分治算法-leetcode148题
分治算法遵循三个步骤:
- 分解(Divide):将原问题划分为多个子问题,子问题是原问题的较小实例。
- 解决(Conquer):递归解决子问题。若子问题足够小,则直接求解。
- 合并(Combine):将子问题的解合并为原问题的解。
常见的分治算法:
1.归并排序(Merge Sort)
- 原理:将数组递归分成两半,分别排序后合并有序子数组。
- 特点:稳定排序,时间复杂度稳定为 O(nlogn),需额外空间。
- 应用场景:大数据排序、外部排序(如海量数据文件排序)。
2. 快速排序(Quick Sort)
- 原理:选择基准元素(Pivot),将数组分为“小于基准”和“大于基准”两部分,递归排序。
- 特点:原地排序,平均时间复杂度 O(nlogn),最坏情况 O(n2)(可通过随机化避免)。
- 应用场景:内存有限的内部排序,如编程语言标准库中的排序实现。
3. 二分查找(Binary Search)
- 原理:在有序数组中,通过不断缩小搜索范围(折半)快速定位目标值。
- 特点:时间复杂度 O(logn),无合并步骤,属于分治的简化形式。
- 应用场景:有序数据的高效查找,如字典、数据库索引。
4. Strassen 矩阵乘法
- 原理:将大矩阵分解为子矩阵,通过7次子矩阵乘法(而非传统8次)降低计算复杂度。
- 特点:时间复杂度 O(nlog27)≈O(n2.81),优于传统 O(n3)。
- 应用场景:大规模矩阵运算优化,如科学计算、图形学。
5. 最近点对问题(Closest Pair of Points)
- 原理:将点集分为左右两半,分别求最近点对,再检查跨分界线的点对。
- 特点:时间复杂度 O(nlogn),巧妙利用分治减少计算量。
- 应用场景:计算几何、碰撞检测、地理信息系统(GIS)。
6. 大整数乘法(Karatsuba 算法)
- 原理:将大整数分解为高位和低位,通过3次乘法替代传统4次,降低计算次数。
- 特点:时间复杂度 O(nlog23)≈O(n1.585),适用于超大数运算。
- 应用场景:密码学(如RSA加密)、高精度计算库。
7. 快速傅里叶变换(FFT)
- 原理:将多项式分解为偶次项和奇次项,递归转换到频域再合并结果。
- 特点:将 DFT 计算复杂度从 O(n2) 降至 O(nlogn)。
- 应用场景:信号处理、图像压缩(如JPEG)、卷积神经网络。
8. 棋盘覆盖问题
- 原理:用L型骨牌覆盖残缺棋盘,递归分割棋盘为四块,处理含残缺的子块。
- 特点:通过分治将复杂覆盖问题分解为可重复子问题。
- 应用场景:算法教学案例、拼图游戏逻辑。
9. 线性时间选择算法(QuickSelect)
- 原理:类似快速排序,通过划分操作递归查找第k小元素。
- 特点:平均时间复杂度 O(n),无需完全排序。
- 应用场景:统计学中位数计算、Top-K问题(如排行榜)
分治、动态规划、贪心对比
| 策略 | 适用场景 | 关键特点 |
|---|---|---|
| 分治 | 子问题独立且合并简单(如排序) | 递归分解 + 合并结果 |
| 动态规划 | 子问题重叠且有最优子结构(如背包) | 记忆化存储避免重复计算 |
| 贪心 | 局部最优解能导向全局最优(如Huffman编码) | 每一步选择当前最优,无回溯 |
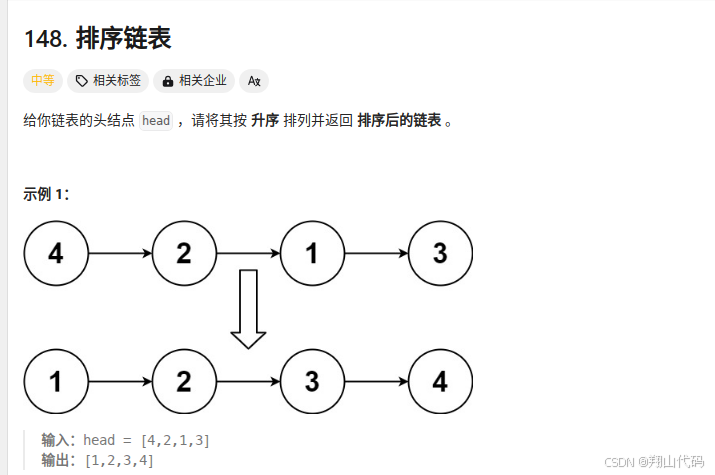 整体步骤如下:
整体步骤如下:
- 递归的终止条件:如果链表为空或者只有一个节点,直接返回,因为已经有序。
- 找到链表的中间节点,将链表分成左右两部分。
- 递归地对左右两部分进行排序。
- 合并排序后的左右两部分。
利用快慢指针找到中间节点,而且有一个很关键的就是一定要把链表从中间节点断开,不然会陷入死循环
代码如下:
class ListNode {int val;ListNode next;ListNode() {}ListNode(int val) { this.val = val; }ListNode(int val, ListNode next) { this.val = val; this.next = next; }
}class Solution {public ListNode sortList(ListNode head) {// 终止条件:链表为空或只有一个节点时直接返回if (head == null || head.next == null) {return head;}// 使用快慢指针找到链表的中间节点(分治的关键步骤)ListNode slow = head, fast = head;while (fast.next != null && fast.next.next != null) {slow = slow.next; // 慢指针每次走一步fast = fast.next.next; // 快指针每次走两步}ListNode mid = slow.next; // 中间节点的下一个节点为右半部分头节点slow.next = null; // 将链表断开为左右两部分// 递归对左右子链表排序(分治的递归分解)ListNode left = sortList(head); // 左半部分排序ListNode right = sortList(mid); // 右半部分排序// 合并两个已排序的链表(分治的结果合并)return merge(left, right);}// 合并两个有序链表private ListNode merge(ListNode l1, ListNode l2) {ListNode dummy = new ListNode(0); // 创建哑节点作为合并后的链表头ListNode cur = dummy;// 遍历两个链表,按升序连接节点while (l1 != null && l2 != null) {if (l1.val <= l2.val) {cur.next = l1;l1 = l1.next;} else {cur.next = l2;l2 = l2.next;}cur = cur.next;}// 将剩余链表直接连接到末尾cur.next = (l1 != null) ? l1 : l2;return dummy.next;}
}