Discriminative and domain invariant subspace alignment for visual tasks
用于视觉任务的判别性和域不变子空间对齐
作者:Samaneh Rezaei,Jafar Tahmoresnezhad
文章于2018年12月4日收到,2019年5月24日被接受,2019年6月3日在线发表于Iran Journal of Computer Science期刊,DOI: 10.1007/s42044-019-00037-y,© Springer Nature Switzerland AG 2019
摘要
迁移学习和域适应是解决训练集(源域)和测试集(目标域)分布不同问题的有效方案。在本文中,我们研究了无监督域适应问题,即目标样本没有标签,而源域样本标签完整。我们通过寻找不同的转换矩阵,将源域和目标域都转换到不相交的子空间中,使得转换空间中每个目标样本的分布与源样本相似。此外,通过非参数准则(最大平均差异,MMD)最小化转换后的源域和目标域之间的边际和条件概率差异。因此,利用类间最大化和类内最小化来区分源域中的不同类别。另外,通过样本标签保留源数据和目标数据的局部信息,包括数据的几何结构。我们通过各种视觉基准实验验证了所提方法的性能。在三个标准基准测试中,我们所提方法的平均准确率达到70.63%。与其他最先进的域适应方法相比,结果证明我们的方法性能更优,提升了22.9%。
关键词:无监督域适应;全局适应;局部适应;独特转换;最大平均差异
1 引言
机器学习(ML)算法在有标签的训练数据上训练分类模型,以对未知的测试数据进行标注。当训练数据量充足且训练数据和测试数据的分布相似时,这些算法表现出较高的性能。然而,在视觉分类任务中,由于相机位置和角度以及图像统计信息的差异,获取足够的有标签数据较为困难。这种差异在视觉应用中被称为分布差异、域转移或跨域问题。因此,用第一组图像训练的ML分类器在预测第二组图像的标签时表现不佳。
解决跨域问题的一种简单方法是手动标注样本,重新训练分类器,但在大多数情况下,这既耗费人力又成本高昂。域适应是克服跨域问题的一种新解决方案,旨在减小训练数据集和测试数据集之间的分布差异,以提高模型性能。根据目标域中是否存在有标签数据,域适应可分为半监督问题和无监督问题。在半监督问题中,目标域有少量有标签数据,而源域数据标签完整;在无监督问题中,源域数据标签完整,目标域数据则完全没有标签。在大多数实际视觉问题中,无法获取目标域的有标签数据,因此,本文重点研究无监督域适应(DA)。
DA方法遵循三种策略。基于模型的方法将基于源域模型学习到的参数适配到目标域;基于实例的方法对与目标域分布最相似的源样本重新加权;基于特征的方法则改变域的特征空间,使源域和目标域更加接近。
基于特征的方法分为数据对齐和子空间对齐两类。数据对齐方法寻找统一的投影矩阵,将源域和目标域转换到共享子空间中,以降低域间的分布差异。这些方法利用源域和目标域的共享特征,找到分布差异最小的公共子空间。另一类方法则使用共享特征和特定域特征,为每个域寻找统一的投影矩阵。
在本文中,我们提出了一种子空间对齐方法,即用于视觉域的判别性和不变子空间对齐(DISA),它在保留数据几何和统计信息的同时,对源域和目标域进行适配。DISA通过统计和几何适配,为每个域找到统一的独立子空间:(1)在统计适配中,DISA通过一种流行的非参数方法——最大平均差异(MMD),减小源域和目标域之间的边际和条件分布差异;(2)此外,利用统计信息增加不同类别之间的可分性和决策区域,减小类内距离,增大类间距离;(3)在几何适配中,DISA利用类和域流形信息提高不同类别之间的判别力。通过缩小具有局部结构和相同标签的样本之间的距离,DISA适配源域和目标域的几何分布和判别结构。
我们在32个跨域视觉分类任务上的结果表明,DISA通过同时适配几何和统计分布,优于其他最先进的域适应方法。
本文的其余部分安排如下:第2节回顾近年来发表的DA领域相关工作;第3节介绍我们提出的方法;第4节讨论实验及结果;第5节给出结论和未来工作方向。
2 相关工作
基于特征的方法作为DA的一个广泛类别,将数据的原始特征空间转换为潜在特征空间,从而减小源域和目标域之间的分布差异。在本文中,我们关注具有数据对齐和子空间对齐趋势的基于特征的方法。
视觉域适应(VDA)是一种数据对齐方法,它寻找一个共同的潜在子空间,共同减小源域和目标域之间的边际和条件分布差异。VDA使用域不变聚类来最大化类间距离,并区分不同类别。然而,VDA忽略了在潜在子空间中保留数据的几何属性。
Yong等人提出了低秩和稀疏表示(LRSR),以找到一个嵌入子空间,在该子空间中每个目标样本可以由源域样本线性重构。在LRSR中,源域或目标域中的每个样本都可以由其邻域重构。因此,当源域和目标域转换到具有相同分布的潜在子空间时,可以使用源域中的相同邻域来重构数据,而不是目标样本的邻域。通过这种方式,LRSR使用具有低秩和稀疏约束的重构矩阵和一个误差矩阵来避免负迁移。然而,LRSR并没有最小化源域和目标域之间的分布差异。紧密且可判别域适应(CDDA)寻找一个共同空间,在该空间中边际和条件概率分布差异都减小,并且类间样本相互排斥。鲁棒数据结构对齐紧密且可判别域适应(RSA - CDDA)改进了CDDA,在统一框架中使用具有低秩和稀疏约束的重构矩阵,用源域重构目标域。Liu等人提出了耦合局部 - 全局适应(CLGA),通过全局和局部适应来适应源域和目标域之间的分布转移。CLGA在全局适应中,使用MMD减小源域和目标域之间的边际和条件分布差异;在局部适应中,构建图结构,利用域的标签和流形结构。最后,将局部和全局适应表述为一个统一的优化问题。
联合几何和统计对齐(JGSA)是一种子空间对齐方法,旨在通过利用共享特征和特定域特征,为每个域找到统一的子空间。JGSA在保留源域信息的同时,减小嵌入子空间之间的边际和条件概率差异。尽管JGSA保留了源样本的信息,但在几何分布适应过程中没有使用源标签。子空间分布对齐(SDA)旨在通过主成分分析(PCA)将源域和目标域转换到各自的特征空间。PCA改变新子空间中每个维度的方差,使源域和目标域在新基上具有不同的方差。SDA使用子空间转换矩阵将源子空间映射到目标子空间,通过矩阵对齐域间分布。SDA用均值和方差描述每个分布,使均值为零并对齐源域和目标域之间的方差。当域间协变量转移较大时,SDA会失效。
在本文中,DISA作为一种基于子空间的方法,旨在将源域和目标域转换到相关的嵌入子空间中。DISA通过最小化域间的条件和边际分布差异,对两个域进行全局适配。此外,DISA通过最小化类间距离和最大化类内距离来区分不同类别。在局部适应方面,DISA保留两个域的几何信息。然后,使用在源域上训练的模型来预测目标域的标签。
3 判别性和不变子空间对齐
3.1 动机
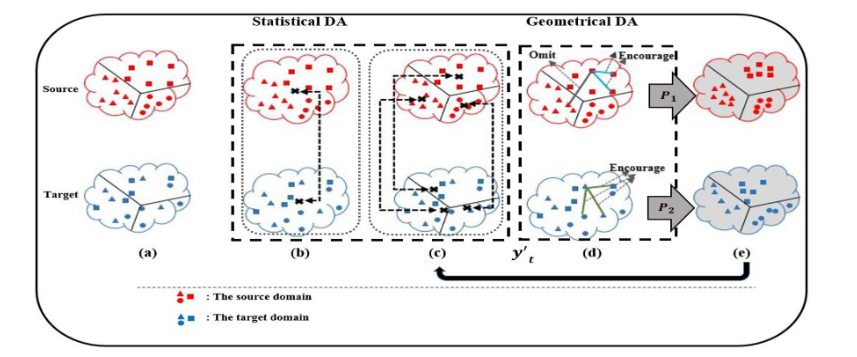
DISA的主要思想如图1所示。DISA通过保留样本的统计和几何信息,迭代地适配源域和目标域。
3.2 问题陈述
我们从域和任务的定义开始,然后阐述问题。
一个域D由两部分组成,即(D = {X, P(x)}),其中(X = {x_1, x_2, \ldots, x_{n_s}}),(x \in X),(n_s)是源样本的数量。
给定一个特定的域D,一个任务定义为(T = {Y, f(x)}),其中Y是样本的标签集,(f(x))是一个分类器,用于为样本分配标签。(f(x))可解释为每个样本的条件概率分布,即(f(x) = P(y|x)),其中(y \in Y)。我们给定一个源域(D_S = {(x_i^s, y_i^s)}{i = 1}^{n_s}),包含(n_s)个有标签的源样本,以及一个目标域(D_T = {x_i^t}{i = 1}^{n_t}),包含(n_t)个无标签的目标样本。假设源域和目标域的分布不同,具体来说(X_s = X_t),(Y_s = Y_t),(P_s(x_s) \neq P_t(x_t)),(P_s(y_s|x_s) \neq P_t(y_t|x_t))。我们的问题是为源样本和目标样本找到一个潜在特征空间,使得:(1)源域和目标域之间的边际和条件分布差异减小;(2)类间距离最大化,类内距离最小化;(3)源样本和目标样本的几何信息得以保留。
3.3 DISA
在本节中,我们介绍DISA,以找到分别用于投影源域和目标域的投影矩阵(P_1)和(P_2)。DISA在统计和几何适配中,减小源域和目标域之间的域转移。
3.3.1 (统计适配)目标重构误差最小化
我们通过最大化目标域在相应嵌入子空间中的方差,来鼓励减小映射后的目标样本的重构误差。基于PCA方法,方差最大化可表示为:
[ \max_{P_2^T P_2 = I} \text{tr}(P_2^T X_t H_t X_t^T P_2) ]
其中(H_t = I_t - \frac{1}{n_t} 1_t 1_t^T)是中心矩阵,用于保留目标样本的方差信息,(1_t \in \mathbb{R}^{n_t})是列向量全为1的向量,(X_t \in \mathbb{R}^{m \times n_t}),m是目标域的原始维度。PCA旨在找到一个投影矩阵(P_2),以最大化数据方差。
3.3.2 (统计适配)源统计判别学习
由于不同类别的源样本具有不同的结构,用源域训练的模型可能会对目标样本预测不准确的标签。为了提高预测模型的性能,我们将源样本投影到一个潜在子空间中,在该子空间中不同类别可以被区分。因此,我们根据以下关系最大化类间距离,最小化类内距离:
[ \min_{P_1} \frac{\text{tr}(P_1^T (\sum_{c = 1}^{C} n_s^c (m_s^c - \overline{m}s)(m_s^c - \overline{m}s)T))}{\text{tr}(P_1T (\sum{c = 1}^{C} X_s^c H_s^c (X_sc)T) P_1)} ]
其中(X_s^c \in \mathbb{R}^{m \times n_sc})包含源样本中属于类c的子集,(m_sc = \frac{1}{n_s^c} \sum{i = 1}{n_sc} x_ic)和(n_sc)分别是(X_s^c)中样本的均值和数量,(\overline{m}s = \frac{1}{n_s} \sum{i = 1}^{n_s} x_i)是(X_s)中源样本的均值。(H_s^c = I_s^c - \frac{1}{n_s^c} (1_sc)T)是类c中样本的中心矩阵,(I_s^c \in \mathbb{R}{n_sc \times n_sc})和(1_sc \in \mathbb{R}{n_sc})分别是单位矩阵和全1向量。
3.3.3 (统计适配)边际分布差异最小化
将源域和目标域投影到各自的子空间后,域间的边际和条件分布差异并没有减小。为了度量边际分布差异,我们使用非参数方法MMD来计算映射后的源域和目标域之间的距离。在计算源域和目标域样本均值在希尔伯特空间中的经验距离时,DISA为每个域找到两个投影(P_1)和(P_2),如下所示:
[ D_1(X_s, X_t) = \left| \frac{1}{n_s} \sum_{x_i \in X_s} P_1^T x_i - \frac{1}{n_t} \sum_{x_j \in X_t} P_2^T x_j \right|^2 ]
上述方程可改写为封闭形式:
[ D_1(X_s, X_t) = \min_{P_1, P_2} \text{tr}([P_1^T \ P_2^T] X M_0 X^T \begin{bmatrix} P_1 \ P_2 \end{bmatrix}) ]
其中(X = [X_s, X_t] \in \mathbb{R}^{m \times (n_s + n_t)}),(M_0 = \begin{bmatrix} (M_0)s & (M_0){st} \ (M_0)_{ts} & (M_0)t \end{bmatrix} \in \mathbb{R}^{(n_s + n_t) \times (n_s + n_t)})是MMD系数矩阵,((M_0)s = \frac{1}{n_s^2}),((M_0){st} = -\frac{1}{n_s n_t}),((M_0){ts} = -\frac{1}{n_t n_s}),((M_0)_t = \frac{1}{n_t^2}),(\text{tr})表示矩阵的迹。
3.3.4 (统计适配)条件分布差异最小化
减小域间的边际分布差异并不能保证源域和目标域之间的类条件分布差异也减小。我们通过计算每个类中源域和目标域之间的经验距离,来缓解域间的类条件分布差异。因此,DISA为每个域找到两个投影(P_1)和(P_2),如下所示:
[ \begin{aligned} D_2(X_s, X_t) &= \sum_{c = 1}^{C} \left| \frac{1}{n_s^c} \sum_{x_i \in X_s^c} P_1^T x_i - \frac{1}{n_t^c} \sum_{x_j \in X_t^c} P_2^T x_j \right|^2 \end{aligned} ]
其中(n_sc)和(n_tc)分别是属于类c的源样本和目标样本的数量。公式(5)可以写成封闭形式:
[ D_2(X_s, X_t) = \min_{P_1, P_2} \text{tr}([P_1^T \ P_2^T] X M_c X^T \begin{bmatrix} P_1 \ P_2 \end{bmatrix}) ]
其中(M_c = \begin{bmatrix} (M_c)s & (M_c){st} \ (M_c)_{ts} & (M_c)_t \end{bmatrix} \in \mathbb{R}^{(n_s + n_t) \times (n_s + n_t)})是MMD系数矩阵,计算方式为((M_c)s = \frac{1}{(n_sc)2}),((M_c){st} = -\frac{1}{n_s^c### 3.3.5(几何适配)通过源样本进行判别学习
样本的统计信息,即样本均值和方差,由于映射域的内在结构存在偏移,不足以最小化源域和目标域之间的域偏移。因此,DISA利用样本的局部信息进行几何分布适配。根据流形定理,几何分布相近的样本具有相同的标签。因此,DISA对跨域的几何分布进行适配。
由于源样本标签完备,DISA同时利用源样本的流形和标签结构,保留数据内在结构的信息,并提高源样本在潜在空间中的可分离性。通过这种方式,我们创建一个具有 n s n_s ns个节点的图结构,其中每个节点对应于 X s X_s Xs中的一个样本。然后,对于每个节点,我们考虑其 p p p个最近邻。如果样本对具有相同的类别和相同的流形,我们用一条带有相应权重的边连接它们。样本对 i i i和 j j j之间的权重通过 W i j = e − ∥ x i − x j ∥ 2 W_{ij}=e^{-\left\|x_{i}-x_{j}\right\|^{2}} Wij=e−∥xi−xj∥2来度量,其中 W ∈ R n s × n s W \in \mathbb{R}^{n_{s}×n_{s}} W∈Rns×ns是权重矩阵,包含每个样本对之间的欧几里得距离。 L = D − W L = D - W L=D−W是图拉普拉斯矩阵,其中 D i i = ∑ j = 1 n s W i j D_{ii}=\sum_{j = 1}^{n_{s}}W_{ij} Dii=∑j=1nsWij是一个对角矩阵。为了在嵌入空间中区分映射后的源样本,DISA找到 P 1 P_1 P1,基于流形结构最小化每个类中源样本之间的距离,如下所示:
[ \min_{P_1} \sum_{i, j = 1}{n_{s}}(P_1T x_{i} - P_1^T x_{j})W_{s_{ij}} = \min_{P_1} \text{tr}(P_1^T X_{s} L_{s} X_{s}^T P_1) ]
L s L_s Ls作为源数据的拉普拉斯矩阵,包含源样本的几何信息。因此, P 1 P_1 P1将几何分布相似的源样本映射到相关子空间中,并使它们彼此靠近。
3.3.6(几何适配)通过目标样本进行流形学习
为了保留目标样本的几何结构,DISA在目标域上构建一个具有 n t n_t nt个节点的最近邻图。由于没有目标样本的相应标签,根据流形定理,我们将每个节点与其 P P P个最近邻连接。因此,DISA通过以下方式找到 P 2 P_2 P2:
[ \min_{P_2} = \sum_{i, j = 1}{n_{t}}(P_2T x_{i} - P_2^T x_{j})W_{t_{ij}} = \min_{P_2} \text{tr}(P_2^T X_{t} L_{t} X_{t}^T P_2) ]
目标样本的拉普拉斯矩阵 L t L_t Lt包含目标数据的几何信息。实际上, P 2 P_2 P2将目标样本转换到相关的潜在子空间中,同时保留了样本的局部信息。
3.3.7(几何适配)子空间生成过程中的散度最小化
DISA通过统计和几何学习为源域和目标域找到成对的投影。为了最小化嵌入子空间中数据的散度,DISA使两个潜在子空间 P 1 P_1 P1和 P 2 P_2 P2更加接近。因此,在子空间生成过程中,域的局部和全局信息都得以保留。这一目标可表示为:
[ \min_{P_1, P_2} \left| P_1 - P_2 \right|_{F}^{2} ]
其中 ∥ ⋅ ∥ F 2 \|\cdot\|_{F}^{2} ∥⋅∥F2是弗罗贝尼乌斯范数。
3.4 优化问题
DISA通过结合公式(1)到(9)找到源投影 P 1 P_1 P1和目标投影 P 2 P_2 P2。我们基于瑞利商开发了最终模型,以对齐跨域偏移,如下所示:
[ \min_{P_1, P_2} \frac{\text{Tr}\left(P^T\left[\begin{array}{cc} \beta S_{w}+\gamma X_{s} L_{s} X_{s}^T+\lambda I & -\lambda I \ -\lambda I & \gamma X_{t} L_{t} X_{t}^T+(\lambda+\mu) I\end{array}\right] + X\left(\sum_{c = 0}^{C} M_{c}\right) XT\right)P}{\text{tr}\left(PT\left[\begin{array}{cc} \beta S_{b} & 0_{(m, m)} \ 0_{(m, m)} & \mu S_{t} \end{array}\right] P\right)} ]
其中 S w = ∑ c = 1 C n s c ( m s c − m ‾ s ) ( m s c − m ‾ s ) T S_{w}=\sum_{c = 1}^{C} n_{s}^{c}(m_{s}^{c}-\overline{m}_{s})(m_{s}^{c}-\overline{m}_{s})^T Sw=∑c=1Cnsc(msc−ms)(msc−ms)T和 S b = ∑ c = 1 C X s c H s c ( X s c ) T S_{b}=\sum_{c = 1}^{C} X_{s}^{c} H_{s}^{c}(X_{s}^{c})^T Sb=∑c=1CXscHsc(Xsc)T用于学习源域的判别信息。 ∑ c = 0 C M c \sum_{c = 0}^{C} M_{c} ∑c=0CMc在 c = 0 c = 0 c=0时计算边际分布的MMD系数矩阵,在 c = 1 c = 1 c=1到 c c c时计算条件分布模式下的MMD系数矩阵。 X = [ X s 0 ( m , n t ) 0 ( m , n s ) X t ] X=\left[\begin{array}{cc}X_{s} & 0_{(m, n_{t})} \\ 0_{(m, n_{s})} & X_{t}\end{array}\right] X=[Xs0(m,ns)0(m,nt)Xt], I ∈ R m × m I \in \mathbb{R}^{m×m} I∈Rm×m是单位矩阵。此外, S t = X t H t X t T S_{t}=X_{t} H_{t} X_{t}^T St=XtHtXtT用于寻找矩阵 P 2 P_2 P2,以最大化目标域在相关嵌入子空间中的方差。 P = [ P 1 P 2 ] ∈ R 2 m × k P=\left[\begin{array}{l}P_{1} \\ P_{2}\end{array}\right] \in \mathbb{R}^{2m×k} P=[P1P2]∈R2m×k,其中 P 1 P_1 P1和 P 2 P_2 P2由公式(10)的特征值分解给出。算法1设计用于实现DISA策略。
3.5 时间复杂度
在本节中,我们分析算法1的计算复杂度如下:对于步骤3和4,在源数据上训练分类器和预测目标样本伪标签的时间复杂度分别为 O ( m n s ) O(mn_{s}) O(mns)和 O ( m n t ) O(mn_{t}) O(mnt)。对于步骤5和6,在全局适配阶段构建边际和条件矩阵需要 O ( ( n s + n t ) 2 ) O((n_{s}+n_{t})^{2}) O((ns+nt)2)。在步骤7和8的局部适配阶段,计算源样本和目标样本的拉普拉斯矩阵分别需要 O ( ( n s ) 2 ) O((n_{s})^{2}) O((ns)2)和 O ( ( n t ) 2 ) O((n_{t})^{2}) O((nt)2)。步骤10中计算耦合变换矩阵的时间复杂度为 O ( k 3 ) O(k^{3}) O(k3),其中 k k k是潜在特征的数量。对于步骤11和12,在映射后的源样本上训练最近邻(NN)分类器和预测映射后的目标样本分别需要 O ( k n s ) O(kn_{s}) O(kns)和 O ( k n t ) O(kn_{t}) O(knt)。综上所述,DISA的计算复杂度为 O ( ( n s + n t ) 2 + k 3 ) O((n_{s}+n_{t})^{2}+k^{3}) O((ns+nt)2+k3) 。
算法1 视觉域的判别性和不变子空间对齐(DISA)
- 输入:源数据 X s X_s Xs,目标数据 X t X_t Xt,源域标签 Y s Y_s Ys,正则化参数: λ , μ , k , T , β \lambda, \mu, k, T, \beta λ,μ,k,T,β
- 输出:投影矩阵 P 1 P_1 P1和 P 2 P_2 P2,目标域标签 y t y_t yt
- 基于 ( X s , Y s ) (X_s, Y_s) (Xs,Ys)学习1-NN分类器 f f f
- 使用分类器 f f f预测目标域 ( X t ) (X_t) (Xt)中的伪标签 Y t 0 Y_{t0} Yt0
- 根据公式(4)构建 M 0 M_0 M0
- 根据公式(5)构建 M c M_c Mc
- 根据公式(7)计算 L s L_s Ls
- 根据公式(8)计算 L t L_t Lt
- 重复直至收敛:
10. 根据公式(5)更新矩阵 M c M_c Mc
11. 求解公式(10),选择 k k k个最小的特征向量作为 P 1 P_1 P1和 P 2 P_2 P2
12. 基于 ( P 1 T X s , Y s ) (P_1^T X_s, Y_s) (P1TXs,Ys)学习分类器 f f f
13. 更新 ( P 2 T X t ) (P_2^T X_t) (P2TXt)上的伪标签 Y t 0 Y_{t0} Yt0 - 结束重复
- 基于 ( P 1 T X s , Y s ) (P_1^T X_s, Y_s) (P1TXs,Ys)学习最终分类器 f ′ f' f′
- 使用 f ′ f' f′预测 X t X_t Xt的标签
- 返回由分类器 f ′ f' f′确定的目标域标签 y t y_t yt
4 实验
在本节中,我们评估所提方法与基线方法以及其他最先进的域适应方法在图像分类任务中的有效性。
4.1 基准数据集描述
Office数据集是最常用的目标识别基准数据集,由4652张真实世界图像组成,分为3个不同的域:Amazon(A:从amazon.com下载的图像)、DSLR(D:由单反相机拍摄的高分辨率图像)和Webcam(W:由网络摄像头拍摄的低分辨率图像),每个域有31个类别,包括相机、帽子、自行车、键盘、剪刀等。Caltech - 256由30607张图像组成,有256个类别。我们从四个域中选择10个常见类别,即计算器、笔记本电脑、键盘、鼠标、显示器、投影仪、耳机、背包、杯子和自行车。我们数据集的配置与文献[24]相同,从图像中提取800维的SURF特征,然后通过z - score归一化作为输入向量。最后,每两个不同的域分别作为源域和目标域,可构建12个域适应任务,即 C → A C→A C→A、 C → W C→W C→W、…、 D → W D→W D→W。CMU - PIE是一个人脸识别基准数据集,由68个人的41368张灰度图像组成,包含不同的光照和姿态。我们与文献[24]一样使用5种姿态,P1、P2、P3、P4和P5,分别对应左侧、上侧、下侧、正面和右侧姿态。由于CMU - PIE数据集包含5个域,可构建20个跨域任务,即 P 1 → P 2 P1→P2 P1→P2、 P 1 → P 3 P1→P3 P1→P3、…、 P 5 → P 4 P5→P4 P5→P4。MNIST和USPS是数字识别基准数据集,分别由2000张和1800张灰度图像组成。MNIST(M)图像收集自美国高中生和美国人口普查局员工;USPS(U)数据集由美国邮政服务信封上扫描的手写数字组成。我们与文献[24]一样使用两个数据集中的10个常见类别。由于数字识别基准数据集有两个域,可构建两个域适应任务,即 U → M U→M U→M和 M → U M→U M→U(图2)。
【此处插入原文图2:Fig. 2 The first row demonstrates the Office+Caltech - 256 dataset, and the second row demonstrates CMU - PIE and MNIST and USPS datasets, respectively (from left to right)】
4.2 实现细节
与其他最先进方法比较DISA性能时,使用的评估指标与文献[20]相同,即准确率,公式如下:
[ \text{Accuracy} =\frac{\left|x: x \in X_{t} \land f(x)=y(x)\right|}{n_{t}} ]
其中 f ( x ) f(x) f(x)是每个目标样本 x x x的预测标签, y ( x ) y(x) y(x)是其真实标签。DISA有五个参数: λ , μ , k , T , β \lambda, \mu, k, T, \beta λ,μ,k,T,β和 r r r。我们通过经验设置,对于Office + Caltech - 256数据集, λ = 0.5 \lambda = 0.5 λ=0.5, μ = 5 \mu = 5 μ=5, β = 0.1 \beta = 0.1 β=0.1;对于CMU - PIE数据集, λ = 5 \lambda = 5 λ=5, μ = 0.5 \mu = 0.5 μ=0.5, β = 0.0005 \beta = 0.0005 β=0.0005;对于数字识别数据集(Digits), λ = 1 \lambda = 1 λ=1, μ = 5 \mu = 5 μ=5, β = 0.001 \beta = 0.001 β=0.001 。Office + Caltech - 256数据集的子空间数量 k k k设置为30,数字识别数据集的 k k k设置为110。两个基准测试中,使DISA收敛的迭代次数 T T T均设置为10。
4.3 实验结果评估与讨论
DISA和其他9种对比方法(NN、JDA、SA、TJM、LRSR、VDA、CDDA、CLGA)在三个基准数据集(Office + Caltech - 256、CMU - PIE和Digits)上的性能分别如表1、表2和表3所示。每个跨域适应对的最高准确率以粗体突出显示。我们根据其他方法论文中报告的结果,将DISA与它们的最佳结果进行比较。所有方法都使用最近邻分类器在有标签的源样本上进行训练,并预测目标样本的标签。根据表1中的结果,在Office + Caltech - 256数据集上,DISA与最先进方法中表现最佳的VDA相比,平均准确率提高了3.35%,并且在12个跨域适应任务中的9个任务上优于VDA。
DISA与最近邻分类器(NN)相比,准确率提高了21.01%,这表明DISA能有效地适配不匹配的源域和目标域。
JDA和TJM将两个域映射到共享的潜在子空间中,以减小域间的边际分布差异。TJM使用 l 2 , 1 l_{2,1} l2,1范数为源样本设置权重,以便更有效地学习模型,JDA则减小条件分布差异。然而,DISA同时适配边际和条件分布差异,并在潜在子空间中保留样本的局部信息。在Office + Caltech - 256、CMU - PIE和Digits数据集上,DISA的性能分别比JDA提高了6.07%、20.71%和13.42%,比TJM提高了7.97%、45.39%和19.12%。
SA是一种基于子空间的方法,将源域和目标域映射到潜在子空间中。SA使用线性变换矩阵使映射后的源域基向量与映射后的目标域基向量对齐,但它忽略了减小分布差异,而DISA同时减小了边际和条件分布差异。在Office + Caltech - 256、CMU - PIE和Digits数据集上,DISA相对于SA的性能分别提高了7.66%、27.77%和18.6%。
虽然LRSR最小化了重构误差,但域间的分布差异仍然很大。DISA使两个域更接近,在Office + Caltech - 256、CMU - PIE和Digits数据集上,其平均准确率相对于LRSR分别提高了6.99%、17.42%和12.72%。
虽然VDA利用统计信息对域进行适配,但它忽略了保留样本的局部信息。然而,DISA同时利用样本的局部和全局信息使两个域更接近。在Office + Caltech - 256、CMU - PIE和Digits数据集上,DISA相对于VDA的平均准确率分别提高了3.35%、9.95%和7.94%。
CDDA通过统计方法对域进行适配,并区分不同类别。DISA减小了边际和条件分布差异,并进行局部域适配。在Office + Caltech - 256、CMU - PIE和Digits数据集上,DISA的平均准确率分别比CDDA高4.16%、17.85%和7.75%。
CLGA在几何和统计适配中对源域和目标域进行适配。在统计适配中,CLGA减小了域间的边际和条件分布差异;在几何适配中,CLGA利用样本的流形和标签信息对两个域进行适配。然而,DISA在统计层面上对两个域进行适配,并利用源域的标签和流形信息进行局部适配。在Office + Caltech - 256数据集上,DISA的性能提高了4.15%,在CMU - PIE和Digits数据集上,相对于CLGA的性能分别提高了8.80%和12.08%。
基于图3a和图3b,与Office + Caltech - 256数据集上表现最佳的VDA相比,DISA在12个问题中的9个上表现更优。DISA在所有12个实验中均优于NN和JDA(基线方法)。图3c和图3d表明,与CMU - PIE数据集上表现最佳的CLGA相比,DISA在20个问题中的20个上表现更优。图3e显示,DISA在所有情况下均优于其他所有最先进的方法。
【此处插入原文图3:Fig. 3 Accuracy (%) of DISA in comparison against cross - domain approaches. a, b Office+Caltech - 256, c, d CMU - PIE, e USPS+MNIST (best viewed in color)】
4.4 参数的影响
DISA的有效性取决于参数的最优值。为了调整潜在子空间维度 k k k、迭代次数 T T T以及正则化参数 μ , β , λ \mu, \beta, \lambda μ,β,λ和 γ \gamma γ的最优值,我们在各种适应任务上对DISA进行评估。我们通过在[0.0001, 5]的广泛范围内进行经验搜索来设置正则化参数 μ , β , λ \mu, \beta, \lambda μ,β,λ和 r r r,计算拉普拉斯矩阵时的邻居数量设置为5。图4a展示了在Office+Caltech-256数据集上评估k影响的实验。我们报告了k∈[20,150]时DISA的平均准确率,其中k=30是Office+Caltech-256数据集潜在子空间的最优维度。图4b、c、d和f分别描绘了参数λ、μ、β和γ对Office+Caltech-256数据集的影响。通过这种方式,选择λ=0.5、μ=1、β=0.1和γ=0.1作为DISA的最优参数。图4e展示了每次迭代对Office+Caltech-256数据集的影响结果。我们选择T=10作为最优参数。
图5a、b、c、d、e和f分别展示了不同参数值k、λ、μ、β、T和γ对CMU-PIE数据集的影响。因此,k=110、λ=5、μ=0.5、β=0.0005、γ=0.001和T=10是CMU-PIE数据集的最优参数。
图6a展示了在Digits数据集上评估参数k敏感性的结果。我们报告了k∈[20,140]时DISA的平均准确率,其中k=110是Digits数据集潜在子空间的最优维度。图6b、c、d和f分别展示了参数λ、μ、β和r对Digits数据集的影响。通过这种方式,选择λ=1、μ=5、β=0.001和γ=0.05作为DISA的最优参数。图6e展示了Digits数据集上迭代敏感性的结果,其中T=10被设置为最优参数。
5 结论与展望
在本文中,我们提出了一种新颖的视觉域适应方法——判别性和不变子空间对齐(DISA),以解决跨域偏移问题。DISA在潜在子空间中找到两个域的相关特征,通过最小化边际和条件分布距离来适应转换后的源域和目标域,从而解决跨域问题。DISA利用域的流形信息来保留样本的几何信息。我们在常见视觉数据集的各种任务上对DISA进行了评估,结果表明,与其他最先进的视觉域适应方法相比,该方法具有优越性。
我们打算将DISA扩展为一种在线方法,用于预测视觉问题中实时数据的标签。作为未来的工作,我们考虑将DISA应用于缺失模态和深度学习问题。