四、Hive DDL表定义、数据类型、SerDe 与分隔符核心
在理解了 Hive 数据库的基本操作后,本篇笔记将深入到数据存储的核心单元——表 (Table) 的定义和管理。掌握如何创建表、选择合适的数据类型、以及配置数据的读写方式 (特别是 SerDe 和分隔符),是高效使用 Hive 的关键。
一、创建表 (CREATE TABLE):定义数据的容器 🏗️
创建表是最核心的 DDL 操作之一,它告诉 Hive 你的数据将以什么样的结构存储和解析。
1. 基本创建表语法
核心结构:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [database_name.]table_name (
col_name1 data_type1 [COMMENT '列1的注释'],
col_name2 data_type2 [COMMENT '列2的注释'],
...
)
[COMMENT '表的注释']
[ROW FORMAT row_format_specification]
[STORED AS file_format]
[LOCATION hdfs_path];
关键组成部分详解:
EXTERNAL: 可选关键字。区分内部表和外部表 (后面后续会深入讲解其区别)。IF NOT EXISTS: 可选。避免表已存在时报错。[database_name.]table_name: 表名。可指定数据库,若不指定则使用当前USE的数据库。(col_name data_type [COMMENT '...'], ...): 列定义列表,表结构的核心。COMMENT 'table_comment': 可选,表注释。ROW FORMAT row_format_specification: 定义行数据解析方式,特别是文本文件中的字段分隔。STORED AS file_format: 指定数据在 HDFS 上的物理存储格式 (如 TEXTFILE, ORC, PARQUET)。LOCATION 'hdfs_path': 对于外部表是必需的;对于内部表是可选的。
二、Hive 数据类型:为你的数据量体裁衣 📏
Hive 支持多种数据类型。
1. 基本数据类型 (Primitive Types)
| 类型 (Type) | 描述 (Description) |
|---|---|
TINYINT | 1字节有符号整数 |
SMALLINT | 2字节有符号整数 |
INT / INTEGER | 4字节有符号整数 |
BIGINT | 8字节有符号整数 |
FLOAT | 4字节单精度浮点数 |
DOUBLE | 8字节双精度浮点数 |
DECIMAL(p, s) | 高精度定点数 (p总位数, s小数位) |
BOOLEAN | TRUE 或 FALSE |
STRING | 可变长度字符序列 (推荐使用) |
VARCHAR(len) | 可变长度字符串 (指定最大长度) |
CHAR(len) | 固定长度字符串 |
DATE | 日期 (YYYY-MM-DD) |
TIMESTAMP | 时间戳 (YYYY-MM-DD HH:MM:SS.ns) |
BINARY | 字节数组 |
基本数据类型建表案例与示例数据:
假设我们有一个文本文件 employees.txt,内容如下,以逗号分隔:
1,Alice,30,55000.75,2022-08-15,true
2,Bob,25,62000.50,2021-03-10,false
对应的建表示例:
CREATE TABLE employees (
id INT,
name STRING,
age SMALLINT,
salary DOUBLE,
hire_date DATE,
is_manager BOOLEAN
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
2. 复杂数据类型 (Complex Types)
| 类型 (Type) | 描述 (Description) |
|---|---|
ARRAY<data_type> | 有序元素集合,所有元素的数据类型必须相同 |
MAP<primitive_type, data_type> | 无序键值对集合,键必须为基本数据类型,值可以是任意 Hive 数据类型 |
STRUCT<col_name:data_type, ...> | 命名字段的集合,每个字段可以有不同的数据类型,类似记录或对象 |
UNIONTYPE<data_type, data_type, ...> | 表示一个值可以是其定义的多种数据类型之一,类似 C/C++ 中的联合体 |
复杂数据类型建表案例与示例数据:
假设我们有一个文本文件 jay_chou_music_3sep.txt,内容如下,字段以 逗号 (,) 分隔,歌曲列表 (数组) 的元素以及获奖信息 (Map) 的条目均以 管道符 (|) 分隔,Map 内的键值对以 冒号 ( : ) 分隔:
七里香,2004,稻香|夜曲|晴天,最佳国语专辑:2005|最佳年度歌曲:2005(七里香)
范特西,2001,双截棍|简单爱|安静,金曲奖最佳专辑:2002|中华音乐人年度推荐专辑:2002
叶惠美,2003,以父之名|东风破|她的睫毛,HITO流行音乐奖年度十大华语歌曲:2004(东风破)|全球华语歌曲排行榜最佳专辑:2003
依然范特西,2006,听妈妈的话|千里之外|菊花台,IFPI香港唱片销量大奖十大销量国语唱片:2006
对应的建表示例:
CREATE TABLE IF NOT EXISTS jay_chou_albums_3sep (album_title STRING COMMENT '专辑名称',release_year INT COMMENT '发行年份',track_names ARRAY<STRING> COMMENT '歌曲名称列表',awards MAP<STRING,STRING> COMMENT '获奖信息 (奖项名称, 获奖年份/描述)'
)
COMMENT '周杰伦专辑信息表'
ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','COLLECTION ITEMS TERMINATED BY '|'MAP KEYS TERMINATED BY ':';
3. 数据类型转换 (Casting)
Hive 允许通过 CAST 函数显式转换数据类型。
语法: CAST(expression AS new_data_type)
示例:
SELECT CAST('456' AS INT) + 100;
三、数据的读写、SerDe 与分隔符:Hive 如何解析你的文件 📄✂️
当 Hive 读取或写入数据到 HDFS 时,它需要知道如何解释这些文件的内容。
1. ROW FORMAT - 定义行内结构与分隔符
ROW FORMAT DELIMITED: 声明行数据是使用分隔符来区分字段的。
FIELDS TERMINATED BY 'delimiter_char': 定义列间分隔符 (如'\t',',','|')。COLLECTION ITEMS TERMINATED BY 'char': 定义ARRAY或MAP中元素间分隔符。MAP KEYS TERMINATED BY 'char': 定义MAP中键值间分隔符。NULL DEFINED AS 'null_representation': 定义文本中何为 NULL (默认'\N')。
2. SerDe (Serializer/Deserializer) - 数据的翻译官
对于更复杂的数据格式 (如 JSON, Avro),Hive 依赖于 SerDe。
- 什么是 SerDe?
SerDe 是 Serializer (序列化器) 和 Deserializer (反序列化器) 的缩写,负责 Hive 内部对象与文件字节流之间的转换。
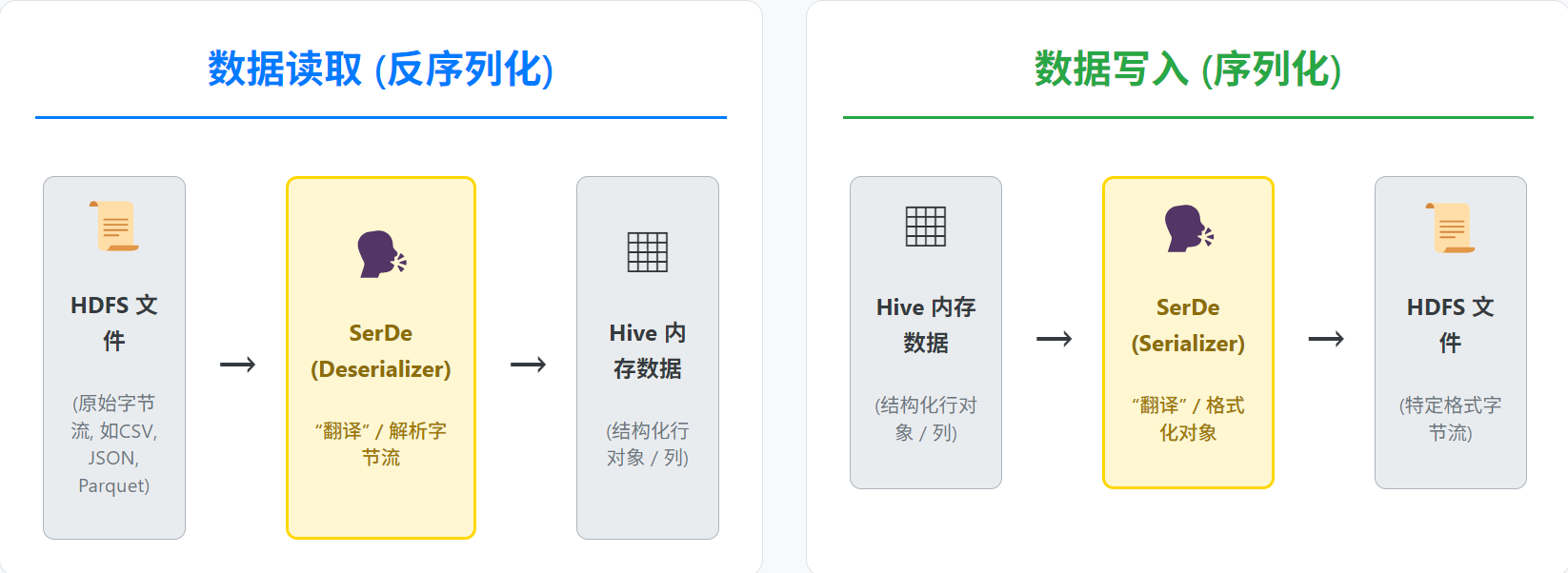
- 如何指定 SerDe?
通过ROW FORMAT SERDE 'serde_class_name'子句,并可选地通过WITH SERDEPROPERTIES (...)传递参数。 - 内置 SerDe 示例:
org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe: 文本文件 (TEXTFILE) 默认使用。org.apache.hive.hcatalog.data.JsonSerDe: 用于读写 JSON 格式的数据。
- SerDe 与分隔符的关系:
对于 TEXTFILE,LazySimpleSerDe会使用你在ROW FORMAT DELIMITED中定义的分隔符。对于 JSON、ORC、Parquet 等,SerDe 有其自己的内部解析逻辑。
SerDe 使用示例 (JSON 数据):
假设我们有一个 JSON 文件 products.json,每行是一个 JSON 对象:
{"id": 1, "name": "Laptop", "price": 1200.00, "tags": ["electronics", "computer"]}
{"id": 2, "name": "Mouse", "price": 25.50, "tags": ["electronics", "accessory"]}
对应的建表示例:
CREATE TABLE products_json (
id INT,
name STRING,
price DOUBLE,
tags ARRAY<STRING>
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE;
四、练习一下吧!✏️
- 练习题 1: 在当前数据库下,创建一个名为
device_status的表。该表包含device_id(STRING),status_code(INT),last_seen(TIMESTAMP),battery_level(FLOAT,表示百分比,如0.85),以及location_info(STRUCT 包含latitude:DOUBLE,longitude:DOUBLE)。字段之间使用逗号分隔。 - 练习题 2: 为
device_status表中的battery_level列添加注释 “设备当前电量百分比”。 - 练习题 3: 创建一个名为
product_catalog的表,包含product_id(BIGINT),product_name(STRING),category(STRING),tags(ARRAY),price(DECIMAL(10,2))。字段使用|分隔,数组tags中的元素使用#分隔。 - 练习题 4: 假设你有一个数据文件,其中 NULL 值用字符串 “NA” 表示。创建一个名为
sensor_readings的表,包含sensor_id(STRING) 和reading_value(DOUBLE)。字段用制表符分隔。配置 Hive 将 “NA” 解析为 NULL。 - 练习题 5: 创建一个名为
clickstream_json的表,用于存储如下格式的 JSON 数据(每行一个JSON对象):{"session": "s1", "user": "u100", "action": "view_page", "page_details": {"url": "/home", "title": "Homepage"}}。表结构应包含session_id(STRING),user_id(STRING),action_type(STRING),page_info(STRUCT 包含url_path:STRING,page_title:STRING)。使用 JSON SerDe。
五、练习题答案 ✅
- 答案 1:
CREATE TABLE device_status (
device_id STRING,
status_code INT,
last_seen TIMESTAMP,
battery_level FLOAT,
location_info STRUCT<latitude:DOUBLE, longitude:DOUBLE>
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
- 答案 2: (假设表已创建,修改列注释)
ALTER TABLE device_status CHANGE COLUMN battery_level battery_level FLOAT COMMENT '设备当前电量百分比';
- 答案 3:
CREATE TABLE product_catalog (
product_id BIGINT,
product_name STRING,
category STRING,
tags ARRAY<STRING>,
price DECIMAL(10,2)
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
COLLECTION ITEMS TERMINATED BY '#';
- 答案 4:
CREATE TABLE sensor_readings (
sensor_id STRING,
reading_value DOUBLE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
NULL DEFINED AS 'NA';
- 答案 5:
CREATE TABLE clickstream_json (
session_id STRING,
user_id STRING,
action_type STRING,
page_info STRUCT<url_path:STRING, page_title:STRING>
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE; -- 或其他适合存储JSON文本的格式