BERT模型讲解
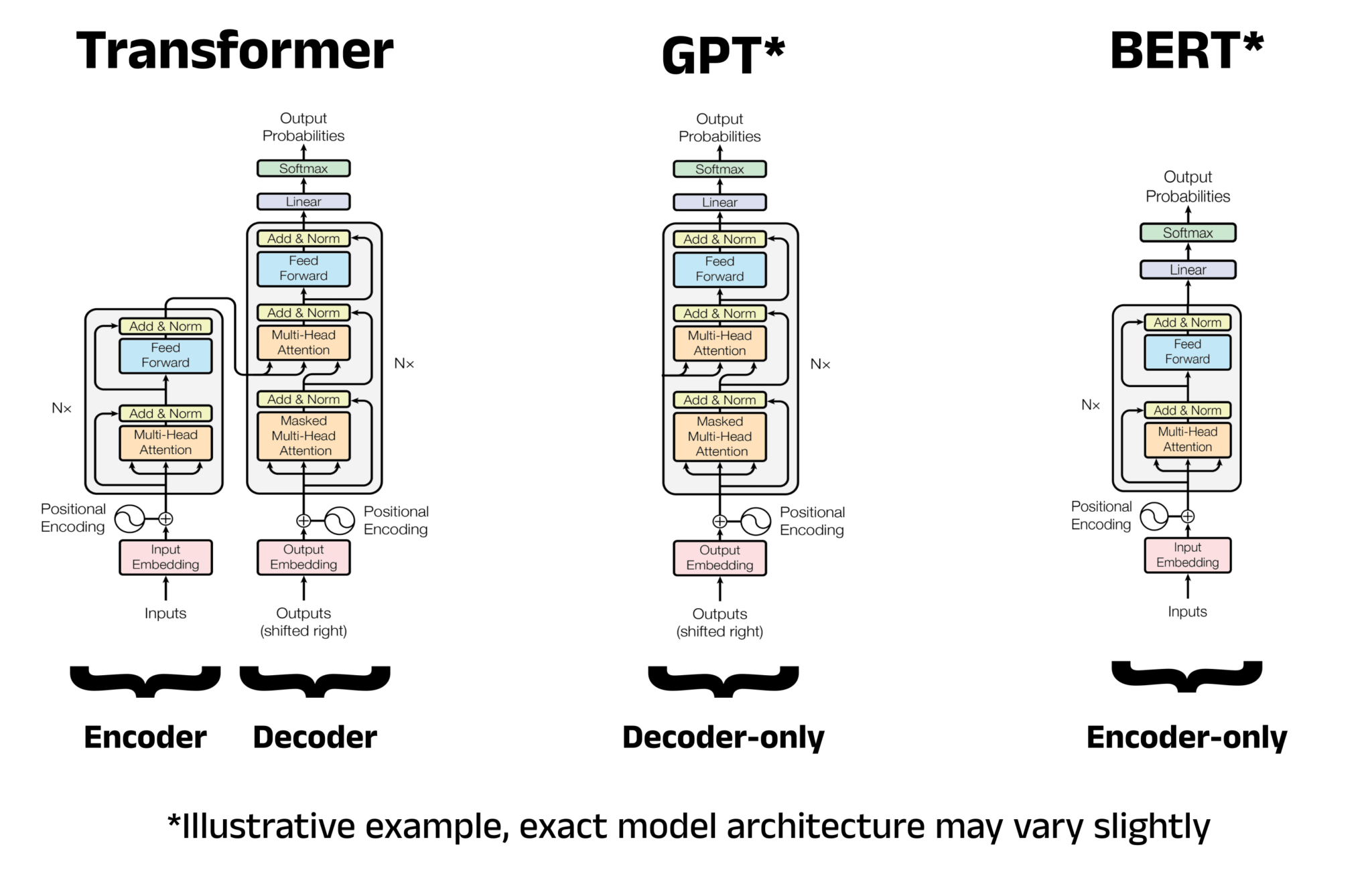
BERT的模型架构
BERT: Bidirectional Encoder Representations from Transformers
BERT这个名称直接反映了:它是一个基于Transformer编码器的双向表示模型。BERT通过堆叠多层编码器来构建深度模型。举例来说:
- BERT-Base:堆叠了12层Encoder,12个注意力头,768维隐藏层,参数量约110M
- BERT-Large:堆叠了24层Encoder,16个注意力头,1024维隐藏层,参数量约340M
BERT的输入表示
BERT的输入表示是其独特之处,包含三部分:
- Token Embedding:词元嵌入,将输入的单词转换为向量表示
- Segment Embedding:段落嵌入,用于区分输入中的不同句子
- Position Embedding:位置嵌入,编码词元在序列中的位置信息
与原始Transformer使用三角函数计算的Position Encoding不同,BERT的Position Embedding是需要学习的参数。
BERT预训练方法
同时进行两项无监督任务的训练来学习语言,即:
- 掩码语言模型MLM
- 下一句预测NSP
接下来我们展开讲解两种任务
掩码语言模型(Masked Language Model, MLM)
即完形填空从而让大模型可以学到上下文。具体做法是(论文中并没讲述为何用这个比例,可能是因为这个比例效果更佳):
- 随机选择输入tokens中的15%
- 对于被选中的tokens:
策略1- 80%的情况下,将其替换为特殊标记[MASK]
策略2- 10%的情况下,将其替换为随机词
策略3- 10%的情况下,保持不变
举例:我爱大语言模型

下一句预测(Next Sentence Prediction, NSP)
NSP任务要求模型判断两个给定句子是否为原文中的相邻句子。这可以让模型理解句子间的关系。是与不是,这也就是转为了二分类任务。
举例:我爱大语言模型
