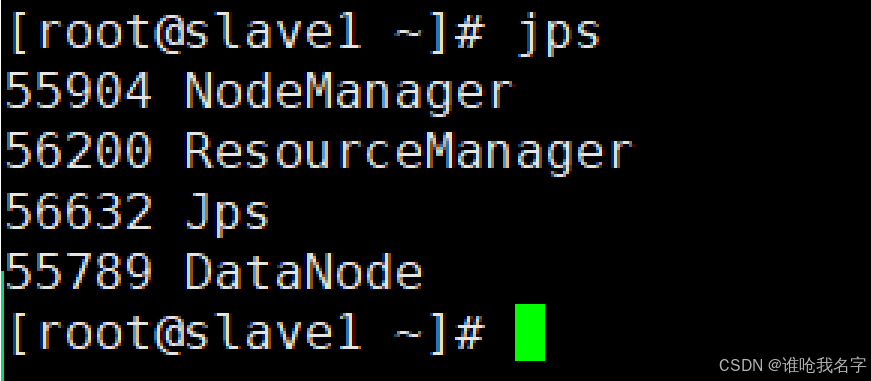
[root@slave1 hadoop-3.1.3]# start-yarn.sh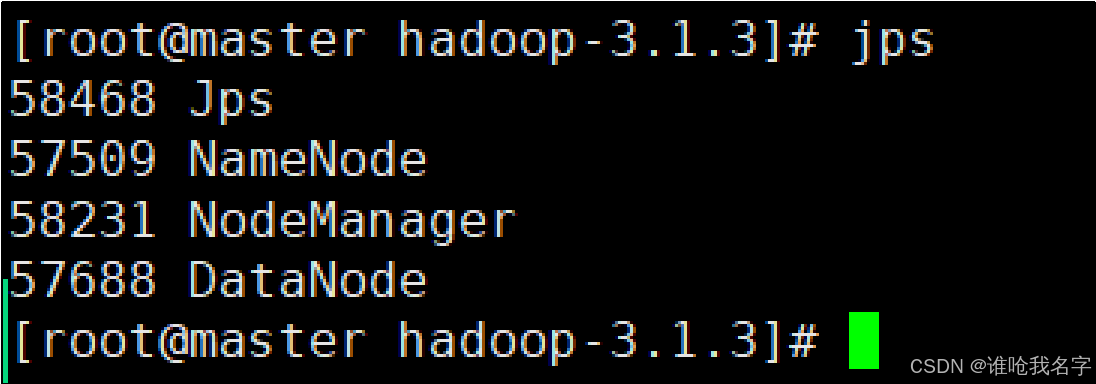
测试HDFS和YARN是否能正常运行
在master节点的/home目录中创建hello.txt⽤于在集群运行wordcount
[root@master opt # cd /home
[root@master home]# vi hello.txt将hello.txt上传到hdfs的/input/目录
[root@master home]# hdfs dfs -mkdir /input/
[root@master home]# hdfs dfs -put hello.txt /input/
2024-03-11 15:09:24,565 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
[root@master home]# hdfs dfs -ls /input/
Found 1 items
-rw-r - r - 1 root supergroup 36 2024-03-11 15:09 /input/hello.txt
[root@master home]#运行hadoop自带的wordcount的jar包,测试yarn的运行情况
[root@master home]# cd $HADOOP_HOME/share/hadoop/mapreduce/
[root@master mapreduce # yarn jar hadoop-mapreduce-examples-3.1.3.jar wordcount /input/hello.txt /output/查看下输出结果
[root@master mapreduce]# hdfs dfs -cat /output/par*
2024-03-11 15:13:56,403 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
hadoop 1
hdfs 1
hello 3
java 1
[root@master mapreduce]#