window 显示驱动开发-线性内存空间段
线性内存空间段是显示硬件使用的经典段类型。 线性内存空间段符合以下模型:
- 它虚拟化位于图形适配器上的视频内存。
- GPU 直接访问它;也就是说,无需通过页面映射进行重定向。
- 它在一维地址空间中以线性方式进行管理。
驱动程序将DXGK_SEGMENTDESCRIPTOR结构的 Flags 成员设置为 0 以指定线性内存空间段。 但是,驱动程序可以设置以下位字段标志来指示其他段支持:
- CpuVisible 指示该段是 CPU 可访问的。
- UseBanking 指示该细分市场划分为银行。
下图显示了线性内存空间段的可视表示形式。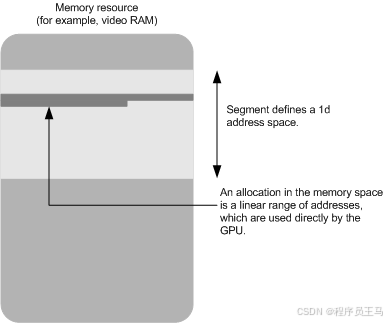
1. 核心特性
| 特性 | 说明 |
|---|---|
| 物理显存虚拟化 | 将 GPU 的物理显存抽象为连续的虚拟地址空间,供 VidMm 统一管理。 |
| 直接 GPU 访问 | GPU 可直接通过物理地址访问,无需页表重定向(无地址转换开销)。 |
| 一维线性管理 | 内存按线性顺序排列,适合 DMA 传输、渲染目标等连续操作。 |
| CPU 可见性可选 | 通过 CpuVisible 标志允许 CPU 访问(如共享纹理)。 |
2. 段描述符配置(DXGK_SEGMENTDESCRIPTOR)
(1) 基础配置
DXGK_SEGMENTDESCRIPTOR Segment = {.Flags = 0, // 默认线性内存空间段.BaseAddress = 0x80000000, // GPU 物理地址起始.Size = 0x40000000, // 段大小(1GB).SegmentId = 1, // 唯一标识符
};示例(CPU 可见的线性段):
{.Flags = DXGK_SEGMENT_FLAGS_CPU_VISIBLE,.BaseAddress = 0x90000000,.Size = 0x20000000, // 512MB.SegmentId = 2,
}3. 内存布局示意图
GPU 物理地址空间示例:
0x80000000 ┌───────────────────────┐ ← 线性内存空间段起始(BaseAddress)│ ││ 连续显存(VRAM) │ ← GPU 直接访问,无页表映射│ │
0xC0000000 └───────────────────────┘ ← 段结束(BaseAddress + Size)4. 典型应用场景
(1) 渲染目标(Render Target)
需求:高性能、低延迟的像素读写。
配置:
{.Flags = 0, // 纯 GPU 访问.BaseAddress = 0x80000000,.Size = 0x10000000, // 256MB
}(2) CPU-GPU 共享缓冲区
需求:CPU 频繁更新的动态数据(如顶点缓冲区)。
配置:
{.Flags = DXGK_SEGMENT_FLAGS_CPU_VISIBLE,.BaseAddress = 0x90000000,.Size = 0x08000000, // 128MB
}(3) 大纹理存储
需求:超大纹理需连续显存(如 8K 贴图)。
配置
{.Flags = DXGK_SEGMENT_FLAGS_USE_BANKING, // 多 Bank 优化.BaseAddress = 0xA0000000,.Size = 0x60000000, // 1.5GB
}5. 驱动开发注意事项
(1) 硬件对齐要求
起始地址对齐:通常需 64KB 或 1MB(依赖 GPU 架构)。
大小对齐:需为硬件页大小(如 4KB)的整数倍。
(2) 性能优化
避免碎片化:连续分配大块资源,减少显存空洞。
Banking 的使用:若 GPU 支持显存 Bank 切换(如 NVIDIA 的 Tiled Resources),可提升并行访问效率。
(3) 错误处理
分配失败:检查 BaseAddress 是否与其他段重叠,或 Size 超出物理显存限制。
CPU 访问异常:若未设置 CPU_VISIBLE,CPU 访问会触发蓝屏(BSOD)。
6. 与其他段类型的对比
| 特性 | 线性内存空间段 | 线性光圈空间段 | AGP 光圈段 |
|---|---|---|---|
| 物理内存 | 直接分配显存 | 虚拟地址映射系统内存 | 混合映射(显存+系统内存) |
| GPU 访问 | 直接访问(零开销) | 需页表转换 | 需页表转换 |
| CPU 访问 | 可选(CPU_VISIBLE) | 默认支持 | 默认支持 |
| 适用场景 | 高性能渲染资源 | CPU 频繁写资源 | 传统兼容性需求 |
7. 总结
线性内存空间段是显存管理的核心机制,提供高效、连续的 GPU 直接访问。
关键配置:
- 通过 Flags 控制 CPU 可见性和 Banking。
- 确保 BaseAddress 和 Size 符合硬件规范。
适用场景:
- 渲染目标、纹理等高性能需求资源。
- 需 CPU-GPU 共享的动态数据(如流式顶点缓冲区)。
正确配置线性段可最大化 GPU 显存利用率,是 WDDM 驱动开发的基础环节。