waterfall与Bidding的请求机制

大家好,我是大明同学。
这期内容主要介绍针对waterfall、bidding、以及waterfall & Bidding共存情况下的处理逻辑
一、waterfall
是基于广告联盟 广告位ID 按照一定规则(价格/经验)排序,由上致下请求,存在的逻辑很多种。
1. 纯串行
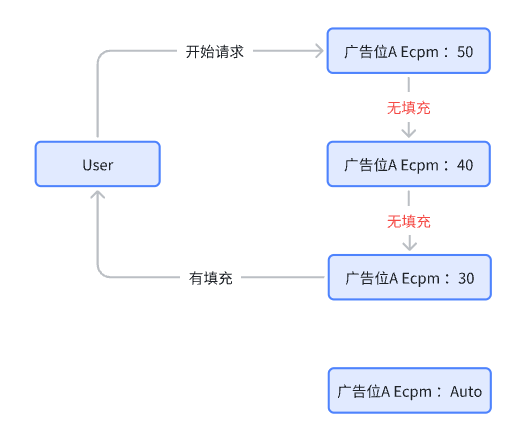
纯串行一种从上至下依次请求的逻辑,直到请求到广告为止。
优点:请求逻辑简单,保证每次请求均最大概率获取高填充
缺点:请求效率低,未区分用户;
请求逻辑简单,因为从上至下请求,所以基于瀑布流每次请求都能保证最大概率请求到高填充。
但该方式存在不小的弊端,大多数联盟对于其代码位ID的数量无限制,导致不少开发者用 ID 量级打造伪Bidding,用来换取收益。例如出现瀑布流下存在50多层甚至更多代码位ID,导致请求效率低下,常会出现因未及时拉到缓存而浪费广告展示时机;
因此,如何基于瀑布流有效及时拉到缓存是关键!!
2. 串并行
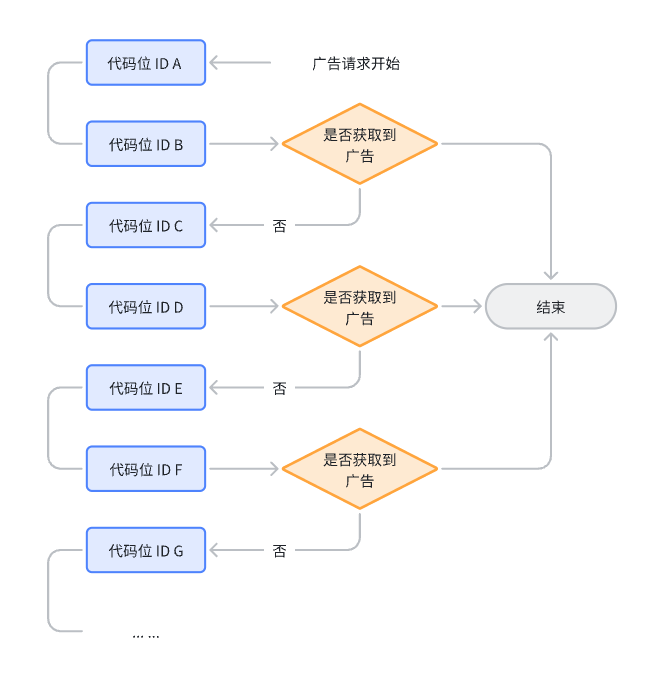
与纯串行的逻辑不同,在此基础上,由串行每次请求一层代码位ID变更成每次请求多层代码位ID,直到请求到广告为止;
例如串并行设置为2层,请求代码位ID A&B,如果获取到广告缓存则停止,未获取到广告缓存继续请求C&D;如果获取到广告缓存则停止,未获取到广告缓存继续请求E&F。
优点:在纯串行的基础上提升了广告请求效率,极大缩短了请求耗时;缺点:存在同请求顺位的2个代码位ID 均返回广告缓存,导致次高层的代码位ID 展示率低;
该模式虽能一定程度上提高请求效率,但在瀑布流下代码位ID 超出50层以上的情况下,中低层用户仍需一定时间才能拿到缓存;另外所有高中低用户均用统一瀑布流,无法区分不同价值用户填充情况,不利于高价值用户的变现价值衡量与优化;
3. 动态价值 & 价值分组
3.1 动态价值请求
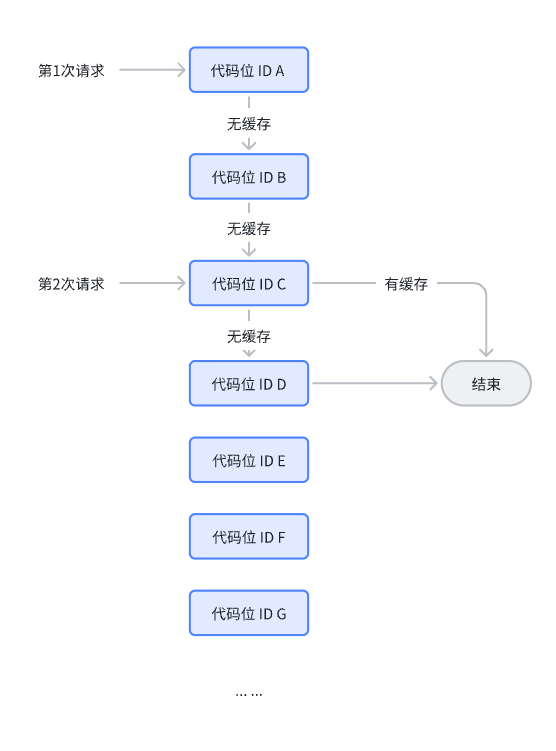
是基于用户的历史填充价值来进行缓存区分。例如初始化时由高到低请求,探索该用户的填充价值,当用户请求代码位ID A & B直至请求到C有缓存;则第二次发起请求时,根据一定机制如上浮系数 k 从某层代码位ID 开始请求。当请求系数为1时,则从代码位ID C开始请求。一般为了防止投放广告价值抖动,上浮20~50%进行后续请求。
优点:基于用户粒度,极大提升了广告填充的效率,减少了低价值用户请求干扰高价值用户请求模型的情况;缺点:当用户背后匹配的广告价值抖动时,存在损失一部分高价值填充的可能。
3.2 价值分组请求
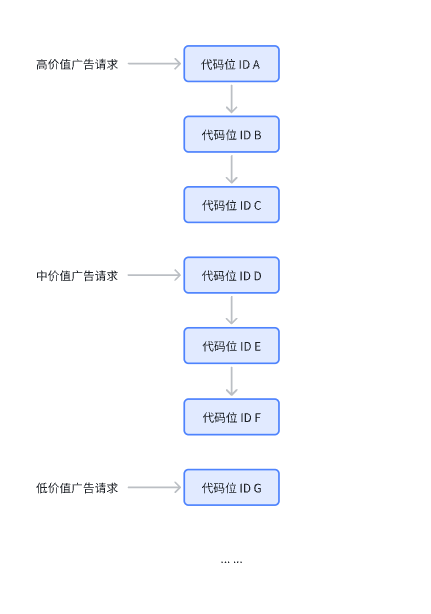
采用人工区分价值分组方式进行请求,当瀑布流请求发起时,分别请求高中低三组代码位ID。各自价值分组请求到缓存各自结束。例如高价值从A 开始直至请求C有缓存截止,中价值组请求 从D 开始直至请求F有缓存截止;展示时从高到低依次检查,优先展示高价值缓存。但该方式下分组步长,需依次加大,例如高价值组3层代码位,中价值组5层代码位ID,低价值组8层代码位ID...主要目的是防止用户频繁展示时因高中价值组未及时填充,出现低价值缓存抢量的情况。
优点:基于价值分组,同样极大提升请求效率,在请求时机有保证的前提下,能够有效保证每次填充均为最高价格;缺点:在用户频繁展示时,可能存在低价值缓存抢量情况;
4. 缓存池
也有一些部分开发者在请求时进行了多个瀑布流缓存区分,在发起广告机会时,同时请求瀑布流 A 与高价值代码位 瀑布流B,当进行展示时,比对两个瀑布流的缓存价值进行展示。与以上价值分组机制类似,本质是分部分请求,以同时请求的量级缩短请求耗时;
优点:提升请求效率,在请求时机有保证的前提下,能够有效保证每次填充均为最高价格;缺点:在用户频繁展示时,可能存在低价值缓存抢量情况;同时需要基于瀑布流请求机制二次开发;
二、waterfall & Bidding
串行
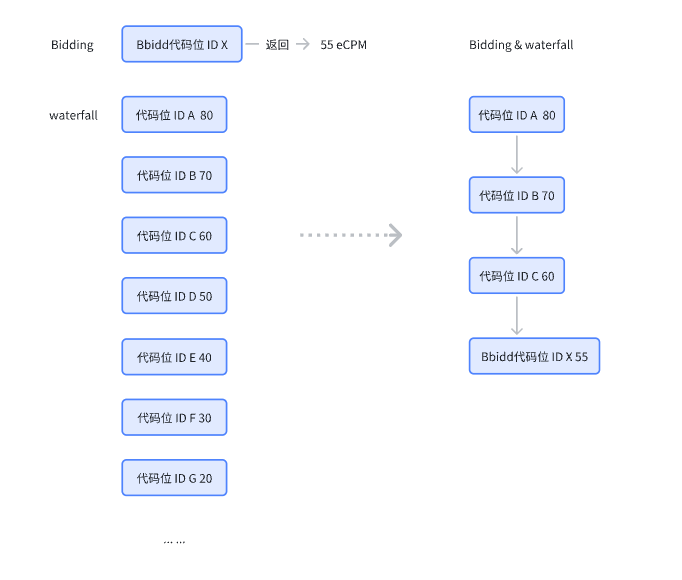
当存在广告时机,先进行多Bidder的竞价请求,进行Bidding比价返回Bidding最高价代码位ID;同时与 waterfall 历史值ecpm比价再获取到最新的waterfall&Bidding排序;
注意事项:因为部分联盟普通代码位实际价格与设定的底价有差入,建议利用三方实际产出的ecpm进行waterfall与Bidding价格比对!!!!
优点:利用Bidding进行动态兜底,减少部分代码位ID请求层级;缺点:串行请求会增加些许请求时长,需进行超时设置;
并行
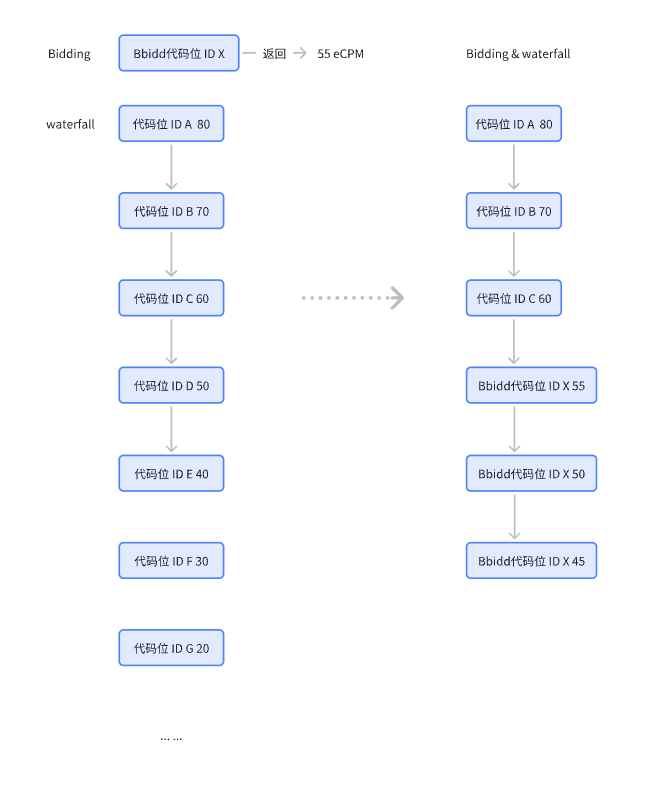
当存在广告时机,同时进行多Bidder的竞价请求与waterfall请求,Bidding比价返回Bidding最高价代码位ID,与 waterfall 历史值ecpm比价再获取到最新的waterfall&Bidding排序;
优点:同时进行广告请求,节省一部分耗时,利用Bidding进行动态兜底;缺点:存在低价值代码位ID有缓存的情况
好的,这里就结束了。
我是大明同学。
下期见。