产品研发的两种模式深度解析
在产品研发过程中,自顶向下(Top-Down)和自底向上(Bottom-Up)是两种经典的策略,分别适用于不同的场景和需求。以下从定义、特点、适用场景及优缺点等方面展开分析:
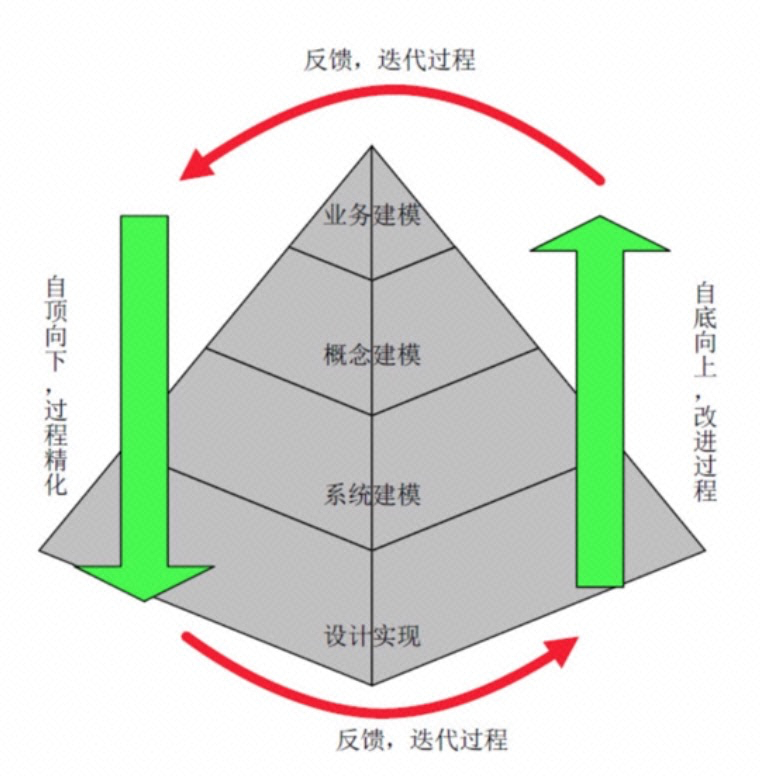
一、自顶向下模式(战略聚焦):规划、分解、牵引
1. 定义与核心逻辑
- 自顶向下是一种战略驱动的研发模式,强调从整体目标出发,通过层级分解将愿景转化为可执行的计划。
- 核心步骤:
- 明确目标:定义产品的战略定位、市场定位及核心价值(如“解决用户X场景下的Y问题”)。
- 功能规划:将目标拆解为功能模块(如“用户注册-商品浏览-支付结算”)。
- 任务分配:按模块分配资源,设定优先级(如MVP版本仅保留核心功能)。
- 牵引执行:通过里程碑(如原型验收、内测发布)推动团队按计划推进。
2. 适用场景
- 产品初期:需要快速验证市场,抢占先机(如“先上线基础功能,再迭代优化”)。
- 复杂系统:涉及多团队协作(如操作系统、企业级软件)。
- 资源有限:需聚焦核心功能,避免过度开发(如初创公司资金紧张时)。
3. 典型案例
- 特斯拉Model 3:先设计整体架构(电池技术、自动驾驶),再分解为零部件开发,最终通过供应链整合实现量产。
- 微信:早期以“熟人社交”为核心,逐步扩展至支付、小程序等生态,均围绕“连接一切”的目标展开。
4. 优缺点
| 优点 | 缺点 |
|---|
| 目标清晰,减少资源浪费 | 灵活性差,可能忽视用户实际需求 |
| 便于跨团队协作,效率高 | 依赖前期规划,若需求变化需返工 |
| 快速验证市场,降低风险 | 过度依赖高层决策,可能脱离一线 |
二、自底向上模式(敏捷迭代):堆叠、聚合
1. 定义与核心逻辑
- 自底向上是一种需求驱动的研发模式,强调从用户痛点或技术可行性出发,通过局部优化逐步形成完整产品。
- 核心步骤:
- 发现需求:通过用户反馈、数据分析找到高频痛点(如“支付流程繁琐”)。
- 快速迭代:针对痛点开发小功能(如“一键支付”),快速上线验证。
- 聚合扩展:将多个小功能整合为模块(如“支付+优惠券+分期”),最终形成完整解决方案。
2. 适用场景
- 用户需求明确:已有大量用户反馈或数据支撑(如电商平台的“收藏夹”功能)。
- 技术成熟度高:可复用现有组件(如开源框架、第三方API)。
- 敏捷开发:需快速响应市场变化(如短视频平台的“特效滤镜”更新)。
3. 典型案例
- 抖音:从“音乐短视频”这一细分需求出发,逐步聚合滤镜、特效、直播等功能,形成泛娱乐生态。
- Slack:最初是游戏公司的内部沟通工具,因用户反馈需求强烈,逐步开放为团队协作平台。
4. 优缺点
| 优点 | 缺点 |
|---|
| 贴近用户,需求匹配度高 | 缺乏整体规划,可能导致功能冗余 |
| 灵活性强,快速试错 | 跨团队协作困难,效率可能较低 |
| 降低前期投入风险 | 长期目标模糊,可能偏离战略方向 |
三、两种模式的对比与选择建议
1. 对比维度
| 维度 | 自顶向下 | 自底向上 |
|---|
| 驱动因素 | 战略目标、市场定位 | 用户需求、技术可行性 |
| 核心能力 | 规划能力、资源整合 | 用户洞察、快速迭代 |
| 风险点 | 需求变化导致返工 | 功能分散、缺乏协同 |
| 成功关键 | 高层决策准确、执行力强 | 用户反馈及时、数据驱动 |
2. 选择建议
- 优先自顶向下:
- 产品处于0-1阶段,需快速验证商业模式。
- 涉及跨团队协作或复杂技术架构。
- 需抢占市场先机(如互联网巨头入局新赛道)。
- 优先自底向上:
- 产品处于1-N阶段,用户需求明确。
- 依赖技术驱动(如AI、区块链等创新领域)。
- 需快速试错(如初创公司探索细分市场)。
3. 混合模式
- 理想状态:两种模式结合(如“战略聚焦+敏捷迭代”)。
- 案例:小米早期通过“用户参与”(自底向上)收集需求,同时坚持“高性价比”(自顶向下)战略定位,最终实现生态化布局。
四、总结
- 自顶向下适合资源集中、目标明确的场景,强调“做正确的事”。
- 自底向上适合需求驱动、快速迭代的场景,强调“把事做正确”。
- 最终目标:在战略与需求之间找到平衡,通过用户价值和商业价值的双重验证实现产品成功。