Ascend的aclgraph(一)aclgraph是什么?torchair又是怎么成图的?
1 aclgraph是什么?
PyTorch框架默认采用Eager模式,单算子下发后立即执行,每个算子都需要从Host侧Python API->Host侧C++层算子下发->Device侧算子kernel执行,在Device侧每次kernel执行之前都需要等待Host侧的下发逻辑完成。因此当单个算子计算量过小或者Host性能不佳时,很容易产生Device空闲时间,即每个kernel执行完后都需要一段时间来等待下一个kernel下发完成。
为了优化Host调度性能,CUDA提供了图模式方案,称为CUDA Graph,一种Device调度策略,即省略算子的Host调度过程,具体参见官网Accelerating PyTorch with CUDA Graphs。
类似地,NPU也提供了图模式方案,称为aclgraph,通过TorchAir提供的backend config配置Device调度模式。
2 aclgraph如何使用
首先,从昇腾aclgraph官网中介绍得知,
该功能通过torchair.get_npu_backend中compiler_config配置,示例如下:
import torch_npu, torchair
config = torchair.CompilerConfig()
# 设置图下沉执行模式
config.mode = "reduce-overhead"
npu_backend = torchair.get_npu_backend(compiler_config=config)
opt_model = torch.compile(model, backend=npu_backend)
mode的设置如下:
| 参数名 | 参数说明 |
|---|---|
| mode | 设置图下沉执行模式,字符串类型。- max-autotune(缺省值):表示Ascend IR Graph下沉模式,其具备了一定的图融合和下沉执行能力,但要求所有算子都注册到Ascend IR计算图,- - reduce-overhead:表示aclgraph下沉模式,主要是单算子kernel的下沉执行,暂不具备算子融合能力,不需要算子注册到Ascend IR计算图。当PyTorch模型存在Host侧调度问题时,建议开启此模式。 |
可以看出来,aclgraph的功能与torchair是结合在一起使用的。
3 函数调用栈
由于torchair的中注释少,Ascend社区上对项目的实现介绍也少。所以,能参考的资料,是真的很少(PS:建议后续给torchair项目做贡献的的同学多给点注释,方便外部开发着快速的阅读和理解代码)。因此,本次小编只能从代码的一层层的剥开去理解整体的逻辑。
从上述的例子着手,看下get_npu_backend中是如何将aclgraph的功能上使能的。
3.1 torchair代码库
torchair是开源的项目,地址参见:https://gitee.com/ascend/torchair
git clone https://gitee.com/ascend/torchair.git
本文从get_npu_backend作为入口函数,
def get_npu_backend(*, compiler_config: CompilerConfig = None, custom_decompositions: Dict = {}):if compiler_config is None:compiler_config = CompilerConfig()decompositions = get_npu_default_decompositions()decompositions.update(custom_decompositions)add_npu_patch(decompositions, compiler_config)return functools.partial(_npu_backend, compiler_config=compiler_config, decompositions=decompositions)
传入的参数compiler_config作用在functools.partial函数,该函数是python的系统函数,是偏函数的概念。
functools.partial(_npu_backend, compiler_config=compiler_config, decompositions=decompositions)
该函数可以认为是:调用_npu_backend函数,然后当前传入的参数是compiler_config和decompositions。_npu_backend其他的参数采用默认参数。特别注意gm:torch.fx.GraphModule参数,解释如下:
torch.fx.GraphModule是 PyTorch 的 FX 变换工具中的一个核心类。FX 是 PyTorch 提供的一个用于模型变换和分析的高级工具集,它允许用户对 PyTorch 模型执行图级别的操作,如插入、删除或修改计算图中的节点。
GraphModule 对象实际上是一个特殊的 PyTorch 模块,它由两部分组成:一个表示计算图的Graph和一个模块层次结构(module hierarchy)。这个计算图是原始模型的图形化表示,其中节点代表运算(比如卷积或ReLU),边代表数据流(即张量)。通过这种表示方法,FX 允许你以编程方式查询和修改模型的行为。
创建一个 GraphModule 通常涉及以下步骤:1. 使用torch.fx.symbolic_trace或其他方法从一个现有的 PyTorch 模块生成一个Graph。2. 将这个Graph和一个包含模型架构信息的Module结合起来,形成一个GraphModule。
由于 GraphModule 实质上也是一个 PyTorch 模块,它可以像普通的 PyTorch 模块一样被调用、保存或加载,并且可以作为更大模型的一部分使用。此外,由于其内部维护了一个计算图,它还支持进一步的分析和变换,这使得它成为实现高级功能(如量化、剪枝等)的理想选择。
该参数的生成处在torch.compile阶段,请先记住有这么一个参数的存在。
3.2 torchair构图函数调用栈
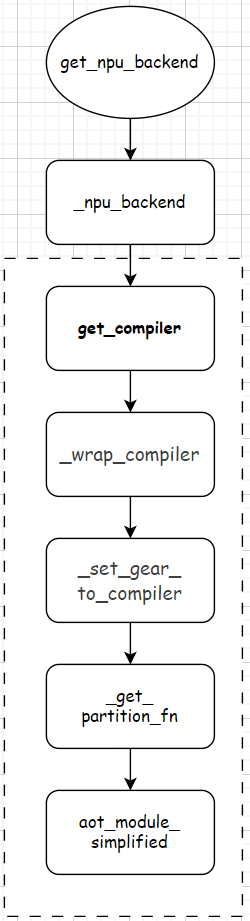
继续看_npu_backend函数定义,调用的函数如上图的虚线方框中所示。主要还是关注涉及到compiler_config的部分。
def _npu_backend(gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor],compiler_config: CompilerConfig = None, decompositions: Dict = {}):if compiler_config is None:compiler_config = CompilerConfig()compiler = get_compiler(compiler_config)input_dim_gears = dict()for i, t in enumerate(example_inputs):dim_gears = get_dim_gears(t)if dim_gears is not None:input_dim_gears[i - len(example_inputs)] = dim_gearsfw_compiler, inference_compiler, joint_compiler = _wrap_compiler(compiler, compiler_config)fw_compiler = _set_gear_to_compiler(fw_compiler, compiler_config, input_dim_gears)inference_compiler = _set_gear_to_compiler(inference_compiler, compiler_config, input_dim_gears)partition_fn = _get_partition_fn(compiler_config)if compiler_config.experimental_config.aot_config_enable_joint_graph:output_loss_index = int(compiler_config.experimental_config.aot_config_output_loss_index.value)return aot_module_simplified_joint(gm, example_inputs,compiler=joint_compiler, decompositions=decompositions,output_loss_index=output_loss_index)keep_inference_input_mutations = bool(compiler_config.experimental_config.keep_inference_input_mutations)# TO DO: fix me in masterif compiler_config.mode.value == "reduce-overhead":keep_inference_input_mutations = Falselogger.debug(f"To temporarily avoid some precision problem in AclGraph, "f"keep_inference_input_mutations config is set to {keep_inference_input_mutations}.")return aot_module_simplified(gm, example_inputs, fw_compiler=fw_compiler, bw_compiler=compiler,decompositions=decompositions, partition_fn=partition_fn,keep_inference_input_mutations=keep_inference_input_mutations,inference_compiler=inference_compiler)
3.2.1 get_compiler
也先给出函数调用栈
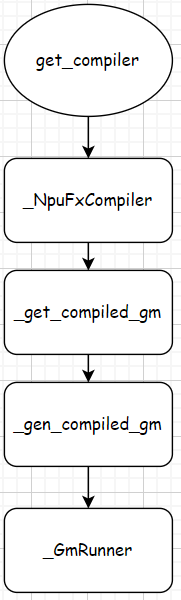
get_compiler经过protected类_NpuFxCompiler,实例化了一个_NpuFxCompiler对象作为compiler。
def get_compiler(compiler_config: CompilerConfig = None):if compiler_config is None:compiler_config = CompilerConfig()return _NpuFxCompiler(compiler_config)
_NpuFxCompiler定义如下,只截取了部分代码。关注__call__部分,是实列compiler调用的接口。
class _NpuFxCompiler:def __init__(self, compiler_config: CompilerConfig) -> None:self.config = compiler_config@pretty_error_msgdef __call__(self, gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor]):return self._get_compiled_gm(gm, example_inputs)def _get_compiled_gm(self, gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor]):if int(self.config.export.experimental.enable_lite_export.value):from torchair._ge_concrete_graph.ge_converter import liteif self.config.debug.fx_summary.enabled:_summarize_fx_graph(gm, example_inputs, self.config.debug.fx_summary.full_path("summary"))if self.config.debug.fx_summary.skip_compile:logger.warning(f'When summarizing FX Graph, npu compilation will be skipped, ''and FALLBACK to EAGER execution to ensure the integrity of the analysis data. ''Once the analysis is complete, please make sure to disable the summary config ''to ensure that the graph is compiled and executed.')return _GmRunner(gm)if self.config.debug.data_dump.enabled:logger.warning(f'When dumping data of FX Graph, npu run will be skipped, ''and FALLBACK to EAGER execution, once dump finished, please make sure to disable ''the data dump config to ensure that the graph is compiled and executed.')data_dumper = _NpuFxDumper(gm, config=self.config.debug.data_dump)return _GmRunner(data_dumper)return _GmRunner(self._gen_compiled_gm(gm, example_inputs))
_get_compiled_gm中self.config.debug.fx_summary.enabled和self.config.debug.data_dump.enabled是2个dump相关信息,当前skip掉。关注于_GmRunner部分。
return _GmRunner(self._gen_compiled_gm(gm, example_inputs))
_GmRunner是一个类,传入的参数是通过_gen_compiled_gm获得,继续看_gen_compiled_gm部分。
3.2.2 _gen_compiled_gm
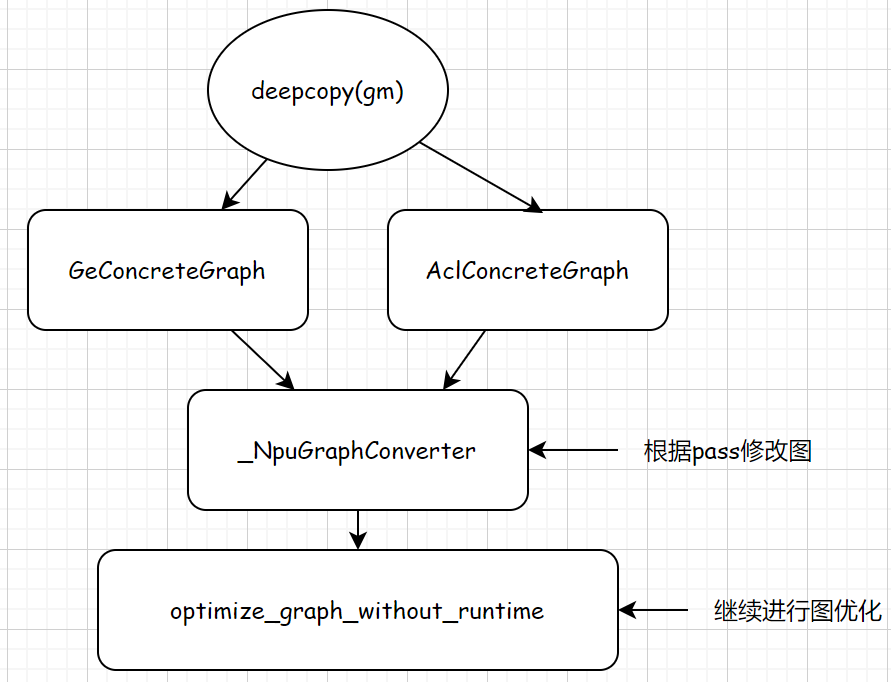
def _gen_compiled_gm(self, gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor]):logger.info(f'compiler inputs')for i, inp in enumerate(example_inputs):logger.info(' input %s: %s', i, inp)logger.info(' graph: %s', gm.graph)# to temporarily fix weight_quant_batchmatmul bugif "torch_npu" in sys.modules:for n in gm.graph.nodes:if n.op == "call_function" and str(n.target) == "npu.npu_weight_quant_batchmatmul.default":self.config.experimental_config.enable_view_optimize = Falselogger.warning(f'To temporarily fix weight_quant_batchmatmul bug, close enable_view_optimize.')breakwith no_dispatch():mutable_gm = copy.deepcopy(gm)if self.config.mode.value == "max-autotune":from torchair._ge_concrete_graph.fx2ge_converter import GeConcreteGraphgraph = GeConcreteGraph(self.config, name="graph_" + str(_next_unique_graph_id()))elif self.config.mode.value == "reduce-overhead":from torchair._acl_concrete_graph.fx2acl_converter import AclConcreteGraphgraph = AclConcreteGraph(self.config)else:raise ValueError(f"Unsupported npu backend mode: {self.config.mode.value}.")concrete_graph: ConcreteGraphBase = _NpuGraphConverter(mutable_gm, graph=graph, garbage_collect_values=False).run(*example_inputs)if self.config.debug.graph_dump.enabled and not self.config.export.export_mode:concrete_graph.dump(self.config.debug.graph_dump.full_path("dynamo_original_graph"))concrete_graph.optimize_graph_without_runtime()
函数里面调用了with no_dispatch()语句,这个是什么意思呢?不慌,小编给出解释;
with no_dispatch() 是与 PyTorch 的 torch.fx 工具一起使用的上下文管理器。torch.fx 是一个用于对 PyTorch 模型进行符号式追踪(symbolic tracing)和变换的库,它允许用户以编程方式操作模型的计算图。
在 torch.fx 中,no_dispatch 上下文用于临时关闭 Python 的调度机制(dispatch mechanism),这通常涉及到自动求导(autograd)、函数转换(如将Python函数转换为计算图中的节点)等过程。当你想要执行一些不想被 torch.fx 追踪的操作时,比如打印调试信息、执行某些自定义的非追踪逻辑等,就可以使用 with no_dispatch(): 来包裹这些代码块。
在with no_dispatch()中对原始GraphModule图进行了深复制。
接下来就是重点部分了,torchair的2种模式(max-autotune,reduce-overhead)的意思如上文所示,这里在代码中匹配上了。接着打开具体分析下:
if self.config.mode.value == "max-autotune":from torchair._ge_concrete_graph.fx2ge_converter import GeConcreteGraphgraph = GeConcreteGraph(self.config, name="graph_" + str(_next_unique_graph_id()))elif self.config.mode.value == "reduce-overhead":from torchair._acl_concrete_graph.fx2acl_converter import AclConcreteGraphgraph = AclConcreteGraph(self.config)else:raise ValueError(f"Unsupported npu backend mode: {self.config.mode.value}.")
这里也明显可以看到,max-autotune模式下,就是通过GE图引擎的方式执行的,有兴趣的可以移位。回到此次讨论的重点,reduce-overhead模式。
AclConcreteGraph是一个类,重点是关注其__call__中的compile方法,该方法是获取aclgraph图的重点(下面是部分代码片段)。本次文章中不展开compile分析,后续单独展开一个篇章。
class AclConcreteGraph(ConcreteGraphBase):def __init__(self, config: CompilerConfig, pool=None, stream=None, capture_error_mode: str = "global",num_warmup_iters=0):try:import torch_npuexcept ImportError as e:raise RuntimeError("Couldn't import torch_npu. When the CompilerConfig.mode is reduce-overhead, ""it is necessary to use torch_npu.npu.NPUGraph(), so importing torch_npu is essential.") from eself._config = configself._npugraph = torch_npu.npu.NPUGraph()self._mempool = torch_npu.npu.graph_pool_handle() if pool is None else poolself._stream = streamself._capture_error_mode = capture_error_modeself._num_warmup_iters = num_warmup_itersself._captured = Falseself._fx_graph = Noneself._replay_func: Callable = Noneself._capture_inputs = []self._capture_outputs = []self._user_inputs_list = []self._meta_inputs = []self._meta_outputs = []def __call__(self, *args: Any, **kwargs: Any) -> Any:self.compile(*args, **kwargs)# input processfor idx in self._user_inputs_list:if self._capture_inputs[idx].data_ptr() != args[idx].data_ptr():self._capture_inputs[idx].copy_(args[idx])# runwith record_function("acl_graph_replay"):self._replay_func(*args, **kwargs)return self._capture_outputs
回到上一级流程,关注于_NpuGraphConverter类。
concrete_graph: ConcreteGraphBase = _NpuGraphConverter(mutable_gm, graph=graph, garbage_collect_values=False).run(*example_inputs)
在_NpuGraphConverter中调用run方法,从GeConcreteGraph或者AclConcreteGraph成图的graph中,通过相关pass对图进行进一步修改,当前只有一个pass : _optimize_sym_input,作用是对图的输入进行call_function的调用,用新的node去替换,
with graph_module.graph.inserting_after(tensor_node):sym_size_node = graph_module.graph.create_node(op="call_function", target=torch.ops.aten.sym_size,args=(tensor_node, i))sym_node.replace_all_uses_with(sym_size_node, propagate_meta=True)logger.debug('Replace node %s by inserting new node %s[op: %s'', target: %s, meta: %s].', sym_node, sym_size_node, sym_size_node.op,sym_size_node.target, sym_size_node.meta)
接着调用
concrete_graph.optimize_graph_without_runtime()
进行图的优化。optimize_graph_without_runtime是在GeConcreteGraph和AclConcreteGraph中都有被定义,而且这2个graph都是继承自ConcreteGraphBase。此处concrete_graph的赋值是ConcreteGraphBase类型,因此optimize_graph_without_runtime会自动选择GE下的还是ACL下的优化。
专注aclgraph中的优化,
def optimize_graph_without_runtime(self):logger.debug('before graph optimization, graph is %s', self.fx_graph.graph)# graph optimization passes herefrom torchair._acl_concrete_graph.acl_graph import replace_dynamic_workspace_opsreplace_dynamic_workspace_ops(self.fx_graph)logger.debug('after graph optimization, graph is %s', self.fx_graph.graph)
可以看到,当前针对aclgraph只有一个pass:replace_dynamic_workspace_ops,该pass的主要最用就是:replace dynamic workspace ops to static workspace 。
估计已经有点绕晕了,先回到上层调用栈_GmRunner部分。
def _get_compiled_gm(self, gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor]):if int(self.config.export.experimental.enable_lite_export.value):from torchair._ge_concrete_graph.ge_converter import liteif self.config.debug.fx_summary.enabled:_summarize_fx_graph(gm, example_inputs, self.config.debug.fx_summary.full_path("summary"))if self.config.debug.fx_summary.skip_compile:logger.warning(f'When summarizing FX Graph, npu compilation will be skipped, ''and FALLBACK to EAGER execution to ensure the integrity of the analysis data. ''Once the analysis is complete, please make sure to disable the summary config ''to ensure that the graph is compiled and executed.')return _GmRunner(gm)if self.config.debug.data_dump.enabled:logger.warning(f'When dumping data of FX Graph, npu run will be skipped, ''and FALLBACK to EAGER execution, once dump finished, please make sure to disable ''the data dump config to ensure that the graph is compiled and executed.')data_dumper = _NpuFxDumper(gm, config=self.config.debug.data_dump)return _GmRunner(data_dumper)return _GmRunner(self._gen_compiled_gm(gm, example_inputs))
这里就是实例化了_GmRunner一个兑现,最终会调用其__call__方法,__call__中又会调用self.runner,该runner就是GeConcreteGraph或者AclConcreteGraph生成图的graph。也就是说,这里开始执行图了。
class _GmRunner:def __init__(self, runner: Callable):self.runner = runnerdef __call__(self, *args, **kwargs):with record_function("npu_fx_compiler inference"):if logger.isEnabledFor(logging.DEBUG):logger.debug('runtime inputs')for i, inp in enumerate(args):logger.debug(' input %s: %s', i, _summary(inp))for k, v in kwargs.items():logger.debug(' input %s: %s', k, _summary(v))gm_result = self.runner(*args, **kwargs)if logger.isEnabledFor(logging.DEBUG):logger.debug('runtime outputs')for i, inp in enumerate(gm_result):logger.debug(' output %s: %s', i, _summary(inp))return gm_result
4 小节一下
以上的内容,主要就是讲了compiler是什么。答案就是:_GmRunner
def _npu_backend(gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor],compiler_config: CompilerConfig = None, decompositions: Dict = {}):if compiler_config is None:compiler_config = CompilerConfig()compiler = get_compiler(compiler_config)
内容太多了,下一篇章再见。